python requests库学习笔记(下)
Posted 艾里_Smiple
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python requests库学习笔记(下)相关的知识,希望对你有一定的参考价值。
1.请求异常处理
请求异常类型:

请求超时处理(timeout):
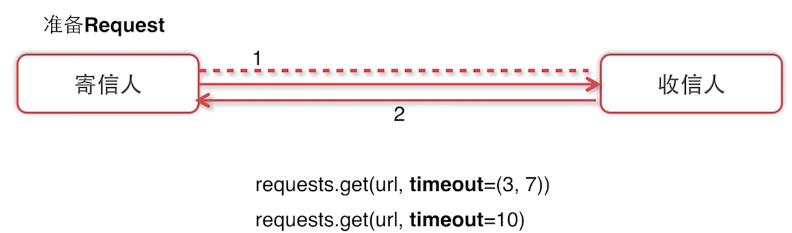
实现代码:
import requests
from requests import exceptions #引入exceptions
A:请求超时
def timeout_request():
try:
response = requests.get(build_uri(\'user/emails\'), timeout=0.1)
except exceptions.Timeout as e:
print e.message
返回数据:HTTPSConnectionPool(host=\'api.github.com\', port=443): Max retries exceeded with url: /user/emails (Caused by ConnectTimeoutError(<urllib3.connection.VerifiedHTTPSConnection object at 0x02BDEC50>, \'Connection to api.github.com timed out. (connect timeout=0.1)\'))
B:未认证时访问,报HTTPError
代码:
def timeout_request():
response = requests.get(build_uri(\'user/emails\'), timeout=10)
print response.text
print response.status_code
返回数据:
{"message":"Requires authentication","documentation_url":"https://developer.github.com/v3"}
401
C:抛出HTTPError异常信息
def timeout_request():
try:
response = requests.get(build_uri(\'user/emails\'), timeout=10)
response.raise_for_status()
except exceptions.HTTPError as e:
print e.message
返回数据:
401 Client Error: Unauthorized for url: https://api.github.com/user/emails #401客户端错误,没有认证的情况下访问url;
注意:以上的两个小程序,通过使用try.....except机制,就合理的处理了发送请求时的各种各样的“拦路虎”,依靠except分支可以帮助我们来处理异常,特别是在调用第三方服务的时候。
2.自定义Requests
requests库进阶部分官方域名:http://www.python-requests.org/en/master/user/advanced/
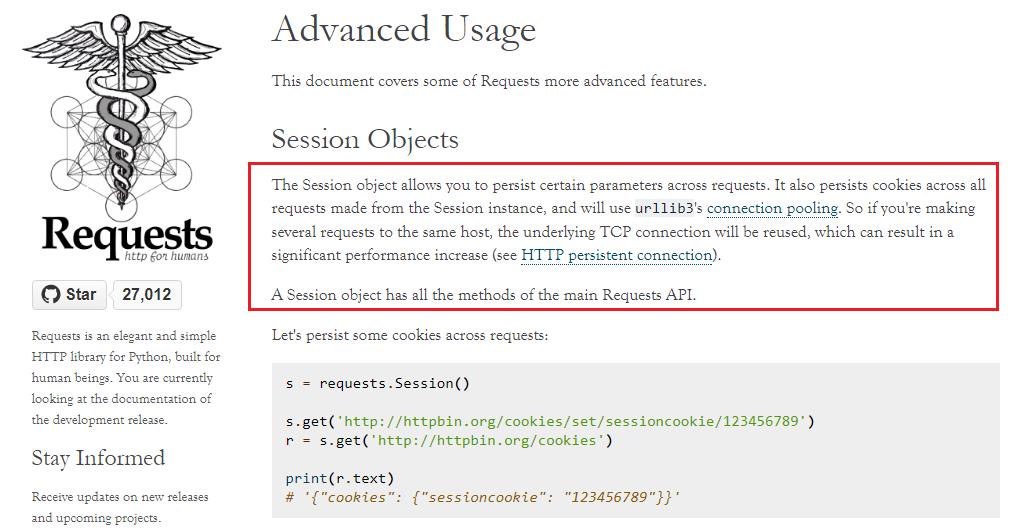
翻译上图中红色框中的内容:
会话对象允许你在发送请求的时候保留某些参数,它也能够保留会话过程中发送请求的cookie,并且使用urllib3进程池,所以如果你向同一个域名发送多个请求时,底层的TCP链接会被重用,由此会带来一个很明显的性能提高(参见HTTP持久链接)。
Session模块的组成:
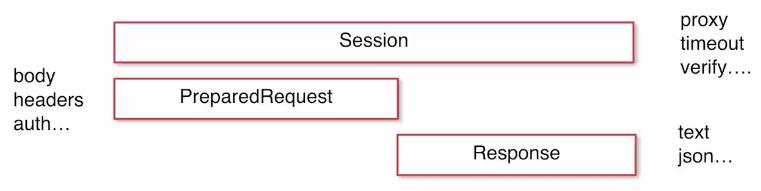
代码实现:
def hard_requests():
\'\'\'构造请求
\'\'\'
from requests import Request, Session #引入Request Session
s = Session()
headers = {\'User-Agent\': \'fake1.3.4\'}
req = Request(\'GET\', build_uri(\'user/emails\'), auth=(\'caolanmiao\', \'key########\'), headers=headers)
prepped = req.prepare() #使用prepare()方法准备url
print prepped.body
print prepped.headers
只有以上的代码时的返回结果:
None
