MLIR基础及开发初探分析
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MLIR基础及开发初探分析相关的知识,希望对你有一定的参考价值。
MLIR基础及开发初探分析
初识MLIR
0x1. 前言
最近开始做一些MLIR的工作,所以开始学习MLIR的知识。这篇笔记是对MLIR的初步印象,并不深入,适合想初步了解MLIR是什么的同学阅读,后面会继续分享MLIR的一些项目。这里要大力感谢中科院的法斯特豪斯(知乎ID)同学先前的一些分享,给了我入门MLIR的方向。
0x2. 什么是IR?
IR即中间表示(Intermediate Representation),可以看作是一种中介的数据格式,便于模型在框架间转换。在深度学习中可以表示计算图的数据结构就可以称作一种IR,例如ONNX,TorchScript,TVM Relay等等。这里举几个例子介绍一下:
首先,ONNX是微软和FaceBook提出的一种IR,他持有了一套标准化算子格式。无论你使用哪种深度学习框架(Pytorch,TensorFlow,OneFlow)都可以将计算图转换成ONNX进行存储。然后各个部署框架只需要支持ONNX模型格式就可以简单的部署各个框架训练的模型了,解决了各个框架之间模型互转的复杂问题。
但ONNX设计没有考虑到一个问题,那就是各个框架的算子功能和实现并不是统一的。ONNX要支持所有框架所有版本的算子实现是不现实的,目前ONNX的算子版本已经有10代以上,这让用户非常痛苦。IR可以类比为计算机架构的指令集,但我们是肯定不能接受指令集频繁改动的。另外ONNX有一些控制流的算子如If,但支持得也很有限。
其次,TorchScript是Pytorch推出的一种IR,它是用来解决动态图模式执行代码速度太慢的问题。因为动态图模式在每次执行计算时都需要重新构造计算图(define by run),使得性能和可移植性都比较差。为了解决这个问题,Pytorch引入了即时编译(JIT)技术即TorchScript来解决这一问题。Pytorch早在1.0版本就引入了JIT技术并开放了C++ API,用户之后就可以使用Python编写的动态图代码训练模型然后利用JIT将模型(nn.Module)转换为语言无关的模型(TorchScript),使得C++ API可以方便的调用。并且TorchScript也很好的支持了控制流,即用户在Python层写的控制流可以在TorchScript模型中保存下来,是Pytorch主推的IR。
最后,Relay IR是一个函数式、可微的、静态的、针对机器学习的领域定制编程语言。Relay IR解决了普通DL框架不支持control flow(或者要借用python 的control flow,典型的比如TorchScript)以及dynamic shape的特点,使用lambda calculus作为基准IR。
Relay IR可以看成一门编程语言,在灵活性上比ONNX更强。但Relay IR并不是一个独立的IR,它和TVM相互耦合,这使得用户想使用Relay IR就需要基于TVM进行开发,这对一些用户来说是不可接受的。
这几个例子就是想要说明,深度学习中的IR只是一个深度学习框架,公司甚至是一个人定义的一种中介数据格式,它可以表示深度学习中的模型(由算子和数据构成)那么这种格式就是IR。
0x3. 为什么要引入MLIR?
目前深度学习领域的IR数量众多,很难有一个IR可以统一其它的IR,这种百花齐放的局面就造成了一些困境。我认为中科院的法斯特豪斯同学B站视频举的例子非常好,建议大家去看一下。这里说下我的理解,以TensorFlow Graph为例,它可以直接被转换到TensorRT的IR,nGraph IR,CoreML IR,TensorFlow Lite IR来直接进行部署。或者TensorFlow Graph可以被转为XLA HLO,然后用XLA编译器来对其进行Graph级别的优化得到优化后的XLA HLO,这个XLA HLO被喂给XLA编译器的后端进行硬件绑定式优化和Codegen。在这个过程中主要存在两个问题。
第一,IR的数量太多,开源要维护这么多套IR,每种IR都有自己的图优化Pass,这些Pass可能实现的功能是一样的,但无法在两种不同的IR中直接迁移。假设深度学习模型对应的DAG一共有10种图层优化Pass,要是为每种IR都实现10种图层优化Pass,那工作量是巨大的。
第二,如果出现了一种新的IR,开发者想把另外一种IR的图层优化Pass迁移过来,但由于这两种IR语法表示完全不同,除了借鉴优化Pass的思路之外,就丝毫不能从另外一种IR的Pass实现受益了,即互相迁移的难度比较大。此外,如果你想为一个IR添加一个Pass,难度也是不小的。举个例子你可以尝试为onnx添加一个图优化Pass,会发现这并不是一件简单的事,甚至需要我们去较为完整的学习ONNX源码。
第三,在上面的例子中优化后的XLA HLO直接被喂给XLA编译器后端产生LLVM IR然后Codegen,这个跨度是非常大的。这里怎么理解呢?我想到了一个例子。以优化GEMM来看,我们第一天学会三重for循环写一个naive的矩阵乘程序,然后第二天你就要求我用汇编做一个优化程度比较高的矩阵乘法程序?那我肯定是一脸懵逼的,只能git clone了,当然是学不会的。但如果你缓和一些,让我第二天去了解并行,第三天去了解分块,再给几天学习一下SIMD,再给几个月学习下汇编,没准一年下来我就可以真正的用汇编优化一个矩阵乘法了。所以跨度太大最大的问题在于,我们这种新手玩家很难参与。我之前分享过TVM的Codegen流程,虽然看起来理清了Codegen的调用链,但让我现在自己去实现一个完整的Codegen流程,那我是很难做到的。
针对上面的问题,MLIR(Multi-Level Intermediate Representation)被提出。MLIR是由LLVM团队开发和维护的一套编译器基础设施,它强调工具链的可重用性和可扩展性。下面我们具体分析一下:
针对第一个问题和第二个问题,造成这些深度学习领域IR的优化Pass不能统一的原因就是因为它们没有一个统一的表示,互转的难度高。因此MLIR提出了Dialect,我们可以将其理解为各种IR需要学习的语言,一旦某种IR学会这种语言,就可以基于这种语言将其重写为MLIR。Dialect将所有IR都放在了同一个命名空间里面,分别对每个IR定义对应的产生式以及绑定对应的操作,从而生成MLIR模型。关于Dialect我们后面会细讲,这篇文章先提一下,它是MLIR的核心组件之一。
针对第三个问题,怎么解决IR跨度大的问题?MLIR通过Dialect抽象出了多种不同级别的MLIR,下面展示官方提供的一些MLIR IR抽象,我们可以看到Dialect是对某一类IR或者一些数据结构相关操作进行抽象,比如llvm dialect就是对LLVM IR的抽象,tensor dialect就是对Tensor这种数据结构和操作进行抽象:
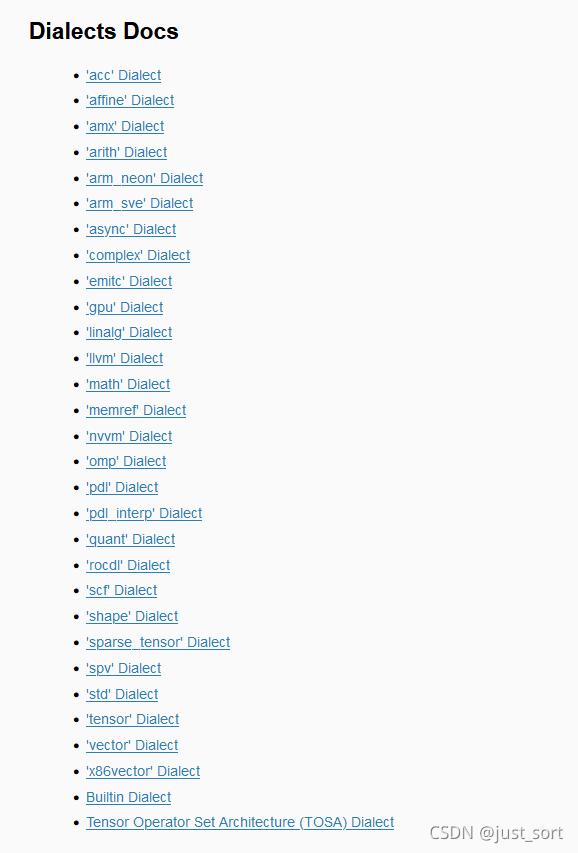
官网提供的MLIR Dialect
除了这些,各种深度学习框架都在接入MLIR,比如TensorFlow,Pytorch,OneFlow以及ONNX等等,大家都能在github找到对应工程。
抽象了多个级别的IR好处是什么呢?这就要结合MLIR的编译流程来看,MLIR的编译流程大致如下:
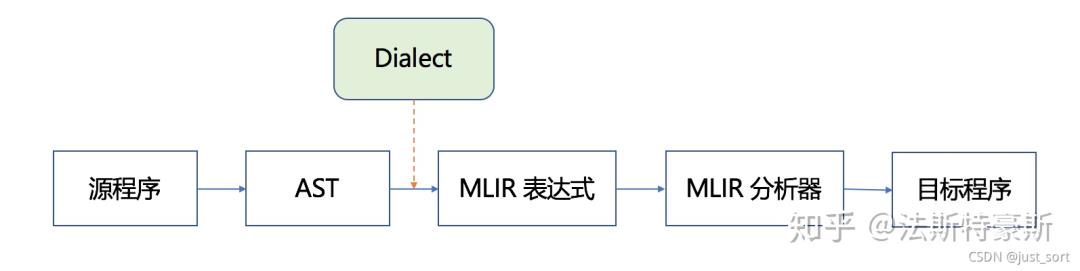
图源法斯特豪斯,侵删
对于一个源程序,首先经过语法树分析,然后通过Dialect将其下降为MLIR表达式,再经MLIR分析器得到目标程序。注意这个目标程序不一定是可运行的程序。比如假设第一次的目标程序是C语言程序,那么它可以作为下一次编译流程的源程序,通过Dialect下降为LLVM MLIR。这个LLVM MLIR即可以被MLIR中的JIT执行,也可以通过Dialect继续下降,下降到三地址码IR对应的MLIR,再被MLIR分析器解析获得可执行的机器码。
因此MLIR这个多级别的下降过程就类似于我们刚才介绍的可以渐进式学习,解决了IR到之间跨度太大的问题。比如我们不熟悉LLVM IR之后的层次,没有关系,我们交给LLVM编译器,我们去完成前面那部分的Dialect实现就可以了。
MLIR Toy Tutorials学习笔记
Toy语言和AST
MLIR提供了一种Toy语言来说明MLIR的定义和执行的流程。Toy语言是一种基于张量的语言,我们可以使用它来定义函数,执行一些数学计算以及输出结果。下面要介绍的例子中限制Tensor的维度是<=2的,并且Toy语言中唯一的数据类型是64位浮点类型,对应C语言中的"double"。另外Values是不可以重写的,即每个操作都会返回一个新分配的值,并自动管理释放。直接看下面这个例子:
def main()
# Define a variable `a` with shape <2, 3>, initialized with the literal value.
# The shape is inferred from the supplied literal.
var a = [[1, 2, 3], [4, 5, 6]];
# b is identical to a, the literal tensor is implicitly reshaped: defining new
# variables is the way to reshape tensors (element count must match).
var b<2, 3> = [1, 2, 3, 4, 5, 6];
# transpose() and print() are the only builtin, the following will transpose
# a and b and perform an element-wise multiplication before printing the result.
print(transpose(a) * transpose(b));
类型检查是通过类型推断静态执行的。Toy语言只需在必要时指定Tensor形状的类型声明。下面定义了一个multiply_transpose函数,注意这个函数里面参数a和b的形状我们预先都是不知道的,只有调用这个函数时我们才知道,可以关注一下下面例子中的shape变化。
# User defined generic function that operates on unknown shaped arguments.
def multiply_transpose(a, b)
return transpose(a) * transpose(b);
def main()
# Define a variable `a` with shape <2, 3>, initialized with the literal value.
var a = [[1, 2, 3], [4, 5, 6]];
var b<2, 3> = [1, 2, 3, 4, 5, 6];
# This call will specialize `multiply_transpose` with <2, 3> for both
# arguments and deduce a return type of <3, 2> in initialization of `c`.
var c = multiply_transpose(a, b);
# A second call to `multiply_transpose` with <2, 3> for both arguments will
# reuse the previously specialized and inferred version and return <3, 2>.
var d = multiply_transpose(b, a);
# A new call with <3, 2> (instead of <2, 3>) for both dimensions will
# trigger another specialization of `multiply_transpose`.
var e = multiply_transpose(b, c);
