Goalng:基础复习一遍过
Posted slowlydance2me
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Goalng:基础复习一遍过相关的知识,希望对你有一定的参考价值。
Go(又称Golang)是Google开发的一种静态强类型、编译型、并发型,并具有垃圾回收功能的编程语言。
剖析 Hello world
新建文件 main.go 写入以下内容:
package main import "fmt" func main() fmt.Println("Hello World!")
其中,packge main 的作用是声明了 main.go 这个go文件所在的包,Go语言中使用包来组织代码,一般一个文件夹就是一个包,包内可以暴露类型或者方法供其他包使用
import "fmt" fmt 是 Go 语言中的一个标准库/包,用于处理标准的输入输出
func main:main 函数是整个程序的入口,main函数所在的包名也必须是main
fmt.Println:调用fmt包的 Println 方法,打印出 ”Hello World!“
执行 go run main.go 或者 go run. 运行该程序就会输出 Hello World!
而 go run main.go 其实有两步:
- go build main.go: 编译成二进制可执行程序
- ./main: 执行该程序
变量与数据类型
变量的声明
Go语言是静态类型的,变量声明时必须明确变量的类型。Go语言在变量声明时,变量的类型写在变量的后面
如:
var a int = 1 var a int // int类型默认为0 var a = 1 //会自动根据1的类型进行类型推断 a := 1 // 简洁模式
Golang 中的基本简单类型
空值:nil
整型类型: int(取决于操作系统), int8, int16, int32, int64, uint8, uint16, …
浮点数类型:float32, float64
字节类型:byte (等价于uint8)
字符串类型:string
布尔值类型:boolean,(true 或 false)
字符串
在 Go 语言中,字符串使用 UTF8 编码
,UTF8 的好处在于,如果基本是英文,每个字符占 1 byte,和 ASCII 编码是一样的,非常节省空间,如果是中文,一般占3字节。包含中文的字符串的处理方式与纯 ASCII 码构成的字符串有点区别。
package main import ( "fmt" "reflect" ) func main() str1 := "Golang" str2 := "Go语言" fmt.Println(reflect.TypeOf(str2[2]).Kind()) // uint8 fmt.Println(str1[2], string(str1[2])) // 108 l fmt.Printf("%d %c\\n", str2[2], str2[2]) // 232 è fmt.Println("len(str2):", len(str2)) // len(str2): 8
- reflect.TypeOf().Kind() 可以知道某个变量的类型,我们可以看到,字符串是以 byte 数组形式保存的,类型是 uint8,占1个 byte,打印时需要用 string 进行类型转换,否则打印的是编码值。
- 因为字符串是以 byte 数组的形式存储的,所以,
str2[2]的值并不等于语。str2 的长度len(str2)也不是 4,而是 8( Go 占 2 byte,语言占 6 byte)。
将 string 转为 rune 数组就可以正确处理中文
str2 := "Go语言" runeArr := []rune(str2) fmt.Println(reflect.TypeOf(runeArr[2]).Kind()) // int32 fmt.Println(runeArr[2], string(runeArr[2])) // 35821 语 fmt.Println("len(runeArr):", len(runeArr)) // len(runeArr): 4
转换成 []rune 类型后,字符串中的每个字符,无论占多少个字节都用 int32 来表示
数组与切片
声明与初始化:
var arr [5]int // 一维 var arr2 [5][5]int // 二维 var arr = [5]int1, 2, 3, 4, 5 // 或 arr := [5]int1, 2, 3, 4, 5
下标索引的使用
arr := [5]int1, 2, 3, 4, 5 for i := 0; i < len(arr); i++ arr[i] += 100 fmt.Println(arr) // [101 102 103 104 105]
数组的长度不能改变,如果想拼接2个数组,或是获取子数组,需要使用切片。切片是数组的抽象。
切片使用数组作为底层结构。
切片包含三个组件:容量,长度和指向底层数组的指针,切片可以随时进行扩展
声明与初始化
slice1 := make([]float32, 0) // 长度为0的切片 slice2 := make([]float32, 3, 5) // [0 0 0] 长度为3容量为5的切片 fmt.Println(len(slice2), cap(slice2)) // 3 5
使用
// 添加元素,切片容量可以根据需要自动扩展 slice2 = append(slice2, 1, 2, 3, 4) // [0, 0, 0, 1, 2, 3, 4] fmt.Println(len(slice2), cap(slice2)) // 7 12 // 子切片 [start, end) sub1 := slice2[3:] // [1 2 3 4] sub2 := slice2[:3] // [0 0 0] sub3 := slice2[1:4] // [0 0 1] // 合并切片 combined := append(sub1, sub2...) // [1, 2, 3, 4, 0, 0, 0]
- 声明切片时可以为切片设置容量大小,为切片预分配空间。在实际使用的过程中,如果容量不够,切片容量会自动扩展。
sub2...是切片解构的写法,将切片解构为 N 个独立的元素。
字典
map 类似于 java 的 HashMap,Python的字典(dict),是一种存储键值对(Key-Value)的数据解构。使用方式和其他语言几乎没有区别。
声明与使用
// 仅声明 m1 := make(map[string]int) // 声明时初始化 m2 := map[string]string "Sam": "Male", "Alice": "Female", // 赋值/修改 m1["Tom"] = 18
