rabbitmq(中间消息代理)在python中的使用
Posted God_Li
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了rabbitmq(中间消息代理)在python中的使用相关的知识,希望对你有一定的参考价值。
在之前的有关线程,进程的博客中,我们介绍了它们各自在同一个程序中的通信方法。但是不同程序,甚至不同编程语言所写的应用软件之间的通信,以前所介绍的线程、进程队列便不再适用了;此种情况便只能使用socket编程了,然而不同程序之间的通信便不再像线程进程之间的那么简单了,要考虑多种情况(比如其中一方断线另一方如何处理;消息群发,多个程序之间的通信等等),如果每遇到一次程序间的通信,便要根据不同情况编写不同的socket,还要维护、完善这个socket这会使得编程人员的工作量大大增加,也使得程序更易崩溃。所以,一般遇到这种情况,便使用消息队列MQ(Message Queue),那么问题来了。
1. 什么是消息队列MQ?
MQ是一种应用程序对应用程序的通信方法。应用程序通过读出(写入)队列的消息(针对应用程序的数据)来通信,而无需使用专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,排队指的是应用程序通过 队列来通信。队列的使用排除了接收和发送应用程序同时执行的要求。
2. 什么是rabbitmq?如何使用它?
RabbitMQ是流行的开源消息队列系统,用erlang语言开发。RabbitMQ是AMQP(高级消息队列协议)的标准实现。
RabbitMQ也是前面所提到的生产者消费者模型,一端发送消息(生产任务),一端接收消息(处理任务)。
rabbitmq的详细使用(包括各种系统的安装配置)可参见其官方文档:http://www.rabbitmq.com/documentation.html
由于应用程序之间的通信情况异常复杂,rabbitmq支持的编程语言有10多种,所以在此博客中不可能完全演示rabbitmq的所有使用。本片博客将会介绍rabbitmq在python中的基本使用,如果你只想使用rabbitmq完成一些简单的任务,则本篇博客足以满足你的需求;如果你想深入学习了解rabbitmq的工作原理,那么读完本篇博客,你可以更容易的读懂rabbitmq的官方文档;当然这些只限于你在使用python编程。
在python中我们使用pika(第三方模块,使用pip安装即可使用)模块进行rabbitmq的操作,接下来,使用python实现一个rabbitmq最简单的通信。
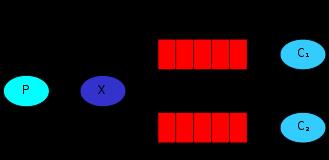
In the diagram below, "P" is our producer and "C" is our consumer. The box in the middle is a queue - a message buffer that RabbitMQ keeps on behalf of the consumer.
Our overall design will look like:

Producer sends messages to the "hello" queue. The consumer receives messages from that queue.
例一(简单的消息收发):
Sending

Our first program send.py will send a single message to the queue. The first thing we need to do is to establish a connection with RabbitMQ server.


1 import pika
2
3 connection = pika.BlockingConnection(pika.ConnectionParameters("localhost")) # 建立程序与rabbitmq的连接
4 channel = connection.channel()
5
6 channel.queue_declare(queue=\'hello\') # 定义hello队列
7 channel.basic_publish(exchange=\'\',
8 routing_key=\'hello\', # 告诉rabbitmq将消息发送到hello队列中
9 body=\'Hello world!\') # 发送消息的内容
10 print(" [x] Sent \'Hello World!\'")
11 connection.close() # 关闭与rabbitmq的连接
Receiving

Our second program receive.py will receive messages from the queue and print them on the screen.
1 import pika
2 import time
3
4 connection = pika.BlockingConnection(pika.ConnectionParameters("localhost")) # 建立程序与rabbitmq的连接
5 channel = connection.channel()
6
7 # 在接收端定义队列,参数与发送端的相同
8 channel.queue_declare(queue=\'hello\')
9
10 def callback(ch, method, properties, body):
11 """
12 收到消息调用callback处理消息
13 :param ch:
14 :param method:
15 :param properties:
16 :param body:
17 :return:
18 """
19 print(" [x] received %r" % body)
20 # time.sleep(30)
21 print("Done....")