# Finally, calling into `multiply_transpose` with incompatible shape will
# trigger a shape inference error.
var f = multiply_transpose(transpose(a), c);
然后我们可以使用下面的命令来产生这个Toy语言程序的AST:
cd llvm-project/build/bin
./toyc-ch1 ../../mlir/test/Examples/Toy/Ch1/ast.toy --emit=ast
前提是要构建好llvm-project工程,构建过程按照https://mlir.llvm.org/getting_started/ 这里的方法操作即可,这里再列一下完整过程:
$ git clone https://github.com/llvm/llvm-project.git
$ mkdir llvm-project/build
$ cd llvm-project/build
$ cmake -G "Unix Makefiles" ../llvm \\
-DLLVM_ENABLE_PROJECTS=mlir \\
-DLLVM_BUILD_EXAMPLES=ON \\
-DLLVM_TARGETS_TO_BUILD="host" \\
-DCMAKE_BUILD_TYPE=Release \\
-DLLVM_ENABLE_ASSERTIONS=ON
$ cmake --build . --target check-mlir
上面Toy程序产生的AST长下面这样:
Module:
Function
Proto \'multiply_transpose\' @../../mlir/test/Examples/Toy/Ch1/ast.toy:4:1
Params: [a, b]
Block
Return
BinOp: * @../../mlir/test/Examples/Toy/Ch1/ast.toy:5:25
Call \'transpose\' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:5:10
var: a @../../mlir/test/Examples/Toy/Ch1/ast.toy:5:20
]
Call \'transpose\' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:5:25
var: b @../../mlir/test/Examples/Toy/Ch1/ast.toy:5:35
]
// Block
Function
Proto \'main\' @../../mlir/test/Examples/Toy/Ch1/ast.toy:8:1
Params: []
Block
VarDecl a<> @../../mlir/test/Examples/Toy/Ch1/ast.toy:11:3
Literal: <2, 3>[ <3>[ 1.000000e+00, 2.000000e+00, 3.000000e+00], <3>[ 4.000000e+00, 5.000000e+00, 6.000000e+00]] @../../mlir/test/Examples/Toy/Ch1/ast.toy:11:11
VarDecl b<2, 3> @../../mlir/test/Examples/Toy/Ch1/ast.toy:15:3
Literal: <6>[ 1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00, 5.000000e+00, 6.000000e+00] @../../mlir/test/Examples/Toy/Ch1/ast.toy:15:17
VarDecl c<> @../../mlir/test/Examples/Toy/Ch1/ast.toy:19:3
Call \'multiply_transpose\' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:19:11
var: a @../../mlir/test/Examples/Toy/Ch1/ast.toy:19:30
var: b @../../mlir/test/Examples/Toy/Ch1/ast.toy:19:33
]
VarDecl d<> @../../mlir/test/Examples/Toy/Ch1/ast.toy:22:3
Call \'multiply_transpose\' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:22:11
var: b @../../mlir/test/Examples/Toy/Ch1/ast.toy:22:30
var: a @../../mlir/test/Examples/Toy/Ch1/ast.toy:22:33
]
VarDecl e<> @../../mlir/test/Examples/Toy/Ch1/ast.toy:25:3
Call \'multiply_transpose\' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:25:11
var: b @../../mlir/test/Examples/Toy/Ch1/ast.toy:25:30
var: c @../../mlir/test/Examples/Toy/Ch1/ast.toy:25:33
]
VarDecl f<> @../../mlir/test/Examples/Toy/Ch1/ast.toy:28:3
Call \'multiply_transpose\' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:28:11
Call \'transpose\' [ @../../mlir/test/Examples/Toy/Ch1/ast.toy:28:30
var: a @../../mlir/test/Examples/Toy/Ch1/ast.toy:28:40
]
var: c @../../mlir/test/Examples/Toy/Ch1/ast.toy:28:44
]
// Block
AST的解析具体实现在mlir/examples/toy/Ch1/include/toy/Parser.h和mlir/examples/toy/Ch1/include/toy/Lexer.h中,感兴趣的读者可以看一下。我对这一块并不熟悉,就暂时不深入下去了,但这个AST看起来还是比较直观的,首先有两个Function对应了Toy程序里面的multiply_transpose和main,Params表示函数的输入参数,Proto表示这个函数在ast.toy文件中的行数和列数,BinOp表示transpose(a) * transpose(b)中的*是二元Op,并列出了左值和右值。其它的以此类推也比较好理解。
简单介绍了一下Toy语言的几个特点以及Toy示例程序产生的AST长什么样子,如果对AST的解析感兴趣可以去查看代码实现。
生成初级MLIR
MLIR 被设计成完全可扩展的基础框架,没有封闭的属性集、操作和类型。MLIR 通过Dialect(https://mlir.llvm.org/docs/LangRef/#dialects)的概念来支持这种可扩展性。Dialect在一个特定的namespace下为抽象提供了分组机制。
在MLIR里面,Operation是抽象和计算的核心单元,在许多方面与 LLVM 指定类似。具有特定于应用程序的语义,并且可以用于表示 LLVM 中的所有核心的 IR 结构:指令、globals(类似function)和模块。下面展示一个Toy语言产生的的transpose Operation。
%t_tensor = "toy.transpose"(%tensor) inplace = true : (tensor<2x3xf64>) -> tensor<3x2xf64> loc("example/file/path":12:1)
结构拆分解释:
%t_tensor:这个Operation定义的结果的名字,前面的%是避免冲突,见https://mlir.llvm.org/docs/LangRef/#identifiers-and-keywords 。一个Operation可以定义0或者多个结果(在Toy语言中,只有单结果的Operation),它们是SSA值。该名称在解析期间使用,但不是持久的(例如,它不会在 SSA 值的内存表示中进行跟踪)。
"toy.transpose" :Operation的名字。它应该是一个唯一的字符串,Dialect 的命名空间前缀为“.”。这可以理解为Toy Dialect 中的transpose Operation。
(%tensor):零个或多个输入操作数(或参数)的列表,它们是由其它操作定义或引用块参数的 SSA 值。
inplace = true :零个或多个属性的字典,这些属性是始终为常量的特殊操作数。在这里,我们定义了一个名为“inplace”的布尔属性,它的常量值为 true。
(tensor<2x3xf64>) -> tensor<3x2xf64>:函数形式表示的操作类型,前者是输入,后者是输出。<2x3xf64>号中间的内容描述了张量的尺寸2x3和张量中存储的数据类型f64,中间使用x连接。
loc("example/file/path":12:1):此操作的源代码中的位置。
了解了MLIR指令的基本结构后,我们把目光放到Chapter2要做什么事情上?即生成初级MLIR。我们执行下面的命令为Chapter2测试例子中的codegen.toy产生MLIR。
./toyc-ch2 ../../mlir/test/Examples/Toy/Ch2/codegen.toy -emit=mlir -mlir-print-debuginfo
其中codegen.toy的内容为:
def multiply_transpose(a, b)
return transpose(a) * transpose(b);
def main()
var a<2, 3> = [[1, 2, 3], [4, 5, 6]];
var b<2, 3> = [1, 2, 3, 4, 5, 6];
var c = multiply_transpose(a, b);
var d = multiply_transpose(b, a);
print(d);
产生的MLIR为:
module
func @multiply_transpose(%arg0: tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":4:1), %arg1: tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":4:1)) -> tensor<*xf64>
%0 = toy.transpose(%arg0 : tensor<*xf64>) to tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":5:10)
%1 = toy.transpose(%arg1 : tensor<*xf64>) to tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":5:25)
%2 = toy.mul %0, %1 : tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":5:25)
toy.return %2 : tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":5:3)
loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":4:1)
func @main()
%0 = toy.constant dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":9:17)
%1 = toy.reshape(%0 : tensor<2x3xf64>) to tensor<2x3xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":9:3)
%2 = toy.constant dense<[1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00, 5.000000e+00, 6.000000e+00]> : tensor<6xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":10:17)
%3 = toy.reshape(%2 : tensor<6xf64>) to tensor<2x3xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":10:3)
%4 = toy.generic_call @multiply_transpose(%1, %3) : (tensor<2x3xf64>, tensor<2x3xf64>) -> tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":11:11)
%5 = toy.generic_call @multiply_transpose(%3, %1) : (tensor<2x3xf64>, tensor<2x3xf64>) -> tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":12:11)
toy.print %5 : tensor<*xf64> loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":13:3)
toy.return loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":8:1)
loc("../../mlir/test/Examples/Toy/Ch2/codegen.toy":8:1)
loc(unknown)
我们需要弄清楚codegen.toy是如何产生的MLIR文件。也即下图的AST到MLIR表达式那部分(包含Dialect)。
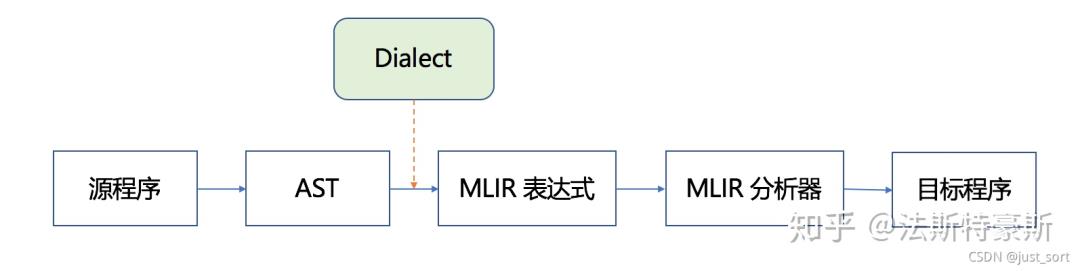
图源知乎法斯特豪斯,侵删
生成MLIR的流程
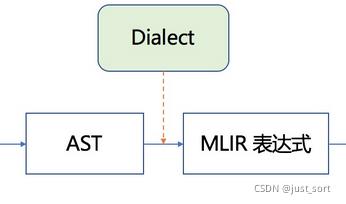
从AST到MLIR由是和Dialect相关的这部分
这里首先有一个MLIRGen函数负责遍历AST。具体在mlir/examples/toy/Ch2/mlir/MLIRGen.cpp文件中实现,里面有一个mlirGen函数,实现如下:
/// Dispatch codegen for the right expression subclass using RTTI.