指针
指针即某个值的地址,类型定义时使用符号*,对一个已经存在的变量,使用 & 获取该变量的地址。
str := "Golang" var p *string = &str // p 是指向 str 的指针 *p = "Hello" fmt.Println(str) // Hello 修改了 p,str 的值也发生了改变
一般来说,指针通常在函数传递参数,或者给某个类型定义新的方法时使用。Go 语言中,参数是按值传递的,如果不使用指针,函数内部将会拷贝一份参数的副本,对参数的修改并不会影响到外部变量的值。如果参数使用指针,对参数的传递将会影响到外部变量。
func add(num int) num += 1 func realAdd(num *int) *num += 1 func main() num := 100 add(num) fmt.Println(num) // 100,num 没有变化 realAdd(&num) fmt.Println(num) // 101,指针传递,num 被修改 4 流程
流程控制
if条件
age := 18 if age < 18 fmt.Printf("Kid") else fmt.Printf("Adult") // 可以简写为: if age := 18; age < 18 fmt.Printf("Kid") else fmt.Printf("Adult")
switch选择
type Gender int8 const ( MALE Gender = 1 FEMALE Gender = 2 ) gender := MALE switch gender case FEMALE: fmt.Println("female") case MALE: fmt.Println("male") default: fmt.Println("unknown") // male
- 在这里,使用了
type关键字定义了一个新的类型 Gender。 - 使用 const 定义了 MALE 和 FEMALE 2 个常量,Go 语言中没有枚举(enum)的概念,一般可以用常量的方式来模拟枚举。
- 和其他语言不同的地方在于,Go 语言的 switch 不需要 break,匹配到某个 case,执行完该 case 定义的行为后,默认不会继续往下执行。如果需要继续往下执行,需要使用 fallthrough,例如:
switch gender case FEMALE: fmt.Println("female") fallthrough case MALE: fmt.Println("male") fallthrough default: fmt.Println("unknown") // 输出结果 // male // unknown
for循环
一个简单的累加的例子,break 和 continue 的用法与其他语言没有区别。
sum := 0 for i := 0; i < 10; i++ if sum > 50 break sum += i
对数组(arr)、切片(slice)、字典(map) 使用 for range 遍历:
nums := []int10, 20, 30, 40 for i, num := range nums fmt.Println(i, num) // 0 10 // 1 20 // 2 30 // 3 40 m2 := map[string]string "Sam": "Male", "Alice": "Female", for key, value := range m2 fmt.Println(key, value) // Sam Male // Alice Female
函数(functions)
一个典型的函数定义如下,使用关键字 func,参数可以有多个,返回值也支持有多个。特别地,package main 中的func main() 约定为可执行程序的入口。
func funcName(param1 Type1, param2 Type2, ...) (return1 Type3, ...) // body
例如,实现2个数的加法(一个返回值)和除法(多个返回值):
func add(num1 int, num2 int) int return num1 + num2 func div(num1 int, num2 int) (int, int) return num1 / num2, num1 % num2 func main() quo, rem := div(100, 17) fmt.Println(quo, rem) // 5 15 fmt.Println(add(100, 17)) // 117
也可以给返回值命名,简化 return,例如 add 函数可以改写为
func add(num1 int, num2 int) (ans int) ans = num1 + num2 return
错误处理(error handling)
如果函数实现过程中,如果出现不能处理的错误,可以返回给调用者处理。比如我们调用标准库函数os.Open读取文件,os.Open 有2个返回值,第一个是 *File,第二个是 error, 如果调用成功,error 的值是 nil,如果调用失败,例如文件不存在,我们可以通过 error 知道具体的错误信息。
import ( "fmt" "os" ) func main() _, err := os.Open("filename.txt") if err != nil fmt.Println(err) // open filename.txt: no such file or directory
可以通过 errorw.New 返回自定义的错误
import ( "errors" "fmt" ) func hello(name string) error if len(name) == 0 return errors.New("error: name is null") fmt.Println("Hello,", name) return nil func main() if err := hello(""); err != nil fmt.Println(err) // error: name is null
error 往往是能预知的错误,但是也可能出现一些不可预知的错误,例如数组越界,这种错误可能会导致程序非正常退出,在 Go 语言中称之为 panic。
func get(index int) int arr := [3]int2, 3, 4 return arr[index] func main() fmt.Println(get(5)) fmt.Println("finished")
$ go run .
