随机森林填充数据
Posted Thank CAT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了随机森林填充数据相关的知识,希望对你有一定的参考价值。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
boston = pd.read_csv("./boston_house_prices.csv")
boston_target = pd.DataFrame(boston["MEDV"])
boston_data = pd.DataFrame(boston.iloc[:,boston.columns != "MEDV"])
boston_target.columns = [0]
boston_data.columns = range(len(boston_data.columns))
n_samples = boston_data.shape[0]
n_feature = boston_data.shape[1]
rng = np.random.RandomState(0)
missing_rate = 0.5
n_missing_sample = int(np.floor(n_samples * n_feature * missing_rate))
n_missing_sample
3289
missing_feature = rng.randint(0, n_feature, n_missing_sample)
missing_sample = rng.randint(0, n_samples, n_missing_sample)
x_missing = boston_data.copy()
y_missing = boston_data.copy()
x_missing = np.array(x_missing)
x_missing[missing_sample, missing_feature] = np.nan
x_missing = pd.DataFrame(x_missing)
x_missing.isna().sum()
0 200
1 201
2 200
3 203
4 202
5 201
6 185
7 197
8 196
9 197
10 204
11 214
12 189
dtype: int64
im_mean = SimpleImputer(missing_values=np.nan, strategy="mean")
x_missing_mean = im_mean.fit_transform(x_missing)
im_0 = SimpleImputer(missing_values=np.nan, strategy="constant", fill_value=0)
x_missing_0 = im_0.fit_transform(x_missing)
x_missing_reg = x_missing.copy()
x_missing_reg.info()
<class \'pandas.core.frame.DataFrame\'>
RangeIndex: 506 entries, 0 to 505
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 306 non-null float64
1 1 305 non-null float64
2 2 306 non-null float64
3 3 303 non-null float64
4 4 304 non-null float64
5 5 305 non-null float64
6 6 321 non-null float64
7 7 309 non-null float64
8 8 310 non-null float64
9 9 309 non-null float64
10 10 302 non-null float64
11 11 292 non-null float64
12 12 317 non-null float64
dtypes: float64(13)
memory usage: 51.5 KB
sortindex = np.argsort(x_missing_reg.isnull().sum(axis=0)).values
for i in sortindex:
df = x_missing_reg
fillc = df.iloc[:,i]
df = pd.concat([df.iloc[:,df.columns != i], boston_target], axis=0)