{\'Authorization\': \'Basic aW1vb2NkZW1vOmltb29jZGVtbzEyMw==\', \'User-Agent\': \'fake1.3.4\'}
可见,请求还没有发送出去
\'\'\'发送请求
\'\'\'
resp = s.send(prepped, timeout=5) #发送请求,使用send()方法
print resp.status_code
print resp.request.headers
print resp.text
加上以上代码后的返回结果:
None
{\'Authorization\': \'Basic aW1vb2NkZW1vOmltb29jZGVtbzEyMw==\', \'User-Agent\': \'fake1.3.4\'}
200
{\'Authorization\': \'Basic aW1vb2NkZW1vOmltb29jZGVtbzEyMw==\', \'User-Agent\': \'fake1.3.4\'}
[{"email":"helloworld2@github.com","primary":true,"verified":false,"visibility":"private"},{"email":"hello-world@.123org","primary":false,"verified":false,"visibility":null},
可见,此时请求才发送成功。
通过上面的代码可以看出,使用自定义的方法构造请求,可以随时控制请求的发送时机。
3.处理响应
响应基本API:

代码举例:
# -*- coding: utf-8 -*-
import requests
response = requests.get(\'https://api.github.com\')
print "状态码,具体解释"
print response.status_code, response.reason
print "头部信息"
print response.headers
print "URL 信息"
print response.url
print "redirect 信息"
print response.history
print "耗费时长"
print response.elapsed
print "request 信息"
print response.request.method
print "编码信息"
print response.encoding
print "消息主体内容: byte"
print response.content, type(response.content)
print "消息主体内容: 解析"
print response.text, type(response.text)
print "消息主体内容"
print response.json(), type(response.json())
有关HTTP状态码(status_code)的域名,可以关注维基百科:https://zh.wikipedia.org/zh/HTTP%E7%8A%B6%E6%80%81%E7%A0%81
常见的status_code和reason:
2xx成功:这一类型的状态码,代表请求已成功被服务器接收、理解、并接受。
200 OK 请求已成功,请求所希望的响应头或数据体将随此响应返回
201 Created 请求已经被实现,而且有一个新的资源已经依据请求的需要而建立
202 Accepted 服务器已接受请求,但尚未处理
204 No Content 服务器成功处理了请求,没有返回任何内容
3xx重定向:这类状态码代表需要客户端采取进一步的操作才能完成请求。通常,这些状态码用来重定向,后续的请求地址(重定向目标)在本次响应的Location域中指明
301 Moved Permanently 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的
302 Found 要求客户端执行临时重定向(原始描述短语为“Moved Temporarily”)。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的
304 Not Modified 表示资源未被修改,因为请求头指定的版本If-Modified-Since或If-None-Match。在这种情况下,由于客户端仍然具有以前下载的副本,因此不需要重新传输资源
4xx客户端错误:这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理。除非响应的是一个HEAD请求,否则服务器就应该返回一个解释当前错误状况的实体,以及这是临时的还是永久性的状况。这些状态码适用于任何请求方法。浏览器应当向用户显示任何包含在此类错误响应中的实体内容。