panic: runtime error: index out of range [5] with length 3
goroutine 1 [running]:
exit status 2
在 Python、Java 等语言中有try...catch机制,在try中捕获各种类型的异常,在catch中定义异常处理的行为。Go 语言也提供了类似的机制defer和recover。
func get(index int) (ret int) defer func() if r := recover(); r != nil fmt.Println("Some error happened!", r) ret = -1 () arr := [3]int2, 3, 4 return arr[index] func main() fmt.Println(get(5)) fmt.Println("finished")
结构体,方法和接口
结构体类似于其他语言中的 class,可以在结构体中定义多个字段,为结构体实现方法,实例化等。接下来我们定义一个结构体 Student,并为 Student 添加 name,age 字段,并实现 hello() 方法
type Student struct name string age int func (stu *Student) hello(person string) string return fmt.Sprintf("hello %s, I am %s", person, stu.name) func main() stu := &Student name: "Tom", msg := stu.hello("Jack") fmt.Println(msg) // hello Jack, I am Tom
- 使用
Studentfield: value, ...的形式创建 Student 的实例,字段不需要每个都赋值,没有显性赋值的变量将被赋予默认值,例如 age 将被赋予默认值 0。 - 实现方法与实现函数的区别在于,
func和函数名hello之间,加上该方法对应的实例名stu及其类型*Student,可以通过实例名访问该实例的字段name和其他方法了。 - 调用方法通过
实例名.方法名(参数)的方式。
除此之外,还可以使用 new 实例化:
func main() stu2 := new(Student) fmt.Println(stu2.hello("Alice")) // hello Alice, I am , name 被赋予默认值""
接口(interfaces)
一般而言,接口定义了一组方法的集合,接口不能被实例化,一个类型可以实现多个接口。
举一个简单的例子,定义一个接口 Person和对应的方法 getName() 和 getAge():
type Person interface getName() string type Student struct name string age int func (stu *Student) getName() string return stu.name type Worker struct name string gender string func (w *Worker) getName() string return w.name func main() var p Person = &Student name: "Tom", age: 18, fmt.Println(p.getName()) // Tom
- Go 语言中,并不需要显式地声明实现了哪一个接口,只需要直接实现该接口对应的方法即可。
- 实例化
Student后,强制类型转换为接口类型 Person。
在上面的例子中,我们在 main 函数中尝试将 Student 实例类型转换为 Person,如果 Student 没有完全实现 Person 的方法,比如我们将 (*Student).getName() 删掉,编译时会出现如下报错信息。
*Student does not implement Person (missing getName method)
但是删除(*Worker).getName()程序并不会报错,因为我们并没有在 main 函数中使用。这种情况下我们如何确保某个类型实现了某个接口的所有方法呢?一般可以使用下面的方法进行检测,如果实现不完整,编译期将会报错。
var _ Person = (*Student)(nil) var _ Person = (*Worker)(nil)
- 将空值 nil 转换为 *Student 类型,再转换为 Person 接口,如果转换失败,说明 Student 并没有实现 Person 接口的所有方法。
- Worker 同上。
实例可以强制类型转换为接口,接口也可以强制类型转换为实例。
func main() var p Person = &Student name: "Tom", age: 18, stu := p.(*Student) // 接口转为实例 fmt.Println(stu.getAge())
空接口
如果定义了一个没有任何方法的空接口,那么这个接口可以表示任意类型。例如
func main() m := make(map[string]interface) m["name"] = "Tom" m["age"] = 18 m["scores"] = [3]int98, 99, 85 fmt.Println(m) // map[age:18 name:Tom scores:[98 99 85]]
并发编程(goroutine)
Go 语言提供了 sync 和 channel 两种方式支持协程(goroutine)的并发。
例如我们希望并发下载 N 个资源,多个并发协程之间不需要通信,那么就可以使用 sync.WaitGroup,等待所有并发协程执行结束。
import ( "fmt" "sync" "time" ) var wg sync.WaitGroup func download(url string) fmt.Println("start to download", url) time.Sleep(time.Second) // 模拟耗时操作 wg.Done() func main() for i := 0; i < 3; i++ wg.Add(1) go download("a.com/" + string(i+\'0\')) wg.Wait() fmt.Println("Done!")
- wg.Add(1):为 wg 添加一个计数,wg.Done(),减去一个计数。
- go download():启动新的协程并发执行 download 函数。
- wg.Wait():等待所有的协程执行结束。
$ time go run .
start to download a.com/2
start to download a.com/0
start to download a.com/1
Done!
可以看到串行需要 3s 的下载操作,并发后,只需要 1s。
real 0m1.563s
使用 channel 信道,可以在协程之间传递消息。阻塞等待并发协程返回消息。
var ch = make(chan string, 10) // 创建大小为 10 的缓冲信道 func download(url string) fmt.Println("start to download", url) time.Sleep(time.Second) ch <- url // 将 url 发送给信道 func main() for i := 0; i < 3; i++ go download("a.com/" + string(i+\'0\')) for i := 0; i < 3; i++ msg := <-ch // 等待信道返回消息。 fmt.Println("finish", msg) fmt.Println("Done!")