mlir::Value mlirGen(ExprAST &expr)
switch (expr.getKind())
case toy::ExprAST::Expr_BinOp:
return mlirGen(cast<BinaryExprAST>(expr));
case toy::ExprAST::Expr_Var:
return mlirGen(cast<VariableExprAST>(expr));
case toy::ExprAST::Expr_Literal:
return mlirGen(cast<LiteralExprAST>(expr));
case toy::ExprAST::Expr_Call:
return mlirGen(cast<CallExprAST>(expr));
case toy::ExprAST::Expr_Num:
return mlirGen(cast<NumberExprAST>(expr));
default:
emitError(loc(expr.loc()))
<< "MLIR codegen encountered an unhandled expr kind \'"
<< Twine(expr.getKind()) << "\'";
return nullptr;
这个函数会根据AST中的节点类型递归调用其它的mlirGen子函数,并在各个子函数完成真正的转换MLIR表达式的操作。以上面codege.toy的transpose(a)操作为例,对应的mlirGen子函数为:
/// Emit a call expression. It emits specific operations for the `transpose`
/// builtin. Other identifiers are assumed to be user-defined functions.
mlir::Value mlirGen(CallExprAST &call)
llvm::StringRef callee = call.getCallee();
auto location = loc(call.loc());
// Codegen the operands first.
SmallVector<mlir::Value, 4> operands;
for (auto &expr : call.getArgs())
auto arg = mlirGen(*expr);
if (!arg)
return nullptr;
operands.push_back(arg);
// Builtin calls have their custom operation, meaning this is a
// straightforward emission.
if (callee == "transpose")
if (call.getArgs().size() != 1)
emitError(location, "MLIR codegen encountered an error: toy.transpose "
"does not accept multiple arguments");
return nullptr;
return builder.create<TransposeOp>(location, operands[0]);
// Otherwise this is a call to a user-defined function. Calls to
// user-defined functions are mapped to a custom call that takes the callee
// name as an attribute.
return builder.create<GenericCallOp>(location, callee, operands);
我们可以看到if (callee == "transpose")这里是对函数签名进行判断,如果是transpose 那么就需要新建一个TransposeOp类型的MLIR节点,即builder.create<TransposeOp>(location, operands[0])。这行代码涉及到MLIR的Dialect和TableGen,我们详细解释一下。
在【从零开始学深度学习编译器】十一,初识MLIR 中已经说过,MLIR是通过Dialect来统一各种不同级别的IR,即负责定义各种Operation和解析,同时还具有可扩展性。在Toy语言中我们也定义了Dialect,定义这个Dialect的时候是通过TableGen规范来定义到mlir/examples/toy/Ch2/include/toy/Ops.td中的。
// Provide a definition of the \'toy\' dialect in the ODS framework so that we
// can define our operations.
def Toy_Dialect : Dialect
let name = "toy";
let cppNamespace = "::mlir::toy";
在MLIR中,Dialect和Operation(也可以说算子)的定义是框架是基于TableGen(一种声明性编程语言)规范构造的,在源码中它以.td的格式存在,在编译时会自动生成对应的C++文件,生成定义好的Dialect。使用TableGen的好处不仅是因为它是声明性的语言让新增Dialect和Operation变得简单,而且容易修改和维护。可能我解释得不是很直观,但我们可以直接结合Chapter2的代码mlir/examples/toy/Ch2/include/toy/Ops.td 来理解。后面我们会看到在Toy语言的示例中,.td文件的组成以及TableGen是如何自动解析.td生成C++代码的。
这里首先在td中定义一下Toy Dialect,并建立和Dialect的链接,它负责将后续在Toy Dialect空间下定义的所有Operation联系起来。即:
// Provide a definition of the \'toy\' dialect in the ODS framework so that we
// can define our operations.
def Toy_Dialect : Dialect
let name = "toy";
let cppNamespace = "::mlir::toy";
然后构造一个Toy_Op类代表Toy Dialect下所有Operation的基类,后面新增Operation都需要继承这个类。
// Base class for toy dialect operations. This operation inherits from the base
// `Op` class in OpBase.td, and provides:
// * The parent dialect of the operation.
// * The mnemonic for the operation, or the name without the dialect prefix.
// * A list of traits for the operation.
class Toy_Op<string mnemonic, list<OpTrait> traits = []> :
Op<Toy_Dialect, mnemonic, traits>;
下面给出transpose Operation的定义感受一下:
def TransposeOp : Toy_Op<"transpose">
let summary = "transpose operation";
let arguments = (ins F64Tensor:$input);
let results = (outs F64Tensor);
let assemblyFormat = [
`(` $input `:` type($input) `)` attr-dict `to` type(results)
];
// Allow building a TransposeOp with from the input operand.
let builders = [
OpBuilder<(ins "Value":$input)>
];
// Invoke a static verify method to verify this transpose operation.
