Mysql数据库基础
Posted 乐之之
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql数据库基础相关的知识,希望对你有一定的参考价值。
一、关系
将实体与实体的关系,反应到最终数据库表的设计上来:
将关系分成三种:
- 一对一
- 一对多(多对一)
- 多对多
所有的关系都是指的表与表之间的关系。
1、一对一
一对一:一张表的一条记录一定只能与另外一张表的一条记录进行对应;反之亦然。
学生表:姓名,性别,年龄,身高,体重,婚姻状况,籍贯,家庭住址,紧急联系人。
| id | 姓名 | 性别 | 年龄 | 体重 | 身高 | 婚姻 | 籍贯 | 住址 | 联系人 |
|---|---|---|---|---|---|---|---|---|---|
其中姓名、性别、年龄、身高、体重属于常用数据
但是婚姻、籍贯、住址、联系人属于不常用数据
如果每次查询都是查询所有数据、不常用的数据就会影响效率、 实际又不用。
-
解决方案:将常用的和不常用的信息分离存储,分成两张表
-
常用信息表
-
| id | 姓名 | 性别 | 年龄 | 体重 | 身高 |
|---|---|---|---|---|---|
-
不常用信息表:
-
保证不常用信息与常用信息一定能够对应上(找一个具有唯一性的字段来共同连接两张表)
| id | 婚姻 | 籍贯 | 住址 | 联系人 |
|---|---|---|---|---|
2、一对多
一对多:一张表中有一条记录可以对应另外一张表中的多条记录;但是返回过,另外一张表的一条记录只能对应第一张表的一条记录。这种关系就是一对多或者多对一。
母亲与孩子的关系:
妈妈表:
| id | 名字 | 年龄 | 电话 |
|---|---|---|---|
孩子表:
| id | 名字 | 年龄 | 电话 |
|---|---|---|---|
以上关系:一个妈妈可以在孩子表中找到多条记录(也有可能是一条);但是一个孩子只能找到一个妈妈:是一种典型的一对多的关系。
但是以上设计,解决了实体的设计表问题,但是没有解决关系问题,孩子找不出妈,妈也找不到孩子。
解决方案:
-
在某一张表中增加一个字段,能够找到另外一张表的中记录
-
应该在孩子表中增加一个字段指向妈妈表(外键)
孩子表:
| id | 名字 | 年龄 | 电话 | 妈妈id |
|---|---|---|---|---|
| 妈妈表的主键 |
3、多对多
多对多:一张表中(A)的一条记录能够对应另外一张表(B)中的多条记录;同时B表中的一条记录也能对应A表中的多条记录: 多对多的关系。
老师与学生的关系:
老师表:
| id | 姓名 | 性别 | 电话 |
|---|---|---|---|
| 1 | 张老师 | 男 | 88888888888 |
| 2 | 李老师 | 男 | 99999999999 |
学生表:
| id | 姓名 | 性别 | 电话 |
|---|---|---|---|
| 1 | 张三 | 男 | 12312312312 |
| 2 | 李四 | 男 | 32132132132 |
以上设计方案:实现了实体的设计,但是没有维护实体的关系。
一个老师教过多个学生;一个学生也被多个老师教过。
-
解决方案:
-
增加一张新表: 专门维护两张表之间的关系
-
这张表就叫做中间表
-
中间表:
| id | t_id(老师id) | s_id(学生id) |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 1 |
| 4 | 2 | 2 |
增加中间表之后:中间表与老师表形成了一对多的关系:而且中间表是多表,维护了能够唯一找到一表的关系;同样的,学生表与中间表也是一个一对多的关系:一对多的关系可以匹配到关联表之间的数据。
二、范式
范式:是一种离散数学中的知识,是为了解决一种数据的存储与优化的问题,保存数据的存储之后,凡是能够通过关系找出来的数据,坚决不再重复储存,终极目标是为了减少数据的冗余。
范式也是一种分层结构的规范,分为六层,每一次层都比上一层更加严格,若要满足下一层范式,前提是满足上一层范式。
六层范式:1NF、2NF、3NF、4NF、5NF、6NF
1NF是最底层,要求最低;6NF最高层,最严格。
范式在数据库的设计当中是有指导意义: 但是不是强制规范。