df_0 = SimpleImputer(missing_values=np.nan, strategy="constant",fill_value=0).fit_transform(df)
y_train = fillc[fillc.notna()]
y_test = fillc[fillc.isna()]
x_train = df_0[y_train.index, :]
x_test = df_0[y_test.index, :]
rfc = RandomForestRegressor(n_estimators=100)
rfc.fit(x_train, y_train)
Ypredict = rfc.predict(x_test)
x_missing_reg.loc[x_missing_reg.iloc[:,i].isna(),i] = Ypredict
X = [boston_data, x_missing_mean, x_missing_0, x_missing_reg]
mse = []
for x in X:
rfc = RandomForestRegressor(random_state=0, n_estimators=100)
score = cross_val_score(rfc, x, np.array(boston_target).ravel(),cv=10,scoring="neg_mean_squared_error").mean()
mse.append(score * -1)
x_labels = [\'Full data\',
\'Zero Imputation\',
\'Mean Imputation\',
\'Regressor Imputation\']
colors = [\'r\', \'g\', \'b\', \'orange\']
plt.figure(figsize=(12, 6))
ax = plt.subplot(111)
for i in np.arange(len(mse)):
ax.barh(i, mse[i],color=colors[i], alpha=0.6, align=\'center\')
ax.set_title(\'Imputation Techniques with Boston Data\')
ax.set_xlim(left=np.min(mse) * 0.9, right=np.max(mse) * 1.1)
ax.set_yticks(np.arange(len(mse)))
ax.set_xlabel(\'MSE\')
ax.set_yticklabels(x_labels)
plt.show()

缺失值处理拉格朗日插值法—随机森林算法填充—sklearn填充(均值/众数/中位数)
文章目录
在进行缺失值填充之前,要先对缺失的变量进行业务上的了解,即变量的含义、获取方式、计算逻辑,以便知道该变量为什么会出现缺失值、缺失值代表什么含义。
缺失值的处理
对于缺失值的处理,从总体上来说分为删除存在缺失值的个案和缺失值插补。
- 不处理
- 删除存在缺失值的样本(或特征)
- 缺失值插补
这里可以阅读以下《美团机器学习实战》中关于缺失值的说明:

一般主观数据不推荐插补的方法,插补主要是针对客观数据,它的可靠性有保证。
附上常用的插补方法

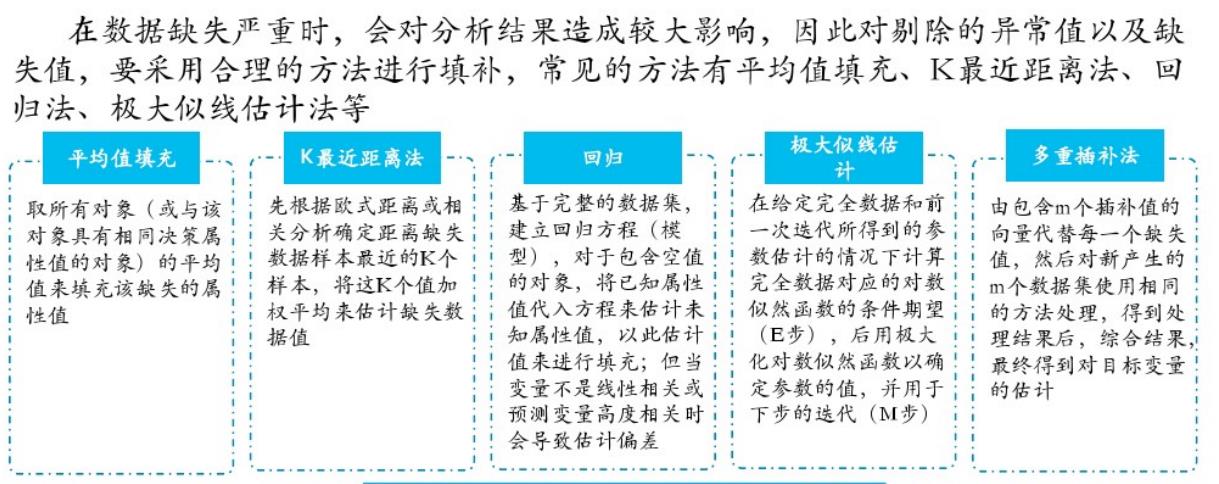
准备数据
使用泰坦尼克数据集:
import seaborn as sns
# 导出泰坦尼克数据集
df = sns.load_dataset('titanic')
df.shape # 891, 15)
df.info()
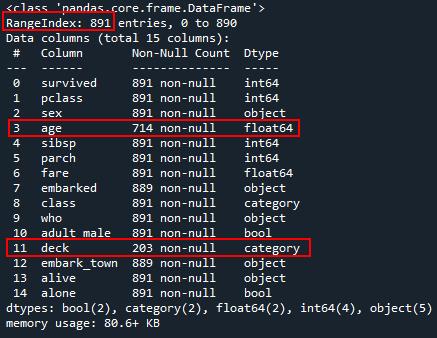
数据字段含义网上有解释
可能会存在样本重复,即有超过一行的样本所显示的所有特征都一样
#去除重复值
df.drop_duplicates(inplace=True)
df.shape
#恢复索引
df.index = range(df.shape[0])
缺失情况
df.isnull().sum()
'''
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int64
'''
缺失占比
df.isna().mean()
'''
survived 0.000000
pclass 0.000000
sex 0.000000
age 0.198653
sibsp 0.000000
parch 0.000000
fare 0.000000
embarked 0.002245
class 0.000000
who 0.000000
adult_male 0.000000