$ time go run .
|
单元测试
假设我们希望测试 package main 下 calc.go 中的函数,要只需要新建 calc_test.go 文件,在calc_test.go中新建测试用例即可。
// calc.go package main func add(num1 int, num2 int) int return num1 + num2
// calc_test.go package main import "testing" func TestAdd(t *testing.T) if ans := add(1, 2); ans != 3 t.Error("add(1, 2) should be equal to 3")
运行 go test,将自动运行当前 package 下的所有测试用例,如果需要查看详细的信息,可以添加-v参数。
$ go test -v
|
包(Package)和模块(Modules)
一般来说,一个文件夹可以作为 package,同一个 package 内部变量、类型、方法等定义可以相互看到。
比如我们新建一个文件 calc.go, main.go 平级,分别定义 add 和 main 方法。
// calc.go package main func add(num1 int, num2 int) int return num1 + num2
// main.go package main import "fmt" func main() fmt.Println(add(3, 5)) // 8
运行 go run main.go,会报错,add 未定义:
./main.go:6:14: undefined: add
因为go run main.go仅编译 main.go 一个文件,所以命令需要换成
$ go run main.go calc.go
8
或
$ go run .
8
Go 语言也有 Public 和 Private 的概念,粒度是包。如果类型/接口/方法/函数/字段的首字母大写,则是 Public 的,对其他 package 可见,如果首字母小写,则是 Private 的,对其他 package 不可见。
Go Modules 是 Go 1.11 版本之后引入的,Go 1.11 之前使用 $GOPATH 机制。Go Modules 可以算作是较为完善的包管理工具。同时支持代理,国内也能享受高速的第三方包镜像服务。接下来简单介绍 go mod 的使用。Go Modules 在 1.13 版本仍是可选使用的,环境变量 GO111MODULE 的值默认为 AUTO,强制使用 Go Modules 进行依赖管理,可以将 GO111MODULE 设置为 ON。
在一个空文件夹下,初始化一个 Module
$ go mod init example
go: creating new go.mod: module example
此时,在当前文件夹下生成了go.mod,这个文件记录当前模块的模块名以及所有依赖包的版本。
接着,我们在当前目录下新建文件 main.go,添加如下代码:
package main import ( "fmt" "rsc.io/quote" ) func main() fmt.Println(quote.Hello()) // Ahoy, world!
运行go run .,将会自动触发第三方包rsc.io/quote的下载,具体的版本信息也记录在了go.mod中:
module example
go 1.13
require rsc.io/quote v3.1.0+incompatible
我们在当前目录,添加一个子 package calc,代码目录如下
demo/
|--calc/
|--calc.go
|--main.go
在 calc.go 中写入
package calc func Add(num1 int, num2 int) int return num1 + num2
在 package main 中如何使用 package cal 中的 Add 函数呢?import 模块名/子目录名 即可,修改后的 main 函数如下:
package main import ( "fmt" "example/calc" "rsc.io/quote" ) func main() fmt.Println(quote.Hello()) fmt.Println(calc.Add(10, 3))
