亿万级分库分表后如何进行跨表分页查询
Posted 漫思
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了亿万级分库分表后如何进行跨表分页查询相关的知识,希望对你有一定的参考价值。
亿万级分库分表后如何进行跨表分页查询
前言
在常规的应用系统开发中,很少会涉及到需要对数据进行分库或者分表的操作,多数情况下,我们习惯使用ORM带来的便利,且使用连接查询是一种高效率的开发方式,就算涉及到分表的场景,很多时候也都可以使用ORM自带的分表规则来解决问题。
比如在电商场景中,用户和订单是属于重点增量的数据,通常情况下,或者按用户编号取模或者按订单编号取模进行分表,按便利性来区分,可以使用按用户编号分表解决后续跨表分页查询问题,这也是推荐的方式之一。
据说淘宝采用的是双写订单,即客户和商家各自一套冗余数据库,再指向订单表,这样做可以规避资源抢夺的问题。
分表后查询的多种方法
全局表查询
顾名思义,全局查询就是将分表后的数据主键再集中存储到一张表中,由于全局表只存储很简单的编号信息,查询效率相对较高,但是在数据持续增长的情况下,压力也越来越大。
禁止跳页查询
禁止跳页查询在移动互联网中广泛被应用,这种方法的原理是在查询中摒弃舍弃传统的Page,转而使用一个timestamp时间戳来代码页码,下一页的查询总是在上一页的最后一条记录的时间戳之后,当客户端拉取不到任何数据的时候,即可停止分页。
这种方法带的一个问题就是不允许进行跳转分页,并且会带来冗余查询的问题,比如需要查询多张表后才得到PageSize需要的数据量,只能按部就班的往下查询,不能进行并行查询。特别致命的是,此方法还将带来重复数据的问题。对数据精度要求不高的场景可以采用。
按日期的二次查询法
按日期的二次查询法号称可以解决分页带来的性能和精度问题,具体原理为,先将分页跳过的数据量平均分布到所有表中,如 Page=10,PageSize=50,如果有5个分表,则SQL语句:page=page/5,LIMIT 2,10;分别对5张表进行查询,得到5个结果集,此时,5个结果集里面分别有10条数据,其中下标0和rn-1的结果分别是当前结果集中的最小和最大时间戳(maxTimestamp),通过比较5张表的返回记录得到一个最小的时间戳 minTimestamp,再将这个最小的时间戳带入SQL条件进行二次查询,SQL代码
SELECT * FROM TABLE_NAME WHERE Timestamp BETWEEN @minTimestamp AND @maxTimestamp ORDER BY Timestamp
通过上面的代码,可以从数据库中得到一个完全的结果集,然后在内存中将5个结果集合并排序,取分页数据即可。看起来无懈可击,完美解决了上面两种分页查询引起的问题。实际上我个人认为,这里面还是有一些需要注意的地方,比如由于分表规则的问题导致第一次查询的表比较多(可能几千张表),又或者在二次查询中,某个区间的数据比较大,最后就是在内存中合并结果集也会造成性能问题。
这种查询方法还是解决了精度的问题,也部分解决了性能问题,特别是在取模分表的场景,数据随机性比较大的情况下,还是非常有用的。
大数据集成法
当数据量达到一定程度的时候,可以考虑上ELK或者其它大数据套件,可以很好的解决分页带的影响。
NewSql法
如果有条件,可以迁移数据库到NewSql类型的数据库上,NewSql数据库属于分布式数据库,既有关系数据库的优点又可以无限扩表,通常还支持关系数据库间的无障碍迁移,比如国产的TiDB数据库等。
有序的二次查询法
有序的二次查询法是基于上面的按日期的二次查询法发展而来,这种方法目前还处于测试阶段,具体做法是将数据按天进行分表,这样就可以确保数据块是连续的,以查询最近17天的分页数据为例,先查询出所有表的总行数,这里使用 COUNT(*) ,Mysql 会优化为information_schema.TABLES.TABLE_ROWS 索引查询提高查询效率,不用担心性能问题,下面列出详细的测试步骤。
建立分页实体
public class PageEntity
/// <summary>
/// 跳过的记录数
/// </summary>
public long Skip get; set;
/// <summary>
/// 选取的记录数
/// </summary>
public long Take get; set;
/// <summary>
/// 总行数
/// </summary>
public long Total get; set;
/// <summary>
/// 表名
/// </summary>
public string TableName get; set;
定义分页算法类
public class PageDataService
...