deck 0.772166
embark_town 0.002245
alive 0.000000
alone 0.000000
dtype: float64
'''
1 sklearn填充
在sklearn当中,使用 impute.SimpleImputerr 来处理缺失值,参数为
sklearn.impute.SimpleImputer (
missing_values=nan,
strategy=’mean’,
fill_value=None,
verbose=0,
copy=True)
| 参数 | 含义 |
|---|---|
| missing_values | 数据中缺失值是什么,默认np.nan |
| strategy | 填补缺失值的策略,默认均值 输入“mean”使用均值填补(仅对数值型特征可用) 输入“median”使用中位数填补(仅对数值型特征可用) 输入“most_frequent”使用众数填补(对数值型和字符型特征都可用) 输入“constant”表示请参考参数“fill_value”中的值(对数值型和字符型特征都可用) |
| fill_value | 当参数strategy为“constant”的时候可用,可输入字符串或数字表示要填充的值,常用0 |
| copy | 默认为True,将创建特征矩阵的副本,反之则会将缺失值填补到原本的特征矩阵中。 |
传统地,
- 如果是分类型特征,采用众数进行填补。
- 如果是连续型特征,采用均值进行填补。
还要考虑
- 均值一般适用于近似正态分布数据,观测值较为均匀散布均值周围;
- 中位数一般适用于偏态分布或者有离群点数据,中位数是更好地代表数据中心趋势;
- 众数一般用于类别变量,无大小、先后顺序之分。
在现实工作时,使用最多的是易于理解的均值或者中位数。
(1)使用均值进行填补(连续型特征)
import numpy as np
import pandas as pd
# 去掉标签
X_missing = df.drop(['survived'],axis=1)
# 查看缺失情况
missing = X_missing.isna().sum()
missing = pd.DataFrame(data='特征': missing.index,'缺失值个数':missing.values)
#通过~取反,选取不包含数字0的行
missing = missing[~missing['缺失值个数'].isin([0])]
# 缺失比例
missing['缺失比例'] = missing['缺失值个数']/X_missing.shape[0]
missing
'''
特征 缺失值个数 缺失比例
2 age 177 0.198653
6 embarked 2 0.002245
10 deck 688 0.772166
11 embark_town 2 0.002245
'''
# 排序
missing.sort_values(by='缺失比例',ascending=False)
#柱形图可视化
import matplotlib.pyplot as plt
import numpy as np
import pylab as pl
fig = plt.figure(figsize=(18,6))
plt.bar(np.arange(missing.shape[0]), list(missing['缺失比例'].values), align = 'center',color=['red','green','yellow','steelblue'])
plt.title('Histogram of missing value of variables')
plt.xlabel('variables names')
plt.ylabel('missing rate')
# 添加x轴标签,并旋转90度
plt.xticks(np.arange(missing.shape[0]),list(missing['特征']))
pl.xticks(rotation=90)
# 添加数值显示
for x,y in enumerate(list(missing['缺失比例'].values)):
plt.text(x,y+0.12,':.2%'.format(y),ha='center',rotation=90)
plt.ylim([0,1.2])
plt.show()
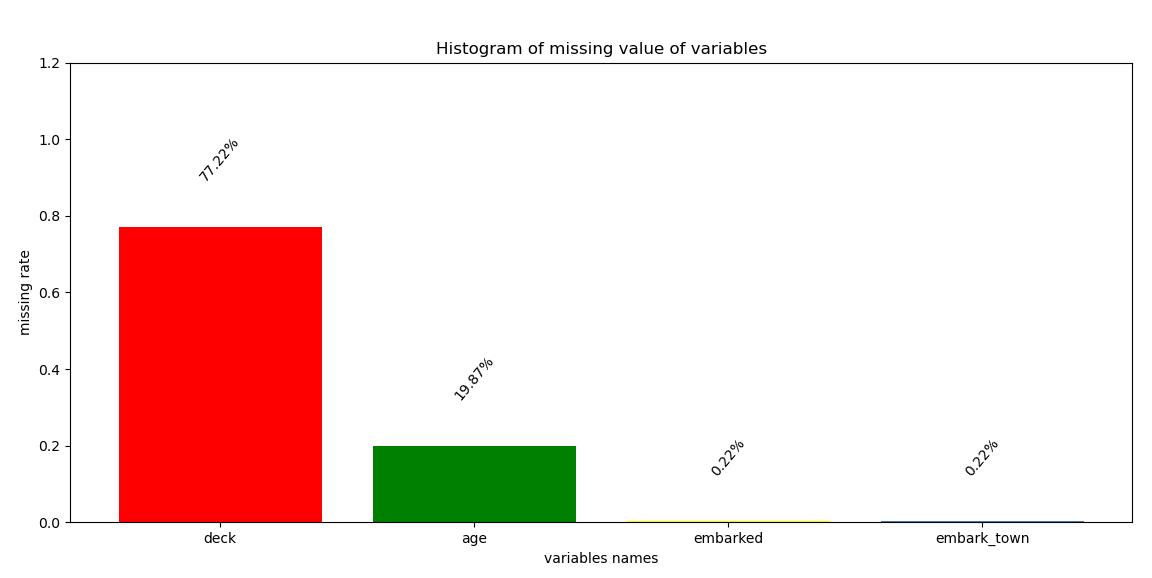
X_missing[missing['特征']].info()
'''
RangeIndex: 891 entries, 0 to 890