$ go run .
Ahoy, world!
13
以上
本文来自博客园,作者:slowlydance2me,转载请注明原文链接:https://www.cnblogs.com/slowlydance2me/p/17286403.html
「深度学习一遍过」必修26:机器学习与深度学习基础知识汇总
本专栏用于记录关于深度学习的笔记,不光方便自己复习与查阅,同时也希望能给您解决一些关于深度学习的相关问题,并提供一些微不足道的人工神经网络模型设计思路。
专栏地址:「深度学习一遍过」必修篇
目录
1 Boosting与Bagging
Boosting
- 个体学习器存在强依赖关系
- 串行
- 最著名的的代表
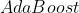
Bagging
- 个体学习器不存在强依赖关系
- 并行
- 一个扩展变体:随机森林
2 卷积层、激活层、池化层作用
- 卷积层:提取特征
- 激活层:进行特征的选择和抑制
- 池化层:降低特征平面分辨率及抽象特征
3 卷积神经网络特性
局部连接
- 思想来自生理学的感受野机制和图像的局部统计特性
权值共享
- 使图像局部学习到的信息可以应用到其他区域,从而使同样的目标在不同的位置能提取到同样的特征
4 正则化相关知识
正则化目的
- 避免过拟合
正则化思路
- 以增大训练集误差为代价来减小泛化误差
正则化方法
- 参数正则化方法:如
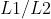 正则化
正则化 - 经验正则化方法:提前停止、模型集成(如
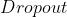 )
) - 隐式正则化方法:数据增强
5 评测指标相关知识
分类评测指标
- 准确率
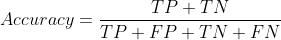
- 精确率
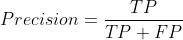
- 召回率
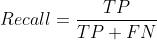
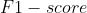

- 混淆矩阵
用于查看是否有特定的类别相互混淆
对于包含多个类别的任务,混淆矩阵很清晰地反映了各类别之间错分的概率
越好的分类器对角线上的值越大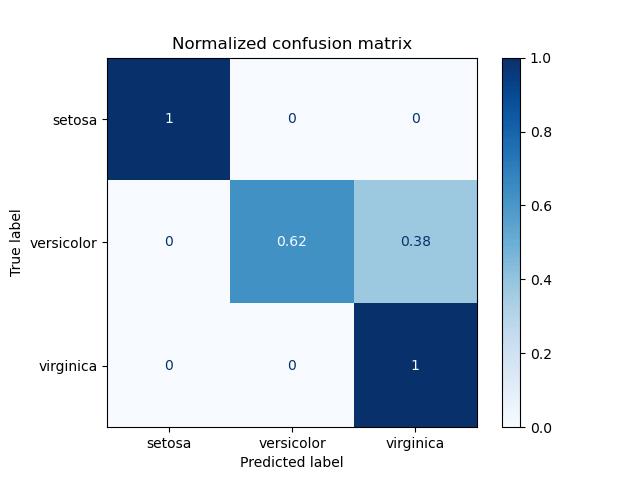
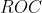 曲线
曲线
用于评价一个分类器在不同阈值下的表现
横坐标: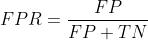
纵坐标: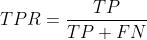
它对正负样本不均衡问题不敏感,所以对于不均衡样本问题常选用 曲线作为评价准则 曲线越靠近左上角,表示该分类器性能越好 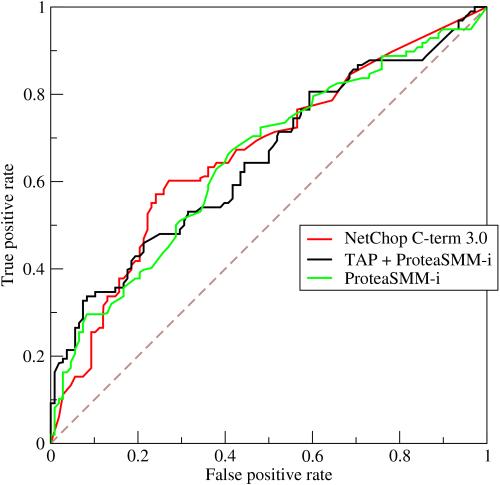
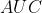 指标
指标
若想通过两条 曲线来定量评估两个分类器的性能,就可以使用 这个指标。 是 曲线下的面积(值不大于 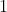 )
)
检索与回归评测指标
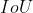 (交并比)
(交并比)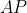
其值等于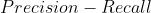 曲线下的面积
曲线下的面积
假设有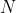 个
个 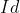 ,其中有
,其中有 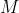 个
个 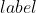 值等于这 个精确率值求平均
