复习之七种寻址
Posted liujy2233
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了复习之七种寻址相关的知识,希望对你有一定的参考价值。
段寄存器:CS、DS、ES、SS
1.指令
指令由操作数码和操作数两部分构成

操作码:说明计算机要执行的操作,如传送、运算、移位、跳转等操作,它是指令中不可缺少的组成部分。
操作数:是指令执行的参与者,即各种操作的对象。也就是指令执行操作过程中需要的操作数。
2、寻址
1、立即寻址 MOV AX , 3069H

操作数直接存放在指令中,紧跟在操作码之后
例如: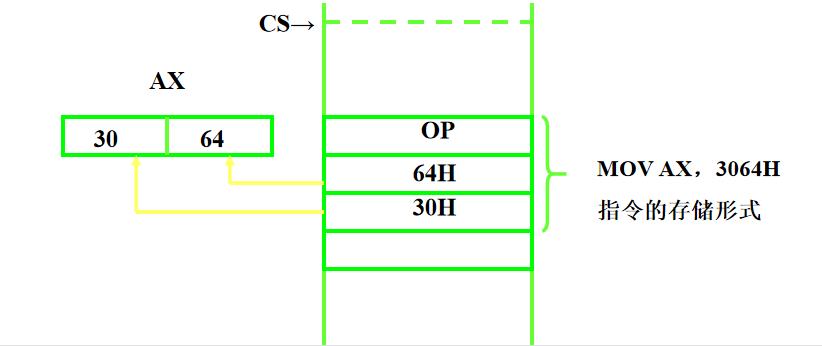
MOV AX,3064H
2、寄存器寻址 MOV AL , B
操作数存储在寄存器中,指令中指定寄存器号,这种寻址方式称为寄存器寻址方式。

例如 :
AX=3064H BX=1024H
MOV AX,BX
得到 AX=1024H BX=1024H
注意事项:
1、 指令中源操作数和目的操作数都是寄存器时,必须采用同样字长的寄存器,否则汇编时会出错;(源操作数指的是不随指令变化的操作数)
2、两个操作数不能同为段寄存器;
3、目的操作数不能为代码段寄存器(CS)
以下各种寻址方式,操作数都在除代码段之外的存储区中,先介绍变址
位移量(displacement):存放在指令中的一个8位或16位或32位的数,但它不是立即数,而是一个地址
基址(base):存放在基址寄存器(如BX、BP)中的内容。它是有效地址中的基址部分,通常用于指向数据段中数组或字符串的首地址
变址(index):存放在变址寄存器(如SI、DI)中的内容。通常用来指向数组中某个元素或字符串的某个字符
EA=基址+(变址x比例因子)+位移量
3、直接寻址 MOV AX , [ 2000H ]

操作数的有效地址只包含位移量一种成分,其值就存放在代码段中指令的操作码之后。位移量的值即操作数的有效地址
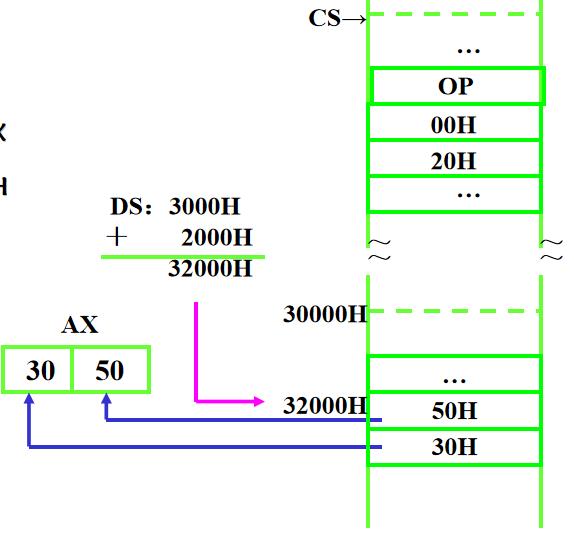
执行指令:MOV AX ,[2000H] 设(DS)=3000H。 执行后:(AX)=?
执行:(32000H)→AX 执行后:(AX)=3050H
4、寄存器间接寻址 MOV AX , [ BX ]

