张同乐-从零开始,打造高效可靠的Locust性能测试
Posted ztloo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了张同乐-从零开始,打造高效可靠的Locust性能测试相关的知识,希望对你有一定的参考价值。
一、前言
欢迎来到Locust负载测试的世界!Locust是一款开源的负载测试工具,它可以模拟成千上万的用户同时访问你的应用程序,以测试其性能和稳定性。
这个工具具有易于使用、可扩展和高度可定制化等特点,因此被广泛应用于各种类型的应用程序的负载测试中。在本视频教程中,我们将为您介绍Locust的基础知识和使用方法,包括如何编写和运行测试脚本、如何设置虚拟用户、如何监控和分析测试结果等等。
我们还将通过实际案例演示如何应用Locust来测试Web应用程序、API、数据库等不同类型的应用程序。
二、Locust 内容详解
- 适用于: Locust 2.14.2 以上版本
- python版本: 3.8.10 以上版本

最新版本Locust 更多实战,更多案例,直达链接:https://edu.51cto.com/course/33521.html
更详细的介绍和演示的直达链接:https://edu.csdn.net/course/detail/38449
Locust性能评测及优化详解
文章目录
Locust性能评测及优化详解
这篇文章是用来补前一篇文章挖的坑,在解析了Locust的整体流程之后,还是要回归落地,看看它到底好不好用,能不能用。
性能评测
在《性能测试工具Locust源码浅析》中,我们进行了一个主流程的分析。本次我们将对Locust进行实际的评测,在具体的评测之前,为了评测结果尽量的准确,我们需要做如下的规约:
- 服务器端没有性能瓶颈(假设有无限能力)
- 系统环境没有限制设定(网络连接数无限制,TIME_WAIT回收及时)
- 外部环境没有额外消耗(网络监控软件、限流软件没有启动)
- 网络带宽没有瓶颈
- 不同待评测工具在同一台机器上进行评测(中间预留足够的资源回收时间)
环境准备
1、压测环境准备
- 机器配置:4核8G
- 操作系统:CentOS(尽量选择Linux系统)
- 网络环境:千兆局域网
- 文件句柄数限制设定:65536
- socket连接回收时间:30ms
2、服务环境准备
- 服务端服务:nginx 8 worker挂载一个静态文件(hello world)
- 机器配置:4核8G
- 操作系统:CentOS(尽量选择Linux系统)
- 网络环境:千兆局域网
- 文件句柄数限制设定:65536
- socket连接设置:net.ipv4.tcp_tw_reuse=1,net.ipv4.tcp_timestamps=1,net.ipv4.tcp_tw_recycle=1,net.ipv4.tcp_fin_timeout = 30