值等于这 个精确率值求平均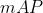
假设有 个 ,其中有 个 值等于 个类别的 值求平均
图像生成指标
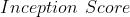
同时评估了生成图像的质量和多样性
仅评估图像生成模型,没有评估生成图像与原始图像之间的相似度,不能保证生成的使我们想要的图像分数对其进行了改进,增加了
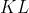 散度来度量真实分布于生成分布之间的差异
散度来度量真实分布于生成分布之间的差异
最大平均差异

6 参数初始化方法
要满足的条件
- 各层激活值不会出现饱和现象
- 各层激活值不为
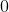
神经网络要求
- 参数梯度应该保持非零
常见问题
- 初始值太小:导致反向传播梯度太小、梯度弥散。降低收敛速度
- 初始值太大:造成振荡,会使
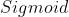 函数等进入梯度饱和区
函数等进入梯度饱和区
参数初始化方法
- 初始化为 :中间层节点值都为零,不利于优化。训练逻辑回归等模型才用
- 生成小的随机数:
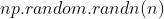
- 标准初始化:权重参数从
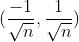 的均匀分布中生成
的均匀分布中生成
保持神经网络每层权重方差与层数无关,会更加有利于优化 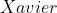 初始化:基于
初始化:基于 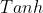 函数提出的,对
函数提出的,对 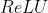 并不友好(虽常搭配使用)
并不友好(虽常搭配使用)
网络越深,各层输入的方差就越小,网络越难训练初始化:基于
函数提出的
7 归一化相关知识
归一化目的
- 让每层输入和输出的分布比较一致,从而降低学习难度
Batch Normalization(BN)
- 用在卷积层后,用于重新调整数据分布
- 方式:求均值
 求方差 归一化 尺度缩放和偏移操作
求方差 归一化 尺度缩放和偏移操作 - 具体方法:
输入数据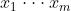 (这些数据是准备进入激活函数的数据)
(这些数据是准备进入激活函数的数据)
计算过程中可以看到:
1、求数据均值
2、求数据方差
3、数据进行标准化
4、训练参数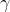 、
、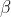
5、输出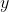 通过 与 的线性变换得到新的值
通过 与 的线性变换得到新的值
在正向传播的时候,通过可学习的γ与β参数求出新的分布值
在反向传播的时候,通过链式求导方式,求出γ与β以及相关权值
- 让每一层的输出归一化到了均值为 ,方差为 的分布
- 好处:①减轻了对初始值的依赖
②训练更快,可以使用更高的学习速率 - 缺陷:依赖于
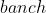 , 很小时计算的均值和方差不稳定
, 很小时计算的均值和方差不稳定
补充: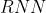 使得 有长有短,因此也不适用此归一化方法
使得 有长有短,因此也不适用此归一化方法
8 最优化方法相关知识
8.1 一阶
批量梯度下降
- 使用所有的训练样本计算梯度,梯度计算稳定,但计算非常慢
随机梯度下降(SGD)
- 每次只取一个样本进行梯度计算,梯度计算不稳定易振荡,但整体趋近于全局最优解
- 解决
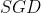 有时很慢的方法:引入动量项(对在梯度点处具有相同方向的维度,增大其动量项;对在梯度点处改变方向的维度,减小其动量项)