let verifier = [ return ::verify(*this); ];
在继承Toy_Op的基础上,还使用TableGen语法定义了描述信息,参数,值,builder,verfier这些元素。
编写完td文件之后,就可以使用mlir-tblgen工具生成C++代码,先使用下面的命令生成Dialect的C++代码:./mlir-tblgen -gen-dialect-decls llvm-project/mlir/examples/toy/Ch2/include/toy/Ops.td -I ../../mlir/include/
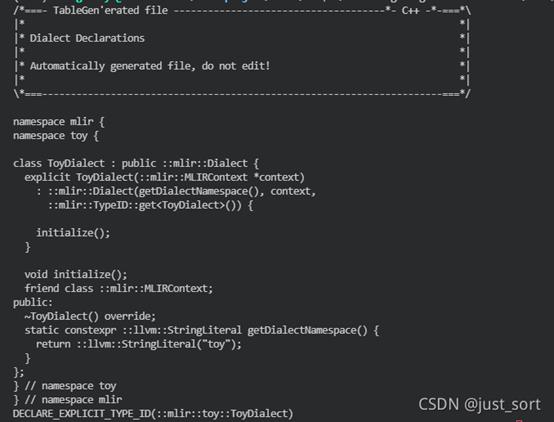
自动生成的Toy Dialect C++代码
把上面的命令换成./mlir-tblgen -gen-op-defs llvm-project/mlir/examples/toy/Ch2/include/toy/Ops.td -I ../../mlir/include/ 就可以生成Operation的C++代码。感兴趣的读者可自行查看。
与工具链 toyc-ch2 的联系,查看CMakeList.txt 文件(默认位置为 llvm-project/mlir/examples/toy/Ch2/include/toy):
set(LLVM_TARGET_DEFINITIONS Ops.td)
mlir_tablegen(Ops.h.inc -gen-op-decls)
mlir_tablegen(Ops.cpp.inc -gen-op-defs)
mlir_tablegen(Dialect.h.inc -gen-dialect-decls)
mlir_tablegen(Dialect.cpp.inc -gen-dialect-defs)
add_public_tablegen_target(ToyCh2OpsIncGen)
使用mlir-tblgen搭配 -gen-op-decls 和 -gen-op-defs 选项,生成 Ops.h.inc 声明代码和 Ops.cpp.inc 定义代码,将两者作为构建工具链 toyc-ch2 的代码依赖。
总结一下,Chapter2主要介绍了MLIR中的MLIRGen,Dialect,Operation以及TableGen这几个MLIR的核心组成部分以及它们是如何相互作用的。它们的关系可以借用中科院Zhang Hongbin同学的PPT来更好的描述:

图源知乎法斯特豪斯,为了方便理解借用到这里,侵删
参考文献链接
https://mp.weixin.qq.com/s/4pD00N9HnPiIYUOGSnSuIw
https://mp.weixin.qq.com/s/jMHesvKmAUU5dYH0WznulA
MLIR编译器调度与优化点滴
MLIR编译器调度与优化点滴
MLIR编译框架下软硬协同设计的思考
自从AI芯片成为热门的研究课题,众多关于AI芯片架构探索的学术文章不断涌现,大家从不同的角度对AI芯片进行架构分析及性能优化。MLIR是谷歌团队推出的开源编译器框架,颇受瞩目,灵活的编译器架构提升了其在众多领域应用的潜力。通过自定义IR的衔接,可以在架构探索和MLIR之间架起一座桥梁,在编译的过程中,自动进行硬件架构的探索和软件的优化编译,甚至生成硬件的代码,实现软硬协同设计。
架构探索方法的介绍
近十年,AI领域专用芯片的演进极大地促进了架构探索(指架构定义及性能分析)的发展,先后出现了众多的分析方法,这些分析方法针对AI计算过程中关键算子以及网络模型进行建模分析,从PPA(Power-Performance-Area)三个角度评估硬件性能。与此同时,伴随着AI编译框架的发展,尤其受益于MLIR编译器框架的可复用及可扩展性(详见MLIR多层编译框架实现全同态加密的讨论),将这些分析方法融入到MLIR框架中也变得十分可能,从而使用编译器对硬件架构进行探索。
架构分析中关注三个方面的表达,分别是计算架构(Computation Element),存储结构(Memory Hierarchy )和互联结构(Interconnect)。对硬件架构进行性能分析时,数据流是搭建分析方法的基础,根据数据流的表达,将workload的计算过程映射到硬件架构的三类实现中。在学术研究中,Eyeriss [1]是较早将数据流引入到AI芯片的性能分析中,根据定义,AI的数据流可以分为三类,输出静止(Output Stationary),权重静止(Weight Stationary)和行静止(Row Stationary)。随后的研究中,MAGNet[2]将其扩种为更多的描述方式,如图1所示,但还是围绕OS,WS和RS展开。根据数据流的划分,AI架构既可以分为这三类,比如NVDLA属于WS,Shi-dinanao属于OS,Eyeriss属于RS。相同的数据流架构可以采用类似的方法进行分析。

图1 不同数据流对应的for-loop表示[2]
围绕数据流表示和硬件映射的表达上,可以归为三类,分别是以计算为中心 (computation-centric)的Timeloop[3], 以数据流为中心(data-centric)的MAESTRO[4]和以关系为中心(relation-centric)的TENET[5]。以计算为中心的表示方法关注的是for-loop表达在时间维度上映射到硬件架构;以数据流为中心的表达关注的是数据映射(data mapping)和复用(reuse);以关系为中心的表达关注循环表达和计算单元及调度之间的关系。将对第二种data-centric的表达方式展开。
在MAESTRO的工作中,将data mapping和reuse作为一等公民,关注的是数据在时间和空间两个维度的复用。对于WS的计算架构,weight在时间维度上复用(相当于保持不变),中间计算结果是在空间维度上复用,其复用如图2所示。
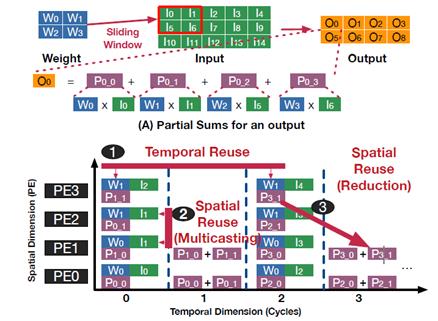
图2 2x2kernel的卷积在WS类型加速器数据复用的表示[4] 关于时间和空间数据复用的表达,文中提出了一种IR的表示方式,我们称之为时域映射(Temporal Map)和空域映射(Spatial Map)。时域映射表示特定的维度与单个PE之间的映射关系,空域映射表示的是特定的维度与多个PE之间的映射关系,具体的表示如下:1.T(size, offset)α:α表示的特定的维度,比如权重的weight,width及channel等,size表示单个时间步长(time step)下α所在维度的index映射到单个PE的尺寸,offset表示的是相邻的时间步长的index偏移。对应的for循环表达如图3所示。2.S(size, offset):α表示特定的维度,size表示维度α映射到每个PE的index的尺寸,offset表示映射到相邻PE的index偏移。

图3 时域和空域映射与循环表达之间的对应关系[4]
假设一个计算架构有3个PE,卷积的权重大小为6,输入元素个数为17,步进为1,计算过程可以通过图4表示。在图中,标签1表示for循环的表达,标签2表示在时域和空域的IR表达,标签3表示数据在PE的分布及时间上的计算过程,图中可以看出cycle1到cycle4复用S中的index(1),也就是weight保持静止。标签4表示空域映射、时域映射以及计算顺序,其中t表示按照所示的箭头方向依次计算。基于这样的IR表达及时间上的计算过程,就可以表示出一个WS架构的计算过程。
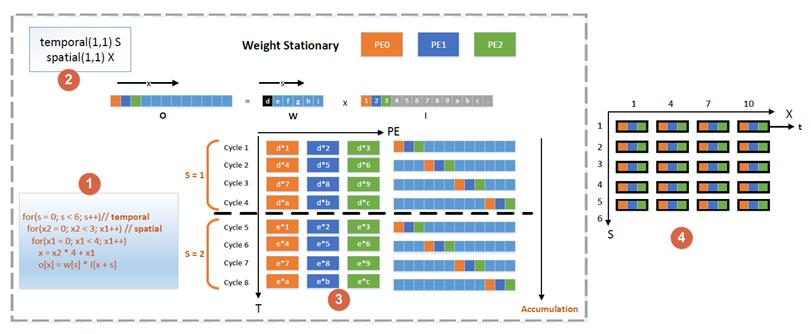
