python之路-02 Python基础
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python之路-02 Python基础相关的知识,希望对你有一定的参考价值。
变量声明及赋值
声明变量:name = "Alex Li"
上述代码声明了一个变量,变量名为: name,变量name的值为:"lanhan"
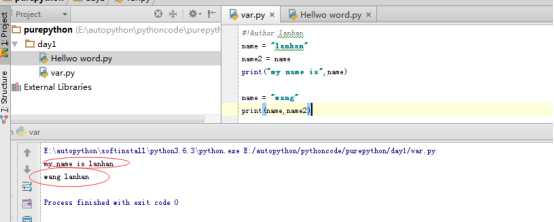
#!Author:lanhan
name = "lanhan"
name2 = name
print("my name is",name)
name = "wang"
print(name,name2)
变量定义的规则:
变量名只能是 字母、数字或下划线的任意组合
变量名的第一个字符不能是数字
以下关键字不能声明为变量名
[‘and‘, ‘as‘, ‘assert‘, ‘break‘, ‘class‘, ‘continue‘, ‘def‘, ‘del‘, ‘elif‘, ‘else‘, ‘except‘, ‘exec‘, ‘finally‘, ‘for‘, ‘from‘, ‘global‘, ‘if‘, ‘import‘, ‘in‘, ‘is‘, ‘lambda‘, ‘not‘, ‘or‘, ‘pass‘, ‘print‘, ‘raise‘, ‘return‘, ‘try‘, ‘while‘, ‘with‘, ‘yield‘]
2.2常量声明及赋值
常量声明及赋值:AGE = “27”
常量声明用大写字母,常量不应该修改,但可以改
2.3字符编码与二进制
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个字母和符号。
关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
字符编码发展史如下:

注:2.7不支持中文,需要添加# -*- coding:utf-8 -*-而3.3直接支持

字符编码与转码
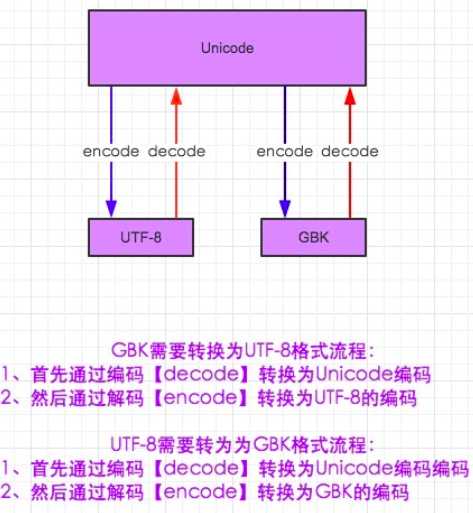
注:1.在python2默认编码是ASCII, python3里默认是unicode
- 在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
示例1:
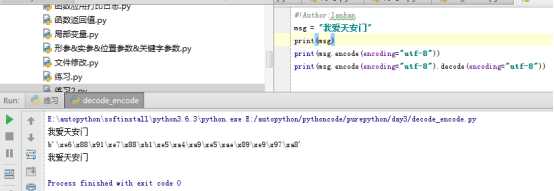
#!Author:lanhan
msg = "我爱天安门"
print(msg)
print(msg.encode(encoding="utf-8"))
print(msg.encode(encoding="utf-8").decode(encoding="utf-8"))