有时很慢的方法:引入动量项(对在梯度点处具有相同方向的维度,增大其动量项;对在梯度点处改变方向的维度,减小其动量项) - 上述方法对所有参数使用了同一个更新速率,但同一个更新速率并不一定适合所有参数(有的参数已经到了仅需微调的阶段,而有些参数由于对应样本少等原因,还需要较大幅度的调整)
- 解决办法见下
AdaGrad
- 自适应地为各个参数分配不同的学习率
- 存在问题:学习率单调递减,训练后期学习率非常小,且需手动设置一个全局的出示学习率
Adadelta
- 可有效解决
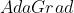 的问题,本质是 算法的扩展,同样是对学习率的自适应约束,不依赖全局学习率,训练初、中期效果理想,训练后期反复在局部最小值附近抖动。
的问题,本质是 算法的扩展,同样是对学习率的自适应约束,不依赖全局学习率,训练初、中期效果理想,训练后期反复在局部最小值附近抖动。 - 算法会累加之前所有的梯度平方,
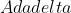 算法只累加固定大小的项,并且仅存储这些项近似计算对应的平均值
算法只累加固定大小的项,并且仅存储这些项近似计算对应的平均值
RMSProp
- 可以看做 的一个特例,依然依赖全局学习率,效果位于 与 之间,适合处理非平稳目标,适用于 的优化
Adam
- 本质是带有动量项的
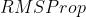 算法,利用梯度的一阶矩估计和二阶矩估计动态调整没和参数的学习率,迭代到后期时,学习率不稳定,可能过大或过小
算法,利用梯度的一阶矩估计和二阶矩估计动态调整没和参数的学习率,迭代到后期时,学习率不稳定,可能过大或过小 - 优点主要在于经过偏置校正后,每次迭代学习率都有一个确定的范围,使得参数比较平稳,对内存需求较小,适用于大多数非凸优化问题,尤其适合处理大数据集和高维空间问题
8.2 二阶
牛顿法
- 有较一阶梯度优化方法更快的收敛速度,但计算量大
拟牛顿法
- 可简化运算的复杂度
9 激活函数相关知识
Sigmoid 函数
(注: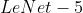 :激活函数 )
:激活函数 )
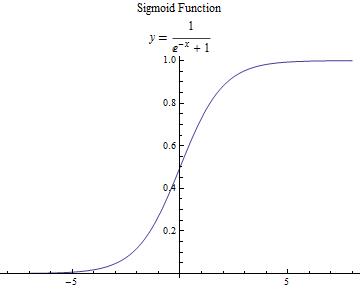
- 缺陷:
- 两端是饱和区,饱和区内梯度接近于 ,会带来梯度消失问题;随着网络层数增加,由于链式法则,连乘的 函数导数也越来越小,导致梯度难以回传,降低网络收敛速度,甚至不能收敛
- 输出并不以 为中心,总是大于 ,而权重参数的梯度与输入有关,这就会造成在反向传播时,一个样本的某个权重的梯度总是同一个符号,这不利于权重的更新
Tanh函数
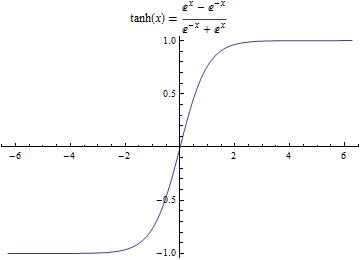
- 解决了 输出值并不以 为中心的问题,但梯度消失问题和幂运算问题仍然存在
线性ReLU函数
(注: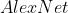 :激活函数 )
:激活函数 )
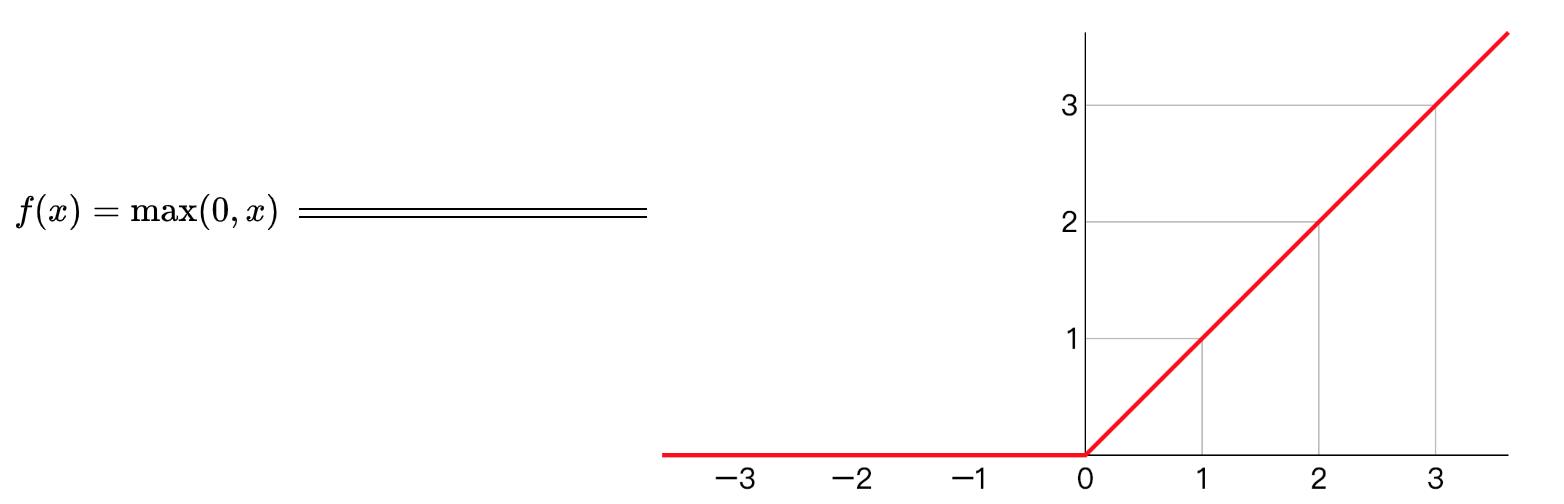
- 若用 函数表示则同时有一半神经元被激活,这不符合生物学只有
 被激活的要求,因此需要新的具有稀疏性的激活函数来学习相对稀疏的特征
被激活的要求,因此需要新的具有稀疏性的激活函数来学习相对稀疏的特征 - 优点:
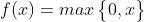 在使用时只需要判断输入是否大于 ,所以其计算速度非常快,收敛速度远快于 和 函数
在使用时只需要判断输入是否大于 ,所以其计算速度非常快,收敛速度远快于 和 函数 - 缺点:存在
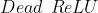 问题,即某些神经元可能永远不会参与计算,导致其相应的参数无法被更新
问题,即某些神经元可能永远不会参与计算,导致其相应的参数无法被更新
Leaky ReLU函数
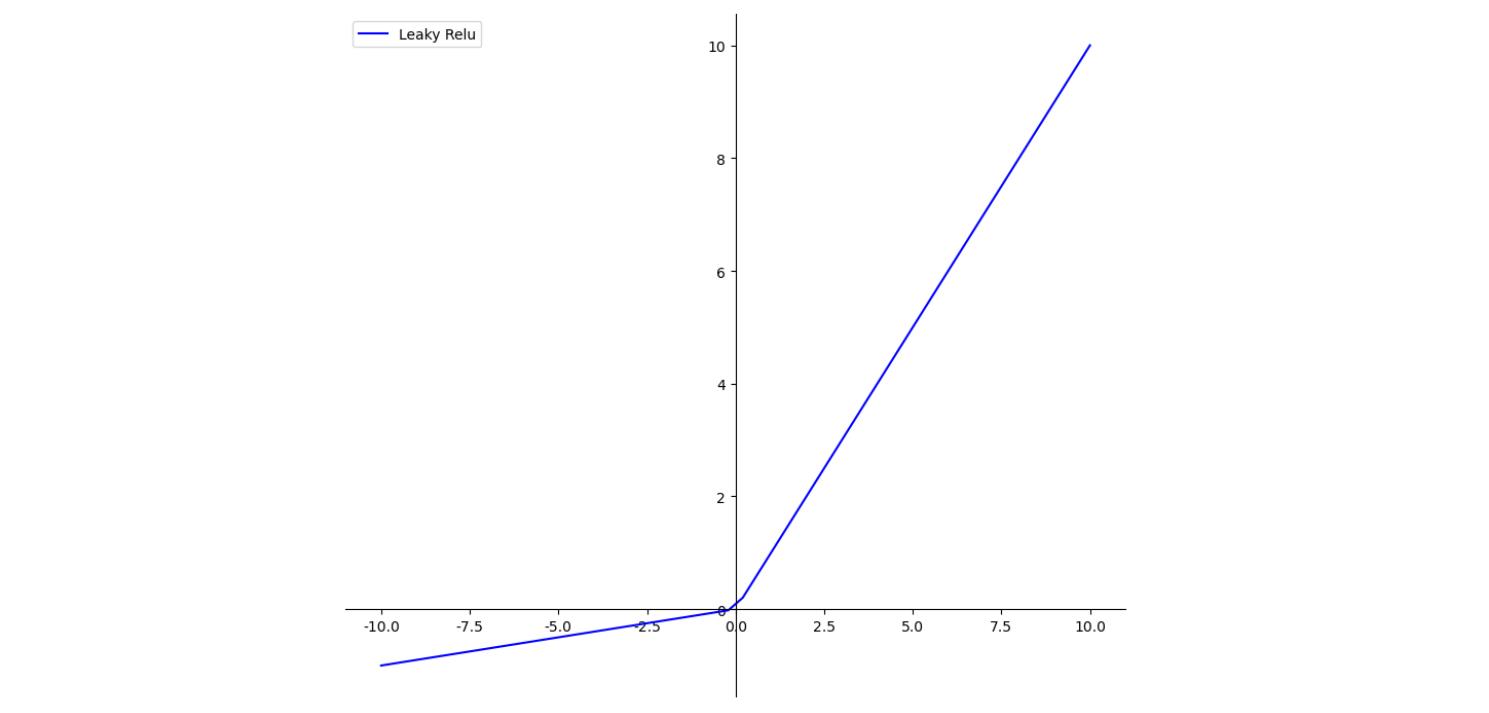
- 其提出是为了解决 问题,从理论上来讲,
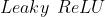 具有 的所有优点,并且不会有 问题,但实际操作并没有完全证明 函数总是好于 函数
