day1_python之字符编码
Posted xiechao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了day1_python之字符编码相关的知识,希望对你有一定的参考价值。
一 、计算机基础知识
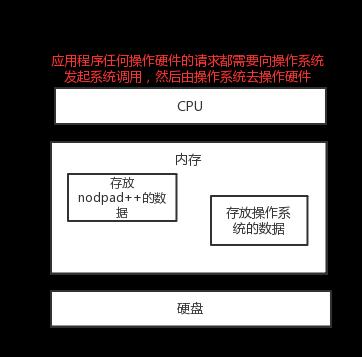
二、文本编辑器存取文件的原理(nodepad++,pycharm,word)
#1、打开编辑器就打开了启动了一个进程,是在内存中的,所以,用编辑器编写的内容也都是存放与内存中的,断电后数据丢失 #2、要想永久保存,需要点击保存按钮:编辑器把内存的数据刷到了硬盘上。 #3、在我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
三 、python解释器执行py文件的原理 ,例如python test.py

#第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器 #第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中(小复习:pyhon的解释性,决定了解释器只关心文件内容,不关心文件后缀名) #第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码( ps:在该阶段,即真正执行代码时,才会识别python的语法,执行文件内代码,当执行到name="egon"时,会开辟内存空间存放字符串"egon")
四、 总结python解释器与文件本编辑的异同
#1、相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样 #2、不同点:文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不去理会python的语法,而python解释器将文件内容读入内存后,可不是为了给你瞅一眼python代码写的啥,而是为了执行python代码、会识别python语法。
五、总结
!!!总结非常重要的两点!!!
#1、保证不乱吗的核心法则就是,字符按照什么标准而编码的,就要按照什么标准解码,此处的标准指的就是字符编码 #2、在内存中写的所有字符,一视同仁,都是unicode编码,比如我们打开编辑器,输入一个“你”,我们并不能说“你”就是一个汉字,此时它仅仅只是一个符号,该符号可能很多国家都在使用,根据我们使用的输入法不同这个字的样式可能也不太一样。只有在我们往硬盘保存或者基于网络传输时,才能确定”你“到底是一个汉字,还是一个日本字,这就是unicode转换成其他编码格式的过程了
unicode----->encode-------->utf-8
utf-8-------->decode---------->unicode
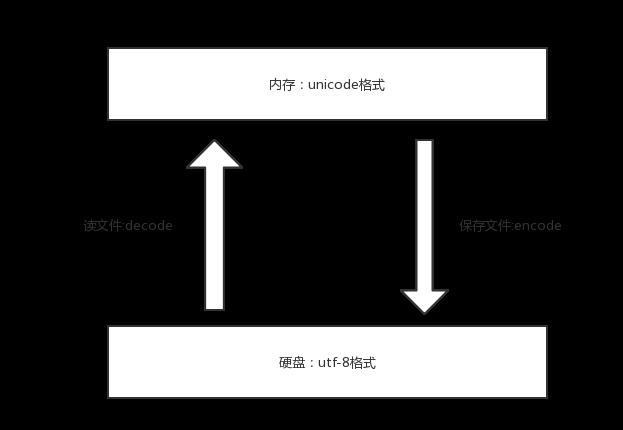
#补充: 浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器 如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的结果。
以上是关于day1_python之字符编码的主要内容,如果未能解决你的问题,请参考以下文章