3、压测工具准备
- Locust
- Jmeter
- ab
- http_load
压测开始
在同一套环境分别使用不同的工具来进行相同场景的请求,这里只发送一个请求hello world的静态文件。不同测试之间停留10分钟以上间隔,以保证2台机器各自资源的回收。
- CPU、内存
- Load Avg(系统队列长度)
- socket连接数
- Window Size(TCP窗口)
Locust
针对Locust先使用单实例进行压测,脚本中设置min_wait和max_wait均为0;由于Locust使用的是requests.session来发起请求,所以默认支持http的keep-alive;在单实例执行完成后,使用4实例来进行相同场景的压测。
具体的压测脚本如下:
from locust import HttpLocust, TaskSet, task
class WebsiteTasks(TaskSet):
@task
def index(self):
self.client.get("/")
class WebsiteUser(HttpLocust):
task_set = WebsiteTasks
host = "http://10.168.xx.xx"
min_wait = 0
max_wait = 0
启动Locust的命令如下:
# 单实例
locust -f performance.py --no-web -c 2 -r 2 -t 5s
# 分布式
locust -f performance.py --master
locust -f performance.py --slave
# 访问http://127.0.0.1:8089 启动压测
不同并发和实例的压测结果如下:

注:分布式场景下,locust停止默认client貌似有bug,web端停止不了。
Jmeter
对于Jmeter工具,首先设置JVM堆大小为固定2G,不设置思考时间,默认勾选keep-alive。分别使用不同的并发数进行场景压测,最终评测出最优并发用户数和最大QPS。
Jmeter的HTTP请求设置如下:
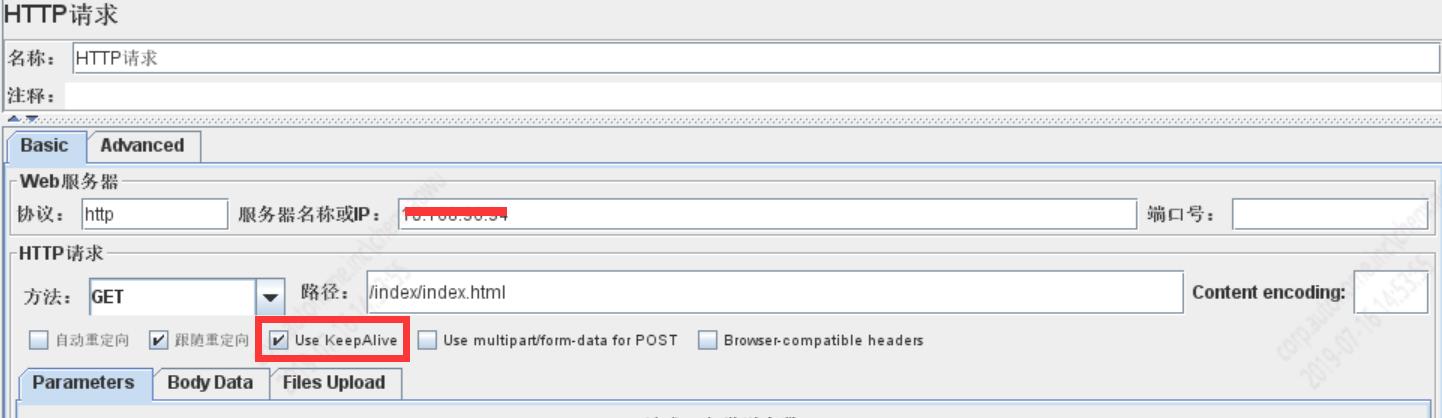
启动Jmeter的命令如下:
sh jmeter -n -t ../xxx.jmx -l /data/xxxx.jtl
不同并发数下的压测结果如下:

ab
ab是apache服务器中的一个压测工具,如果你不想安装整个apache,那么你可以直接安装httpd-tools即可。ab可以通过-k参数开启keep-alive模式,同时可以指定并发数和请求总数。
ab的启动命令及参数如下:
./ab -n 6000000 -c 150 http://10.168.xx.xx/index/index.html
ab不同并发数下的压测结果如下:
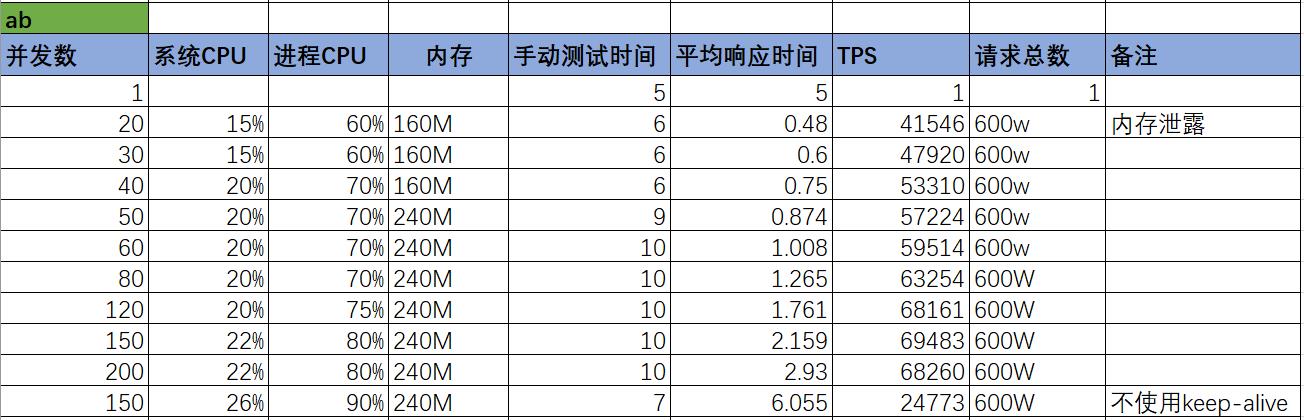
为什么ab做了这么多次测试呢?因为本来没有想过能压到这么高的并发。另外会发现使用keep-alive性能会提升很高。
http_load
http_load工具需要下载后在本地编译,由于http_load不支持keep-alive设置,所以只能指定并发数和请求总数。具体的压测命令如下:
./http_load -p 100 -f 6000000 http://10.168.xx.xx/index/index.html
http_load不同并发数下的压测结果如下:

因为http_load不支持设置keep-alive,所以它的数据和ab不使用keep-alive时差不多。
压测说明
由于压测场景比较单一,所以数据只能代表在该场景下,各工具在压测能力上的不同体现。如果换作另外的场景,可能工具之间的性能表现会有所变化。但总体来讲应该不会有太多的可变性。
各工具的压测能力,基本上与其实现的语言执行效率成正比。C > JAVA > Python。另外,在使用keep-alive的情况下,确实会提高通信性能。
判定压测工具最大并发能力,在确保手工测试时间与基准时间接近的情况下,依据QPS曲线来判定。如果压测的同时手工测试时间明显大于基准时间,则表示服务器先出现了性能问题。
很多工具的响应时间统计显示为0,所以单纯从工具端获取响应时间是不准的。需要在压测同时人工访问并计时,结合服务器端的QPS、响应时间等综合来得出。
性能优化
通过上面简单的对几个工具的评测,从这组数据的体现来讲,Locust是最弱的,Jmeter和网络上的评测结果接近。但是因为Locust属于Python系列,所以还是抱着希望来看看Locust是否还有优化的潜力。
Locust优化项
为了尝试给Locust进行性能提升,收集并思考从如下几种方式来进行尝试:
- 思考时间设置为0(默认为1秒,上述已设置)
- 使用keep-alive模式(默认为keep-alive,待确认是否生效)
- 替换为urllib3基础库(requests是基于urllib3进行的封装)
- 替换为使用socket库发送请求
- 替换为go实现的客户端发送请求
测试Locust默认是否为keep-alive
为了检测是否使用了keep-alive,可以通过wireshark来进行抓包,并查看不同请求是否复用了一个TCP连接;如果是则为keep-alive,否则就不是keep-alive模式。
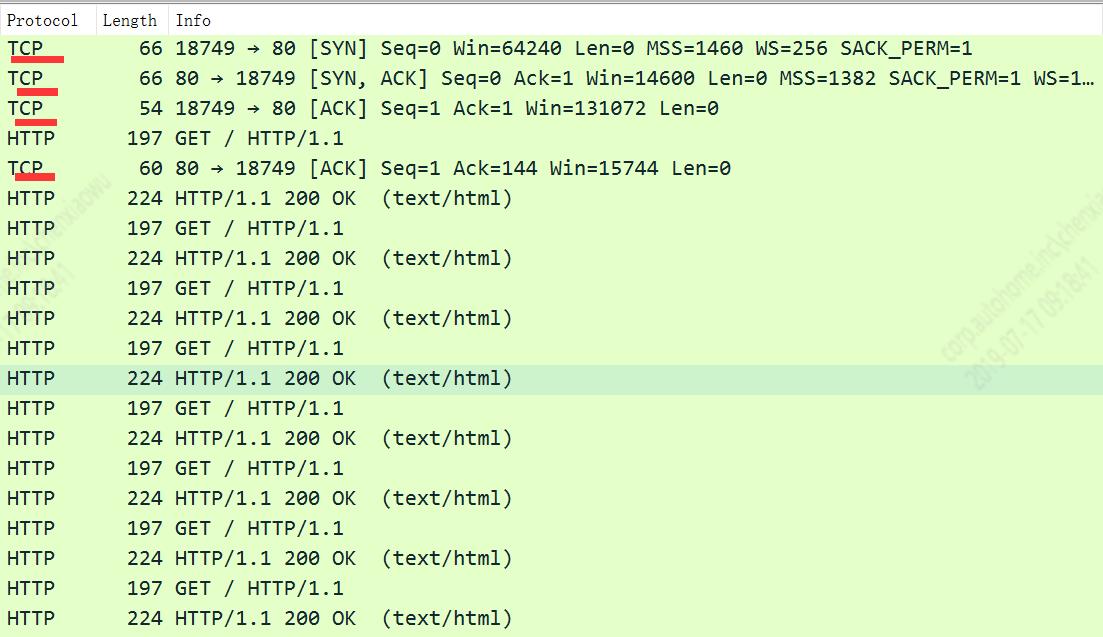
从结果可以看出,requests.session确实默认是支持keep-alive的。所以如果使用locust的默认client,这块是不需要优化的了。
替换为urllib3实现client