操作数的有效地址只包含基址寄存器内容或者变址寄存器内容一种成分。因此有效地址就在某个寄存器中,而操作数则在存储器中。(16位寻址可用的寄存器:BX,BP,SI,DI)

物理地址PA=16×DS + SI/DI/BX
物理地址PA=16×SS+ BP
不允许使用AX、CX、DX 存放 EA
MOV AX, [CX] 错误
5、寄存器相对寻址 MOV AX , COUNT [ SI ]
操作数的有效地址为基址寄存器或变址寄存器的内容和指令中指定的位偏移量之和。 (寄存器的规定同寄存器间接寻址)

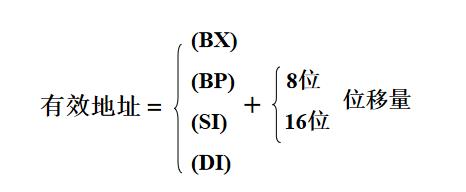
例如:
MOV AX, COUNT[SI]
或 MOV AX, [COUNT+SI]
假设 (DS)=3000H, (SI)=2000H, COUNT=3000H(符号地址)
EA=SI+COUNT=5000H
PA=DS*16+EA=35000H
则: PA = 35000H
假设(35000H)=1234H, 那么 (AX)=1234H *

6、基址变址寻址 MOV AX , [ BP ] [ DI ]
操作数有效地址是一个基址寄存器(如BX、BP)和一个变址寄存器(如SI、DI)的内容之和。 有效地址由两种成分组成。


MOV AX, [BX] [DI]
MOV AX, [BX+DI]
MOV AX, ES:[BX] [SI]
必须是一个基址寄存器和一个变址寄存器的组合
MOV AX, [BX] [BP] 错误
MOV AX, [SI] [DI] 错误
假设指令:MOV BX, [BX+SI],在执行时,(DS)=1000H,(BX)=2100H,(SI)=0011H,内存单元12111H的内容为1234H。问该指令执行后,BX的值是什么?
EA=BX+SI=2111H
PA=DS*16+EA=12111H
所以得出BX的值为1234H

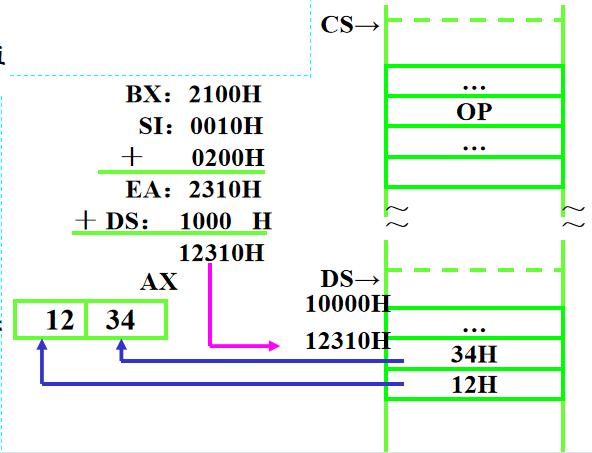
7、相对基址变址寻址 MOV AX , MASK [ BX ] [ SI ]
操作数有效地址是一个基址寄存器(如BX、BP)的值与一个变址寄存器(如SI、DI)的值和指令中的偏移量之和。( 16位寻址位:移量为8位/16位) 有效地址由三种成分组成。
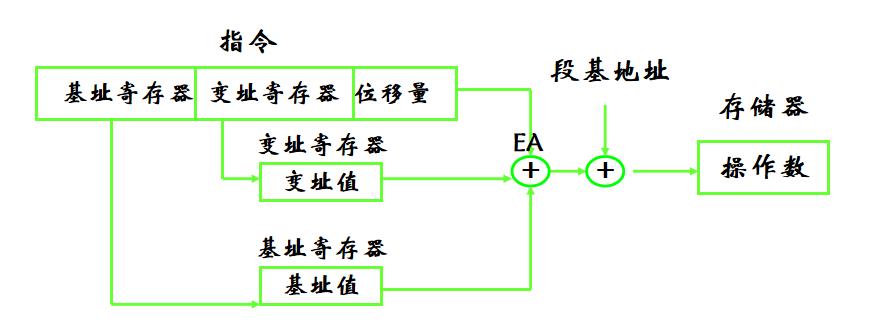

