python 批量下载 excel中的图片
Posted xuybb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 批量下载 excel中的图片相关的知识,希望对你有一定的参考价值。

文件格式:xlsx
就三列 编码 名称 和图片地址
注意事项
1.注意缩进 for循环下面的所有都要缩进
2.把脚本和excel 放到同一个文件夹内
3.用python3
如果你是第一次用,那就需要下载python 配置环境变量 这部分百度就行
然后在执行脚本之前 cmd下载xlrd 和 requests 注意版本 这部分不做会报错 到时候根据报错信息百度也行
脚本执行语法
cmd cd到脚本所在路径 执行 python 脚本名.py
有报错看报错 没报错等执行完
脚本如下
import xlrd
import requests
a = xlrd.open_workbook(\'2.xlsx\',\'r\') #打开.xlsx文件
sht = a.sheets()[0] #打开表格中第一个sheet
row1 = sht.row_values(0)
#设置要下载的图片的范围,对应于 Excel 中的行数
start = 2
end = 203
for i in range(start,end):
url = sht.cell(i,2).value #依次读取每行第三列的数据,也就是 URL
code = sht.cell(i,0).value #第一列 编码
f = requests.get(url)
ii = str(i) #按照下载顺序(行号)构造文件名
url2 = url[-3:] #根据链接地址获取文件后缀,后缀有.jpg 和 .gif 两种
dir = code + "." + url2 #构造完整文件名称
with open(dir,"wb") as code:
code.write(f.content) #保存文件
print(url) #打印当前的 URL
jindu = (i - start) / (end - start) * 100 #计算下载进度
print("下载进度:",jindu,"%") #显示下载进度
批量将多个图片转PDF的记录
本文记录了图片下载后转换成PDF的过程,期间用到了EXCEL和PYTHON,所有来源都是从网络上学习后,稍加整理并测试通过。
[阶段一:有规则的图片下载地址]
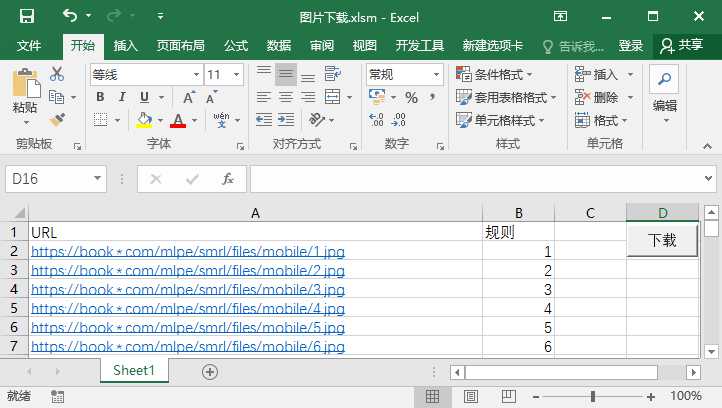
之所以用Excel下载图片,主要是电脑上没有下载工具,于是找到以下代码,并稍加修改后,就可以完成批量下载了(我们不谈速度23333)
1 Option Explicit 2 Private Declare Function MakeSureDirectoryPathExists _ 3 Lib "imagehlp.dll" (ByVal Pfad As String) As Long 4 Private Declare Function DeleteUrlCacheEntry Lib "wininet" Alias _ 5 "DeleteUrlCacheEntryA" (ByVal lpszUrlName As String) As Long 6 Private Declare Function URLDownloadToFile Lib "urlmon" _ 7 Alias "URLDownloadToFileA" ( _ 8 ByVal pCaller As Long, _ 9 ByVal szURL As String, _ 10 ByVal szFileName As String, _ 11 ByVal dwReserved As Long, _ 12 ByVal lpfnCB As Long) As Long 13 14 Public Sub GetFiles() 15 Const strBackup As String = "D:poto" ‘保存路径 16 Dim arr 17 Dim TargetFile As String 18 Dim lngTMP, i As Long 19 Dim cnt 20 21 arr = Range("a1").CurrentRegion 22 MakeSureDirectoryPathExists strBackup 23 cnt = UBound(arr) 24 For i = 2 To cnt 25 TargetFile = strBackup & arr(i, 2) & ".jpg" ‘A列 26 Call DeleteUrlCacheEntry(arr(i, 1)) ‘B列 27 lngTMP = URLDownloadToFile(0, arr(i, 1), TargetFile, 0, 0) 28 DoEvents 29 Application.StatusBar = "结束前请勿乱动:" & i & "/" & cnt 30 Next 31 32 Application.StatusBar = cnt & "/" & cnt & " 完成。" 33 End Sub