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 714 non-null float64
1 embarked 889 non-null object
2 deck 203 non-null category
3 embark_town 889 non-null object
'''
X_missing['embarked'].unique() # array(['S', 'C', 'Q', nan], dtype=object)
X_missing['deck'].unique() # [NaN, C, E, G, D, A, B, F]
X_missing['embark_town'].unique() # array(['Southampton', 'Cherbourg', 'Queenstown', nan], dtype=object)
deck 列缺失比例达到77%,这里考虑直接删除该列
X_missing.drop(['deck'],axis=1,inplace=True)
# 把各个类型 分离出来 方便采用不同的填补方法
# 数值型(即数据类型为int、float的列)
X_missing[missing['特征']].select_dtypes(include='number').columns
# 除数据类型为number外其他的列
X_missing[missing['特征']].select_dtypes(exclude='number').columns
#
X_missing[missing['特征']].select_dtypes(include='object').columns
X_missing[missing['特征']].select_dtypes(include=['int', 'datetime', 'object']).columns
使用均值进行填补,仅对数值型特征可用,这里对age进行填补
#填补年龄
Age = X_missing.loc[:,"age"].values.reshape(-1,1) #sklearn当中特征矩阵必须是二维
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer() #实例化,默认均值填补
#imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean')
imp_mean = imp_mean.fit_transform(Age) #fit_transform一步完成调取结果
X_missing.loc[:,"age"] = imp_mean
X_missing.info()
'''
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 pclass 891 non-null int64
1 sex 891 non-null object
2 age 891 non-null float64
3 sibsp 891 non-null int64
4 parch 891 non-null int64
5 fare 891 non-null float64
6 embarked 889 non-null object
7 class 891 non-null category
8 who 891 non-null object
9 adult_male 891 non-null bool
10 embark_town 889 non-null object
11 alive 891 non-null object
12 alone 891 non-null bool
'''
(2)使用中位数、0进行填补(连续型特征)
也可以用中位数填补或用0填补
imp_median = SimpleImputer() #实例化
imp_median = SimpleImputer(strategy="median") #用中位数填补
imp_median = imp_median.fit_transform(Age)
imp_0 = SimpleImputer() #实例化
imp_0 = SimpleImputer(strategy="constant",fill_value=0) #用0填补
imp_0 = imp_0.fit_transform(Age)
最需要注意的一点是SimpleImputer传入的参数至少要是二维,如果将直接索引出的一列特征传入的话,是会发生报错的,所以必须利用reshape()将一维转化为二维。之后的操作就是先实例化、然后训练模型,最后用填充后的数据覆盖之前的数据。
(3)使用众数进行填补(离散型特征)
使用众数填补embarked、embark_town