MOV AX, MASK [BX] [SI]
MOV AX, MASK [BX+SI]
MOV AX, [MASK+BX+SI]
假设指令:MOV AX, [BX+SI+200H],在执行时,(DS)=1000H,(BX)=2100H,(SI)=0010H,内存单元12310H的内容为1234H。问该指令执行后,AX的值是什么?
EA=BX+SI+200H=2310H
PA=DS*16+EA=12310H
所以得出AX值为1234H

数据挖掘之七种常用的方法
来源:http://www.alibuybuy.com/posts/84759.html
摘要:数据挖掘又称数据库中的知识发现,是目前人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程 利用数据挖掘进行数据分析常用的方法主要有分类、回归分析、聚类、关联规则、特征、变化和偏差分析、Web页挖掘等, 它们分别从不同的角度对数据进行挖掘。
① 分类。分类是找出数据库中一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到某个给定的类别。
它可以应用到客户的分类、客户的属性和特征分析、客户满意度分析、客户的购买趋势预测等,如一个汽车零售商将客户按照对汽车的喜好划分成不同的类,这样营销人员就可以将新型汽车的广告手册直接邮寄到有这种喜好的客户手中,从而大大增加了商业机会。
② 回归分析。回归分析方法反映的是事务数据库中属性值在时间上的特征,产生一个将数据项映射到一个实值预测变量的函数,发现变量或属性间的依赖关系,其主要研究问题包括数据序列的趋势特征、数据序列的预测以及数据间的相关关系等。
它可以应用到市场营销的各个方面,如客户寻求、保持和预防客户流失活动、产品生命周期分析、销售趋势预测及有针对性的促销活动等。
③ 聚类。聚类分析是把一组数据按照相似性和差异性分为几个类别,其目的是使得属于同一类别的数据间的相似性尽可能大,不同类别中的数据间的相似性尽可能小。
它可以应用到客户群体的分类、客户背景分析、客户购买趋势预测、市场的细分等。
④ 关联规则。关联规则是描述数据库中数据项之间所存在的关系的规则,即根据一个事务中某些项的出现可导出另一些项在同一事务中也出现,即隐藏在数据间的关联或相互关系。
在客户关系管理中,通过对企业的客户数据库里的大量数据进行挖掘,可以从大量的记录中发现有趣的关联关系,找出影响市场营销效果的关键因素,为产品定位、定价与定制客户群,客户寻求、细分与保持,市场营销与推销,营销风险评估和诈骗预测等决策支持提供参考依据。
⑤ 特征。特征分析是从数据库中的一组数据中提取出关于这些数据的特征式,这些特征式表达了该数据集的总体特征。如营销人员通过对客户流失因素的特征提取,可以得到导致客户流失的一系列原因和主要特征,利用这些特征可以有效地预防客户的流失。
⑥ 变化和偏差分析。偏差包括很大一类潜在有趣的知识,如分类中的反常实例,模式的例外,观察结果对期望的偏差等,其目的是寻找观察结果与参照量之间有意义的差别。在企业危机管理及其预警中,管理者更感兴趣的是那些意外规则。意外规则的挖掘可以应用到各种异常信息的发现、分析、识别、评价和预警等方面。
⑦ Web页挖掘。随着Internet的迅速发展及Web 的全球普及, 使得Web上的信息量无比丰富,通过对Web的挖掘,可以利用Web 的海量数据进行分析,收集政治、经济、政策、科技、金融、各种市场、竞争对手、供求信息、客户等有关的信息,集中精力分析和处理那些对企业有重大或潜在重大影响的外部环境信息和内部经营信息,并根据分析结果找出企业管理过程中出现的各种问题和可能引起危机的先兆,对这些信息进行分析和处理,以便识别、分析、评价和管理危机。
数据挖掘是一种决策支持过程,它通过高度自动化地分析企业的数据,做出归纳性的推理,从中挖掘出潜在的模式,帮助决策者调整市场策略,减少风险,做出正确的决策。这对于一个企业的发展十分重要。
如果您从中感受到数学的魅力了,
请支持一下小编!欢迎分享或赞赏!
热经典文章推荐:
以上是关于复习之七种寻址的主要内容,如果未能解决你的问题,请参考以下文章