注意:我们掌握前三个范式即可。
1、1NF
第一范式
-
属性不可分割
-
即每个属性都是不可分割的原子项。(实体的属性即表中的列)
原子性:
-
数据表的每一列都是不可分割的基本数据项,同一列中不能有多个值,也不能存在重复的属性。
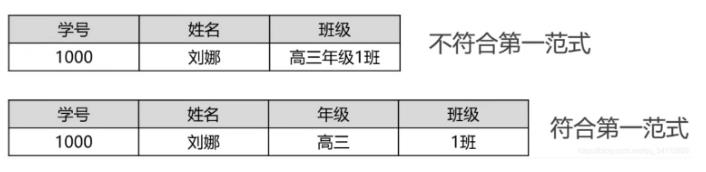
讲师排课表:
| 讲师 | 性别 | 班级 | 教室 | 代课时间 | 时间区间(开始,结束) |
|---|---|---|---|---|---|
| 苯环 | male | python2301 | p01 | 50天 | x年x月x日—x年x月x日 |
| 萧何 | male | python2302 | p02 | 50天 | x年x月x日—x年x月x日 |
| 蓝桥 | male | python2303 | p03 | 50天 | x年x月x日—x年x月x日 |
上表设计不存在问题,但是如果需求是将数据查出来之后,要求显示一个老师从什么时候开始上课,到什么时候节课,需要将代课时间进行拆分,不符合1NF,数据不具有原子性,可以再拆分。
-
解决办法:将排课时间区间拆分成两个字段就解决问题。
| 讲师 | 性别 | 班级 | 教室 | 代课时间 | 开始 | 结束 |
|---|---|---|---|---|---|---|
| 苯环 | male | python2301 | p01 | 50天 | x年x月x日 | x年x月x日 |
| 萧何 | male | python2302 | p02 | 50天 | x年x月x日 | x年x月x日 |
| 蓝桥 | male | python2303 | p03 | 50天 | x年x月x日 | x年x月x日 |
2、2NF
第二范式
-
满足第一范式
-
第二范式需要确保数据表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言),每张表只描述一件事情;
-
消除部分依赖,要求一张表中的每一列都完全依赖于主键(针对于组合主键),也就是不会出现某一列只和部分主键相关。
简单理解一下:
-
唯一性:数据表中的每条记录必须是唯一的。
-
为了实现区分,通常要为表加上一个列来存储唯一标识,这个唯一属性列被称作主键列
案例1:
-
学号为001的学生在2023-01-10考试第一次58没及格,然后当天补考第二次还是60没及格,于是数据库就有了重复的数据。解决办法就是添加一个考试流水号,让数据变得唯一。
| 学号 | 考试成绩 | 日期 |
|---|---|---|
| 001 | 60 | 2023-01-10 |
| 001 | 60 | 2023-01-10 |
| 考试流水号 | 学号 | 考试成绩 | 日期 |
|---|---|---|---|
| 20230110335 | 001 | 60 | 2023-01-10 |
| 20230110567 | 001 | 60 | 2023-01-10 |
3、3NF
第三范式
-
满足第一范式和第二范式
-
第三范式需要确保数据表中的每一列数据表和主键直接相关,而不能间接相关。
-
消除传递依赖,要求一张表中的每一列都和主键是直接依赖的,不是间接依赖。
简单理解:
-
关联性:每列都与主键有直接关系,不存在传递依赖。
案例1:
-
根据主键爸爸能关联儿子女儿,但是女儿的玩具、衣服都不是依赖爸爸的,而是依赖女儿的,这些东西不是与爸爸有直接关系,所以拆分两个表。
儿子女儿依赖于爸爸,女儿的玩具、衣服依赖于女儿。
| 爸爸 | 儿子 | 女儿 | 女儿的玩具 | 女儿的衣服 |
|---|---|---|---|---|
| 张三 | 张小山 | 张婷婷 | 芭比娃娃 | 校服 |
拆分后:
| 爸爸 | 儿子 | 女儿 |
|---|---|---|
| 张三 | 张小山 | 张婷婷 |
| 儿女 | 女儿的玩具 | 女儿的衣服 |
|---|---|---|
| 张婷婷 | 芭比娃娃 | 校服 |
三、数据库高级操作
1、查询数据
完整语法
Select [字段别名]/* from 数据源 [where条件子句] [group by子句] [having子句] [order by子句] [limit 子句];(1)通用的select语句
- select * from 表名;
(2)去重查询
数据准备:
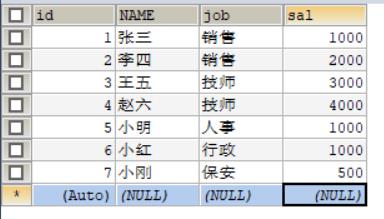
CREATE TABLE t_emp(
id INT(10) PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20) NOT NULL,
job VARCHAR(20) NOT NULL
)
INSERT INTO t_emp
(NAME, job)
VALUE
(\'张三\', \'销售\'),
(\'李四\', \'销售\'),
(\'王五\', \'技师\'),
(\'赵六\', \'技师\');假如我们查询员工职业,执行如下语句:
SELECT job FROM t_emp;结果如下:
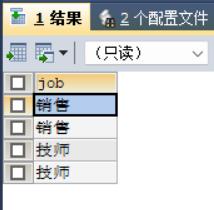
我们发现有很多重复的记录,因为职业是有可能相同的。
此时我们加上distinct,继续执行。
SELECT DISTINCT job FROM t_emp;结果如下:
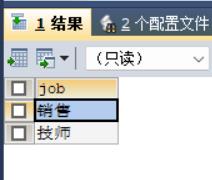
注意:
-
distinct关键字只能在select子句中使用一次
-
distinct关键字只能写在select子句的第一个字段前面
(3)聚合查询
通过聚合函数进行聚合查询。
聚合函数在数据查询分析中,应用十分广泛。
聚合函数可以对数据求和、求最大值和最小值、求平均值等等。
SQL提供了如下聚合函数:
-
Count(): 统计每一组有多少记录
-
Max(): 统计每组中非空的最大值
-
Min(): 统计非空的最小值
-
Avg(): 统计平均值
-
Sum(): 统计和
数据准备:
CREATE TABLE t_emp(
id INT(10) PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20) NOT NULL,
job VARCHAR(20) NOT NULL,
sal INT(20) NOT NULL
)
INSERT INTO t_emp
(NAME, job, sal)
VALUE
(\'张三\', \'销售\', 1000),
(\'李四\', \'销售\', 2000),
(\'王五\', \'技师\', 3000),
(\'赵六\', \'技师\', 4000);案例1:查询公司员工平局工资
SELECT AVG(sal) FROM t_emp;案例2:月收入最高的员工
SELECT MAX(sal) FROM t_emp;(4)分组查询
Group by:主要用来分组查询,,通过一定的规则将一个数据集划分为若干个小的区域,然后针对每个小区域分别进行数据汇总处理。也就是根据某个字段进行分组(相同的放一组,不同的分到不同的组)
案例1:根据不同的 job 分组显示平均工资
SELECT job, ROUND(AVG(sal)) FROM t_emp GROUP BY job;
/*round四舍五入为整数*/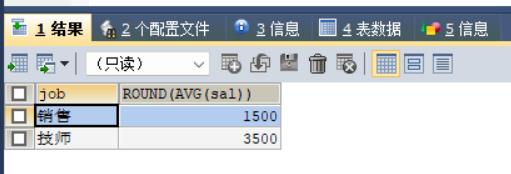
(5)排序查询
Order by: 排序,根据某个字段进行升序或者降序排序。
基本使用语法:
-
单字段排序
Order by 字段名 [asc|desc]; -- asc是升序(默认的),desc是降序- 多字段排序
Order by 字段名1, 字段名2, 字段名3 [asc|desc]; -- asc是升序(默认的),desc是降序(6)分页查询
Limit:子句是一种限制结果的语句,用来做数据分页的。
可以事先多准备一点数据。
Limit有两种使用方式:
-
方案1:只用来限制长度(数据量)
-
语法:limit 数据量
SELECT * FROM t_emp LIMIT 2;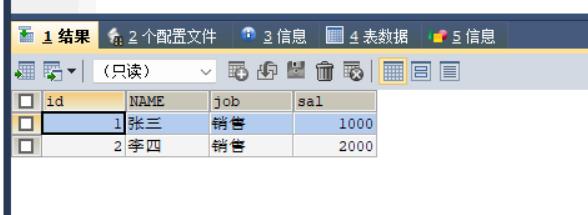
-
方案2:限制起始位置,限制数量
-
语法:limit 起始位置,长度
SELECT * FROM t_emp LIMIT 2, 3;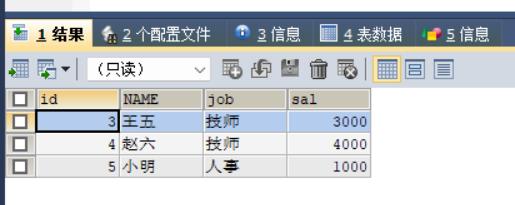
2、多表查询
MySQL语句学习的难点和重点就在于多表查询,同时MySQL也有诸多方法供大家选择(联结表、左连接、右连接……)还是子查询(SELECT子查询、WHERE子查询、FROM子查询),掌握一种方法达到目的即可,当然其他方法也需要理解,本节将阐述完整的多表查询方法。