# 查看缺失情况
missing = X_missing.isna().sum()
missing = pd.DataFrame(data='特征': missing.index,'缺失值个数':missing.values)
#通过~取反,选取不包含数字0的行
missing = missing[~missing['缺失值个数'].isin([0])]
# 缺失比例
missing['缺失比例'] = missing['缺失值个数']/X_missing.shape[0]
missing
'''
特征 缺失值个数 缺失比例
6 embarked 2 0.002245
10 embark_town 2 0.002245
'''
X_missing['embarked'].unique() # array(['S', 'C', 'Q', nan], dtype=object)
X_missing['embark_town'].unique() # array(['Southampton', 'Cherbourg', 'Queenstown', nan], dtype=object)
imp_most = SimpleImputer() #实例化
imp_most = SimpleImputer(strategy = "most_frequent")
X_missing[missing['特征']] = imp_most.fit_transform(X_missing[missing['特征']])
X_missing.isnull().sum()
'''
pclass 0
sex 0
age 0
sibsp 0
parch 0
fare 0
embarked 0
class 0
who 0
adult_male 0
embark_town 0
alive 0
alone 0
dtype: int64
'''
SimpleImputer优于fillna()之处在于前者可以一行语句指定填充值的形式,而利用fillna()需要多行重复语句才能实现,或者需要提前计算某列的平均值、中位数或者众数。
比如,用fillna()填充
# 用中位数填充
X_missing.loc[:,"age"] = X_missing.loc[:,"age"].fillna(X_missing.loc[:,"age"].median())
或者更一般的
# 均值填充
data['col'] = data['col'].fillna(data['col'].means())
# 中位数填充
data['col'] = data['col'].fillna(data['col'].median())
# 众数填充
data['col'] = data['col'].fillna(stats.mode(data['col'])[0][0])
(4)KNN填补
官网:https://scikit-learn.org/stable/modules/generated/sklearn.impute.KNNImputer.html
使用sklearn的impute 模块中的KNNImputer 函数。KNNImputer通过欧几里德距离矩阵寻找最近邻,帮助估算观测中出现的缺失值。
每个样本的缺失值都是使用n_neighbors训练集中找到的最近邻的平均值估算的 。如果两个都不缺失的特征都接近,则两个样本接近。
class sklearn.impute.KNNImputer(*,
missing_values=nan,
n_neighbors=5,
weights='uniform',
metric='nan_euclidean',
copy=True,
add_indicator=False)
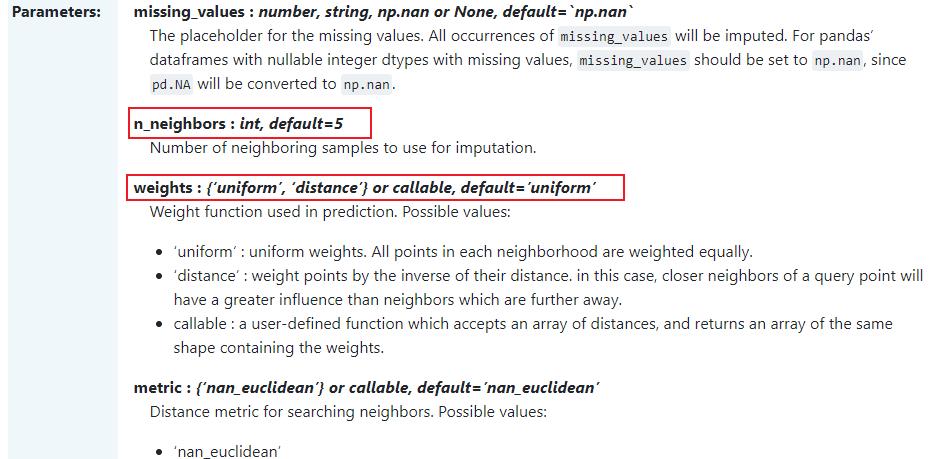
import numpy as np
from sklearn.impute import KNNImputer
X = [[1, 2, np.nan], [3, 4, 3], [np.nan, 6, 5], [8, 8, 7]]
imputer = KNNImputer(n_neighbors=2)
imputer.fit_transform(X)
'''
array([[1. , 2. , 4. ],
[3. , 4. , 3. ],
[5.5, 6. , 5. ],
[8. , 8. , 7. ]])
'''
# 对于离散数据
data = [['a1',12,'M'],['a2',10,np.nan],['a3',14,'F'],['a4',8,'M'],['a5',7,'F']
,['a6',20,'F'],['a7',7,'M']]