400 Bad Request 由于明显的客户端错误(例如,格式错误的请求语法,太大的大小,无效的请求消息或欺骗性路由请求),服务器不能或不会处理该请求
401 Unauthorized 类似于403 Forbidden,401语义即“未认证”,即用户没有必要的凭据
403 Forbidden 没有权限;服务器已经理解请求,但是拒绝执行它。与401不同的是,身份验证并不能提供任何帮助,而且这个请求也不应该被重复提交
404 Not Found 请求失败,请求所希望得到的资源未被在服务器上发现,但允许用户的后续请求
5XX:服务器错误,表示服务器无法完成明显有效的请求
500 Internal Server Error 通用错误消息,服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。没有给出具体错误信息
502 Bad Gateway 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应
503 Service Unavailable 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是暂时的,并且将在一段时间以后恢复
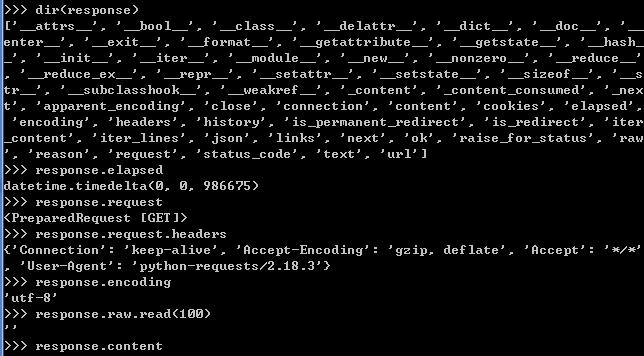

通过dir(response),可以查看response的全部API。
4.下载图片/文件

举例:通过下面代码实现下载图片(百度“github”图片中的第一个),下图是实现流程图
# -*- coding: utf -*-
import requests
def download_image():
"""demo: 下载图片, 文件
"""
# 伪造headers信息
headers = {\'User-Agent\': \'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36\'} #获取权限,使用Firefox浏览器
# 限定url
url = "http://img3.imgtn.bdimg.com/it/u=2228635891,3833788938&fm=21&gp=0.jpg"
response = requests.get(url, headers=headers, stream=True) #stream=True 流传输
# 打开文件
with open(\'demo.jpg\', \'wb\') as fd:
# 每128写入一次
for chunk in response.iter_content(128):
fd.write(chunk)
def download_image_improved():
"""demo: 下载图片
"""
headers = {\'User-Agent\': \'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.93 Safari/537.36\'}
url = "http://img3.imgtn.bdimg.com/it/u=2228635891,3833788938&fm=21&gp=0.jpg"
response = requests.get(url, headers=headers, stream=True)
from contextlib import closing
with closing(requests.get(url, headers=headers, stream=True)) as response: #把打开的流stream关闭,以节省资源
with open(\'demo1.jpg\', \'wb\') as fd:
for chunk in response.iter_content(128):
fd.write(chunk)
download_image_improved()
如下图,demo.jpg文件已经成功下载到本地了
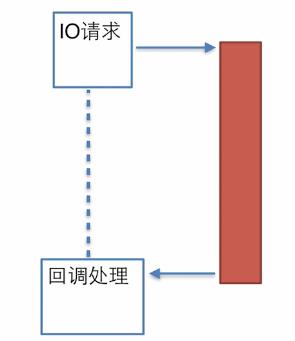
5.事件钩子
事件钩子(event hooks)模型
# -*- coding: utf-8 -*-
import requests
def get_key_info(response, *args, **kwargs):
"""回调函数
"""
print response.headers[\'Content-Type\']
def main():
"""主程序
"""
requests.get(\'https://api.github.com\', hooks=dict(response=get_key_info))