(1)数据准备
首先准备一个数据库
-
创建公司表
#创建数据库,可忽略,一般用不到
CREATE DATABASE test;
use test;
#创建数据表company
CREATE TABLE company (
id INT PRIMARY KEY,
name VARCHAR(255) NOT NULL
);
#新增数据
INSERT INTO company VALUES(1,\'IBM\');
INSERT INTO company VALUES(2,\'HP\');- 创建员工表
#创建数据表menber
CREATE TABLE menber(
id INT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
sal DOUBLE(10,2),
comid INT,
FOREIGN KEY(comid) REFERENCES company(id)
);
#新增数据
INSERT INTO menber VALUES(101,\'小李\',3000,1);
INSERT INTO menber VALUES(102,\'小王\',4000,1);
INSERT INTO menber VALUES(103,\'小刘\',5000,2);
INSERT INTO menber VALUES(104,\'小孙\',5000,2);(2)联结
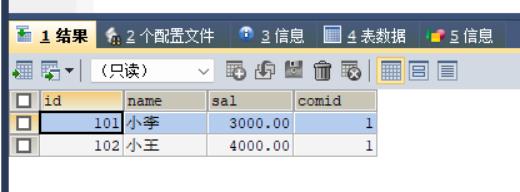
应用:查询IBM的员工信息
SELECT
m.*
FROM
company c, menber m
WHERE
c.id = m.comid AND c.name = \'IBM\';结果:
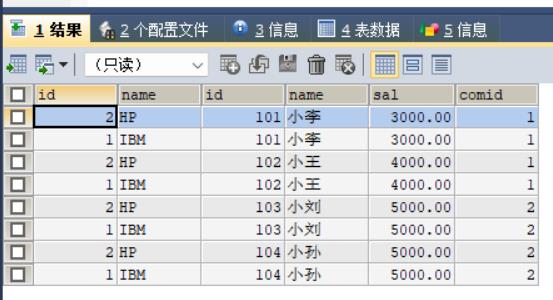
拓展:(笛卡尔积)
SELECT * FROM company, menber结果:
(3)左外连接查询
左表是主表、左表中满足条件的记录会查询出来、左表中【不满足】条件的也会查出来,运行结果也以左表为主。
格式:
select 字段 from 表1 left join 表2 on 表1.字段1 = 表2.字段2SELECT
*
FROM
company c LEFT JOIN menber m
ON
c.id = m.comid;(4)右外连接查询
右表是主表、右表中所有的记录会查询出来,运行结果以右表为主。
格式:
select 字段 from 表1 RIGHT JOIN 表2 on 表1.字段1 = 表2.字段2SELECT
*
FROM
menber m RIGHT JOIN company c
ON
c.id = m.comid;(5)内连接查询
查询的是满足条件的记录。
格式:
SELECT 字段 FROM 表1 INNER JOIN 表2 ON 表1.字段1 = 表2.字段2SELECT * FROM menber m INNER JOIN company c ON c.id = m.comid(6)子查询
把一个查询的结果当作另一个查询的条件。
应用:查询小刘的公司民名称
SELECT NAME FROM company WHERE id = 2;
SELECT NAME FROM company WHERE id = (SELECT comid FROM menber WHERE name = \'小刘\');3、练习
多表查询数据准备
-- 创建db6数据库
CREATE DATABASE db6;
-- 使用db6数据库
USE db6;
-- 创建user表
CREATE TABLE USER(
id INT PRIMARY KEY AUTO_INCREMENT, -- 用户id
NAME VARCHAR(20), -- 用户姓名
age INT -- 用户年龄
);
-- 添加数据
INSERT INTO USER VALUES (1,\'张三\',23);
INSERT INTO USER VALUES (2,\'李四\',24);
INSERT INTO USER VALUES (3,\'王五\',25);
INSERT INTO USER VALUES (4,\'赵六\',26);
-- 订单表