df = pd.DataFrame(data,columns=['name','age','gender'])
'''
name age gender
0 a1 12 M
1 a2 10 NaN
2 a3 14 F
3 a4 8 M
4 a5 7 F
5 a6 20 F
6 a7 7 M
'''
# 将离散数据转化为数值型
df['gender_map'] = df.gender.map('F':1,'M':0)
df
'''
name age gender gender_map
0 a1 12 M 0.0
1 a2 10 NaN NaN
2 a3 14 F 1.0
3 a4 8 M 0.0
4 a5 7 F 1.0
5 a6 20 F 1.0
6 a7 7 M 0.0
'''
df_fill = df[['age','gender_map']]
'''
age gender_map
0 12 0.0
1 10 NaN
2 14 1.0
3 8 0.0
4 7 1.0
5 20 1.0
6 7 0.0
'''
# 填补
from sklearn.impute import KNNImputer
impute = KNNImputer(n_neighbors = 2)
df_filled = impute.fit_transform(df_fill)
df_filled
'''
array([[12., 0.],
[10., 0.],
[14., 1.],
[ 8., 0.],
[ 7., 1.],
[20., 1.],
[ 7., 0.]])
'''
另外,还有其他的实现KNN填充方式
利用knn算法填充,其实是把目标列当做目标标量,利用非缺失的数据进行knn算法拟合,最后对目标列缺失进行预测。(对于连续特征一般是加权平均,对于离散特征一般是加权投票)
fancyimpute 类
from fancyimpute import KNN
fill_knn = KNN(k=3).fit_transform(data)
data = pd.DataFrame(fill_knn)
sklearn类
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
def knn_filled_func(x_train, y_train, test, k = 3, dispersed = True):
# params: x_train 为目标列不含缺失值的数据(不包括目标列)
# params: y_train 为不含缺失值的目标列
# params: test 为目标列为缺失值的数据(不包括目标列)
if dispersed:
knn= KNeighborsClassifier(n_neighbors = k, weights = "distance")
else:
knn= KNeighborsRegressor(n_neighbors = k, weights = "distance")
knn.fit(x_train, y_train)
return test.index, knn.predict(test)
2 随机森林回归进行填补
现实中,很少用算法(如随机森林)填补缺失值,因为算法填补很慢,不如均值或者0。另外,算法插补方法,领导不一定能理解,造成不必要的麻烦。
具体的
在现实中,其实非常少用到算法来进行填补,有以下几个理由:
- 算法是黑箱,解释性不强。如果你是一个数据挖掘工程师,你使用算法来填补缺失值后,你不懂机器学习的老板或者同事问你的缺失值是怎么来的,你可能需要从头到尾帮他/她把随机森林解释一遍,这种效率过低的事情是不可能做的,而许多老板和上级不会接受他们无法理解的东西。
- 算法填补太过缓慢,运行–次森林需要有至少100棵树才能够基本保证森林的稳定性,而填补一个列就需要很长的时间。在我们并不知道森林的填补结果是好是坏的情况下,填补一个很大的数据集风险非常高,有可能需要跑好几个小时,但填补出来的结果却不怎么优秀,这明显是–个低效的方法。
但这种方法还是值得学习的
随机森林插补法原理
对于一个有n个特征的数据来说,其中特征T有缺失值,我们就把特征T当作标签,其他的
n-1个特征 + 原本的标签 = 新的特征矩阵
那对于T来说,它没有缺失的部分,就是我们的 Y_train,这部分数据既有标签也有特征,而它缺失的部分,只有特征没有标签,就是我们需要预测的部分。
特征T不缺失的值对应的其他n-1个特征 + 本来的标签:X_train
特征T不缺失的值:Y_train
特征T缺失的值对应的其他n-1个特征 + 本来的标签:X_test
特征T缺失的值:未知,我们需要预测的 Y_test
那如果数据中除了特征T之外,其他特征也有缺失值怎么办?