示例2:
#!Author:lanhan
#-*- coding:utf-8 -*-
import sys
print(sys.getdefaultencoding())
s = "你好"
s_to_unicode = s.decode("utf-8")
print(s_to_unicode)
‘‘‘
s_to_gbk = s.decode("utf-8").encoding("gbk")
print(s_to_gbk)
print("你好")
‘‘‘
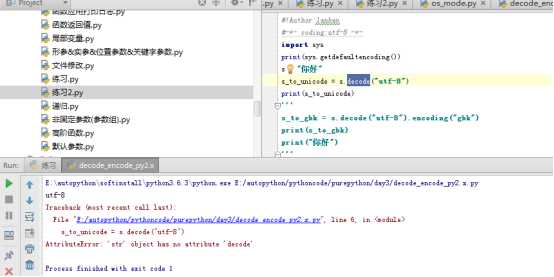
注:这里报错是正常的,因为#-*- coding:utf-8 -*-定义的是文件编码,并不是程序的编码,所以程序默认的编码还是unicode
示例3:
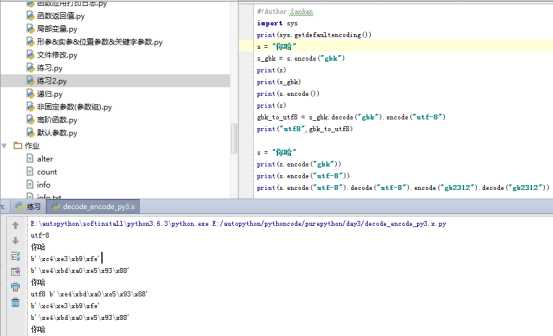
2.4注释
- 单行注释:# 被注释内容
- 多行注释:""" 被注释内容 """(3个单引号也可以)
扩:3个单引号可以用来打印输入值
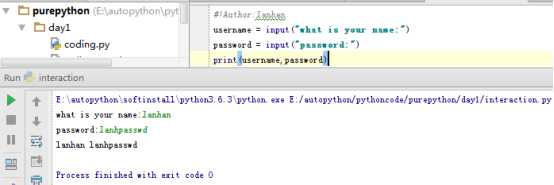
2.5 用户输入
input()
扩展1:字符串按固定格式的拼接‘‘‘ + 变量 +‘‘‘
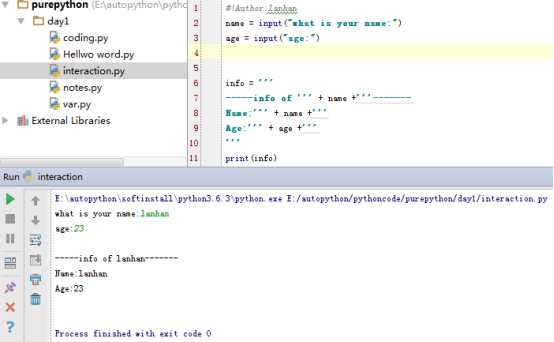
扩展2:字符串按固定格式的拼接%s
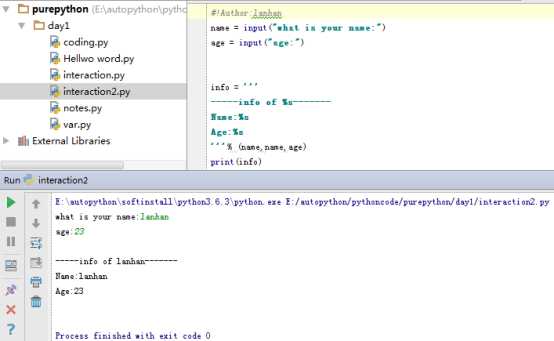
PS: 字符串是 %s;整数 %d;浮点数%f
扩展3:字符串格式化拼接 .format
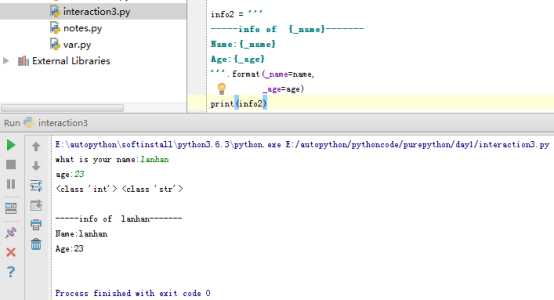
扩展4:顺序化格式拼接 .format
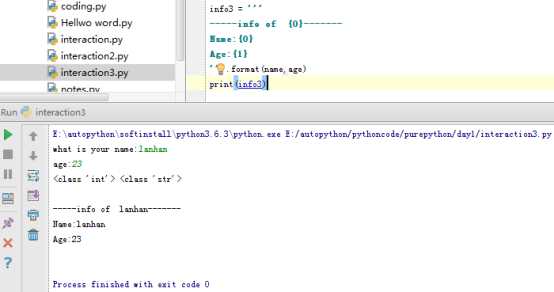
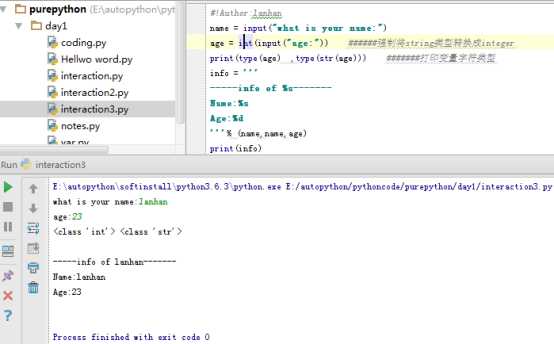
#!Author:lanhan
name = input("what is your name:")
age = int(input("age:")) ######强制将string类型转换成integer
print(type(age) ,type(str(age))) #######打印变量字符类型
info = ‘‘‘
-----info of %s-------
Name:%s
Age:%d
‘‘‘% (name,name,age)
#print(info1)
info2 = ‘‘‘
-----info of {_name}-------
Name:{_name}
Age:{_age}
‘‘‘.format(_name=name,
_age=age)
#print(info2)
info3 = ‘‘‘
-----info of {0}-------