main()
返回数据:
application/json; charset=utf-8
利用事件钩子的方法可以使得request和response分开,特别是当代码很多的时候,方便管理。
6.Request库--HTTP认证
前面所讲的发送一个请求,得到响应,其实有一个简单的假设,就是通过HTTP通讯,我们访问的所有资源都是可见的,实际上很多时候,为了提高安全性,服务端要验证请求的来源,只有通过验证的请求,服务端才会响应。最简单基本认证的模式,如下图:
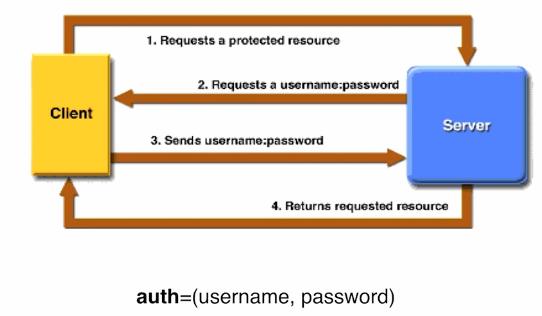
对于受保护的服务,在发送请求的时候就要加上一个requests库里的认证参数:auth
实验代码:
# -*- coding: utf-8 -*-
import requests
BASE_URL=\'https://api.github.com\'
def construct_url(end_point):
return \'/\'.join([BASE_URL,end_point])
def basic_auth():
"""基本认证
"""
response=requests.get(construct_url(\'user\'),auth=(\'caolanmiao\',\'key######\')) #添加auth参数,完成认证
print response.text
print response.request.headers
basic_auth()
返回数据:
{"login":"caolanmiao","id":22490616,"avatar_url":"https://avatars0.githubusercontent.com/u/22490616?v=4","gravatar_id":"","url":"https://api.github.com/users/caolanmiao","html_url":"https://github.com/caolanmiao","followers_url":"https://api.github.com/users/caolanmiao/followers","following_url":"https://api.github.com/users/caolanmiao/following{/other_user}","gists_url":"https://api.github.com/users/caolanmiao/gists{/gist_id}","starred_url":"https://api.github.com/users/caolanmiao/starred{/owner}{/repo}","subscriptions_url":"https://api.github.com/users/caolanmiao/subscriptions","organizations_url":"https://api.github.com/users/caolanmiao/orgs","repos_url":"https://api.github.com/users/caolanmiao/repos","events_url":"https://api.github.com/users/caolanmiao/events{/privacy}","received_events_url":"https://api.github.com/users/caolanmiao/received_events","type":"User","site_admin":false,"name":"Yannan.Jia","company":null,"blog":"","location":"Pecking","email":"534304558@qq.com","hireable":null,"bio":"Software QA Engineer","public_repos":1,"public_gists":0,"followers":0,"following":1,"created_at":"2016-09-28T06:00:27Z","updated_at":"2017-08-19T09:27:39Z","private_gists":0,
"total_private_repos":0,"owned_private_repos":0,"disk_usage":0,"collaborators":0,"two_factor_authentication":false,"plan":{"name":"free","space":976562499,"collaborators":0,"private_repos":0}}
