python numpy模块的np.empty((3,4))为啥是全1矩阵?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python numpy模块的np.empty((3,4))为啥是全1矩阵?相关的知识,希望对你有一定的参考价值。
见图:其他参数显示都是垃圾值,只有3,4显示是全1矩阵

估计是前面用np.ones()生成过同形的矩阵。
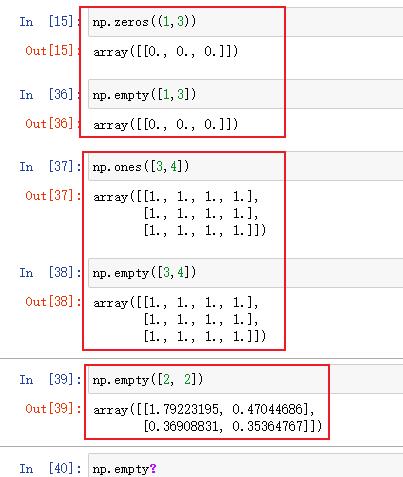
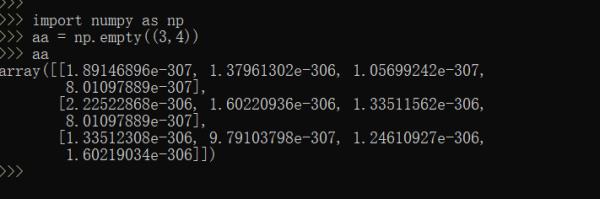
是挺奇怪的,我就是出不来你的结果。
http://docs.scipy.org/doc/numpy/reference/generated/numpy.empty.html
python的 numpy库学习总结和介绍(超详细)模块
目录
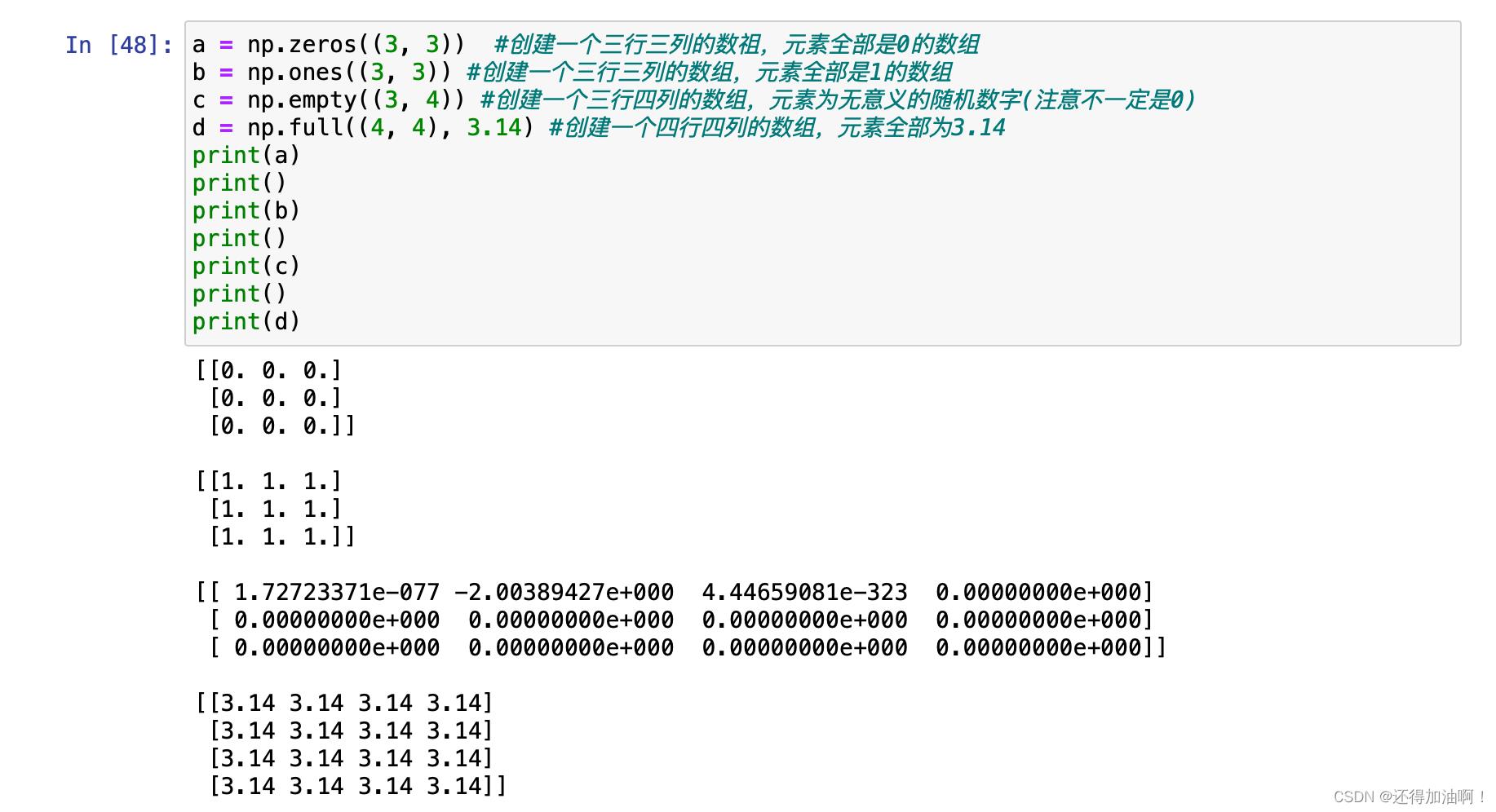
2.np.zeros(),np.ones(),np.empty(),np.full(),传递对应的形状参数,来创建一个初始化的数组
3.np.linspace()与np.arange()的使用
4.numpy求解线性方程组 ---np.linalg.solve()
前言
python作为一个胶水语言,如今在数值科学计算,数据分析,机器学习等方面作为一个常用的工具发挥着重要的作用,其中自然少不了python的numpy库的应用,今天我们就一起来探索numpy库对数据的相关操作与用法,也可以为后面pandas库和matplotlib库做好充分的准备基础

numpy是什么?
numpy库是是用python进行数值计算、矩阵运算、数据处理、数据分析的常用库,也是进一步学习pandas库的基础,既然是去对数据进行处理,我把numpy对数据的操作归纳为四个部分来进行介绍,分别是1.创建数据容器 2.操作容器 3.读取与修改数据4.操作数据 。下面我们来对这四个部分来分别进行详细介绍
一、创建数据容器
既然要分析数据,那我们肯定得先用一个容器把数据装起来吧,所以第一步就是创建数据容器。
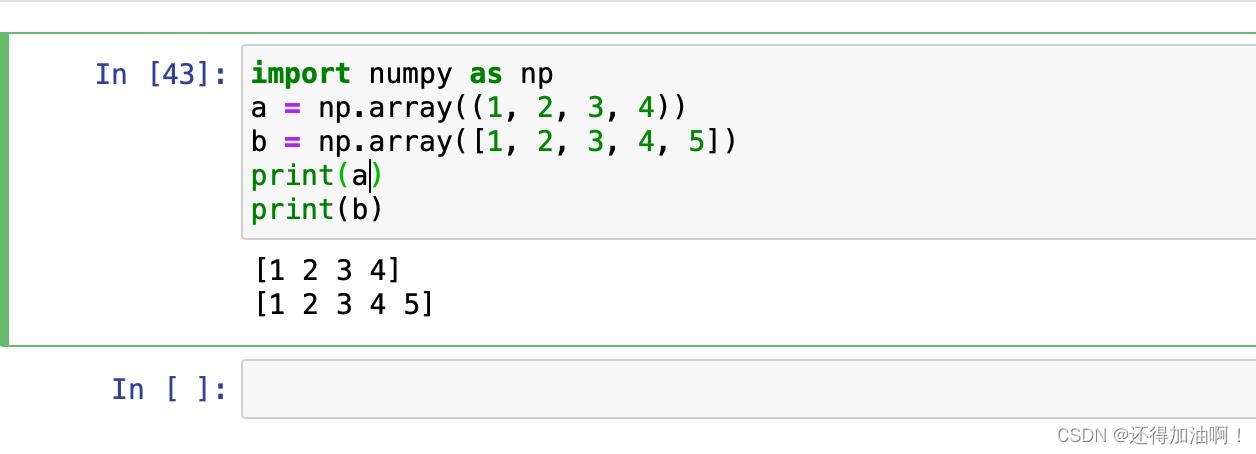
1.np.array(),通过传递一个列表,元祖来创建
示例如下:
2.np.zeros(),np.ones(),np.empty(),np.full(),传递对应的形状参数,来创建一个初始化的数组
示例如下:
3.np.linspace()与np.arange()的使用