Name:{0}
Age:{1}
‘‘‘.format(name,age)
print(info3)
扩展5:字符串强制转换
扩展6:密码暗文
# -*- coding: utf-8 -*-
import getpass
# 将用户输入的内容赋值给 name 变量
pwd = getpass.getpass("请输入密码:")
# 打印输入的内容
print(pwd)
2.6 python运行过程
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接比较与源码的时间,若大于源码时间则直接调用,否则就重新编译。
所以我们应该这样来定位PyCodeObject和pyc文件(预编译后的字节码文件
),我们说pyc文件其实是PyCodeObject的一种持久化保存方式
2.7数据类型
2.7.1数字
2.7.1.1 int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
2.7.1.2 long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,Python3.x都叫整型
2.7.1.3 float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号
2.7.1.4 complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注:Python中存在小数字池:-5 ~ 257
2.7.2布尔值
真或假
1 或 0
2.7.3字符串
"hello world"
2.8数据运算
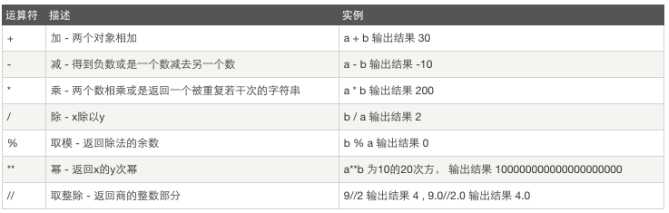
2.8.1算数运算
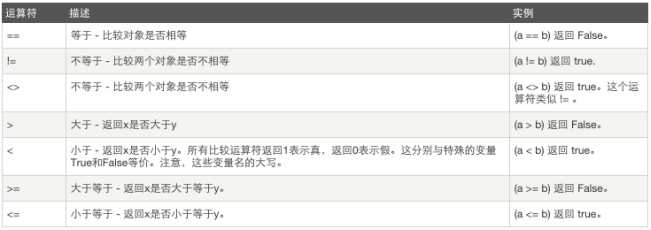
2.8.2比较运算
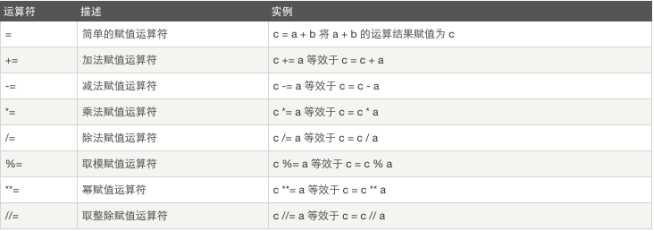
2.8.3赋值运算
2.8.4逻辑运算

2.8.5成员运算

2.8.6身份运算

2.8.7位运算
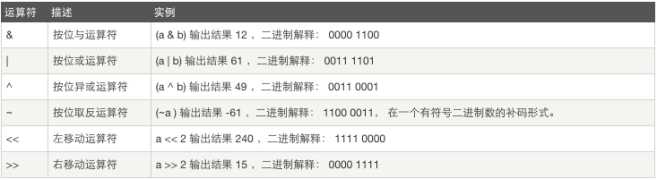
计算机中能表示的最小单位,是一个二进制位
计算机中能存储的最小单位,是一个二进制位(bit)
8bit = byte(字节)
1024byte = 1kbyte
1024kbyte = 1mbyte
1024mb = 1gb
1024gb = 1T
示例:
a = 60
b = 13
c = 0
c = a & b;
print “Line 1 - Value of c is ”,c
计算:
128 64 32 16 8 4 2 1
a = 60 0 0 1 1 1 1 0 0