初始化表
在 PageDataService 类中使用内存表模拟数据库表,主要模拟数据分页的情况,所以每个表的数据量都很小,方便人肉计算和跳页
private readonly static List<PageEntity> entitys = new List<PageEntity>()
new PageEntity Total=12,TableName="230301" ,
new PageEntity Total=3,TableName="230302" ,
new PageEntity Total=4,TableName="230303" ,
new PageEntity Total=1,TableName="230304" ,
new PageEntity Total=1,TableName="230305" ,
new PageEntity Total=7,TableName="230306" ,
new PageEntity Total=2,TableName="230307" ,
new PageEntity Total=11,TableName="230308" ,
new PageEntity Total=41,TableName="230309" ,
new PageEntity Total=25,TableName="230310" ,
new PageEntity Total=33,TableName="230311" ,
new PageEntity Total=8,TableName="230312" ,
new PageEntity Total=3,TableName="230313" ,
new PageEntity Total=0,TableName="230314" ,
new PageEntity Total=17,TableName="230315" ,
new PageEntity Total=88,TableName="230316" ,
new PageEntity Total=2,TableName="230317"
;
分页算法
public static List<PageEntity> Pagination(int page, int pageSize)
long preBlock = 0;
int currentPage = page;
int currentPage = page >= 1 ? page - 1 : 0;
long currentPageSize = pageSize;
List<PageEntity> results = new List<PageEntity>();
foreach (var item in entitys)
if (item.Total == 0)
continue;
var skip = (currentPage * currentPageSize) + preBlock;
var remainder = item.Total - skip;
if (remainder > 0)
item.Skip = skip;
item.Take = currentPageSize;
if (remainder >= currentPageSize)
results.Add(item);
break;
else
currentPageSize = currentPageSize - remainder;
item.Take = remainder;
currentPage = 0;
preBlock = 0;
results.Add(item);
else
preBlock = Math.Abs(remainder);
currentPage = 0;
// 输出测试结果
if (results.Count > 0)
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine("本次查询,Page:0,PageSize:1", page, pageSize);
Console.ForegroundColor = ConsoleColor.Gray;
foreach (var item in results)