[阶段二:将图片转PDF]
本来以为这个很容易,随便下载一个软件转换一下就行了,没想到尝试了好多软件,都需要付费,而且大多数是大于5张图片就100%需要收费了。正好最近在看python,基础语法什么的已经了解了,于是网络上搜刮了一下:
源码:
1 from PIL import Image 2 import os 3 import re 4 5 6 def tryint(s): #将元素中的数字转换为int后再排序 7 try: 8 return int(s) 9 except ValueError: 10 return s 11 12 def str2int(v_str): #将元素中的字符串和数字分割开 13 return [tryint(sub_str) for sub_str in re.split(‘([0-9]+)‘, v_str)] 14 15 def sort_humanly(v_list): #以分割后的list为单位进行排序 16 return sorted(v_list, key=str2int) 17 def rea(path, pdf_name): 18 file_list = os.listdir(path) 19 pic_name = [] 20 im_list = [] 21 for x in file_list: 22 if "jpg" in x or ‘png‘ in x or ‘jpeg‘ in x: 23 pic_name.append(x) 24 25 pic_name=sort_humanly(pic_name) 26 print(‘---‘) 27 print(pic_name) 28 new_pic = [] 29 30 for x in pic_name: 31 if "jpg" in x: 32 new_pic.append(x) 33 34 for x in pic_name: 35 if "png" in x: 36 new_pic.append(x) 37 38 print("hec", new_pic) 39 40 im1 = Image.open(os.path.join(path, new_pic[0])) 41 new_pic.pop(0) 42 for i in new_pic: 43 img = Image.open(os.path.join(path, i)) 44 # im_list.append(Image.open(i)) 45 if img.mode == "RGBA": 46 img = img.convert(‘RGB‘) 47 im_list.append(img) 48 else: 49 im_list.append(img) 50 im1.save(pdf_name, "PDF", resolution=100.0, save_all=True, append_images=im_list) 51 print("输出文件名称:", pdf_name) 52 53 54 if __name__ == ‘__main__‘: 55 56 mypath = input("输入文件路径>") 57 pdf_name = mypath + r‘ esult.pdf‘ 58 if ".pdf" in pdf_name: 59 rea(mypath, pdf_name=pdf_name) 60 else: 61 rea(mypath, pdf_name="{}.pdf".format(pdf_name))
这里面涉及一个排序问题,就是1.JPG、2.JPG、10.JPG等,用了默认的.sort之后,排序是1.JPG、10.JPG、2.JPG。有点问题,于是又重新找了一个排序放上去就正常了,特别网上分享经验的各位Up主。下面就是这个神奇的排序:
1 def tryint(s): #将元素中的数字转换为int后再排序 2 try: 3 return int(s) 4 except ValueError: 5 return s 6 7 def str2int(v_str): #将元素中的字符串和数字分割开 8 return [tryint(sub_str) for sub_str in re.split(‘([0-9]+)‘, v_str)] 9 10 def sort_humanly(v_list): #以分割后的list为单位进行排序 11 return sorted(v_list, key=str2int)
资源来源网上,为个人整理,欢迎大家提意见~!!!
以上是关于python 批量下载 excel中的图片的主要内容,如果未能解决你的问题,请参考以下文章