b = 13 0 0 0 0 1 1 0 1
and
----------------------------------------------------------
0 0 0 0 1 1 0 0 = 12
or
0 0 1 1 1 1 0 1 = 61
---------------------------------------------------------------------
^
0 0 1 1 0 0 0 1 = 49
~a(195-256=-61)
1 1 0 0 0 0 1 1 = 195
a << 2 (左移1位,乘以2)
60*2*2 =240
a >> 2 (右移1位,除以2)
60/2/2 =15
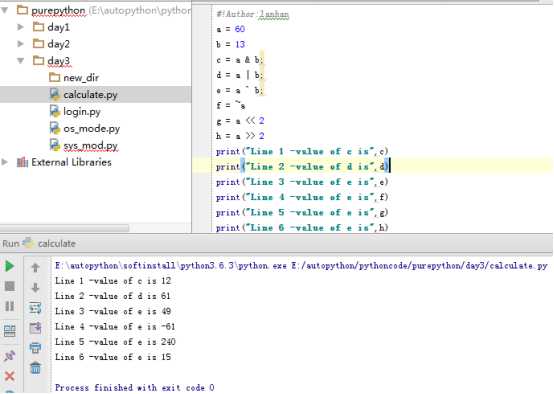
2.8.8运算符优先级
2.9 bytes类型
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)
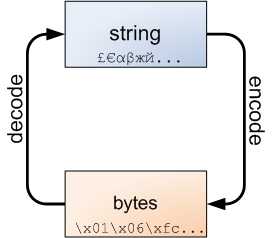
#!Author:lanhan
msg = "我爱天安门"
print(msg)
print(msg.encode(encoding="utf-8"))
print(msg.encode(encoding="utf-8").decode(encoding="utf-8"))
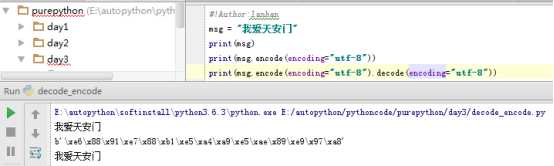
注:python3里默认的编码为utf-8,python2里默认的编码为系统编码
2.9.1 三元运算
result = 值1 if 条件 else 值2
如果条件为真:result = 值1
如果条件为假:result = 值2
2.9.2进制
2.9.2.1二进制
2.9.2.2八进制
2.9.2.3十进制
2.9.2.4十六进制
十六进制与十进制关系:
10:0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
16:0 1 2 3 4 5 6 7 8 9 A B C D E F
十六进制与二进制关系:

二进制转换十六进制:
二进制转换成十六进制的方法是,取四合一法,即从二进制的小数点为分界点,向左(或向右)每四位取成一位(无法凑足四位,在小数点的最左边(或最右边)补0,进行换算)
16进制的表示方法:
后缀:H 示例:BH表示16进制的11
前缀:0X* 示例:0X23就是16进制的23
二进制转换十六进制:
一分四,即一个十六进制数分成四个二进制数,用四位二进制按权相加,最后得到二进制,小数点依旧就可以啦
以上是关于python之路-02 Python基础的主要内容,如果未能解决你的问题,请参考以下文章