4.运用np.random来创建随机数数组
1.np.random.rand(),根据传入形状参数创建元素为来自[0,1)的随机数的数组
2.np.random.randn(),根据传入形状参数创建元素为满足标准正态分布的数组
3.np.random.random(),根据传入形状参数创建元素为来自[0,1)的随机数的数组
4.np.random.randint(),根据传入的取值范围和形状参数创建元素为来自范围内的随机整数的数组
5.np.random.normal(),根据传入的数学期望、方差和形状参数来创建元素满足对应正态分布的数组
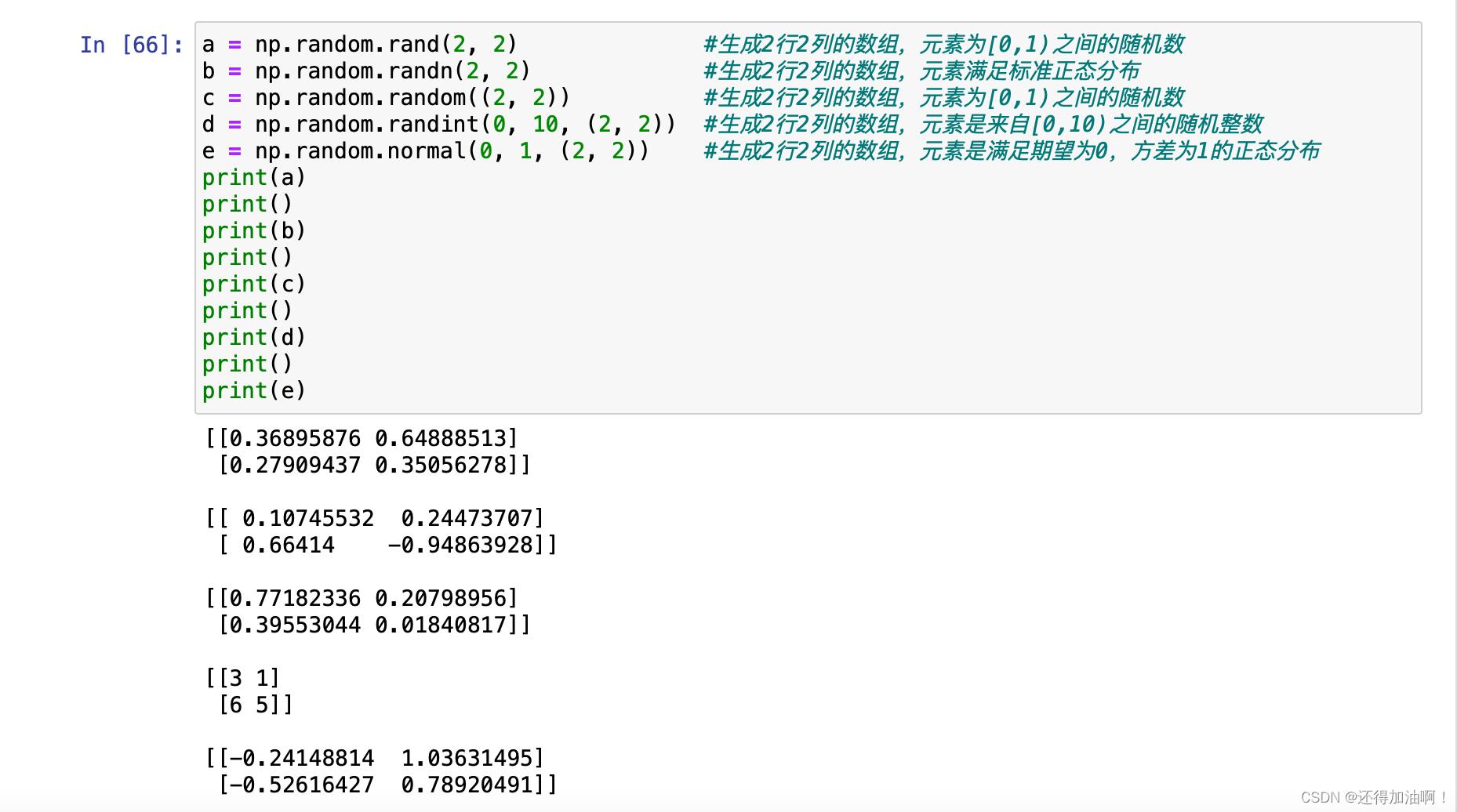
注意:np.random.rand()和np.random.randn为直接传入形状参数数字,不需要以元祖或者列表的形式去传入维数,且以上函数可以不传入任何参数使用,用来生成一个满足条件的随机数。
5.数组的常见属性
数组常见的属性有四个:shape--形状,ndim--数组维度,size--数组元素的个数,dtype--数组元素的数据类型,示例如下:
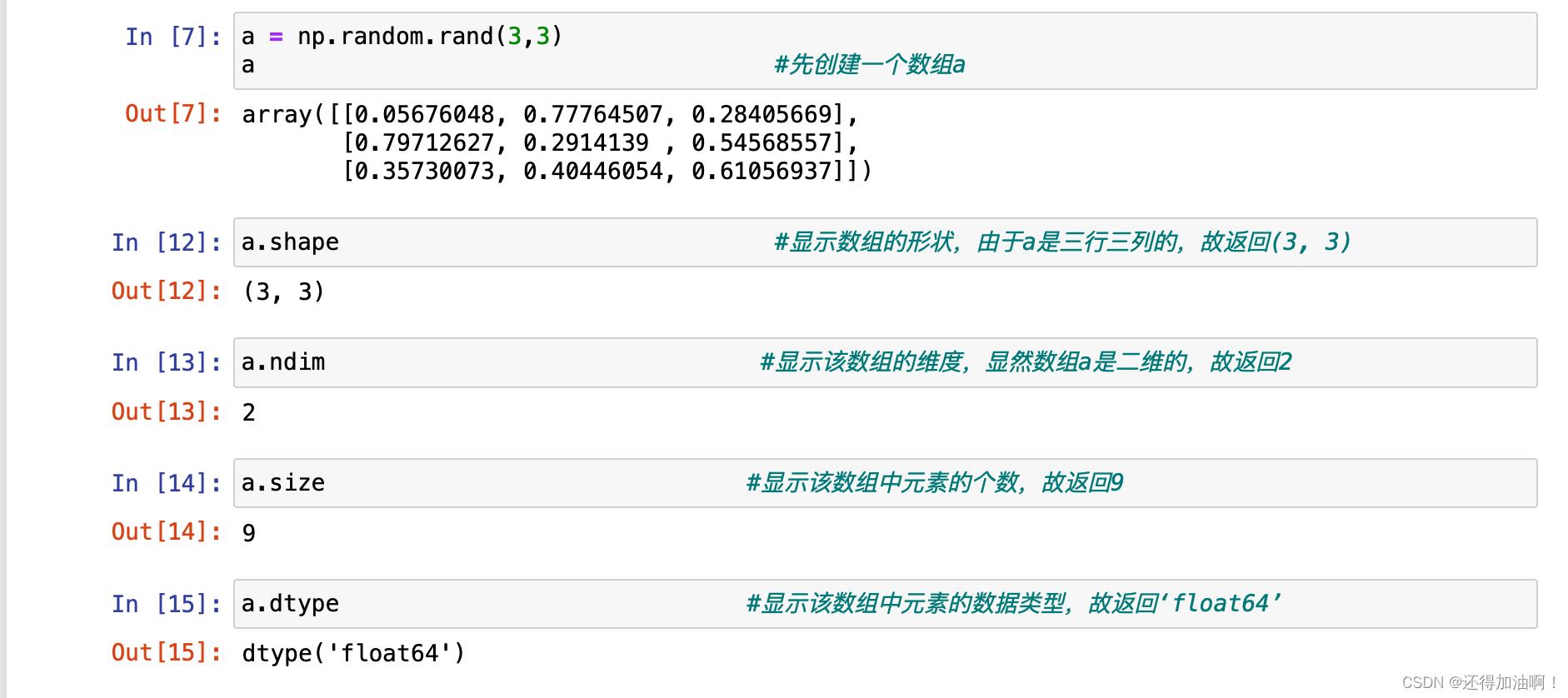
其中的dtype属性一般最值得注意,因为数组只能存储一种数据类型,存在和C语言类似的强制数据类型转换,我们可以利用astype()方法传入想要转化的数据类型来进行操作,如下:
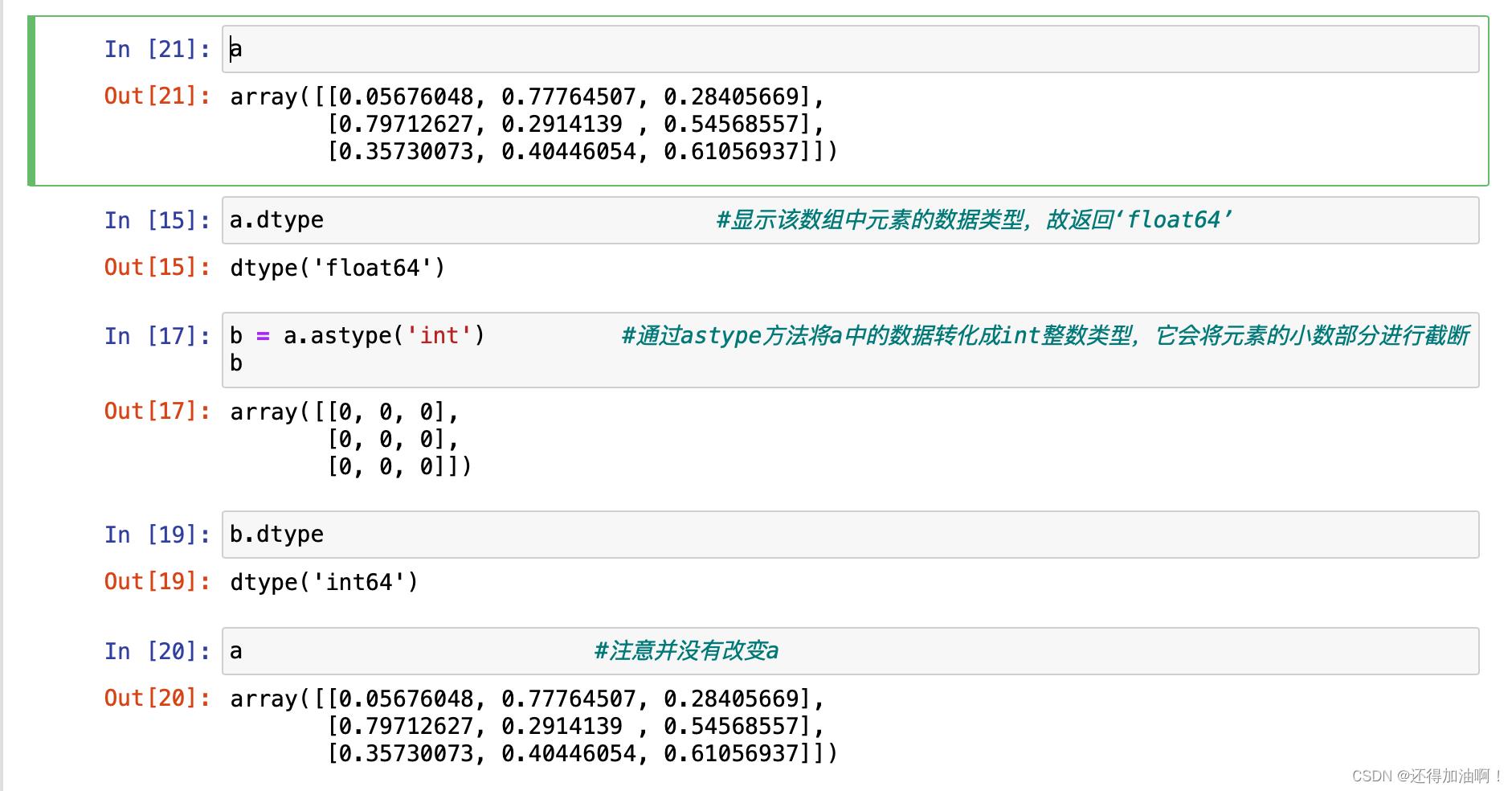
注意:astype()方法并非原地修改,而是在不修改原数组的基础上返回一个新数组.
二、操作数据容器
好了通过上面我们已经创建了我们的数据容器--数组,但是有时候我们可能需要把一个数据容器分割成多个数据容器,或者把多个数据容器合并成一个数据容器,这就要讲到操作数据容器,其中包括数据的变形与数组的拼接和分裂
1.数组的变形
数组的变形主要是用数组的reshape()方法来实现,只需以数组或者列表的方法传入形状参数便会返回对应的数组(原数组并没有改变,且返回的数组是原数组的副本视图),示例如下:

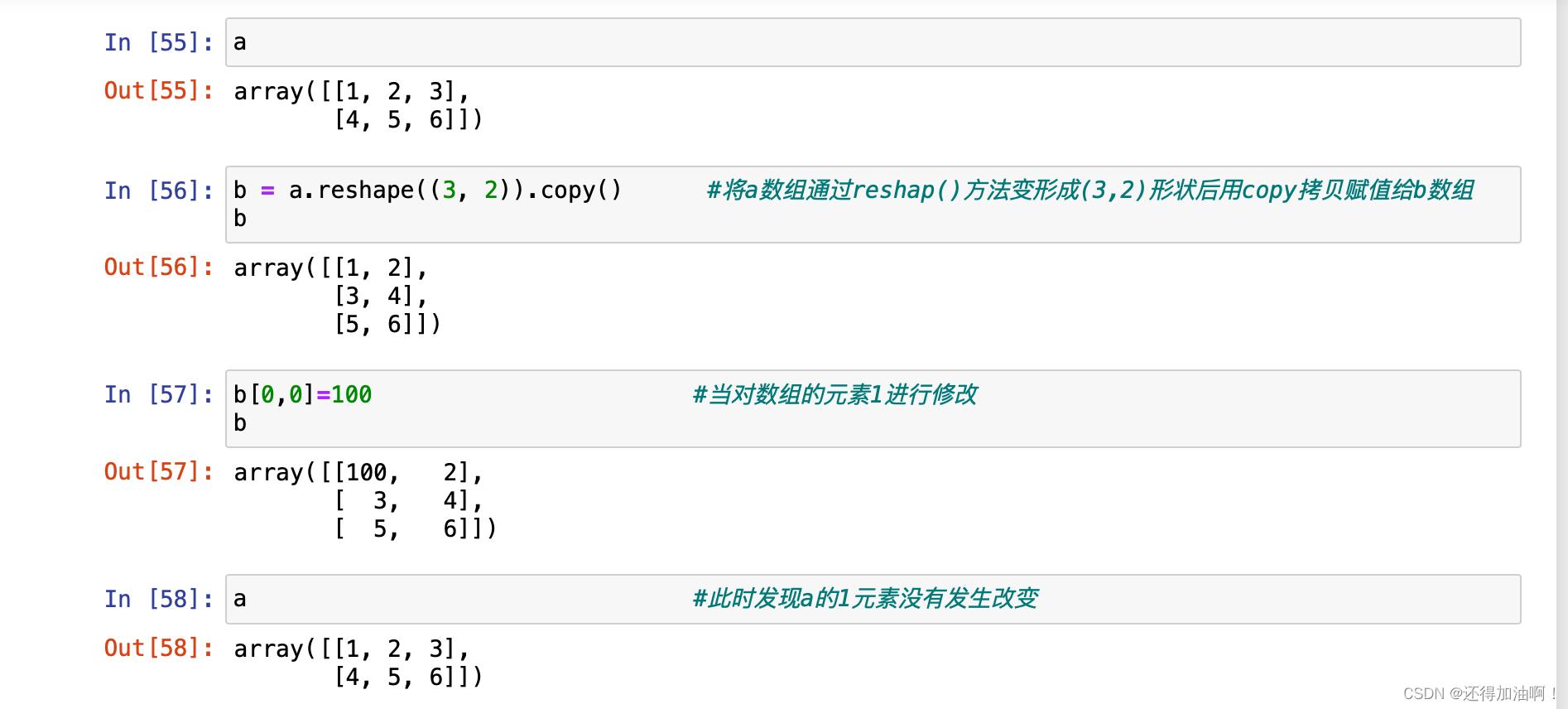
注意:通过reshape()方法返回的为原数组的副本视图,即在返回数组上进行相关操作,都会反应在原数组上面,示例如下:

这种返回副本视图的方式,有时候为我们做数据分析提供了一些便利,在后续数据分析的实战你会感觉的到,但是有时候你可能会想要避免这种情况,比如要用python进行一些矩阵相关的算法实现时,那么你可以使用python的copy方法,示例如下:
2.数组的拼接
数组的拼接就是将二个数组拼接在一起,主要是使用numpy库的concatenate()函数,它的第一个参数是传入一个列表或者元祖,里面包含着要进行拼接的数组,另外一个则是轴参数,axis,要详细的了解axis参数可以参考我的另一篇博客:对python的numpy库和pandas库相关方法和函数的axis参数的理解
下面直接在示例中对concatenate()函数进行介绍:

另外numpy库还有二个用于数组拼接的函数,分别是hstack()函数--水平拼接,vstack--垂直拼接,他们只需要传入包含拼接数组的列表或者元祖即可,hstack相当于指定了axis=1,按列进行拼接,vstack相当于指定了axis=0,按行进行拼接,示例如下:

注意:concatenate()函数和hstack()函数、vstack()函数也是在不改变原数组的情况下返回原数组的副本视图,如果想要避免需要使用copy()方法进行拷贝后赋值。
3.数组的分裂
数组的分裂就是根据指定的分裂点来对数据进行分裂,对于一维的数组通常使用numpy库的split()函数,他只需要二个个参数,一个是要进行分割的一维数组,另一个就是分割点(这里可能会用到一些数组取值的地方,如果不了解可以先看一下下面的“获取和修改数据”),示例如下:

对于一维数组我们一般使用split()函数,对于二维我们一般使用hsplit()--水平分割和vstack()--垂直分割。对hsplit()函数,我们只需要传入要分割的数组和对应的分割列索引。对vsplit()函数,我们只需要传入要分割的数组和对应的分割行索引.示例如下:
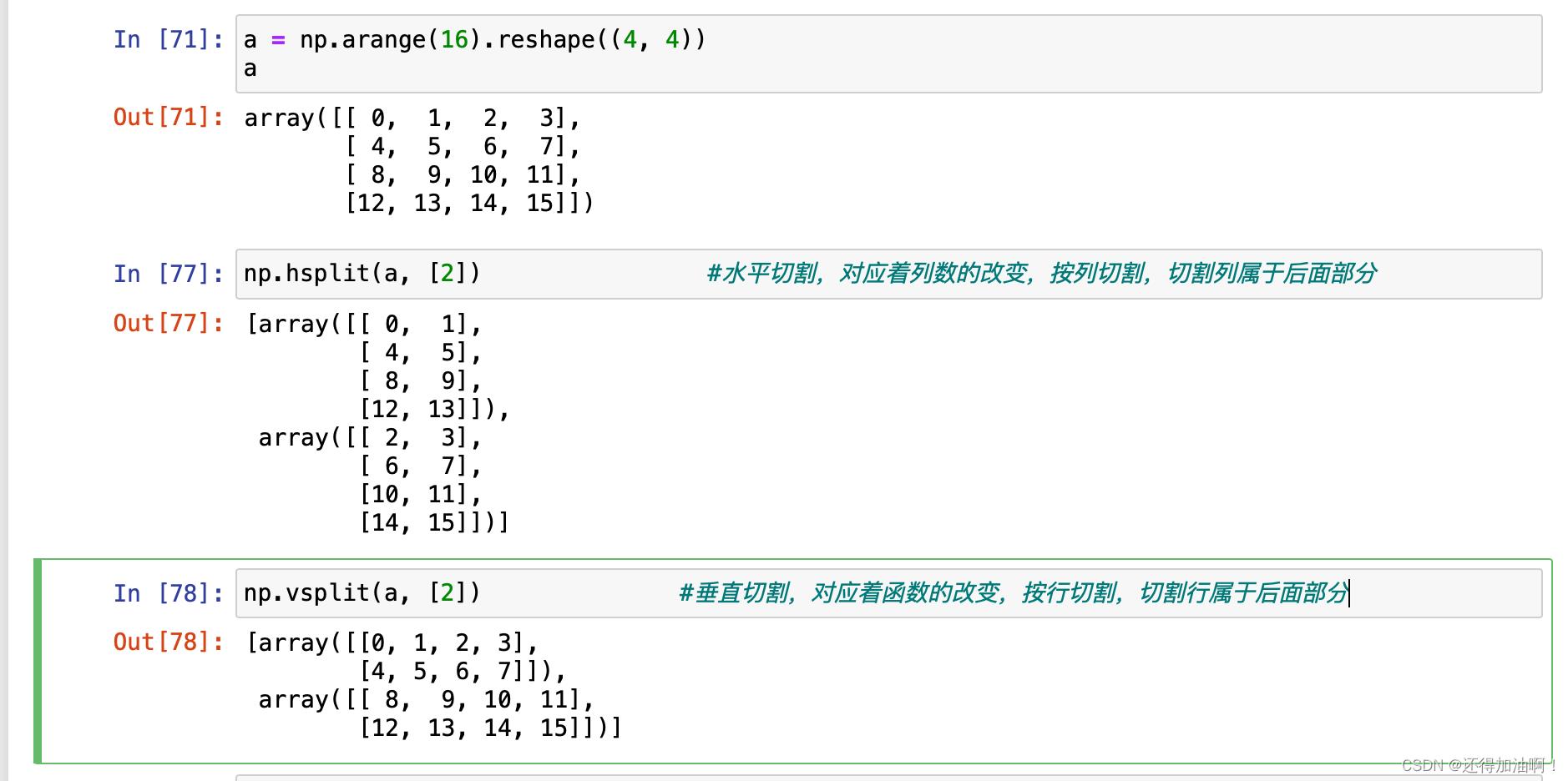
注意:数组的分裂返回的数组也是原数组的副本视图。
三、读取和修改数据
将数据用数据容器数组装起来以后,自然少不了数据的存取与修改了,接下来来介绍对数组中数据的读取与修改。
1.下标索引
了解过其他编程语言的同学对下标索引应该十分熟悉,直接看示例:
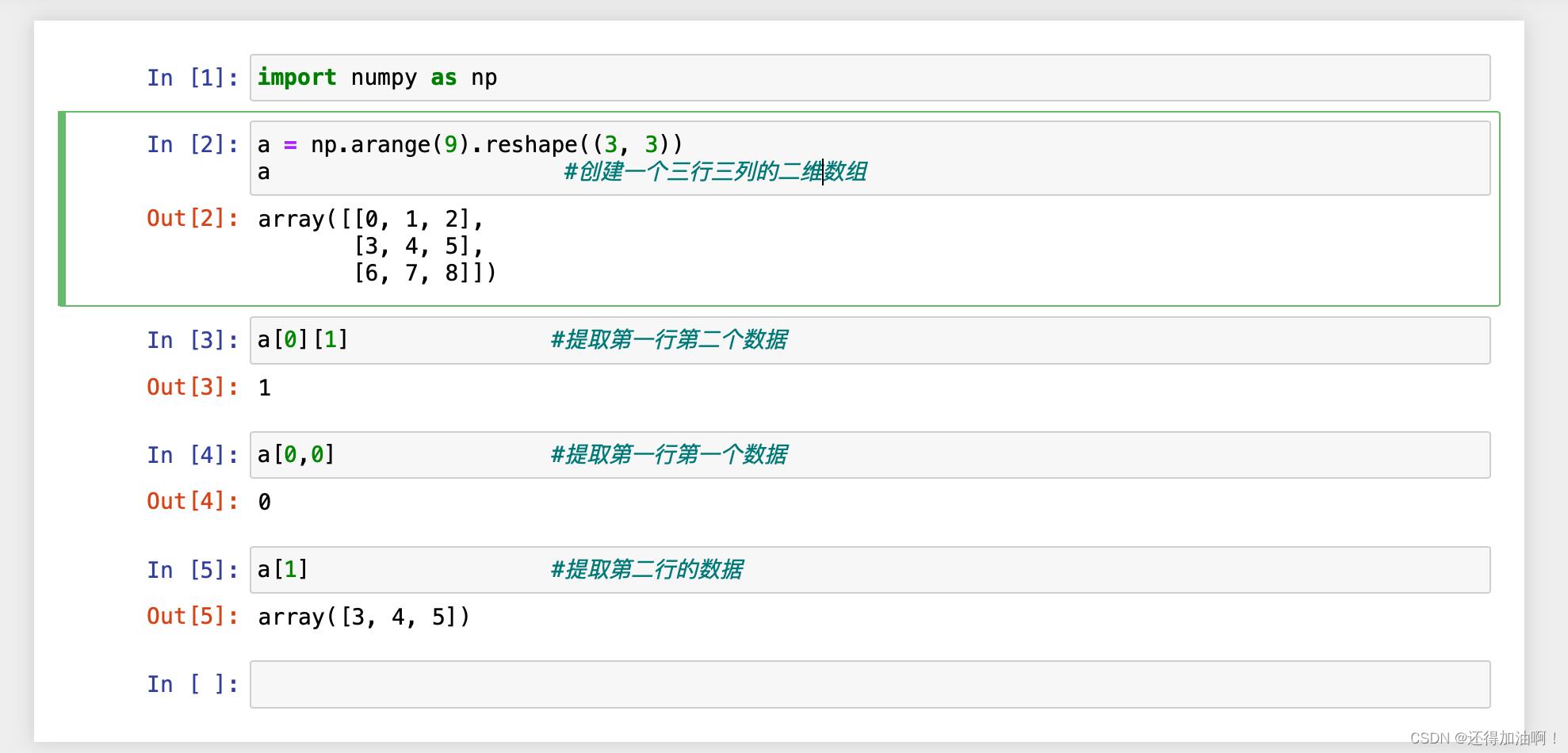
这些就是下标索引的常用方法,十分快捷有效,但是想要重分使用python的简洁与方便,可以使用python的切片对数据进行索引
2.切片索引
话不多说,直接上例子:

3.掩码索引(布尔型索引)
所谓掩码就是通过传入一个布尔类型的数组来进行索引,会返回对应位置为True的元素
示例如下:

4.花哨的索引(有的书翻译成花式索引)
花哨索引是指传入一个数组,数组内包括要进行索引的数据对应的下标,返回的是一个新的数组(下标索引返回的是一个数据)
直接上例子:

5.组合索引
所谓组合索引就是将上面的四种索引方法组合起来使用,我们来看一下常用的组合索引例子:

注意:上述索引方法,除花哨索引返回的是一个新的数组,其他索引方法返回的都是原数组的副本视图。
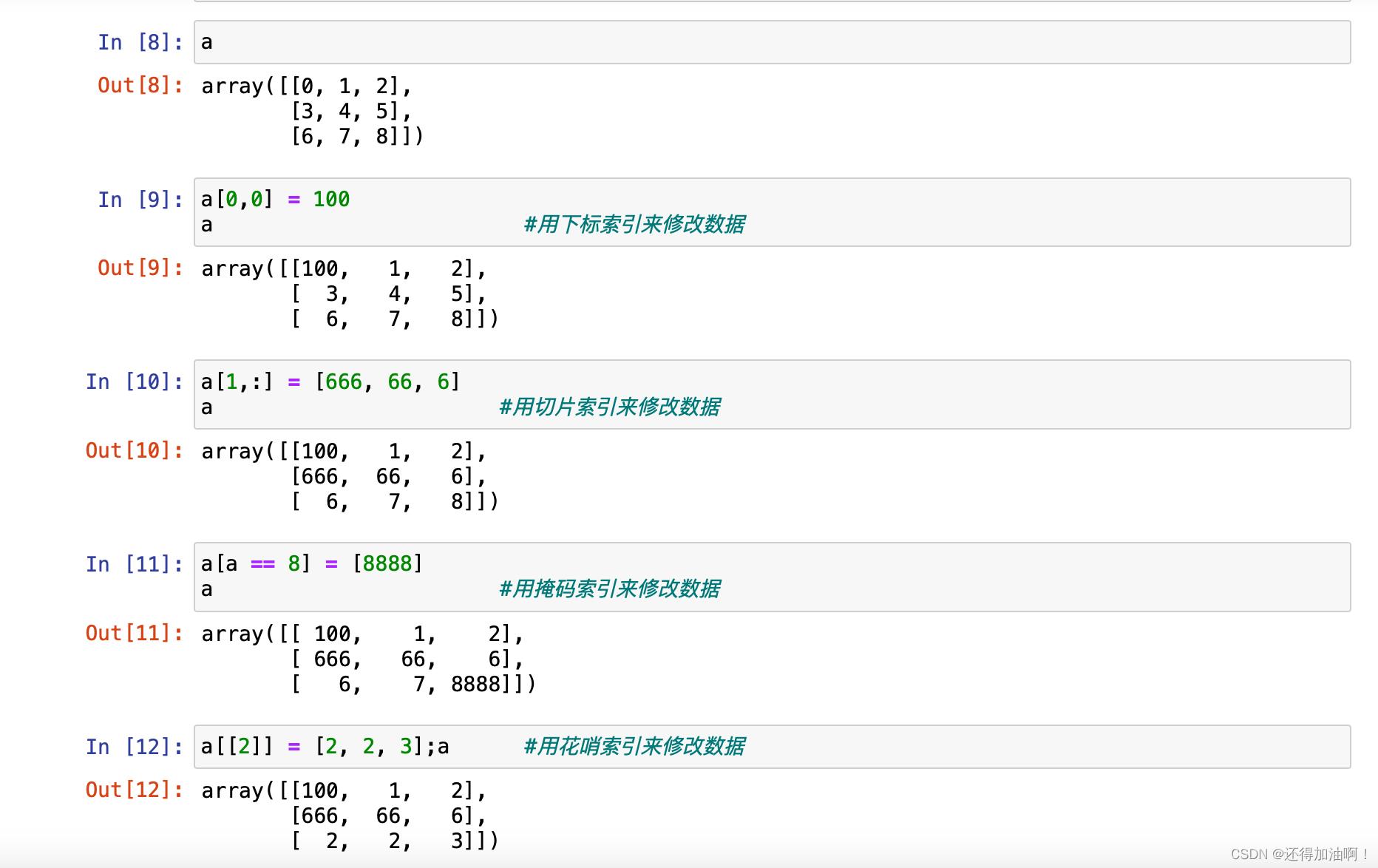
6.数据的修改
有了数组的获取,修改就十分容易,只要对获取的数据进行重新赋值就可以,示例如下:
四、操作数据
对数据的操作,主要包括三个部分:通用函数,聚合,排序,下面来一一进行介绍
1.通用函数
python的numpy库的数组运算是和R语言类似的,具有向量性,我们通过数组的加减乘除来说明这一点:
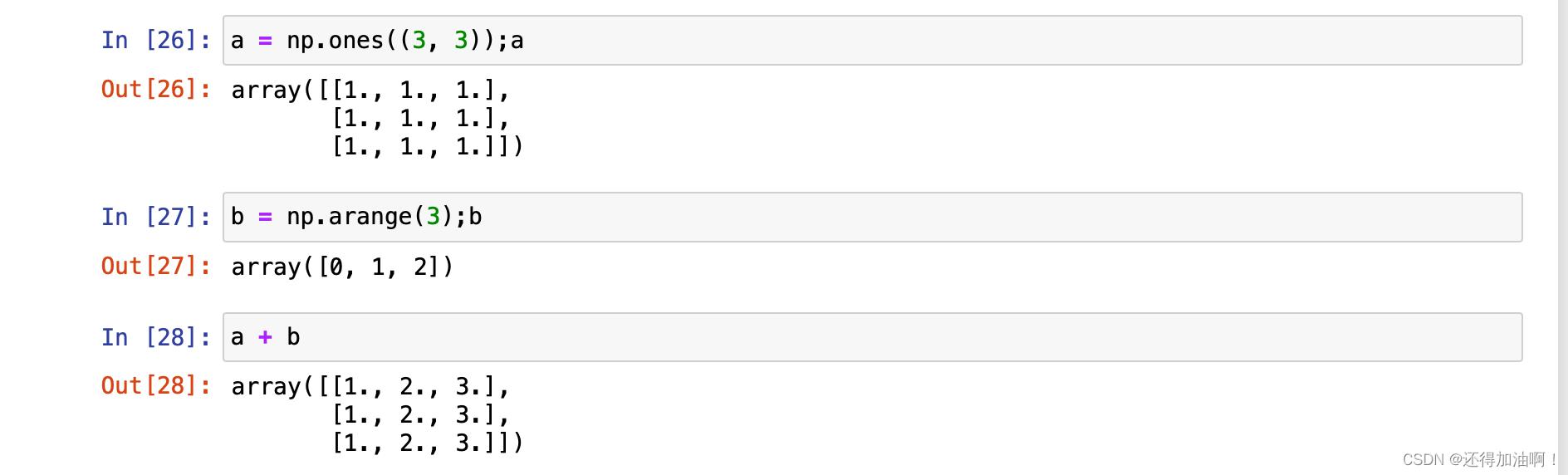
当二个数组形状相等时则就是二个数组对应位置的数据做对应的运算:

当二个数组形状不同是,则此时遵循广播规则,关于广播规则详细可以查看我的另外一篇博客:numpy库数组运算的广播规则,这里就简单看几个例子

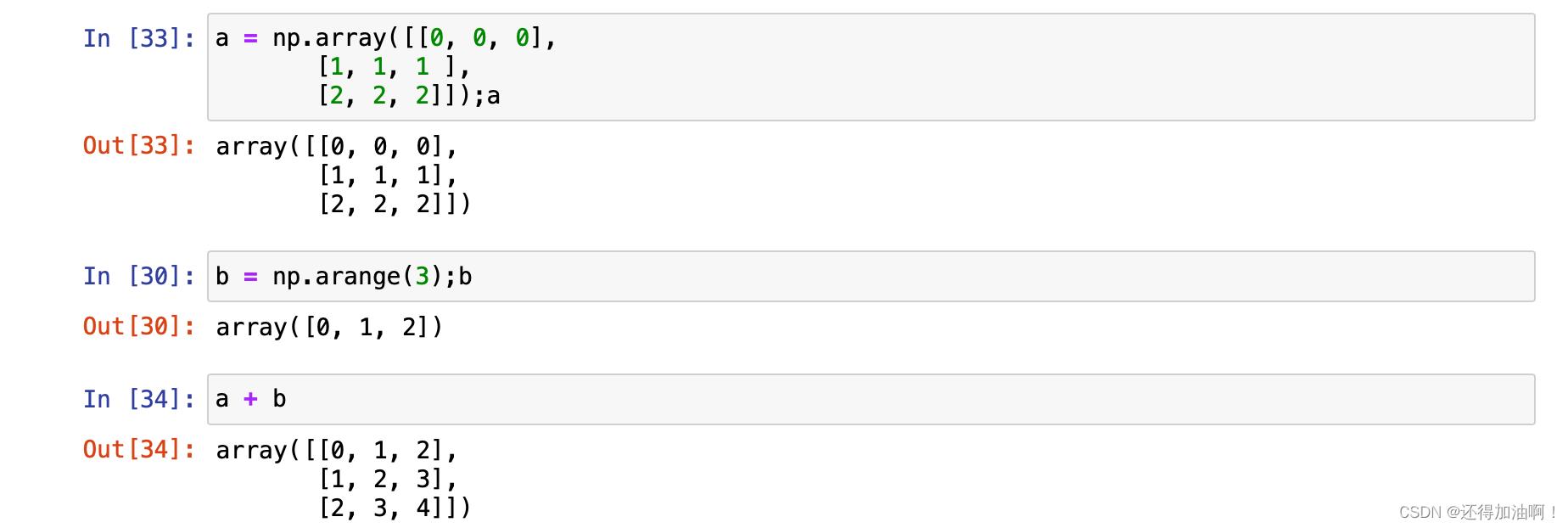
这里的+,-,*,/ 其实是numpy库通用函数的简化形式,其具体及其补充应如下:


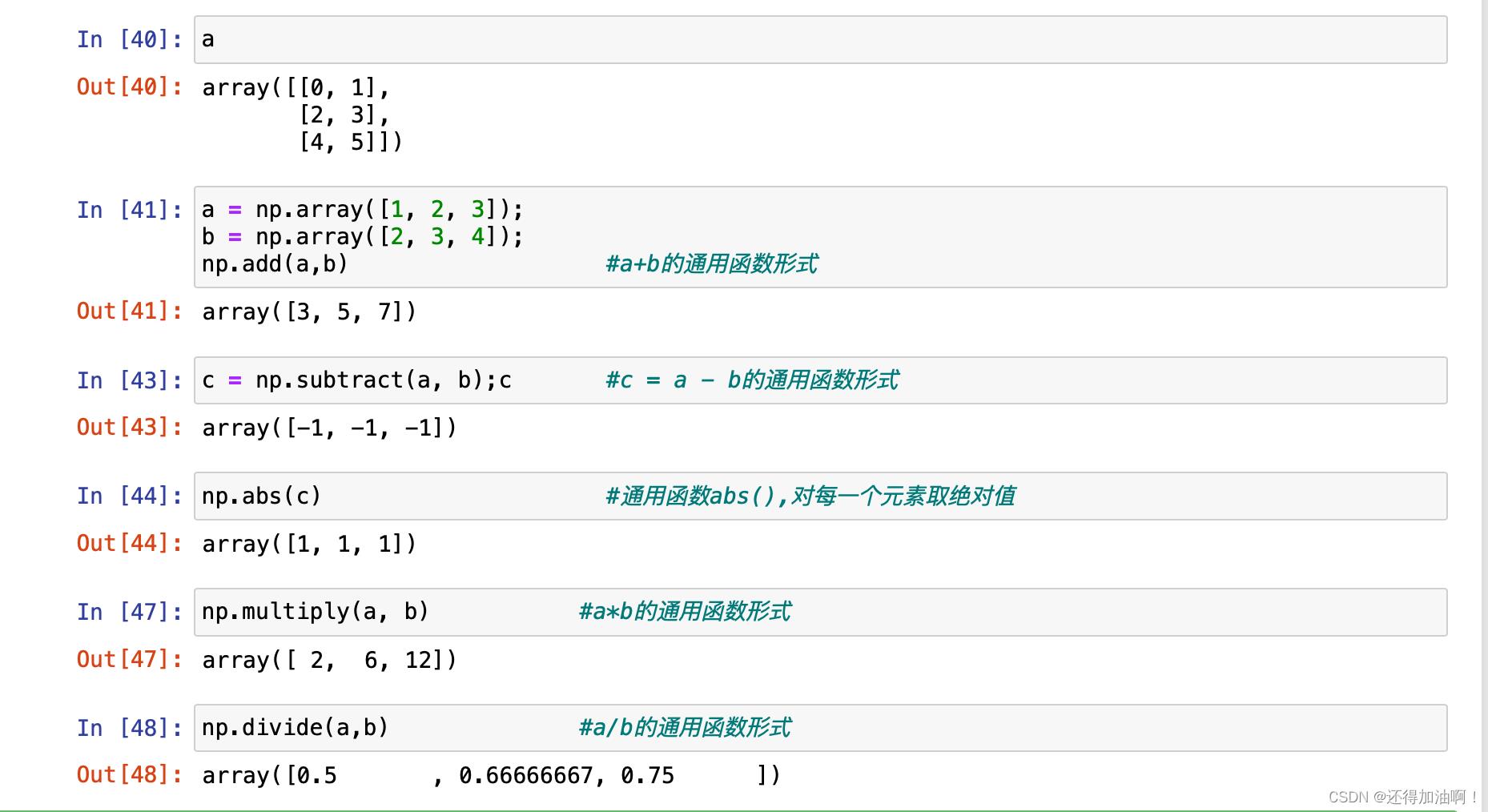
下面展示一些通用函数的常用示例:
2.聚合操作
聚合操作在数据分析与统计学中经常用到,就是得到一个整体的统计量,对数据整体进行一个概括性的描述,numpy中常见的用于数据的聚合方法如下:

下面来展示一些常用的聚合方法:

还有二个用于布尔类型的数组的常用方法any()和all(),any用于检测数组中是否存在一个或者多个True,all()用于检测数组中是否都是True,示例如下:

3.数组元素的排序
python有自带的sort排序可以使用在数组对象上,但是numpy库也有自己的sort方法,它是基于C语言的快速排序算法编写的,所以在面对大量的数据时,运行速度会比python自带的sort方法更快。对一维,可直接使用,对二维数组则需要传入轴参数axis。示例如下:
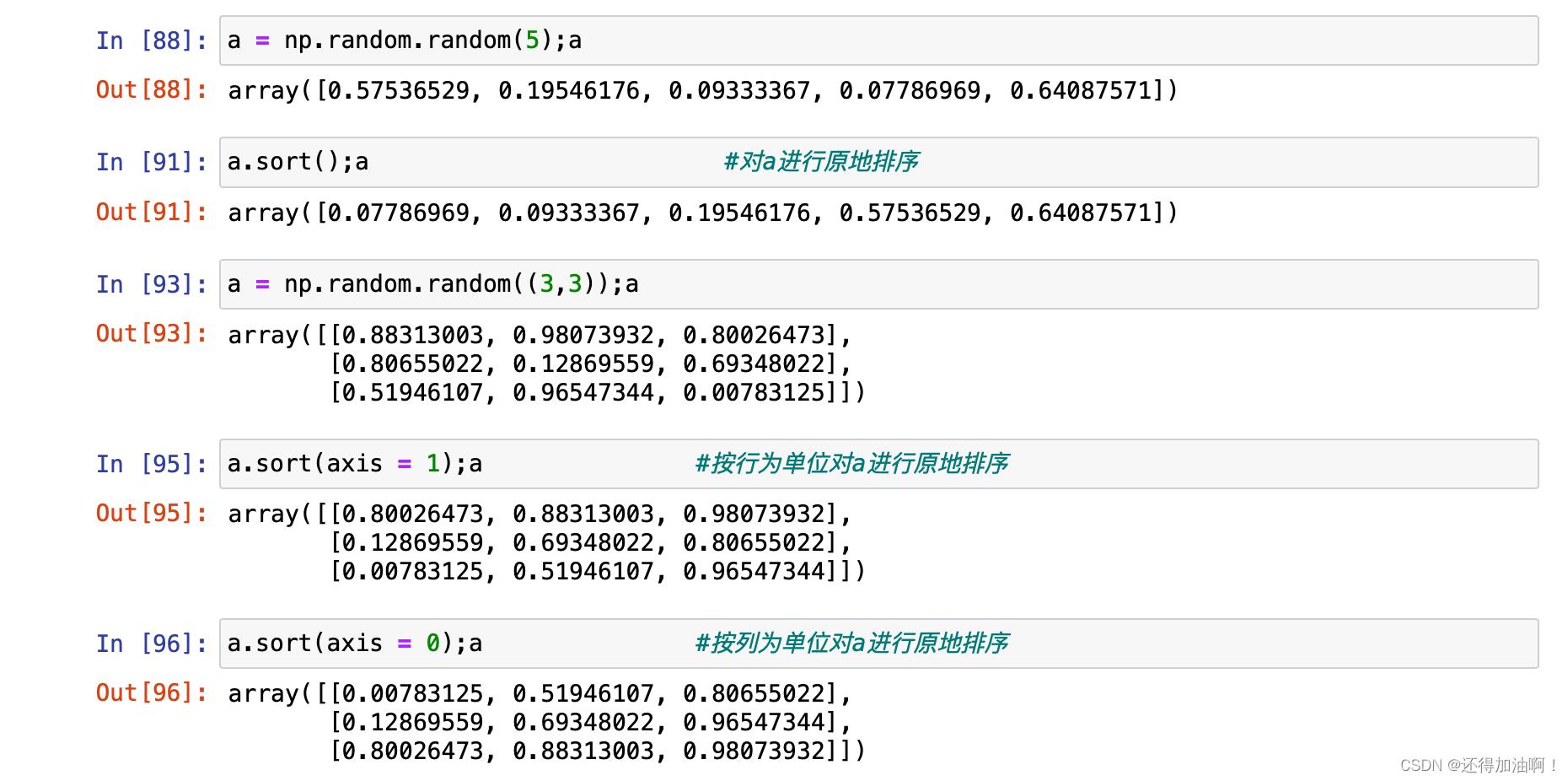
注意:sort方法是对数组进行原地排序,如果想在不改变原数据的情况下返回一个排序好的新数组(不是原数组的副本视图),则可以使用np.sort()函数。
如果想要获得原始数组排序好的索引值可以使用argsort()方法或者np.argsort()函数,示例如下:

五.从线性代数的角度来使用numpy
numpy中有一个linalg模块,其中包括了一些我们所学的线性代数的操作,下面我对其中一些常用的操作进行介绍
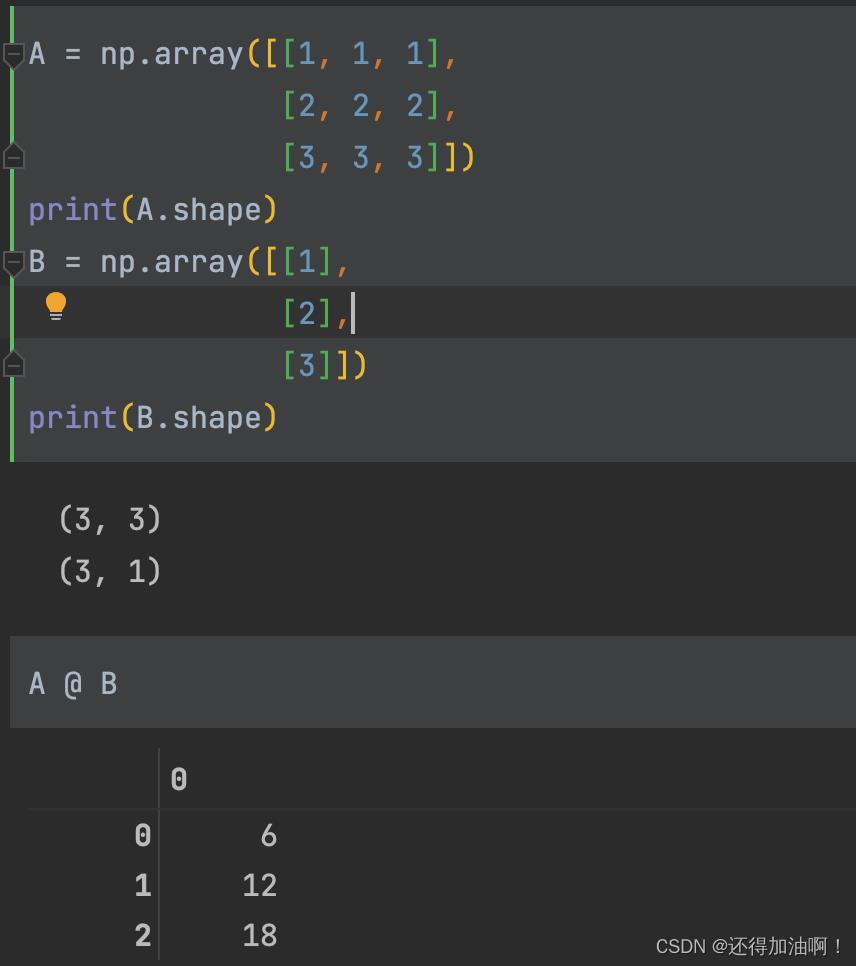
1.矩阵的乘法
要让二个array对象进行矩阵的乘法首先需要它们满足线性代数中进行矩阵乘法的条件,然后使用@ 即为进行线性代数中矩阵的乘法,示例如下:
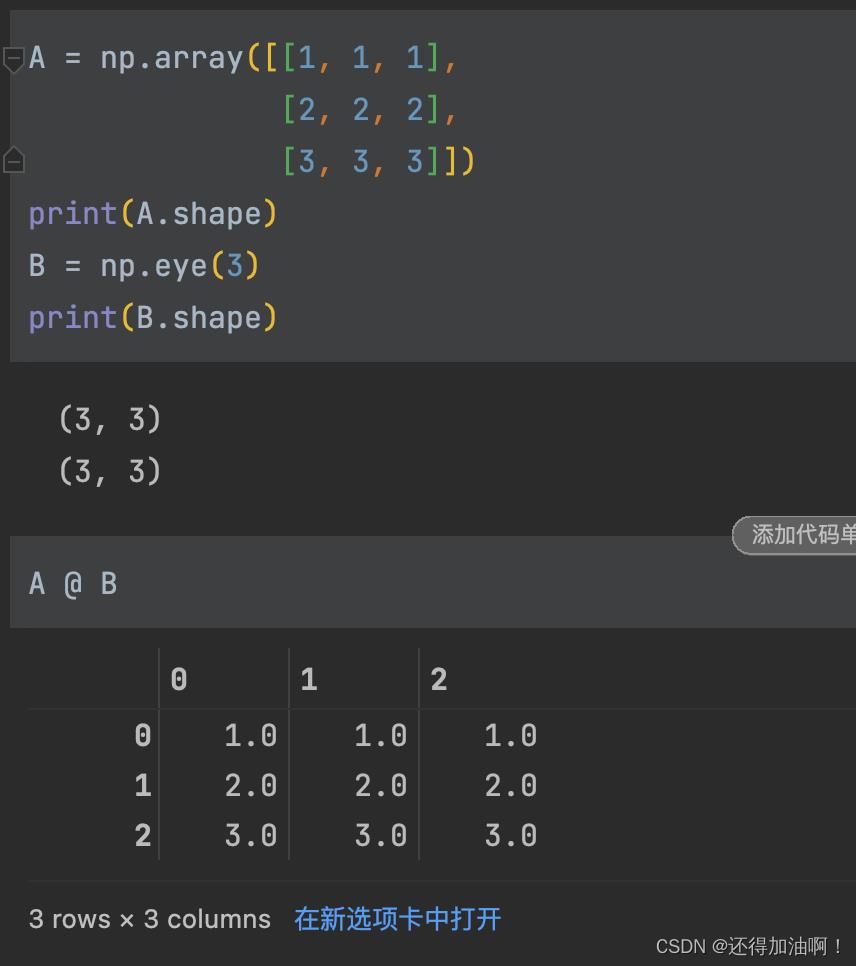
2.矩阵的转置和逆
求矩阵的转置:
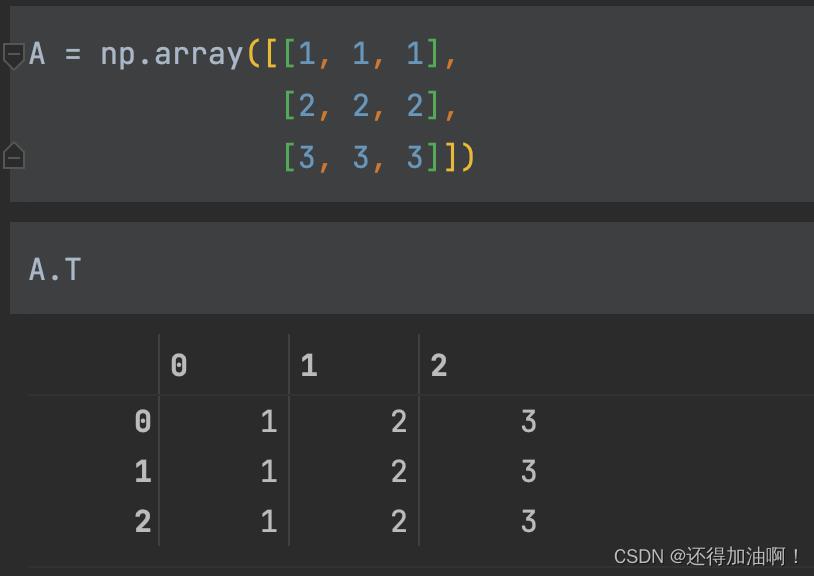
求矩阵的逆(注意前提是矩阵有逆,例如上面的矩阵A就是没有逆的,它行列式为0): 
3.numpy的多项式拟和---np.polyfit()
虽然这个不是线性代数的部分,但是还是想要说说
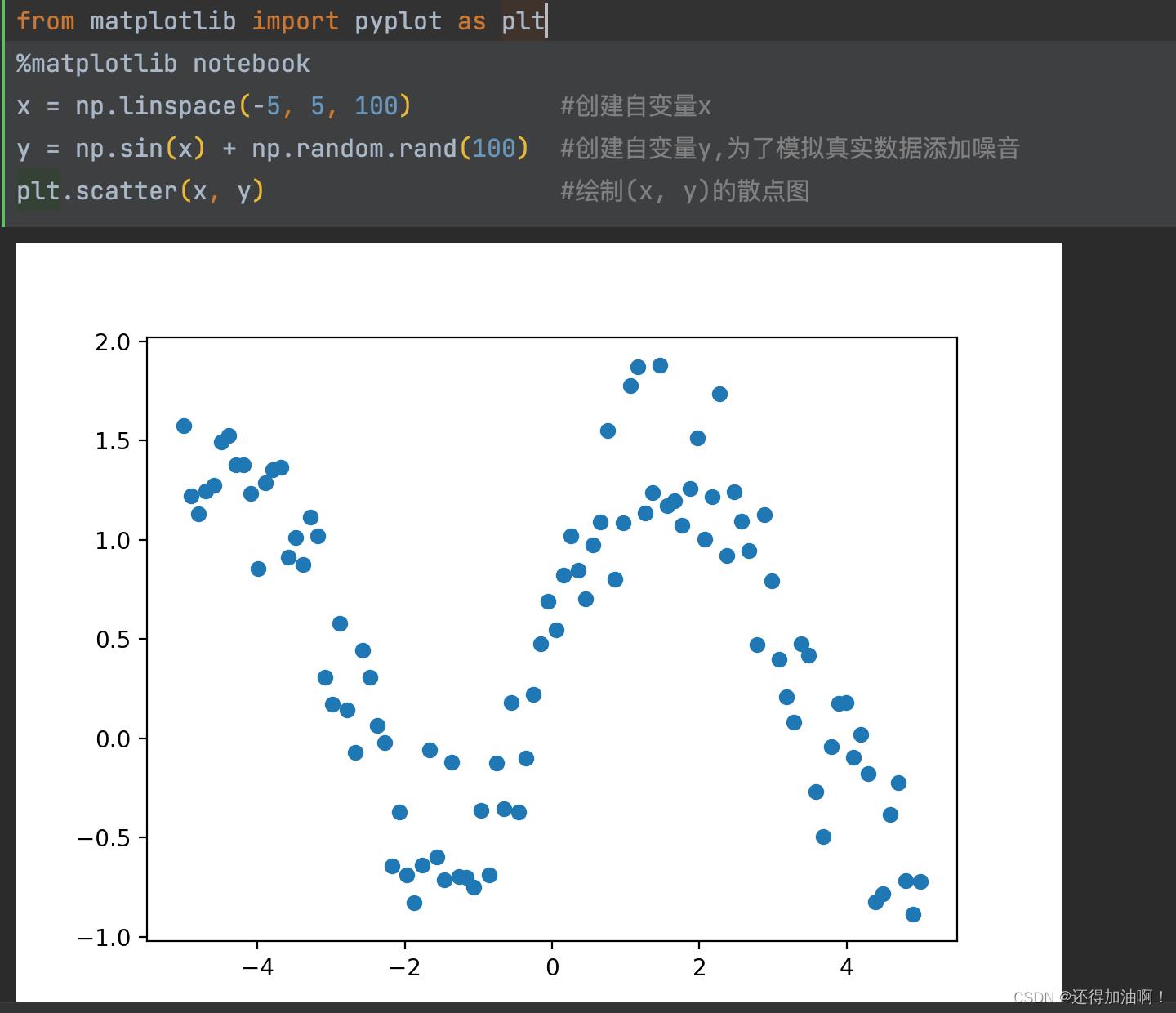
数学支撑:任何可微连续的函数,都可以用一个N次多项式来估计,而比N次幂更高阶的部分为无穷小可以忽略不计
即:对于一堆数据点(x, y),可以只根据这些数据,找出一个多项式函数,使得函数画出来的曲线和原始数据曲线尽量匹配,示例如下:
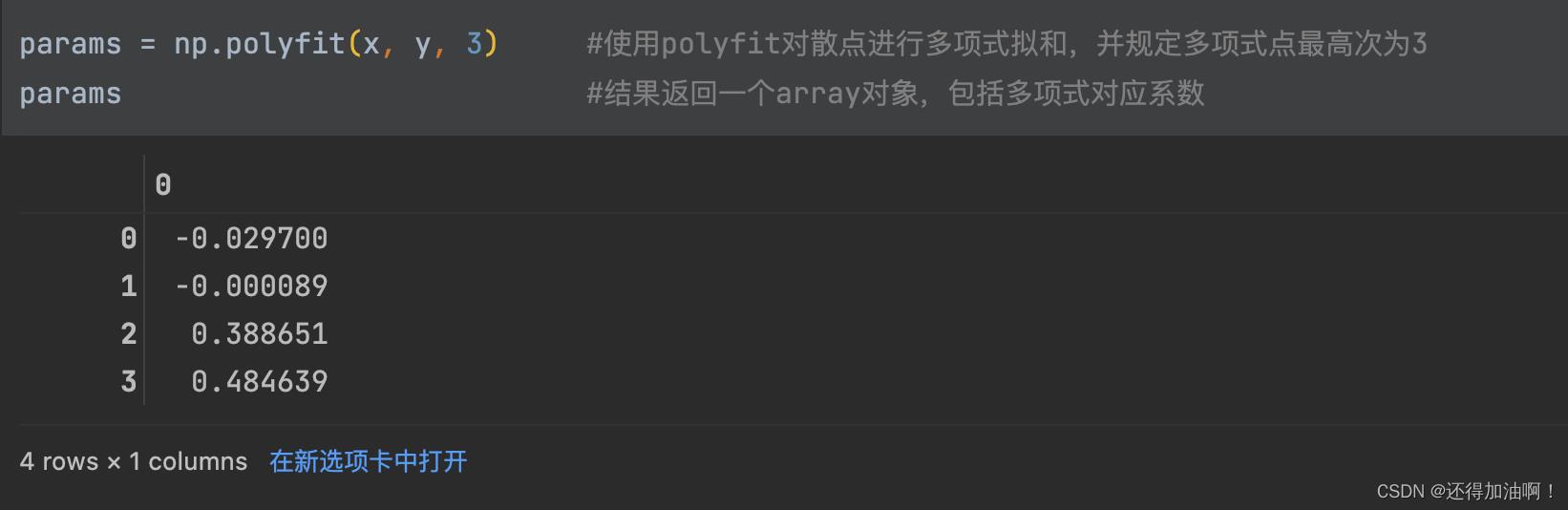