答案是遍历所有的特征,从缺失最少的开始进行填补(因为填补缺失最少的特征所需要的准确信息最少)。填补一个特征时,先将其他特征的缺失值用0代替,每完成一次回归预测,就将预测值放到原本的特征矩阵中,再继续填补下一个特征。每一次填补完毕,有缺失值的特征会减少一个,所以每次循环后,需要用0来填补的特征就越来越少。当进行到最后一个特征时(这个特征应该是所有特征中缺失值最多的),已经没有任何的其他特征需要用0来进行填补了,而我们已经使用回归为其他特征填补了大量有效信息,可以用来填补缺失最多的特征。遍历所有的特征后,数据就完整,不再有缺失值了。
代码
换一个数据集
(1)构造缺失数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
dataset = load_boston()
# 总共506*13=6578个数据,不含缺失值
# 完整的数据
X_full, y_full = dataset.data, dataset.target
n_samples = X_full.shape[0] # 样本 506
n_features = X_full.shape[1] # 特征 13
rng = np.random.RandomState(0) # 种子
# 缺失率为0.2,即构造的缺失值占20%
missing_rate = 0.2
n_missing_samples = int(np.floor(n_samples * n_features * missing_rate))
# 缺失值索引
missing_col_index = rng.randint(0,n_features,n_missing_samples)
missing_row_index = rng.randint(0,n_samples,n_missing_samples)
X_missing = X_full.copy()
y_missing = y_full.copy()
# 替换,构造缺失值数据集
X_missing[missing_row_index,missing_col_index] = np.nan
X_missing = pd.DataFrame(X_missing,columns=dataset.feature_names)
用随机森林回归来填补缺失值
X_missing_reg = X_missing.copy()
# 查看缺失情况
missing = X_missing_reg .isna().sum()
missing = pd.DataFrame(data='特征': missing.index,'缺失值个数':missing.values)
#通过~取反,选取不包含数字0的行
missing = missing[~missing['缺失值个数'].isin([0])]
# 缺失比例
missing['缺失比例'] = missing['缺失值个数']/X_missing_reg .shape[0]
missing
'''
特征 缺失值个数 缺失比例
0 CRIM 91 0.179842
1 ZN 88 0.173913
2 INDUS 93 0.183794
3 CHAS 109 0.215415
4 NOX 96 0.189723
5 RM 100 0.197628
6 AGE 93 0.183794
7 DIS 85 0.167984
8 RAD 87 0.171937
9 TAX 92 0.181818
10 PTRATIO 88 0.173913
11 B 93 0.183794
12 LSTAT 88 0.173913
'''
X_df = X_missing_reg.isnull().sum()
# 得出列名 缺失值最少的列名 到 缺失值最多的列名
colname= X_df[~X_df.isin([0])].sort_values().index.values
# 缺失值从小到大的特征顺序
sortindex =[]
for i in colname:
sortindex .append(X_missing_reg.columns.tolist().index(str(i)))
# 遍历所有的特征,从缺失最少的开始进行填补,每完成一次回归预测,就将预测值放到原本的特征矩阵中,再继续填补下一个特征
for i in sortindex:
#构建我们的新特征矩阵和新标签
df = X_missing_reg 以上是关于随机森林填充数据的主要内容,如果未能解决你的问题,请参考以下文章