CREATE TABLE orderlist(
id INT PRIMARY KEY AUTO_INCREMENT, -- 订单id
number VARCHAR(30), -- 订单编号
uid INT, -- 外键字段
CONSTRAINT ou_fk1 FOREIGN KEY (uid) REFERENCES USER(id)
);
-- 添加数据
INSERT INTO orderlist VALUES (1,\'hm001\',1);
INSERT INTO orderlist VALUES (2,\'hm002\',1);
INSERT INTO orderlist VALUES (3,\'hm003\',2);
INSERT INTO orderlist VALUES (4,\'hm004\',2);
INSERT INTO orderlist VALUES (5,\'hm005\',3);
INSERT INTO orderlist VALUES (6,\'hm006\',3);
INSERT INTO orderlist VALUES (7,\'hm007\',NULL);
-- 商品分类表
CREATE TABLE category(
id INT PRIMARY KEY AUTO_INCREMENT, -- 商品分类id
NAME VARCHAR(10) -- 商品分类名称
);
-- 添加数据
INSERT INTO category VALUES (1,\'手机数码\');
INSERT INTO category VALUES (2,\'电脑办公\');
INSERT INTO category VALUES (3,\'烟酒茶糖\');
INSERT INTO category VALUES (4,\'鞋靴箱包\');
-- 商品表
CREATE TABLE product(
id INT PRIMARY KEY AUTO_INCREMENT, -- 商品id
NAME VARCHAR(30), -- 商品名称
cid INT, -- 外键字段
CONSTRAINT cp_fk1 FOREIGN KEY (cid) REFERENCES category(id)
);
-- 添加数据
INSERT INTO product VALUES (1,\'华为手机\',1);
INSERT INTO product VALUES (2,\'小米手机\',1);
INSERT INTO product VALUES (3,\'联想电脑\',2);
INSERT INTO product VALUES (4,\'苹果电脑\',2);
INSERT INTO product VALUES (5,\'中华香烟\',3);
INSERT INTO product VALUES (6,\'玉溪香烟\',3);
INSERT INTO product VALUES (7,\'计生用品\',NULL);
-- 中间表
CREATE TABLE us_pro(
upid INT PRIMARY KEY AUTO_INCREMENT, -- 中间表id
uid INT, -- 外键字段。需要和用户表的主键产生关联
pid INT, -- 外键字段。需要和商品表的主键产生关联
CONSTRAINT up_fk1 FOREIGN KEY (uid) REFERENCES USER(id),
CONSTRAINT up_fk2 FOREIGN KEY (pid) REFERENCES product(id)
);
-- 添加数据
INSERT INTO us_pro VALUES (NULL,1,1);
INSERT INTO us_pro VALUES (NULL,1,2);
INSERT INTO us_pro VALUES (NULL,1,3);
INSERT INTO us_pro VALUES (NULL,1,4);
INSERT INTO us_pro VALUES (NULL,1,5);
INSERT INTO us_pro VALUES (NULL,1,6);
INSERT INTO us_pro VALUES (NULL,1,7);
INSERT INTO us_pro VALUES (NULL,2,1);
INSERT INTO us_pro VALUES (NULL,2,2);