4.numpy求解线性方程组 ---np.linalg.solve()
由线性代数知识,一个线性方程组可以表示为AX = b的形式,由此可以调用np.linalg.solve来对其进行求解,示例如下:
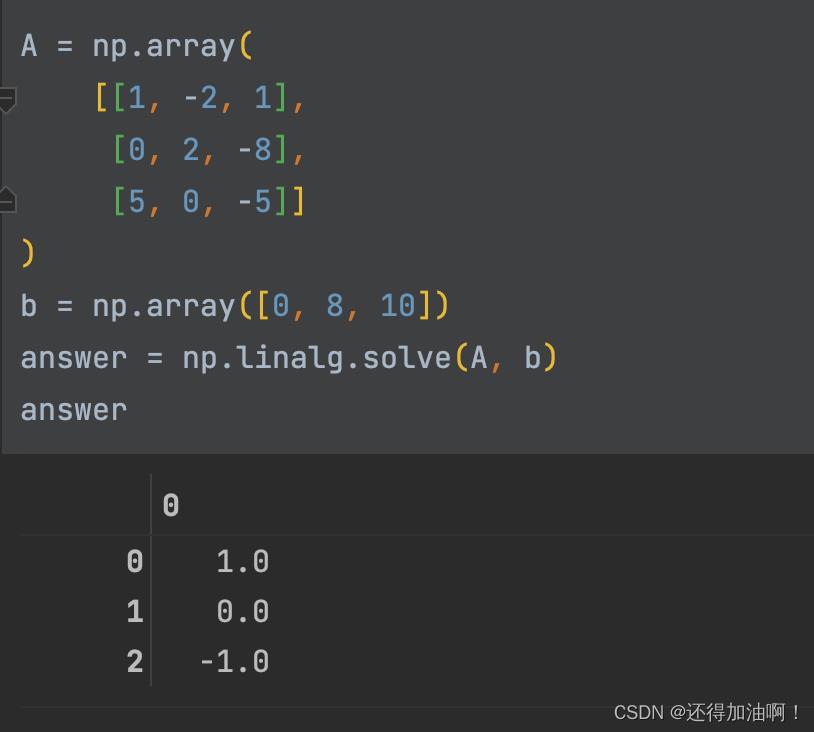
由于该线性方程具有唯一解,我们可以用逆矩阵的解法来进行检验:
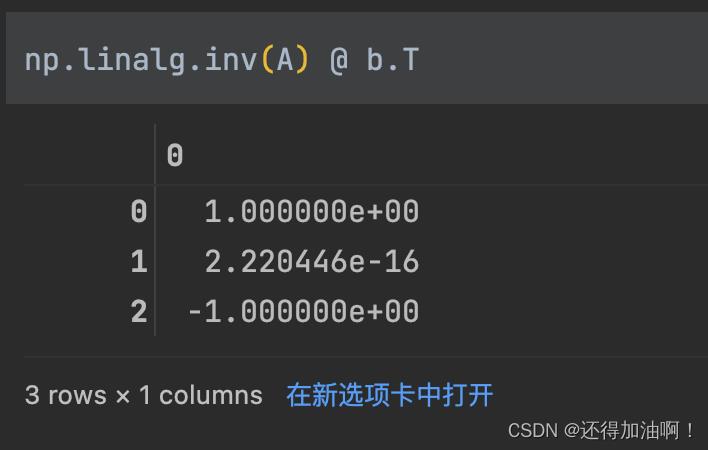
验证应该和上述方法所求的解是相同的,上述逆矩阵求解的结果是由于计算机对浮点数的存储机制所造成的。
六.数组的读取与存储
对array数组对象的读取与存储主要有四种方法:
1.np.load(filename):从.npy或者.npz文件中加载numpy数组,如果文件后缀是.npy返回单个数组,如果文件后缀是.npz返回多个数组的字典
2.np.save(filename, arr):将单个numpy数组保存到.npy文件中
3.np.savez(filename, arra=arra, arrb=arrb):将多个numpy数组保存到.npz未压缩的文件格式中
4.np.savez_compressed(filename, arra=arra, arrb=arrb):将多个numpy数组保存到.npz压缩的文件格式中
示例如下:

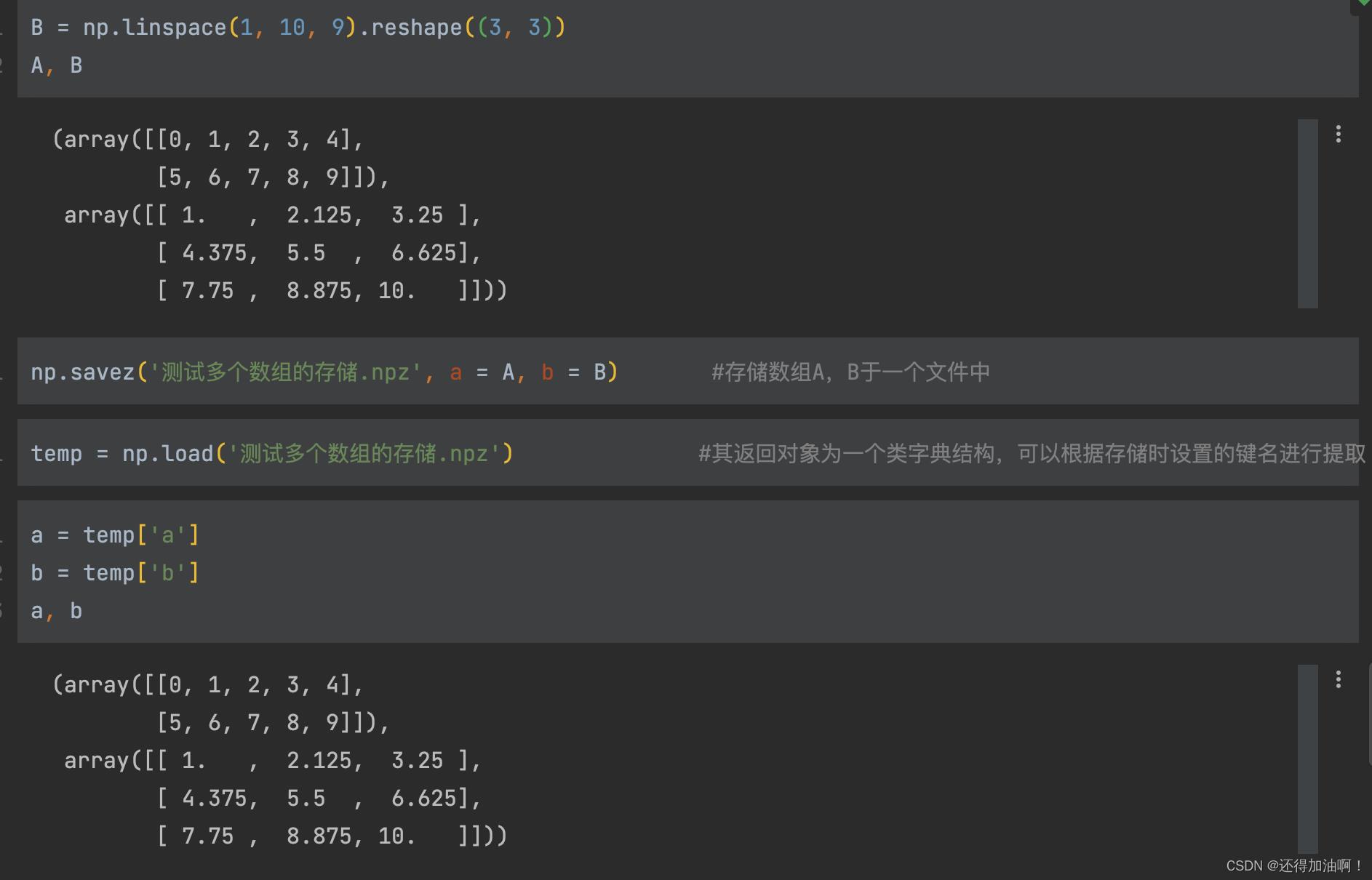
np.savez_compressed的使用和np.savez相同 。
总结
以上就是我对python的numpy库的常用操作的了解与学习笔记,如果文章有错误和一些常用操作的缺少希望大家在评论区给予意见,如果有问题也可以在评论区进行询问,我会及时给予回复,大家一起进步和提高!
以上是关于python numpy模块的np.empty((3,4))为啥是全1矩阵?的主要内容,如果未能解决你的问题,请参考以下文章
python pandas numpy matplotlib 常用方法及函数
用实践带领你进入numpy的世界——:numpy基本数组创建函数