Python怎样获取XPath下的A标签的内容
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python怎样获取XPath下的A标签的内容相关的知识,希望对你有一定的参考价值。
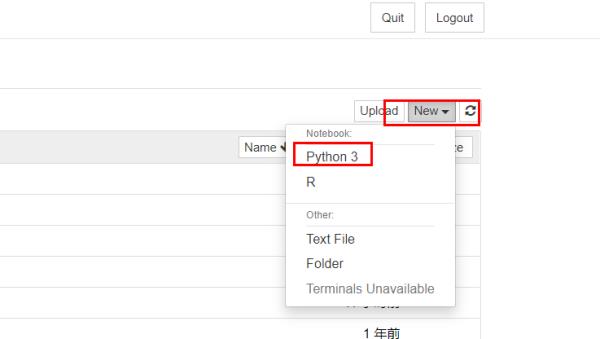
参考技术A1、首先打开jupyter notebook,在主界面的右边点击New,选择Python3新建一个Python文件:
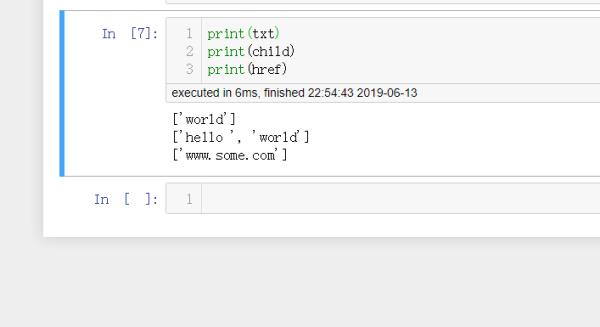
2、然后首先引入lxml包,定义一段html文本,用etree中和HTML方法导入上述html文本,然后就可以用xpath定位A标签的内容了,定位用的的函数是text方法,最后把结果打印出来即可:

3、最后运行所有的cell中的代码,即可拿到A标签的内容了。以上就是Python获取XPath下的A标签的内容的方法演示:
Xpath基础学习