Console.WriteLine("表:0,总行数:1,OFFSET:2,LIMIT:3", item.TableName, item.Total, item.Skip, item.Take);
Console.WriteLine();
else
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine("分页下无数据:0,1", page, pageSize);
Console.ForegroundColor = ConsoleColor.Gray;
return results;
在上面的分页算法中,定义了4个私有变量,分别是
preBlock:存跨表数据块长度
currentPage:当前表分页
currentPageSize:当前表分页长度,也是当前表接 preBlock 所需要的查询长度
results:查询表结果,存需要进行二次查询的表结构
接下来,就对最近 17 张表进行模拟轮询计算,把数据块连接起来,首先是计算 skip 的长度,这里使用当前表分页加跨表块
var skip = ((currentPage - 1) * currentPageSize) + preBlock
得到真实的 skip,然后用当前表 Total - skip 得到下一表的接续长度
var remainder = item.Total - skip;
再通过判断接续长度 remainder 大于 0,如果小于0则设定 preBlock 和 currentPage 进入下一表结构,如果大于 0 则进一步判断其是否可以覆盖 currentPageSize,如果可以覆盖则记录当前表并跳出循环,否则 重置 currentPageSize 和其它条件后进入下一个表结构。
if (remainder > 0)
item.Skip = skip;
item.Take = currentPageSize;
if (remainder >= currentPageSize)
results.Add(item);
break;
else
currentPageSize = currentPageSize - remainder;
item.Take = remainder;
currentPage = 1;
preBlock = 0;
results.Add(item);
else
preBlock = Math.Abs(remainder);
currentPage = 1;
测试分页结果
构建一些测试数据进行分页,看接续是否已经闭合
public class Program
public static void Main(string[] args)
PageDataService.Pagination(1, 40);
PageDataService.Pagination(2, 40);
PageDataService.Pagination(3, 40);
PageDataService.Pagination(4, 40);
PageDataService.Pagination(5, 40);
PageDataService.Pagination(6, 40);
PageDataService.Pagination(7, 40);
PageDataService.Pagination(8, 40);
PageDataService.Pagination(9, 40);
PageDataService.Pagination(113, 10);
Console.ReadKey();
输出测试结果
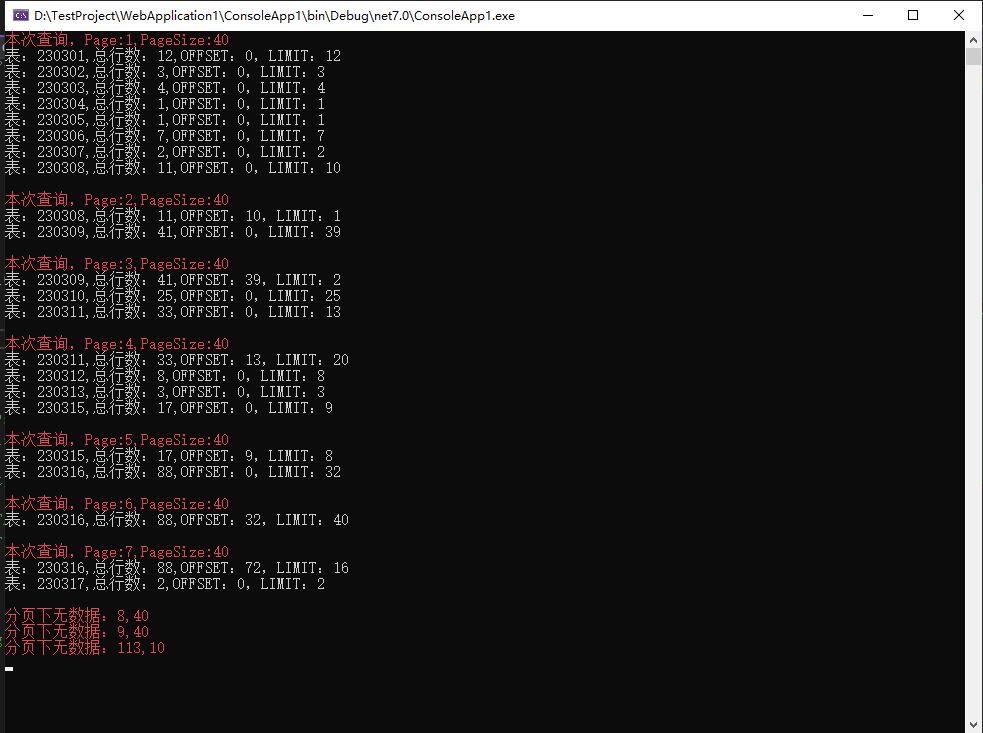
通过输出的测试结果,可以看到,数据块是连续的,且已经得到了每次需要查询的表结构数据,在实际应用中,只需要对这个结果执行并行查询然后在内存中归并排序就可以了。
并行查询和排序
public static void Query()
var entitys = PageDataService.Pagination(1, 40);
List<UserEntity> datas = new List<UserEntity>();
Parallel.ForEach(entitys, entity =>