{\'Authorization\': \'Basic Y2FvbGFubWlhbzpqaWEyMjE1NDkw\', \'Connection\': \'keep-alive\', \'Accept-Encoding\': \'gzip, deflate\', \'Accept\': \'*/*\', \'User-Agent\': \'python-requests/2.18.3\'}
返回的数据中,可以看到,添加auth参数后,在request的headers中加了一串Authorization,Basic后面的这一串码“Y2FvbGFubWlhbzpqaWEyMjE1NDkw”是什么呢?
其实这一串码是base64格式的,解码后就是我的用户名和密码(\'caolanmiao\',\'key######\')。

所以这种基本形式的认证是把用户名和密码放在request的headers中,使用任何语言(比如python)都可以对已经编码后的用户名和密码进行解码,可见,具备一定的安全性,但是安全性并不够强。
另一种安全性更强的认证---OAUTH认证
比如一个app在登录的时候,提供了通过github账号来快速登录的入口,那么完成登录的流程就如下图所示:
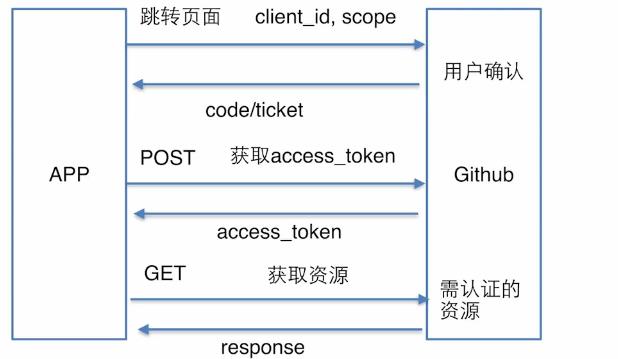
实验代码:
# -*- coding:utf-8 -*-
import requests
BASE_URL=\'https://api.github.com\'
def construct_url(end_point):
return \'/\'.join([BASE_URL,end_point])
def basic_oauth():
headers={\'Authorization\':\'token dd6322fa6c57a548268453dc245cbcdc352a7811\'} #通过token完成认证
# user/emails
response=requests.get(construct_url(\'user/emails\'),headers=headers)
print response.request.headers
print response.text
print response.status_code
7.Request库--Proxy(代理)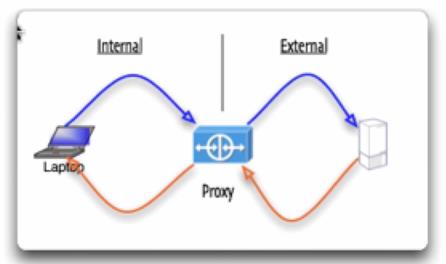
Heroku这个服务器(相当于国内的“阿里云”)对于国外的资源是可见的,比如是可以直接访问facebook的;Socks服务是一种在会话层的协议,类似于HTTP协议;

实现代码:
import requests
proxies={\'http\':\'socks5://127.0.0.1080\',\'https\':\'socks5://127.0.0.1080\'} #定义代理
url=\'https://www.facebook.com\'
response=requests.get(url,proxies=proxies,timeout=10) #添加代理
8.Request库--Session和Cookie
大家都知道http协议的请求和下一个请求之间是独立的、没有关系的。但是经常有些时候我们需要使得请求和上一个请求有关系,比如“在购物的情景中,已经登录了账户,把商品加入购物车中,不能出现发出一个新请求后,购物车中的商品清空了的情况”。
简而言之,session是存储在服务器端的,来保存登录信息;cookie是保存在浏览器中来存储的。
cookie存储的方式如图1:
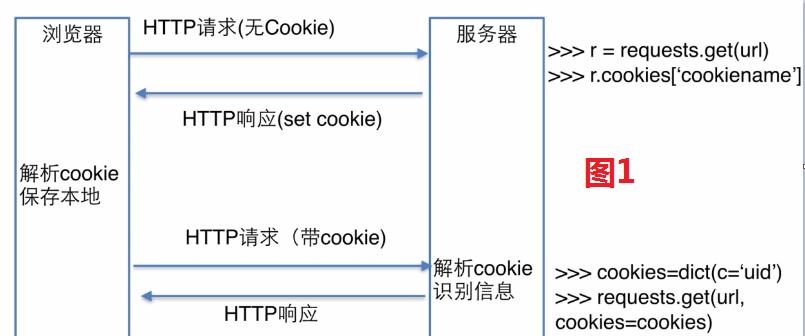
cookie存储的方式缺点:1.每次发送请求都带着cookie,造成了带宽特别大,特别占用网络请求;2.cookie如果在浏览器端是明文存储的话,容易解析时,是可以伪造的,很不安全。
那么鉴于cookie存储方式的不足,session存储的方式应运而生。
session存储的方式如图2:
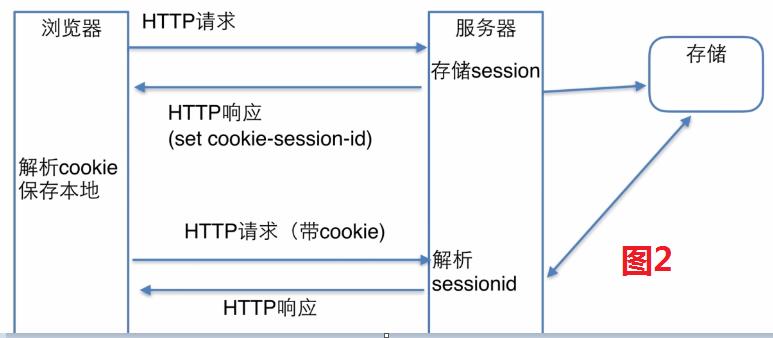
session存储的方式优点:1. 服务器返回的cookie-session-id相比于整个cookie是很小的,节省带宽,减少了网络传输的压力;2.服务器把session存储在数据库或者radis(内存)中,实现了本地化,相比于cookie存储方式的每次在网络中发送整个cookie更安全。
看到的同学也可以利用github上的api自己试试。
以上是关于python requests库学习笔记(下)的主要内容,如果未能解决你的问题,请参考以下文章