方法
-
获取文本
a/text()获取a标签下的文本a//text()获取a标签下所有标签的文本a[text()=‘xxx‘]获取文本为xxx的a标签
-
@符号a/@href获取a标签的href的属性,其他属性获取方法相同a[@class=‘xxx‘]获取class属性为xxx的a标签
-
//获取当前位置下的所有标签a//sapn获取a标签下的所有的span标签
例子
获取豆瓣电影排行榜的所有电影名:
1、
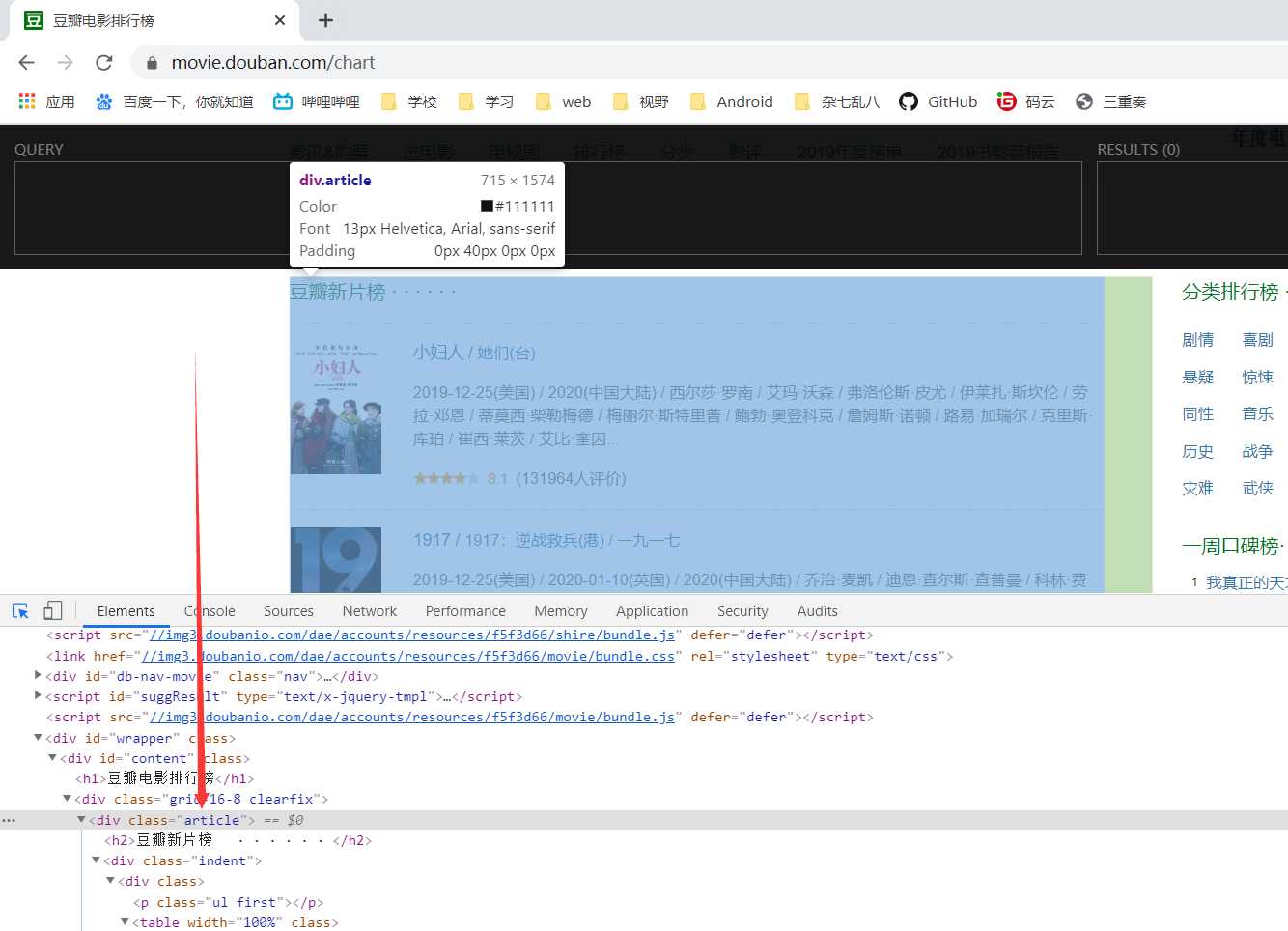
我们可以看到属于类为article的div,我们写上//div[@class=‘article‘]
2、我们进一步发现该div下只有一个div,于是可以加上/div,这样所有的影片块就被选中了
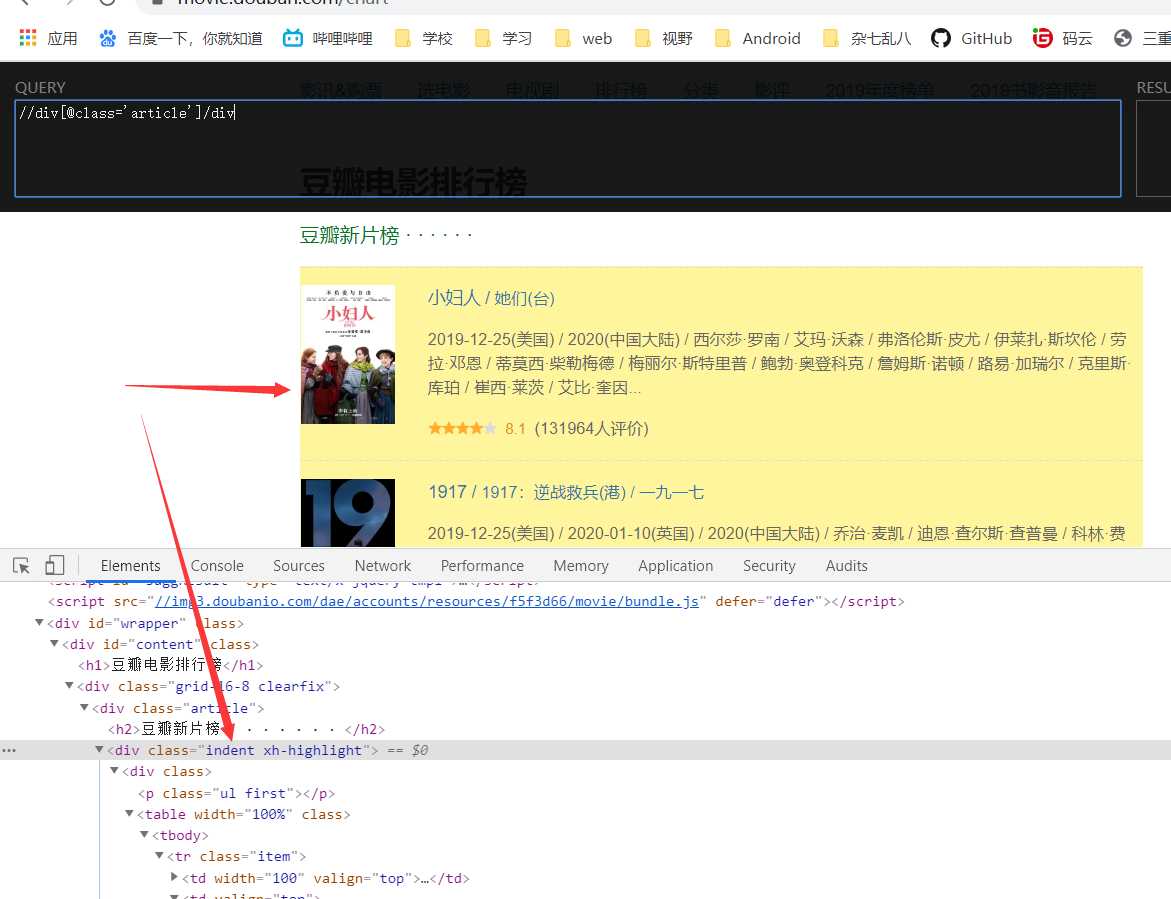
3、观察发现每一个电影都是一个table
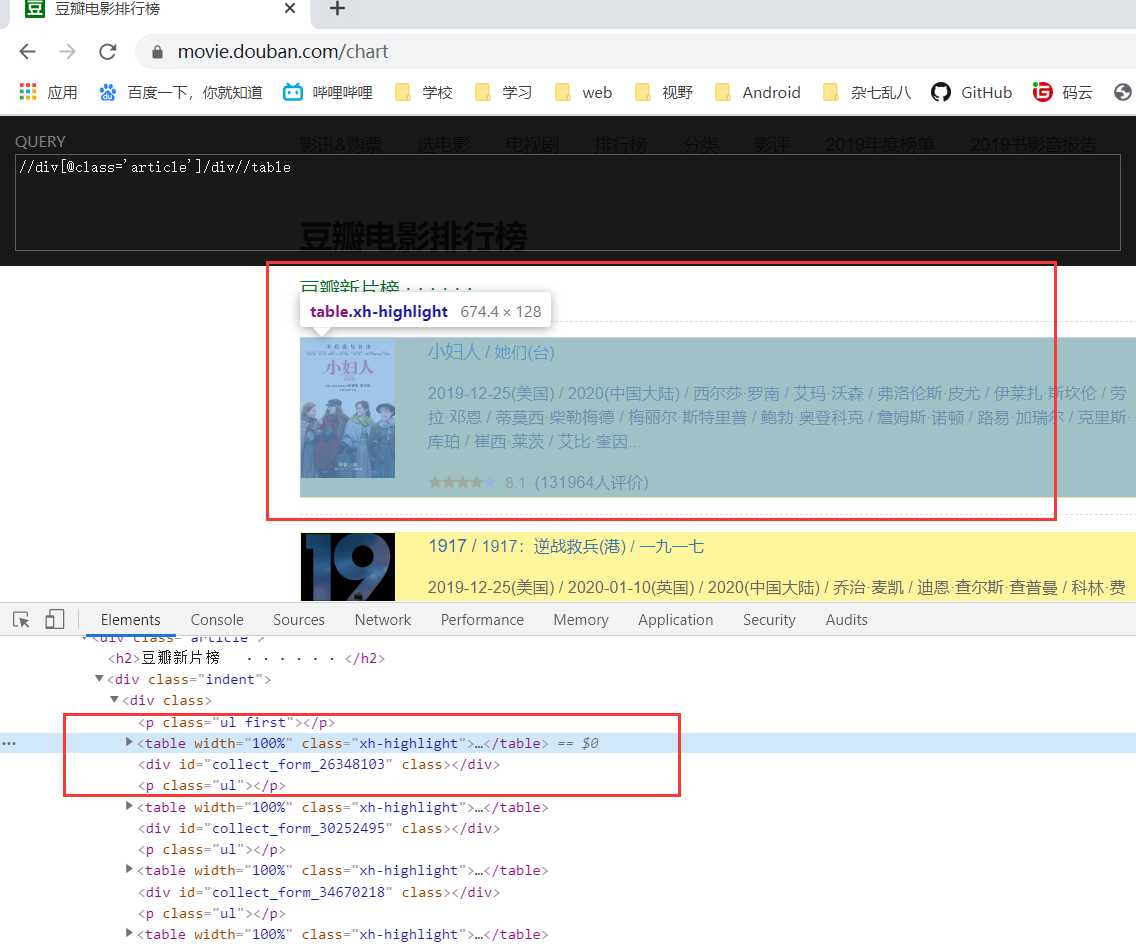