var sql = $"SELECT * FROM TABLE_entity.TableName ORDER BY Timestamp LIMIT entity.Skip,entity.Take";
var results = Mysql.Query<UserEntity>(sql);
datas.AddRange(results);
);
// 排序
datas = datas.OrderByDescending(x => x.Timestamp).ToList();
到这里,就完成了有序的二次查询法的算法过程。这种分页算法存在一定的局限性,比如必须是连续的数据块,按一定时间区间进行分表才可使用,大区间查询时的分页,第一次查询会比较慢,比如查询区间为3年内的按天分表分页数据,将会导致第一次查询开启 3*365 个数据库连接,当然,这取决于你第一次查询采用的是并行查询还是轮询,还是有优化空间的。
结束语
本文共列出了多种分库分表方式下的查询问题,大部分 ORM 只解决了分表插入的问题,对于分页查询,实际上也是没有很好的解决方案,原因在于分页查询和业务的分割有着紧密的联系,很多时候不能简单的将业务问题认为是中间件的问题。有序的二次查询法作为一次探索,期望能解决部分业务带来的分页问题。

-
欢迎关注收取阅读最新文章
-
好看点个推荐呗~
- 出处:http://www.cnblogs.com/viter/
- 本文版权归作者和博客园共有,欢迎个人转载,必须保留此段声明;商业转载请联系授权,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
- 欢迎大家关注我的微信公众号,一起学习一起进步
外包项目可以找我,前端后端一锅端,作者:漫思,转载请注明原文链接:https://www.cnblogs.com/sexintercourse/p/17285928.html
如有疑问,请加我微信,maliang19860121,24小时在线战略合作伙伴面试官:给我讲一下分库分表方案
链接:https://www.cnblogs.com/littlecharacter/p/9342129.html
一、数据库瓶颈
1、IO瓶颈
2、CPU瓶颈
二、分库分表
1、水平分库
2、水平分表
3、垂直分库
4、垂直分表
三、分库分表工具
四、分库分表步骤
五、分库分表问题
1、非partition key的查询问题(水平分库分表,拆分策略为常用的hash法)
2、非partition key跨库跨表分页查询问题(水平分库分表,拆分策略为常用的hash法)
3、扩容问题(水平分库分表,拆分策略为常用的hash法)
六、分库分表总结
七、分库分表示例
一、数据库瓶颈
不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。接下来就可以想象了吧(并发量、吞吐量、崩溃)。
1、IO瓶颈
第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。
第二种:网络IO瓶颈,请求的数据太多,网络带宽不够 -> 分库。
2、CPU瓶颈
第一种:SQL问题,如SQL中包含join,group by,order by,非索引字段条件查询等,增加CPU运算的操作 -> SQL优化,建立合适的索引,在业务Service层进行业务计算。
第二种:单表数据量太大,查询时扫描的行太多,SQL效率低,CPU率先出现瓶颈 -> 水平分表。
二、分库分表
1、水平分库
1、概念:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
2、结果:
每个库的结构都一样;
每个库的数据都不一样,没有交集;
所有库的并集是全量数据;
3、场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库。
4、分析:库多了,io和cpu的压力自然可以成倍缓解。
2、水平分表
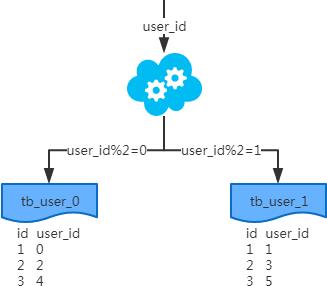
1、概念:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
2、结果:
每个表的结构都一样;
每个表的数据都不一样,没有交集;
所有表的并集是全量数据;