INSERT INTO us_pro VALUES (NULL,2,3);
INSERT INTO us_pro VALUES (NULL,2,4);
INSERT INTO us_pro VALUES (NULL,2,5);
INSERT INTO us_pro VALUES (NULL,2,6);
INSERT INTO us_pro VALUES (NULL,2,7);
INSERT INTO us_pro VALUES (NULL,3,1);
INSERT INTO us_pro VALUES (NULL,3,2);
INSERT INTO us_pro VALUES (NULL,3,3);
INSERT INTO us_pro VALUES (NULL,3,4);
INSERT INTO us_pro VALUES (NULL,3,5);
INSERT INTO us_pro VALUES (NULL,3,6);
INSERT INTO us_pro VALUES (NULL,3,7);
INSERT INTO us_pro VALUES (NULL,4,1);
INSERT INTO us_pro VALUES (NULL,4,2);
INSERT INTO us_pro VALUES (NULL,4,3);
INSERT INTO us_pro VALUES (NULL,4,4);
INSERT INTO us_pro VALUES (NULL,4,5);
INSERT INTO us_pro VALUES (NULL,4,6);
INSERT INTO us_pro VALUES (NULL,4,7);- 查询用户的编号、姓名、年龄、订单编号
/*
分析:
用户的编号、姓名、年龄 user表 订单编号 orderlist表
条件:user.id = orderlist.uid
*/
SELECT
t1.`id`, -- 用户编号
t1.`name`, -- 用户姓名
t1.`age`, -- 用户年龄
t2.`number` -- 订单编号
FROM
USER t1, -- 用户表
orderlist t2 -- 订单表
WHERE
t1.`id` = t2.`uid`;- 查询用户年龄大于23岁的信息。显示用户的编号、姓名、年龄。订单编号
/*
分析:
用户的编号、姓名、年龄 user表 订单编号 orderlist表
条件:user.age > 23 AND user.id = orderlist.uid
*/
/*
select
t1.`id`, -- 用户编号
t1.`name`, -- 用户姓名
t1.`age`, -- 用户年龄
t2.`number` -- 订单编号
from
user t1, -- 用户表
orderlist t2 -- 订单表
where
t1.`age` > 23
and
t1.`id` = t2.`uid`;
*/
SELECT
t1.`id`, -- 用户编号
t1.`name`, -- 用户姓名
t1.`age`, -- 用户年龄
t2.`number` -- 订单编号
FROM
USER t1 -- 用户表
LEFT OUTER JOIN
orderlist t2 -- 订单表
ON
t1.`id` = t2.`uid`
WHERE
t1.`age` > 23;- 查询商品分类的编号、分类名称。分类下的商品名称
/*
分析:
商品分类的编号、分类名称 category表 分类下的商品名称 product表
条件:category.id = product.cid
*/
SELECT
t1.`id`, -- 分类编号
t1.`name`, -- 分类名称
t2.`name` -- 商品名称
FROM
category t1, -- 商品分类表
product t2 -- 商品表
WHERE
t1.`id` = t2.`cid`;
Mysql基础1
一、数据库简介
1、Structured Query Language (结构化查询语言)
2、SQL:工业标准。(各个数据库厂商都支持)
SQL-Server:对标准进行了扩展。TSQL 方言
Oracle:对标准进行了扩展。PLSQL
规定:
shell>window下命令
mysql>mysql中的命令,一般以;结尾(进入数据库)
二、安装MySQL数据库
如何验证安装是否成功!