因为requests底层使用的是urllib3库,所以这里我们也尝试直接使用urllib3作为locust的client,看在性能上是否有提升。client代码如下:
import time
import urllib3
from locust import Locust, events
from locust.exception import LocustError
# from requests import Response
class Response:
def __init__(self, url):
self.url = url
self.reason = 'OK'
self.status_code = 200
self.data = None
class FastHttpSession:
def __init__(self, base_url=None):
self.base_url = base_url
# self.http = urllib3.PoolManager()
self.http = urllib3.HTTPConnectionPool(base_url)
def get(self, path):
full_path = f'self.base_urlpath'
return self.url_request(full_path)
def url_request(self, url, name="hello world"):
rep = Response(url)
start_time = time.time()
try:
# r = self.http.request('GET', url)
r = self.http.urlopen('GET', url)
total_time = int((time.time() - start_time) * 1000)
events.request_success.fire(request_type="urllib3", name=name, response_time=total_time, response_length=0)
except Exception as e:
total_time = int((time.time() - start_time) * 1000)
events.request_failure.fire(request_type="urllib3", name=name, response_time=total_time, exception=e)
rep.status_code = r.status
rep.reason = r.reason
rep.data = r.data
return rep
class FastHttpLocust(Locust):
client = None
def __init__(self):
super(FastHttpLocust, self).__init__()