4、进一步定位到属于一个类属性为pl2的div下的a标签
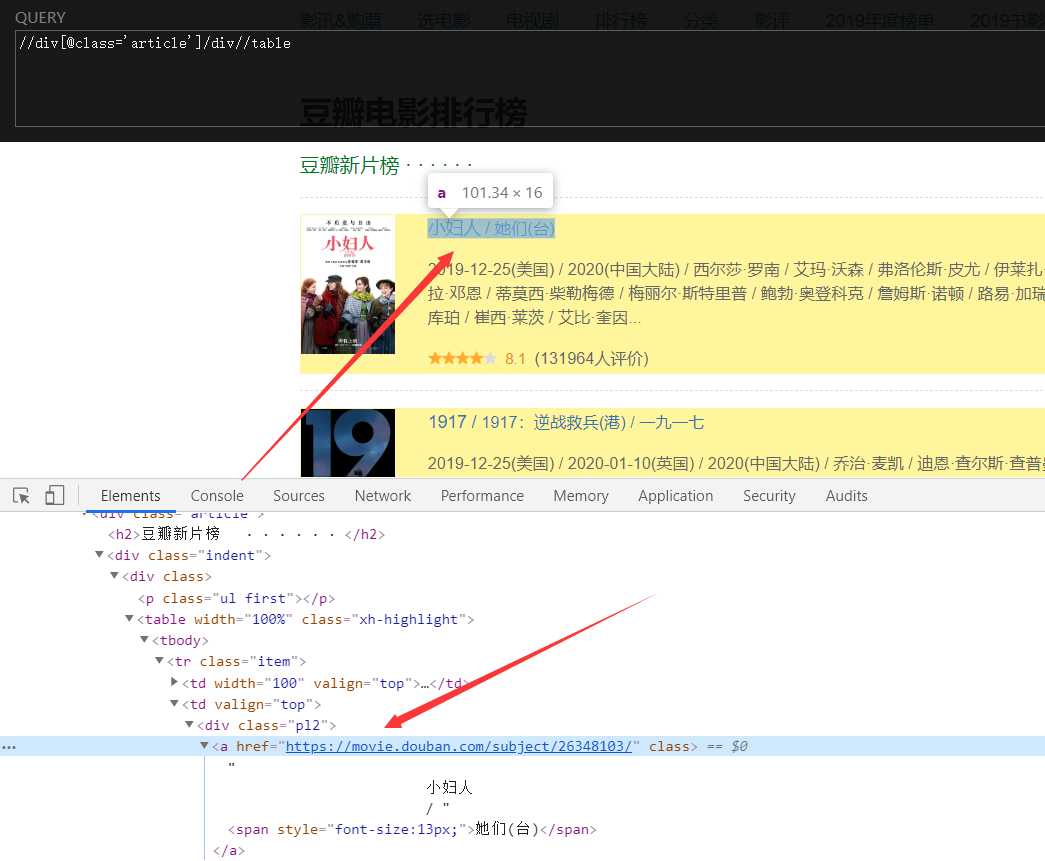
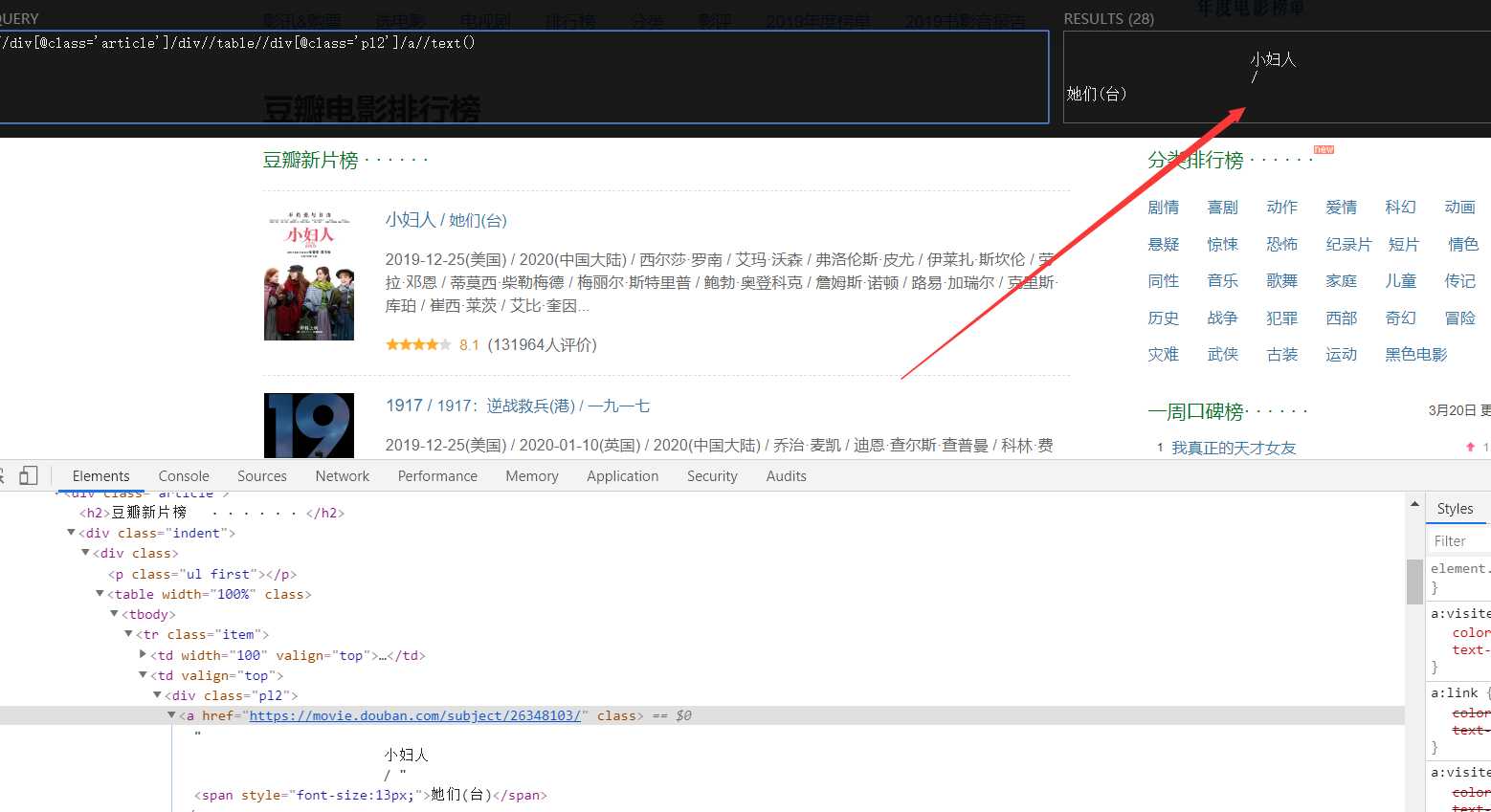
5、追加//div[@class=‘pl2‘]/a//text()
以上是关于Python怎样获取XPath下的A标签的内容的主要内容,如果未能解决你的问题,请参考以下文章