shell>mysql -u root -psorry
显示所有的数据库
mysql>SHOW DATABASES;
除了test,其他2个数据库不要动。
*****三、SQL语句
1、DDL:Data Definition Language(数据定义语言)
关键字:CREATE ALTER DROP(操作对象:数据库和表结构。就是定义数据库或表的结构)
------------------------------------------------------------------
创建一个名称为mydb1的数据库。
mysql>CREATE DATABASE mydb1;
查看数据库的创建细节
mysql>SHOW CREATE DATABASE mydb1;
创建一个使用gbk字符集的mydb2数据库。
mysql>CREATE DATABASE mydb2 CHARACTER SET gbk;
创建一个使用utf8字符集,并带校对规则的mydb3数据库。
mysql>CREATE DATABASE mydb3 CHARACTER SET utf8 COLLATE utf8_general_ci;
查看当前数据库服务器中的所有数据库
mysql>SHOW DATABASES;
查看前面创建的mydb2数据库的定义信息
mysql>SHOW CREATE DATABASE mydb2;
删除前面创建的mydb2数据库
mysql>DROP DATABASE mydb2;
查看服务器中的数据库,并把其中mydb1库的字符集修改为gbk;
mysql>ALTER DATABASE mydb1 CHARACTER SET gbk;
备份test库中的数据,并恢复
备份:
shell>mysqldump -h localhost -u root -psorry test>c:/test.sql
恢复数据库:(删除掉test数据库)
创建test数据库
mysql>CREATE DATABASE test;
mysql>USE test;
恢复:
方式一:
mysql>SOURCE C:/test.sql;
//选择数据库
mysql>USE test;
方式二:
shell>mysql -u root -psorry test<c:/test.sql
显示数据库中的所有表格
mysql>SHOW TABLES;
-------------------------------------------------
创建员工信息表
mysql>CREATE TABLE employee(
id int,
name varchar(100),
gender varchar(10),
birthday date,
entry_date date,
job varchar(100),
salary float(8,2),
resume varchar(200)
);
查看数据库中所有的表格
mysql>SHOW TABLES;
查看某张表格的结构
mysql>DESC employee;
在上面员工表的基本上增加一个image列。
mysql>ALTER TABLE employee ADD (image blob);
修改job列,使其长度为60。
mysql>ALTER TABLE employee MODIFY job varchar(60);
删除gender列。
mysql>ALTER TABLE employee DROP gender;
表名改为user。
mysql>RENAME TABLE employee TO user;
修改表的字符集为utf-8
mysql>ALTER TABLE user CHARACTER SET utf8;
列名name修改为username
mysql>ALTER TABLE user CHANGE name username varchar(100);
*2、DML:Data Manipulation Language(数据操作语言)
关键字:INSERT UPDATE DELETE(操作对象:表中的数据。就是操作表中的记录用的)
------------------------------------------------------------------
在MySQL中,字符或字符串或日期类型的数据要使用单引号引起来。关键字NULL表示空值,不同于空字符串值。‘‘
使用insert语句向表中插入三个员工的信息。
mysql>INSERT INTO user (id,username,birthday,entry_date,job,salary,resume) VALUES (1,‘huangshanshan‘,‘1992-09-08‘,‘2012-11-15‘,‘CEO‘,‘10000‘,‘beautiful girl‘);
mysql>INSERT INTO user VALUES (2,‘niuyang‘,‘1992-09-08‘,‘2012-11-15‘,‘CTO‘,‘10000‘,‘beautiful boy‘);
mysql>INSERT INTO user VALUES (3,‘于连林‘,‘1992-09-08‘,‘2012-11-15‘,‘CMO‘,‘10000‘,‘帅锅‘);
告诉服务器客户端用的编码是什么?