图4 1D卷积操作在时域和空域的表示演示图
基于IR的性能分析方法
Aladdin[6]是较早开展基于编译的方式进行硬件的性能分析,将性能分析提前到RTL代码之前,避免了RTL代码及C-model大量的开发工作,基本的思路是将计算任务lowering到动态数据依赖图(DDDG:Dynamic Data Dependence Graph)级别,DDDG是针对特定架构的中间表达(Intermediate Representation)的表示,如图5所示。针对特定的硬件架构,分析DDDG的动态执行过程,即可评估出性能和功耗的数据,他们基于ILDJIT compiler IR[7]。

图5 DDDG的计算表示[6]
基于GEM5的工作,他们将其扩展为GEM5-Aladdin,用于对加速器系统级的性能分析,涵盖了SoC的接口通信开销,从而实现加速器架构和通信的协同设计。GEM5负责CPU和内存系统的性能分析,Aladdin负责加速器的性能分析。DDDG的表示从ILDJIT IR迁移到LLVMIR。
Interstellar[8]是将Halide语言用于AI架构的性能分析,数据流表达的方式属于computation-centric,核心工作是将和计算及数据流相关的for-loop转换到Halide的scheduling language,同时显性表达存储和计算。其中,关于架构和数据流是在Halide编译过程中的IR表达中引入,同时和Halide语言中的hardware primitive对应起来,将整个计算过程拆解到IR级别,然后映射到硬件结构,最后根据数据流的计算过程评估硬件的性能,整体过程如图6所示。最终采用调用硬件语言代码库的方式生成硬件设计。

图6 标签1为Halide语言描述conv操作;标签2表示Halide Lowering过程中对in, compute_at, split及reorder调度原语(scheduling primitives)的IR表示;标签3表示调度原语和硬件架构的对应关系[8]
架构级别的IR
Micro-IR[9]文章的核心思想是将加速器的架构表示为一个并发的结构图(Concurrent Structural Graph),每个组件就是一个架构级别的硬件单元,比如计算单元、网络或者存储器。结构图中显性地表达了加速器的构成组件,以及不同组件之间的数据流动,最终回归到数据流的表达和实现上。定义架构级别IR的好处在于1)将算法的表达和硬件架构解耦,2)将硬件的优化和RTL的代码实现解耦。这样一来,硬件架构IR层的优化工作可以单独展开。
整个编译的架构基于LLVM的实现,前端接入为AI framework,然后编译到LLVM IR,LLVM IR再对接到Micro-IR,在Micro-IR优化的PASS中聚焦就是前文提及到的关于数据流的映射、调度,tiling以及映射到硬件的intrinsic。最后对接到chisel的IR FIRTL,生成可综合的硬件语言。
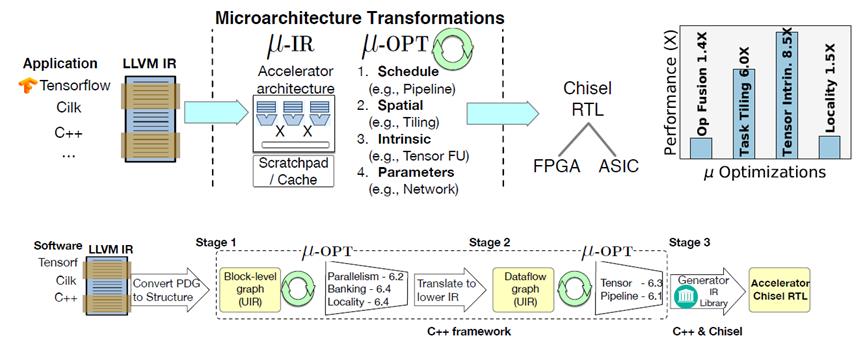
图7 Micro-IR的编译流程[9]
对于架构的表达,也是围绕数据流、存储和互联的展开,如图8所示,将一个简单的奇偶乘法翻译到IR图层,再翻译到IR的具体表达。
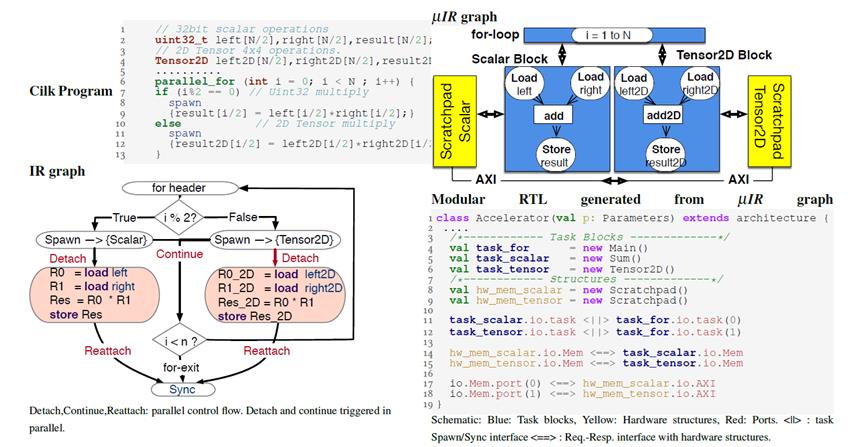
图8 Micro-IR的编译表示[9]
MLIR中引入架构探索的可能性和挑战
可能性:1.经过上述章节的分析发现现有的性能分析方法的研究工作都有IR表示的思想,而且基于数据流的表示思想具有较好的理论基础,从时域和空域两个维度展开,也有很好的IR具体实现。2.基于IR性能分析的方法也处于不断演进的过程中,从ILDJIT到LLVM再到Halide,都证实了基于IR进行架构探索的可行性。同时不同的表示方式具有不同的有点,比如Halide中突出调度的思想,可以将该思想引入到MLIR中,形成schedule IR。3.关于硬件架构IR表示的文章也较多,比如Spatial[10],文中举例的micro-IR 是比较典型的标准,与MLIR都基于LLVM的编译流程,将其引入到MLIR中作为硬件架构存在可能性。4.Union[11]是将MAESTRO性能分析的工作引入到MLIR的框架中,但是MAESTRO是作为架构探索的工具使用,没有接入到MLIR的编译流程中。
挑战:1.目前的架构探索都是基于相对规则的架构展开,没有涉及到复杂的工业界的芯片,存有一定的局限性,将其方法应用到工业界还有很大的隔阂。2.定义一个通用型的架构IR比较困难。架构是比较分散的,不同的任务需求有不同的架构设计,虽然架构设计从大的层面分为计算、存储和互联,但通过IR精准地刻画架构充满挑战,比如对于架构IR控制流的表示,Micro-IR中关于控制流的表达没有进行详细的阐述。3.在编译过程中,如何将软件任务能够自动翻译到架构IR上,同时能够对硬件架构进行自动调整和优化,这也是很大的挑战。目前是针对特定的已知架构,将计算任务映射到硬件。
总结了现有的针对AI架构的数据流分析方法,以及基于数据流分析方法构建的架构探索工具,同时介绍了现有的硬件架构的IR。这些丰富的分析方法和IR表示为架构探索引入到MLIR提供了可能性,也让我们看到了基于MLIR的编译器框架开展软硬协同设计的巨大潜力。
基于MLIR实现GEMM编译优化
GEMM(General Matrix Multiplication)即通用矩阵乘法运算,由于其计算行为具有一定的复杂性以及规律性,是编译算法研究的绝佳场景。MLIR是近期非常热门的一个编译器软件框架,是工业界及科研界研究的一个热点,其提供了一套灵活的软件基础设施,对中间表达式(IR)及其相互之间的转换进行规范的管理,是一个非常友好的编译器开发平台[1][2]。即是分析在MLIR框架下,实现GEMM优化的内容,以及对MLIR在这一方面的实现优势的讨论。
GEMM优化策略介绍
矩阵乘法运算,由于其过程会包含大量的乘加操作,并且伴随大量的数据读写,因而如何充分利用好底层硬件的存储资源以及计算资源,是编译器对其性能优化的关键。目前,已有的一些优化策略主要包括:
1.矩阵分块(Tile)
当前的处理器性能主要受限于内存墙,即计算速度要大于数据存储的速度。为了打破内存墙的约束,各类硬件包括CPU及其他专用处理器,会设置不同层次的存储单元,而这些不同层级的存储单元往往大小以及读写速度不同,一般越靠近计算单元的存储其存储容量也越小但访问的速度也越快。如果可以将计算过程的数据局部化分块,而这些分块的数据可以独立完成计算,那么分块的数据就可以放在层次化的存储中,然后通过不同存储间建立Ping-Pong的数据传输方式,将数据存储与计算解耦,从而可以有效得隐藏存储墙的问题,提高计算效率。矩阵运算就有这种特点,因而可以通过矩阵分块来加速运算,如下图1所示,假设有两层存储,将输入矩阵A和B,以及输出矩阵C,根据存储大小划分成相应的小块,即m->mc,n->nc,k->kc,每次将Ac(mc, kc), Bc(kc,nc), Cc(mc, nc)送入到离计算单元更近的存储模块内,完成局部的计算后再进行下一次的计算。

图1 矩阵运算的Tile操作示意图
在不同的底层硬件中,由于存储的层次以及不同层次的存储的容量大小不一样,分块的大小也会不一样。比如,文章[3]中对CPU而言,(Ac, Bc, Cc)划块的大小与cache大小一致,而为了充分利用register的资源,还会对(Ac, Bc, Cc)再进一步细划块成(Ar, Br, Cr),其尺寸大小与寄存器的数量一致。
2.向量化(Vectorize)