3、场景:系统绝对并发量并没有上来,只是单表的数据量太多,影响了SQL效率,加重了CPU负担,以至于成为瓶颈。
4、分析:表的数据量少了,单次SQL执行效率高,自然减轻了CPU的负担。
3、垂直分库
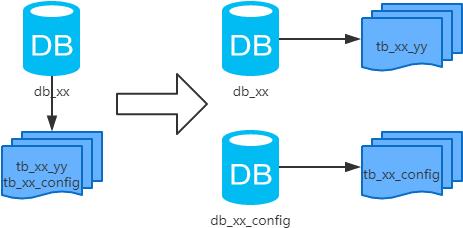
1、概念:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
2、结果:
每个库的结构都不一样;
每个库的数据也不一样,没有交集;
所有库的并集是全量数据;
3、场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块。
4、分析:到这一步,基本上就可以服务化了。例如,随着业务的发展一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化。再有,随着业务的发展孵化出了一套业务模式,这时可以将相关的表拆到单独的库中,甚至可以服务化。
4、垂直分表
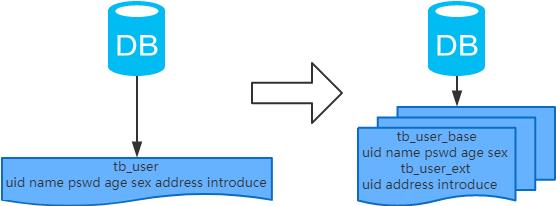
1、概念:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
2、结果:
每个表的结构都不一样;
每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据;
所有表的并集是全量数据;
3、场景:系统绝对并发量并没有上来,表的记录并不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大。以至于数据库缓存的数据行减少,查询时会去读磁盘数据产生大量的随机读IO,产生IO瓶颈。
4、分析:可以用列表页和详情页来帮助理解。垂直分表的拆分原则是将热点数据(可能会冗余经常一起查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表。这样更多的热点数据就能被缓存下来,进而减少了随机读IO。拆了之后,要想获得全部数据就需要关联两个表来取数据。但记住,千万别用join,因为join不仅会增加CPU负担并且会讲两个表耦合在一起(必须在一个数据库实例上)。关联数据,应该在业务Service层做文章,分别获取主表和扩展表数据然后用关联字段关联得到全部数据。
三、分库分表工具
1、sharding-sphere:jar,前身是sharding-jdbc;
2、TDDL:jar,Taobao Distribute Data Layer;
3、Mycat:中间件。
注:工具的利弊,请自行调研,官网和社区优先。
四、分库分表步骤
根据容量(当前容量和增长量)评估分库或分表个数 -> 选key(均匀)-> 分表规则(hash或range等)-> 执行(一般双写)-> 扩容问题(尽量减少数据的移动)。
五、分库分表问题
1、非partition key的查询问题(水平分库分表,拆分策略为常用的hash法)
1、端上除了partition key只有一个非partition key作为条件查询
映射法
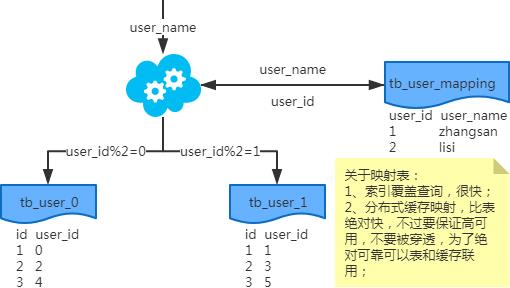
基因法
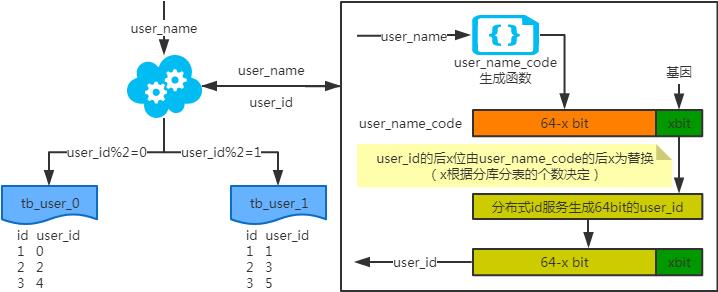
注:写入时,基因法生成user_id,如图。关于xbit基因,例如要分8张表,23=8,故x取3,即3bit基因。根据user_id查询时可直接取模路由到对应的分库或分表。根据user_name查询时,先通过user_name_code生成函数生成user_name_code再对其取模路由到对应的分库或分表。id生成常用snowflake算法。
2、端上除了partition key不止一个非partition key作为条件查询
映射法
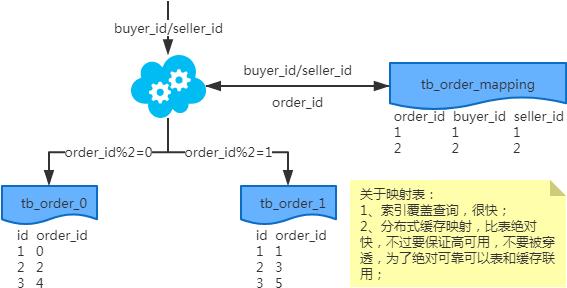
冗余法
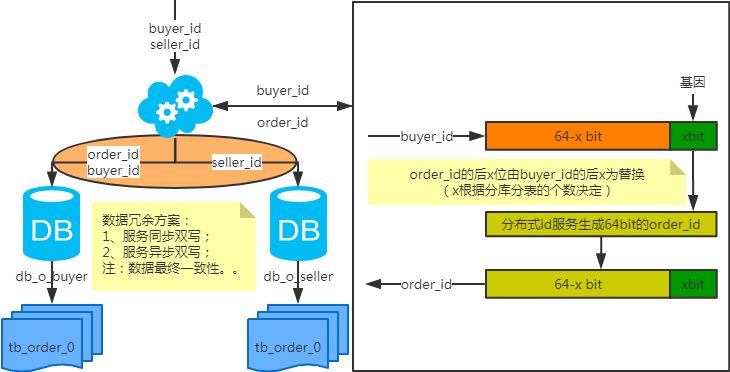
注:按照order_id或buyer_id查询时路由到db_o_buyer库中,按照seller_id查询时路由到db_o_seller库中。感觉有点本末倒置!有其他好的办法吗?改变技术栈呢?