22
23 channel.basic_consume(callback,
24 queue=\'hello\', # 告诉rabbitmq此程序从hello队列中接收消息
25 no_ack=True)
26
27 # channel.basic_consume(callback,
28 # queue=\'hello\')
29
30 print(\' [*] Waiting for messages. To exit press CTRL+C\')
31 channel.start_consuming() # 开始接收,未收到消息阻塞
注1:我们可以打开time.sleep()的注释(模仿任务处理所需的时间),将no_ack设为默认值(不传参数),同时运行多个receive.py, 运行send.py发一次消息,第一个开始运行的receive.py接收到消息,开始处理任务,如果中途宕机(任务未处理完);那么第二个开始运行的receive.py就会接收到消息,开始处理任务;如果第二个也宕机了,则第三个继续;如果依次所有运行的receive都宕机(任务未处理完)了,则下次开始运行的第一个receive.py将继续接收消息处理任务,这个机制防止了一些必须完成的任务由于处理任务的程序异常终止导致任务不能完成。如果将no_ack设为True,中途宕机,则后面的接收端不会再接收消息处理任务。
注2:如果发送端不停的发消息,则接收端分别是第一个开始运行的接收,第二个开始运行的接收,第三个开始运行接收,依次接收,这是rabbitmq的消息轮循机制(相当于负载均衡,防止一个接收端接收过多任务卡死,当然这种机制存在弊端,就是如果就收端机器有的配置高有的配置低,就会使配置高的机器得不到充分利用而配置低的机器一直在工作)。这一点可以启动多个receive.py,多次运行send.py验证。
上面的例子我们介绍了消息的接收端(即任务的处理端)宕机,我们该如何处理。接下来,我们将重点放在消息的发送端(即服务端),与接收端不同,如果发送端宕机,则会丢失存储消息的队列,存储的消息(要发送给接收端处理的任务),这些信息一旦丢失会造成巨大的损失,所以下面的重点就是消息的持久化,即发送端异常终止,重启服务后,队列,消息都将自动加载进服务里。其实只要将上面的代码稍微修改就可实现。
例二(消息的持久化):
Sending:
1 import pika
2
3 connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
4 channel = connection.channel()
5
6 channel.queue_declare(queue=\'task_queue\', durable=True) #使队列持久化
7
8 message = "Hello World"
9 channel.basic_publish(exchange=\'\',
10 routing_key=\'task_queue\',
11 body=message,
12 properties=pika.BasicProperties(
13 delivery_mode=2, #使消息持久化
14 ))
15
16 print(" [x] Sent %r" % message)
17 connection.close()
Receiving:
1 import pika
2 import time
3
4 connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
5 channel = connection.channel()
6
7 channel.queue_declare(queue=\'task_queue\', durable=True) #再次申明队列,和发送端参数应一样
8 print(\' [*] Waiting for messages. To exit press CTRL+C\')
9
10 def callback(ch, method, properties, body):
11 print(" [x] received %r" % body)
12 time.sleep(2)
13 print(" [x] Done")
14 # 因为没有设置no_ask=True, 所以需要告诉rabbitmq消息已经处理完毕,rabbitmq将消息移出队列。
15 ch.basic_ack(delivery_tag=method.delivery_tag)
16
17 #同一时间worker只接收一条消息,等这条消息处理完在接收下一条
18 channel.basic_qos(prefetch_count=1)
19 channel.basic_consume(callback,
20 queue=\'task_queue\')
21
22
23 channel.start_consuming()
注1:worker.py中的代码如果不设置,则new_task.py意外终止在重启后,worker会同时接收终止前没有处理的所有消息。两个程序中的queue设置的参数要相同,否则程序出错。no_ask=True如果没设置,则worker.py中的ch.basic_ack(delivery_tag=method.delivery_tag)这行代码至关重要,如果不写,则不管接收的消息有没有处理完,此消息将一直存在与队列中。
注2:这句代码---channel.basic_qos(prefetch_count=1),解决了上例中消息轮循机制的代码,即接收端(任务的处理端)每次只接收一个任务(参数为几接收几个任务),处理完成后通过向发送端的汇报(即注1中的代码)来接收下一个任务,如果有任务正在处理中它不再接收新的任务。
前面所介绍的例一,例二都是一条消息,只能被一个接收端收到。那么该如何实现一条消息多个接收端同时收到(即消息群发或着叫广播模式)呢?