向量化的操作,主要是利用硬件的向量化指令或者SIMD(单指令多数)指令的特性,实现一个指令周期对多个值操作的能力。如下图2所示,通过将4个数据组成向量,利用处理器可以处理4个元素的新向量的计算能力,可以将4个指令周期的处理时间,压缩成1个指令周期的处理时间,从而极大提高运算处理能力。

图2 vectorize操作示意图
3.循环展开(Unroll)
由于矩阵乘法有多层循环构成,如果底层硬件有一定的并行化能力,包括多线程多进程处理能力等,那么可以对循环进行适当展开,从而提高计算的并行度,增加并发执行的机会。如下图3所示,将一个次数为1024的循环,展开成256次循环,新的循环内又包含4条可以并行执行的展开计算,如果处理器能够并行处理循环内部的展开计算,那么通过对原来的循环展开,可以获得接近4倍的性能提升。

图3 循环展开操作示意图
矩阵乘法的运算也包括其他的优化策略,比如数据重排等,但总体而言,各类编译器都是利用这些策略,充分利用硬件的存储及计算资源,达到最佳的运算效率。一些传统的计算库,如:OpenBLAS, BLIS, MKL等,开发时间长,性能也有比较优秀的表现。
MLIR实现GEMM优化
MLIR基于多层中间表示的方言(Dialect)思想,提供了一整套完善的编译器基础框架,可以帮助开发者快速实现编译策略想法的编译器。主要参考论文[4],分析GEMM运算在MLIR中的实现,对应的硬件Target是因特尔i7-8700K处理器,每个核包含有32/256KB L1/L2 Cache以及多核共享的12MB L3 Cache,处理器支持AVX-2指令(256bit),优化目标是一个2088x2048xf64与2048x2048xf64的矩阵乘。
首先,其在高层次的Dialect上定义了一个矩阵运算的算子,这个算子的参数包含了输入矩阵(A,B)以及输出矩阵(C),同时为这个算子添加了tile/unroll 的尺寸等属性。如下图4所示,其中(M_C, K_C, M_R, N_R)属于Tile尺寸,K_U属于Unroll的大小。这里面(M_C, K_C)的选择是使得M_CxK_C大小的A矩阵块能够在L2 cache中复用,(K_C, N_R)的选择是使得K_CxN_R大小的B矩阵块能够在L1 cache中复用,(M_R, N_R)的选择是使得M_RxN_R大小的输出矩阵块能够在CPU Register中复用,这些值是根据硬件计算或者tunning出来的,在这里面的测试取了一个经验值。这些属性可以协助转换到更低一层的算子的策略实现,而选择哪些属性,则是跟编译算法以及编译的底层硬件对象有关,这些属性也是协助转换成下一层跟硬件更贴近的中间表示的实现,因而可以根据实际需要,灵活使用。

图4 GEMM算子的高层次定义
其次,MLIR的特点就是通过统一的多层中间表示,来实现对算子的层层低层化(lower)到具体的硬件目标上。针对上述高层次上定义的矩阵乘法算子,通过利用其所携带的优化属性,以及底层硬件的特点,设计了多条转换的路径(Pass),从而进一步把该算子lower到MLIR框架提供的中间辅助层(此中选择了Affine, Linalg,和Standard Dialect)。在这一层的转换过程中,基本包含了所有的策略,如:Tile,定制化复制,unroll,vectorize等。然后再将中间的辅组层的Dialect,进一步lower到LLVM Dialect上,如下图5所示。
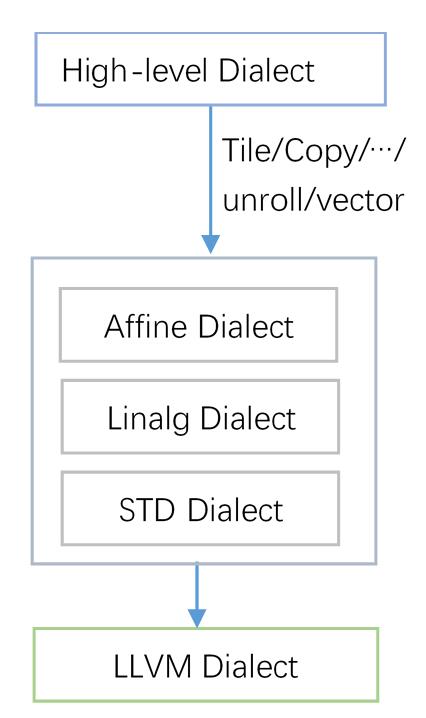
图5 GEMM算子Lowing的层次化Dialect示意图
最后,通过mlir提供的mlir-cpu-runner工具,可以运行最后生成的LLVM Dialect的结果。总体优化及运行测试的命令,如下图6所示。其中,“-hopt”,“-hopt-vect”等,是从高层的算子(hop.matmul)到中间辅组层的转换路径,每一条路径都包含有相应的编译策略,可以根据需要,灵活添加以及改变,“-convert-linalg-to-loops”, “-lower-affine”等时中间辅助层之间的转换,最后转换成LLVM Dialect。

图6 MLIR运行GEMM的命令示意图
总体上,一个GEMM运算通过在MLIR框架下实现,并重写优化策略的路径,可以得到如图7所示的结果,其中箭头1对应包含了所有重写优化策略的MLIR实现,可以看到其能达到的计算速率为61.94GFLOPS,离理论上的峰值计算速率(75.2GFLOPS)比较接近,跟传统的计算库相比(如:BLIS,OpenBLAS,MKL等),也有着可以媲美的结果,其中的差距可能是传统的计算库有tunning的机制以及在编译器后端生成汇编指令及机器码有更成熟且高效的优化,因而可以得到更好的优化结果。总体而言,用MLIR重写的GEMM优化算法有着非常良好的表现。
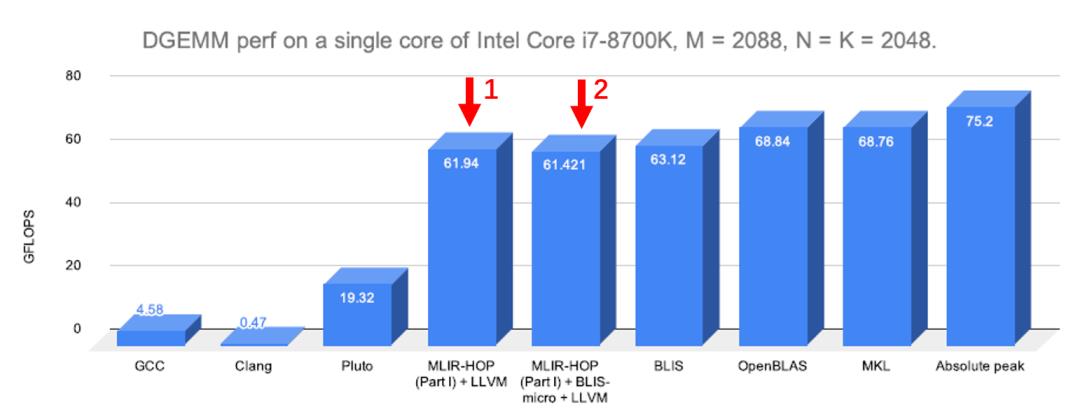
图7 MLIR编译运行结果与其他计算库的对比示意图
另一方面,MLIR框架提供了非常完善的C++以及Python接口,因而可以很方便接入已有的计算库,进行联合优化。在[4]文中尝试了用MLIR+BLIS的方法,将MLIR放在外侧(提供手动优化功能),BLIS则作为micro-kernel放在内侧(提供auto tunning功能),最终的结果如图7中箭头2所示。可以看出,对于DGEMM(双精度),通过MLIR与BLIS的联合优化,也可以达到接近峰值的性能,而其性能要比单独的MLIR或者BLIS优化要差一点。但其实在SGEMM(单精度)的测试中,MLIR+BLIS的优化又要比单独的MLIR或者BLIS优化要好一些,因而其中的性能在差异还需要进一步分析。总体而言,MLIR提供了非常完善的支持,可以融合已有的计算库的优化算法,去实现联合的编译优化。
MLIR实现GEMM优化的优势
通过上面对MLIR实现GEMM优化算法的编译的介绍,可以看出MLIR在其中有着非常突出的优势。
首先,MLIR框架提供了非常完善的编译器基础设施,可以让开发者不需要花费太多精力在编译器周边的实现,从而更加专注于编译算法的开发。同时,其基于多层中间表达的方式,可以让编译器更加模块化,可以让编译算法利用不同层次的中间表达的抽象信息,在不同的层次中逐步具体化,从而使得算法实现更加层次化,更加易于实现及管理。
其次,MLIR框架提供了一直到最底层硬件的表示支持,由于其可以层次化在不同的中间表示层实现编译算法,可以在高层次的中间表示中实现不依赖于底层硬件的通用算法,而在接近硬件底层中,开发针对性的路径实现相应的编译算法,因而可以很方便地针对不同硬件目标开发统一的编译环境。本人认为,这也是MLIR相对于一些现有的AI编译器,如:TVM等,最有优势的地方之一,由于其框架可以根据需要自行扩展Dialect,同时这些Dialect又在系统中遵循一套统一的范式进行管理,因而对不同的编译目标(硬件target)会有很强的扩展性,同时编译器的工程管理又可以做到非常好的统一性。
另外,MLIR框架提供了完善的C++/Python接口,可以很方便地接入已有的优化算法,快速实现算法迁移。
主要介绍了矩阵乘法运算在MLIR编译器框架实现的主要过程及内容,以及其在优化算法的多层次实现,以及接入已有优化算法的能力等方面的优势。MLIR编译框架,为编译器的开发者,在多层中间表达转换以及算法优化等方面提供强大的基础设施支持,降低开发编译器的门槛。
参考文献链接
https://mp.weixin.qq.com/s/s5_tA28L94arLdm5UijkZg
