从python2,python3编码问题引伸出的通用编码原理解释
Posted RainLa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从python2,python3编码问题引伸出的通用编码原理解释相关的知识,希望对你有一定的参考价值。
今天使用python2编码时遇到这样一条异常UnicodeDecodeError: ‘ascii’ code can’t decode byte 0xef
发现是编码问题,但是平常在python3中几乎没有遇到过,所以特意查了资料,原来python3和python2对于字符串的理解不一样,在python3中,字符串默认unicode编码
一.解释python2和python3文本处理方式
在Python3当中,文本字符串类型(使用Unicode数据存储)被命名为 str , 字节字符串类型被命名为 bytes 。一般情况下,实例化一个字符串会得到一个 str 对象 :
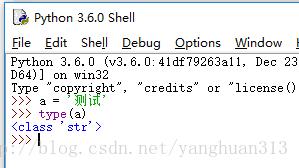
如果你想得到bytes,那就在文本之前加上前缀 b , 或者 encode 一下。

所以,很显然,str 对象有一个encode方法,bytes 对象有一个decode方法。
在Python3中的 str 对象在Python2中叫做 unicode , bytes 对象在Python2中叫做 str
在python2中使用中文字符串的方式是在页首声明# *--coding:utf-8--*


二.常用编码方式
顺便在网上查了一下字符集和编码方式的文档,发现很多人都解释的难以理解,所以这里尝试说清楚一下。这里不解析字符集和编码方式,统称为编码方式。
不论什么编码,在计算机中统一是按照二进制字节形式存储,一个字节有8位
1.ASCII码,总共有128个,用1个字节的低7位来表示
2.ISO-8859-1,128个字符表示明显不够用,所以ISO组织又制订了新的标准来扩展ASCII码,它们是ISO-8859-1到ISO-8859-15,其中ISO-8859-1涵盖了大部分西欧编码,所以用的最多。ISO-8859-1也是单字节编码,总共表示256个字符,发现字符变成?时,一般是使用了ISO-8859-1编码,规定不认识范围内的使用3f表示的就是?
3.GB2312,双字节编码,范围为A1-F7,其中A1-A9是符号区,包含682个符号,B0-F7是汉字区,包含6763个汉字,汉字使用两个字节表示
4.GBK,用于扩展GB2312,编码范围8140~FEFE,总共有23940个码位,使用GB2312编码的汉字可以用GBK来解码
5.UTF-16,所有字符都是用两个字节,两个字节为16bit,所以叫UTF-16,但是浪费空间.(同unicode)
6.UTF-8,每个编码区域有不同的字码长度,最长为三个字节,编码规则如下:
(1)如果一个字节的第一位为0,那么代表当前字符为单字节字符,占用一个字节的空间。0之后的所有部分(7个bit)代表在Unicode中的序号。
(2)如果一个字节以110开头,那么代表当前字符为双字节字符,占用2个字节的空间。110之后的所有部分(7个bit)代表在Unicode中的序号。且第二个字节以10开头
(3)如果一个字节以1110开头,那么代表当前字符为三字节字符,占用2个字节的空间。110之后的所有部分(7个bit)代表在Unicode中的序号。且第二、第三个字节以10开头
(4)如果一个字节以10开头,那么代表当前字节为多字节字符的第二个字节。10之后的所有部分(6个bit)代表在Unicode中的序号
具体每个字节的特征可见下表,其中x代表序号部分,把各个字节中的所有x部分拼接在一起就组成了在Unicode字库中的序号
| Byte 1 | Byte 2 | Byte3 |
|---|---|---|
| 0xxx xxxx | ||
| 110x xxxx | 10xx xxxx | |
| 1110 xxxx | 10xx xxxx | 10xx xxxx |
我们分别看三个从一个字节到三个字节的UTF-8编码例子:
| 实际字符 | 在Unicode字库序号的十六进制 | 在Unicode字库序号的二进制 | UTF-8编码后的二进制 | UTF-8编码后的十六进制 |
| $ | 0024 | 010 0100 | 0010 0100 | 24 |
| ¢ | 00A2 | 000 1010 0010 | 1100 0010 1010 0010 | C2 A2 |
| € | 20AC | 0010 0000 1010 1100 | 1110 0010 1000 0010 1010 1100 | E2 82 AC |
细心的读者不难从以上的简单介绍中得出以下规律:
- 3个字节的UTF-8十六进制编码一定是以
E开头的 - 2个字节的UTF-8十六进制编码一定是以
C或D开头的 - 1个字节的UTF-8十六进制编码一定是以比
8小的数字开头的
三.常见问题处理之Emoji
所谓Emoji就是一种在Unicode位于\\u1F601–\\u1F64F区段的字符。这个显然超过了目前常用的UTF-8字符集的编码范围\\u0000–\\uFFFF。Emoji表情随着IOS的普及和微信的支持越来越常见。下面就是几个常见的Emoji:



那么Emoji字符表情会对我们平时的开发运维带来什么影响呢?最常见的问题就在于将他存入MySQL数据库的时候。一般来说MySQL数据库的默认字符集都会配置成UTF-8(三字节),而utf8mb4在5.5以后才被支持,也很少会有DBA主动将系统默认字符集改成utf8mb4。那么问题就来了,当我们把一个需要4字节UTF-8编码才能表示的字符存入数据库的时候就会报错:ERROR 1366: Incorrect string value: \'\\xF0\\x9D\\x8C\\x86\' for column 。 如果认真阅读了上面的解释,那么这个报错也就不难看懂了。我们试图将一串Bytes插入到一列中,而这串Bytes的第一个字节是\\xF0意味着这是一个四字节的UTF-8编码。但是当MySQL表和列字符集配置为UTF-8的时候是无法存储这样的字符的,所以报了错。
【附】手持两把锟斤拷, 口中疾呼烫烫烫。 脚踏千朵屯屯屯, 笑看万物锘锘锘。
以上是关于从python2,python3编码问题引伸出的通用编码原理解释的主要内容,如果未能解决你的问题,请参考以下文章