其实,在rabbitmq中只有consumer(消费者,即接收端)与queue绑定,对于producer(生产者,即发送端)只是将消息发送到特定的队列。consumer从与自己相关的queue中读取消息而已。所以要实现消息群发,只需要将同一条放到多个消费者队列即可。在rabbitmq中这个工作由exchange来做,它可以设定三种类型,它们分别实现了不同的需求,我们分别来介绍。
例三(exchange的类型为fanout):
当exchange的类型为fanout时,所有绑定这个exchange的队列都会收到发来的消息。
1 import pika
2 import sys
3
4 connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'localhost\'))
5 channel = connection.channel()
6
7 # 申明一个exchange,两个参数分别为exchange的名字和类型;当exchang=\'fanout\'时,所有绑定到此exchange的消费者队列都将收到消息
8 channel.exchange_declare(exchange=\'logs\',
9 exchange_type=\'fanout\')
10
11 # 消息可以在命令行启动脚本时以参数的形式传入
12 # message = \' \'.join(sys.argv[1:]) or "info: Hello World!"
13 message = \'Hello World!\'
14
15 channel.basic_publish(exchange=\'logs\',
16 routing_key=\'\',
17 body=message)
18 print(" [x] Sent %r" % message)
19 connection.close()
1 import pika
2
3 connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'localhost\'))
4 channel = connection.channel()
5
6 channel.exchange_declare(exchange=\'logs\',
7 exchange_type=\'fanout\')
8
9 # 随机生成一个queue,此queue唯一,且在连接端开后自动销毁
10 result = channel.queue_declare(exclusive=True)
11 # 得到随机生成消费者队列的名字
12 queue_name = result.method.queue
13
14 # 将消费者队列与exchange绑定
15 channel.queue_bind(exchange=\'logs\',
16 queue=queue_name)
17
18 print(\' [*] Waiting for logs. To exit press CTRL+C\')
19
20 def callback(ch, method, properties, body):
21 print(" [x] received %r" % body)
22
23 channel.basic_consume(callback,
24 queue=queue_name,
25 no_ack=True)
26
27 channel.start_consuming()
注1:emit_log.py为消息的发送端,receive_logs.py为消息的接收端。可以同时运行多个receive_logs.py,当emit_log.py发送消息时,可以发现所有正在运行的receive_logs.py都会收到来自发送端的消息。
注2:类似与广播,如果消息发送时,接收端没有运行,那么它将不会收到此条消息,即消息的广播是即时的。
例四(exchange的类型为direct):
当exchange的类型为direct时,发送端和接收端都要指明消息的级别,接收端只能接收到被指明级别的消息。
1 import pika
2 import sys
3
4 connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'localhost\'))
5 channel = connection.channel()
6
7 channel.exchange_declare(exchange=\'direct_logs\',
8 exchange_type=\'direct\')
9
10 # 命令行启动时,以参数的的形式传入发送消息的级别,未传怎默认设置未info
11 # severity = sys.argv[1] if len(sys.argv) > 2 else \'info\'
12 # 命令行启动时,以参数的的形式传入发送消息的内容,未传怎默认设置Hello World!
13 # message = \' \'.join(sys.argv[2:]) or \'Hello World!\'
14
15 # 演示使用,实际运用应用上面的方式设置消息级别
16 severity = \'info\' #作为例子直接将消息的级别设置为info
17 # severity = \'warning\'
18 message = \'Hello World\'
19
20 #使用exchang的direct模式时,routing_key的值为消息的级别
21 channel.basic_publish(exchange=\'direct_logs\',
22 routing_key=severity,
23 body=message)
24 print(" [x] Sent %r:%r" % (severity, message))
25 connection.close()
1 #!/usr/bin/env python
2 import pika
3 import sys
4
5 connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'localhost\'))
6 channel = connection.channel()
7
8 channel.exchange_declare(exchange=\'direct_logs\',
9 exchange_type=\'direct\')
10
11 result = channel.queue_declare(exclusive=True)
12 queue_name = result.method.queue
13
14 # 命令行启动时以参数的形式传入要接收哪个级别的消息,可以传入多个级别
15 # severities = sys.argv[1:]
16
17 # 演示使用,实际运用应该用上面的方式指明消息级别
18 # 作为演示,直接设置两个接收级别,info 和 warning
19 severities = [\'info\', \'warning\']
20
21 if not severities:
22 """如果要接收消息的级别不存在则提示用户输入级别并退出程序"""
23 sys.stderr.write("Usage: %s [info] [warning] [error]\\n" % sys.argv[0])
24 sys.exit(1)
25
26 for severity in severities:
27 """依次为每个消息级别绑定queue"""
28 channel.queue_bind(exchange=\'direct_logs\',
29 queue=queue_name,
30 routing_key=severity)
31
32 print(\' [*] Waiting for logs. To exit press CTRL+C\')
33
34 def callback(ch, method, properties, body):
35 print(" [x] %r:%r" % (method.routing_key, body))
36
37 channel.basic_consume(callback,
38 queue=queue_name,
39 no_ack=True)
40
41 channel.start_consuming()
注1:exchange_type=direct时,rabbitmq按消息级别发送和接收消息,接收端只能接收被指明级别的消息,其他消息,即时是由同一个发送端发送的也无法接收。当在接收端传入多个消息级别时,应逐个绑定消息队列。
注2:exchange_type=direct时,同样是广播模式,也就是如果给多个接收端指定相同的消息级别,它们都可以同时收到这一级别的消息。
例三(exchange的类型为topic):
当exchange的类型为topic时,在发送消息时,应指明消息消息的类型(比如mysql.log、qq.info等),我们可以在接收端指定接收消息类型的关键字(即按关键字接收,在类型为topic时,这个关键字可以是一个表达式)。
1 import pika
2 import sys
3
4 connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'localhost\'))
5 channel = connection.channel()
6
7 channel.exchange_declare(exchange=\'topic_logs\',
8 exchange_type=\'topic\')
9
10 # 以命令行的方式启动发送端,以参数的形式传入发送消息类型的关键字
11 routing_key = sys.argv[1] if len(sys.argv[1]) > 2 else \'anonymous.info\'
12 # routing_key = \'anonymous.info\'
13 # routing_key = \'abc.orange.abc\'
14 # routing_key = \'abc.abc.rabbit\'
15 # routing_key = \'lazy.info\'
16
17 message = \' \'.join(sys.argv[2:]) or \'Hello World!\'
18 channel.basic_publish(exchange=\'topic_logs\',
19 routing_key=routing_key,
20 body=message)
21 print(" [x] Sent %r:%r" % (routing_key, message))
22 connection.close()
1 #!/usr/bin/env python
2 import pika
3 import sys
4
5 connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'localhost\'))
6 channel = connection.channel()
7
8 channel.exchange_declare(exchange=\'topic_logs\',
9 exchange_type=\'topic\')
10
11 result = channel.queue_declare(exclusive=True)
12 queue_name = result.method.queue
13
14 binding_keys = sys.argv[1:]
15 # binding_keys = \'#\' #接收所有的消息
16 # binding_keys = [\'*.info\'] #接收所有以".info"结尾的消息
17 # binding_keys = [\'*.orange.*\'] #接收所有含有".orange."的消息
18 # binding_keys = [\'*.*.rabbit\', \'lazy.*\'] #接收所有含有两个扩展名且结尾是".rabbit"和所有以"lazy."开头的消息
19
20 if not binding_keys:
21 sys.stderr.write("Usage: %s [binding_key]...\\n" % sys.argv[0])
22 sys.exit(1)
23
24 for binding_key in binding_keys:
25 channel.queue_bind(exchange=\'topic_logs\',
26 queue=queue_name,
27 routing_key=binding_key)
28
29 print(\' [*] Waiting for logs. To exit press CTRL+C\')
30
31 def callback(ch, method, properties, body):
32 print(" [x] %r:%r" % (method.routing_key, body))
33
34 channel.basic_consume(callback,
35 queue=queue_name,
36 no_ack=True)
37
38 channel.start_consuming()
注:当exchange的类型为topic时,发送端与接收端的代码都跟类型为direct时很像(基本只是变一个类型,如果接收消息类型的指定不用表达式,它们几乎一样),但是topic的应用场景更广。
注:rabbitmq指定消息的类型的表达式其实很简单:
\'#\':代表接收所有的消息(一般单独使用),使用它相当于exchang的类型为fanout。
\'*\':代表任意一个字符(一般与其他单词配合使用)。
不使用\'#\'或\'*\',使用它相当于exchang的类型为direct。
前面介绍的都是一端发送,一端接收的消息传递模式,那么rabbitmq该如何实现客户端和服务端都要发送和接收(即RPC)呢?
我们先来简单了解以下RPC,RPC(Remote Procedure Call)采用客户机/服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
例五(通过rabbitmq实现rpc):
先来看以下在rabbitmq中rpc的消息传递模式:
 我们以客户端发送一个数字n,服务端计算出斐波那契数列的第n个数的值返回给客户端为例。
我们以客户端发送一个数字n,服务端计算出斐波那契数列的第n个数的值返回给客户端为例。
1 import pika
2
3 connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'localhost<以上是关于rabbitmq(中间消息代理)在python中的使用的主要内容,如果未能解决你的问题,请参考以下文章