mysql>SET character_set_client=gbk;
查看数据
mysql>SELECT * FROM user;
解决返回的数据中文乱码
mysql>SET character_set_results=gbk;
MySQL中的各种编码:
查看有哪些地方用到编码
mysql>SHOW VARIABLES LIKE ‘character%‘;
character_set_client:此变量通知服务器客户端用的是什么编码
character_set_connection:此变量通知服务器客户端链接时用的是什么编码
character_set_database:数据库用的编码
character_set_results:是数据库给客户端返回时使用的字符集设定,如果没有指明,使用服务器默认的字符集。
character_set_server:是服务器安装时指定的默认字符集设定
character_set_system :是数据库系统使用的字符集设定。
将所有员工薪水修改为5000元。
mysql>UPDATE user SET salary=5000;
将姓名为’niuyang’的员工薪水修改为30000元。
mysql>UPDATE user SET salary=30000 WHERE username=‘niuyang‘;
将姓名为’huangshanshan’的员工薪水修改为20000元,job改为HR。
mysql>UPDATE user SET salary=20000,job=‘HR‘ WHERE username=‘huangshanshan‘;
将于连林的薪水在原有基础上增加10000元。
mysql>UPDATE user SET salary=salary+10000 WHERE username=‘于连林‘;
删除表中名称为’于连林’的记录。
mysql>DELETE FROM user WHERE username=‘于连林‘;
删除表中所有记录。(一条一条地删除)
mysql>DELETE FROM user;
使用truncate删除表中记录。(摧毁整张表,然后重建表结构)
mysql>TRUNCATE user;
------------------------------------------------------------------
*3、DQL:Data Query Language(数据查询语言)
关键字:SELECT
查询表中所有学生的信息。
mysql>SELECT id,name,chinese,english,math FROM student;
或者SELECT * FROM student;
查询表中所有学生的姓名和对应的英语成绩。
mysql>SELECT name,english FROM student;
过滤表中重复数据。
mysql>SELECT DISTINCT english FROM student;
在所有学生语文分数上加10分特长分。
mysql>SELECT id,name,chinese+10 FROM student;
统计每个学生的总分。
mysql>SELECT id,name,chinese+english+math FROM student;
使用别名表示学生分数。(AS可以省略)
mysql>SELECT id,name,chinese+english+math AS 总分 FROM student;
mysql>SELECT id,name,chinese+english+math 分 FROM student;
查询姓名为wu的学生成绩
mysql>SELECT id,name,chinese,english,math FROM student WHERE name=‘王五‘;
查询英语成绩大于90分的同学
mysql>SELECT name,english FROM student WHERE english>90;
查询总分大于200分的所有同学
mysql>SELECT name,chinese+english+math AS 总分 FROM student WHERE (chinese+english+math)>200;
------------------------------------------------------------------
(选修)4、DCL:Data Control Language(数据控制语言)
GRANT等
*****四、多表关系及设计
*****五、约束
以上是关于Mysql数据库基础的主要内容,如果未能解决你的问题,请参考以下文章