https://mp.weixin.qq.com/s/A1h4pJSJ8VF97DrZksNULg
[1] Y. Chen, J. Emer, and V. Sze, “Eyeriss: A spatial architecture for energy efficient dataflow for convolutional neural networks,” in Proc. ISCA,2016.
[2] R. Venkatesan, Y. S. Shao, M. Wang, J. Clemons, S. Dai, M. Fojtik, B. Keller, A. Klinefelter, N. R. Pinckney, P. Raina et al., “MAGNet: A Modular Accelerator Generator for Neural Networks,” in ICCAD, 2019
[3] A. Parashar, P. Raina, Y. S. Shao, Y. Chen, V. A. Ying, A. Mukkara, R. Venkatesan, B. Khailany, S. W. Keckler, and J. Emer, “Timeloop: A Systematic Approach to DNN Accelerator Evaluation,” in 2019 IEEE International Symposium on Performance Analysis of Systems and
Software, 2019
[4] H. Kwon, P. Chatarasi, V. Sarkar, T. Krishna, M. Pellauer, and A. Parashar, “Maestro: A data-centric approach to understand reuse, performance, and hardware cost of dnn mappings,” IEEE Micro, 2020.
[5] L. Lu, N. Guan, Y. Wang, L. Jia, Z. Luo, J. Yin, J. Cong, and Y. Liang, “TENET: A Framework for Modeling Tensor Dataflow Based on Relation-centric Notation,” in 2021 ACM/IEEE 48rd Annual International Symposium on Computer Architecture, 2021.
[6] S. Shao, B. Reagen, G.-Y. Wei, and D. Brooks, “Aladdin: A Pre-RTL, Power-Performance Accelerator Simulator Enabling Large Design Space Exploration of Customized Architectures,” in ISCA, 2014.
[7] S. Campanoni, G. Agosta, S. Crespi-Reghizzi, and A. D. Biagio, “A highly flexible, parallel virtual machine: Design and experience of ildjit,” Software Practice Expererience, 2010.
[8] X. Yang, M. Gao, Q. Liu, J. Setter, J. Pu, A. Nayak, S. Bell, K. Cao, H. Ha, P. Raina, C. Kozyrakis, and M. Horowitz, “Interstellar: Using halide’s scheduling language to analyze dnn accelerators,” in Proceedings of the Twenty-Fifth International Conference on Architectural
Support for Programming Languages and Operating Systems (ASPLOS), 2020.
[9] Sharifian, Amirali & Hojabr, Reza & Rahimi, Navid & Liu, Sihao & Guha, Apala & Nowatzki, Tony & Shriraman, Arrvindh. (2019). μIR -An intermediate representation for transforming and optimizing the microarchitecture of application accelerators. 940-953. 10.1145/3352460.3358292.
[10] David Koeplinger, MatthewFeldman, Raghu Prabhakar, Yaqi Zhang, Stefan Hadjis, Ruben Fiszel, Tian Zhao, Luigi Nardi, Ardavan Pedram, Christos Kozyrakis, and Kunle Olukotun. 2018. Spatial: A Language and Compiler for Application Accelerators. In Proceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI 2018).
[11] Geonhwa Jeong, Gokcen Kestor, Prasanth Chatarasi, Angshuman Parashar, Po-An Tsai, Sivasankaran Rajamanickam, Roberto Gioiosa, Tushar Krishna: Union: A Unified HW-SW Co-Design Ecosystem in MLIR for Evaluating Tensor Operations on Spatial Accelerators. CoRR abs/2109.07419 (2021)
[1] Chris Lattner, Mehdi Amini,Uday Bondhugula, Albert Cohen, Andy Davis, Jacques Pienaar, River Riddle,Tatiana Shpeisman, Nicolas Vasilache, and Oleksandr Zinenko. Mlir: A compiler infrastructure for the end of moore\'s law, 2020
[2] MLIR:https://mlir.llvm.org/
[3] Tze Meng Low, etc. Analytical Modeling Is Enough for High-Performance BLIS. 2016.
[4] UdayBondhugula, High Performance Code Generation in MLIR: An Early Case Study With GEMM. 2020.
以上是关于MLIR基础及开发初探分析的主要内容,如果未能解决你的问题,请参考以下文章