3、后台除了partition key还有各种非partition key组合条件查询
NoSQL法
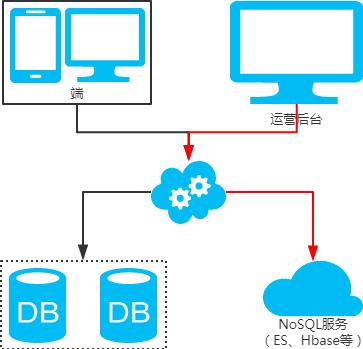
冗余法
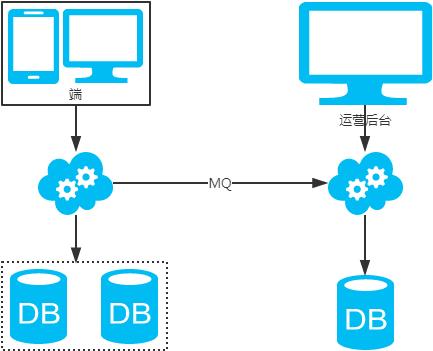
2、非partition key跨库跨表分页查询问题(水平分库分表,拆分策略为常用的hash法)
注:用NoSQL法解决(ES等)。
3、扩容问题(水平分库分表,拆分策略为常用的hash法)
1、水平扩容库(升级从库法
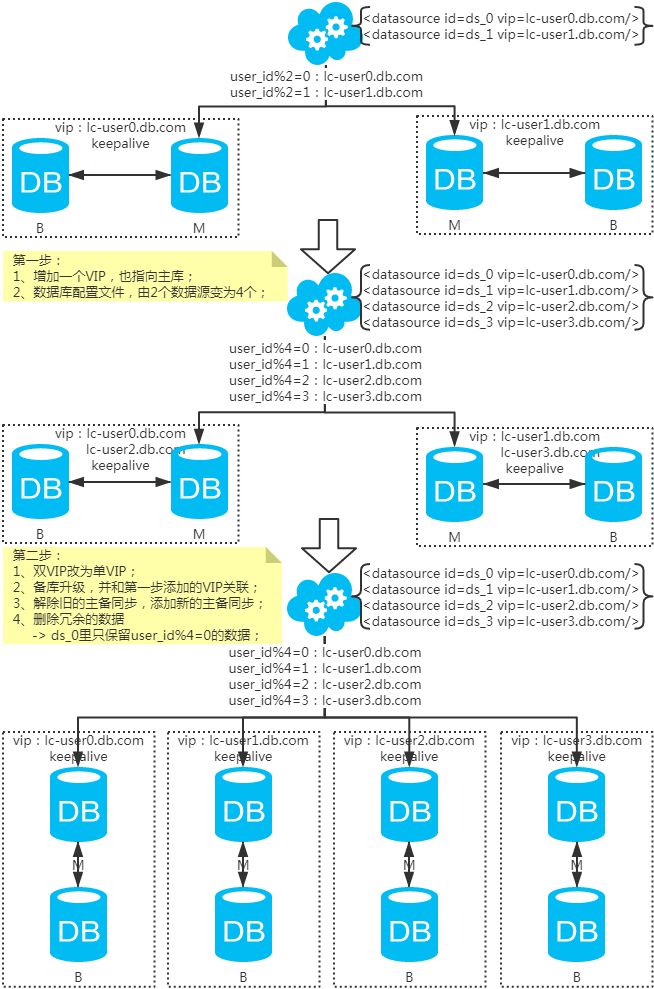
注:扩容是成倍的。
2、水平扩容表(双写迁移法)
第一步:(同步双写)应用配置双写,部署;
第二步:(同步双写)将老库中的老数据复制到新库中;
第三步:(同步双写)以老库为准校对新库中的老数据;
第四步:(同步双写)应用去掉双写,部署;
注:双写是通用方案。
六、分库分表总结
分库分表,首先得知道瓶颈在哪里,然后才能合理地拆分(分库还是分表?水平还是垂直?分几个?)。且不可为了分库分表而拆分。
1、选key很重要,既要考虑到拆分均匀,也要考虑到非partition key的查询。
2、只要能满足需求,拆分规则越简单越好。
七、分库分表示例
●编号619,输入编号直达本文
●输入m获取文章目录
Web开发
以上是关于亿万级分库分表后如何进行跨表分页查询的主要内容,如果未能解决你的问题,请参考以下文章