具有 的所有优点,并且不会有 问题,但实际操作并没有完全证明 函数总是好于 函数
Maxout函数
- 就是最大值函数,从多个输入中取最大值,其具有 函数的所有优点,线性、不饱和性,同时没有 函数的缺点。其拟合能力非常强,可以拟合任意的凸函数,实验结果表明,
函数与
组合使用可以发挥比较好的效果
Softmax函数
- 公式
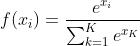
- 可视为 函数的泛化形式,该函数一般用于多分类神经网络输出,待补充……
10 优化目标相关知识
- 损失函数越小,模型的鲁棒性越好
10.1 分类任务损失
0-1损失
- 当标签与预测类别相等时,损失为 ,否则为
 损失无法对
损失无法对 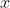 进行求导,这使其在依赖反向传播的深度学习模型中无法被优化
进行求导,这使其在依赖反向传播的深度学习模型中无法被优化
交叉熵损失
- 交叉熵函数是两个分布的互信息,可以反映两个概率分布的相关程度
- 损失的大小完全取决于分类为正确标签那一类的概率,当所有样本都分类正确时,损失为 ,否则,损失大于
Softmax损失
- 是交叉熵损失的特例(
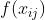 的表现形式为
的表现形式为 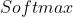 ),常应用于分类分割任务
),常应用于分类分割任务
KL散度
- 用于估计两个分布的相似性, 散度并不是一个对称的损失,常被用于生成式模型
Sigmoid Cross Entropy损失
- 通常被用于多分类任务
10.2 回归任务损失
- 回归结果是整数或实数,并没有先验的概率密度分布,其常用的损失是
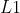 损失和
损失和 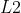 损失
损失
L1损失
- 公式

- 以绝对误差作为距离,具有稀疏性,常被作为正则项添加到其他损失中来约束参数的稀疏性, 损失最大的问题是梯度在零点不平滑
L2损失
- 公式

- 以绝对误差的平方和作为距离, 损失也常常作为正则项,当预测值与目标值相差很大时,梯度容易爆炸,因为梯度中包含了预测值和目标值的差异项, 损失最大的问题是梯度容易爆炸
Smooth L1损失
- 公式
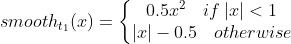
- 解决
 梯度不平滑, 梯度爆炸问题
梯度不平滑, 梯度爆炸问题 - 在 比较小时,上式等价于 ,保持平滑
- 在 比较大时,上式等价于 ,可以限制数值的大小
问答环节
- 问:神经网络的初始权值和阈值为什么都归一化 到 之间呢?(分割归一化到
 )
)
答:因为神经元的传输函数在 之间区别比较大,如果大于 以后,传输函数值变化不大(导数或斜率就比较小),不利于反向传播算法的执行。反向传播算法需要用到各个神经元传输函数的梯度信息,当神经元的输入太大时(大于 比如),相应的该点自变量梯度值就过小,就无法顺利实现权值和阈值的调整)。传输函数比如
之间区别比较大,如果大于 以后,传输函数值变化不大(导数或斜率就比较小),不利于反向传播算法的执行。反向传播算法需要用到各个神经元传输函数的梯度信息,当神经元的输入太大时(大于 比如),相应的该点自变量梯度值就过小,就无法顺利实现权值和阈值的调整)。传输函数比如  或
或 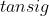 ,若把函数图像画出来会发现,
,若把函数图像画出来会发现,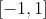 之间函数图像比较徒,一阶导数(梯度)比较大,如果在这个范围之外,图像就比较平坦,一阶导数(梯度)就接近 了。
之间函数图像比较徒,一阶导数(梯度)比较大,如果在这个范围之外,图像就比较平坦,一阶导数(梯度)就接近 了。
欢迎大家交流评论,一起学习
希望本文能帮助您解决您在这方面遇到的问题
感谢阅读
END
以上是关于Goalng:基础复习一遍过的主要内容,如果未能解决你的问题,请参考以下文章