if self.host is None:
raise LocustError(
"You must specify the base host. Either in the host attribute in the Locust class, or on the command line using the --host option.")
self.client = FastHttpSession(base_url=self.host)
从urllib3请求时录制的TCP通信可以看出,它默认也是使用了keep-alive模式。
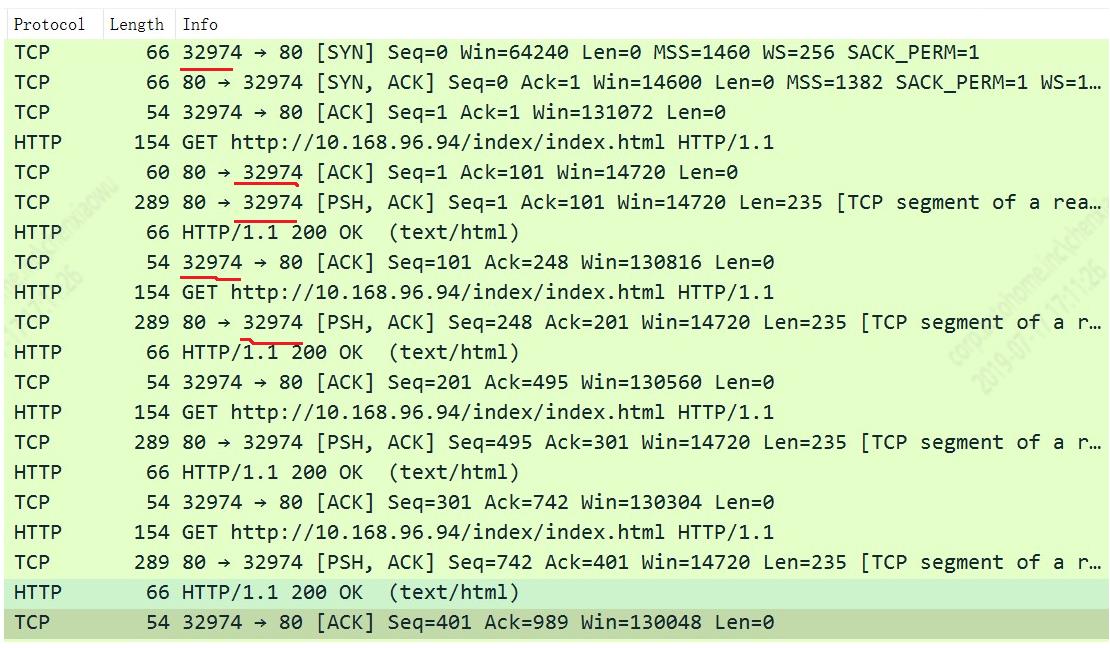
具体压测执行结果如下:
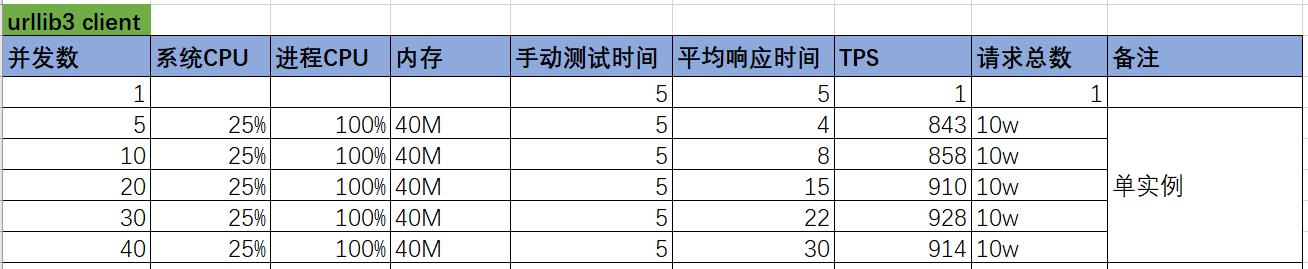
从压测结果可以看出,使用urllib3并发能力增加了将近一倍;不过相比较于其它语言的实现,还是有一定的差距。
替换为socket实现client
本来准备继续使用socket来实现client,但是TCP协议编程这块有坑,没有达到理想的效果,这个坑先留着日后再填!
替换为go实现client
在查找Locust优化方案的时候,发现已经有人实现了go语言的client。github地址:https://github.com/myzhan/boomer,安装步骤也很简单,按照项目说明即可很快完成。
使用go语言的client也很方便,只要把原来启动slave的命令替换为启动go程序即可。具体命令如下:
locust -f performance.py --master
./http.out --url http://10.168.xx.xx/index/index.html
不同并发数下的压测结果如下:

在boomer项目里,实现了2个版本的go客户端;除了上面的那个,还有一个fast版本的,启动命令如下:
locust -f performance.py --master
./fasthttp.out --url http://10.168.xx.xx/index/index.html
不同并发数下的压测结果如下:
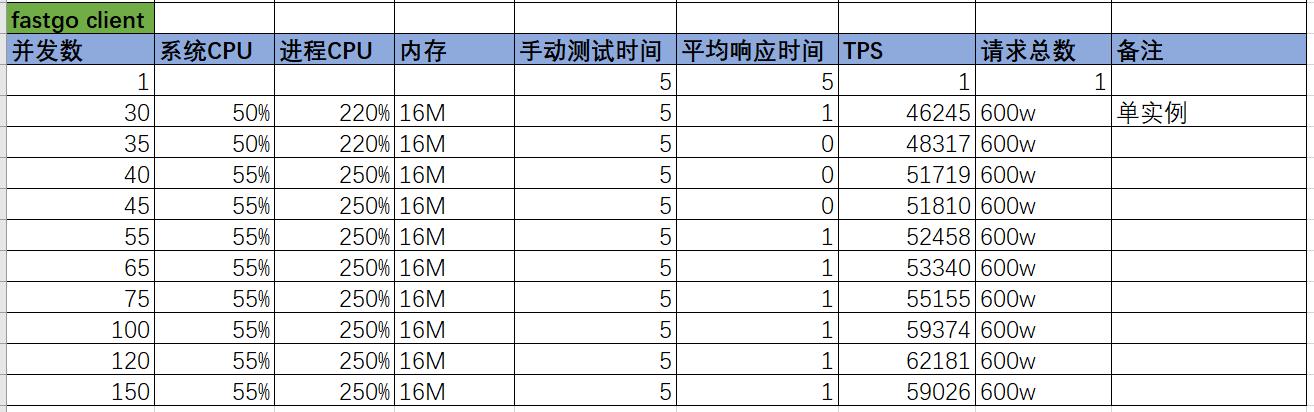
注意:普通版本client和fast版本的对应go文件分别为
examples/http/client.go和examples/fasthttp/client.go。
总结
从当前评测的结果来看,python实现的客户端在压力生成上并没有优势;而像ab这样的工具在场景支持上却不够丰富;如果希望2者兼得,那么go版本的locust客户端或许是个不错的选择!
locust官方github上有一个issue,相关人员对于locust施压能力不足的解释是:“locust主要解决场景开发效率问题,而不是解决生成压力的问题,因为人效成本远大于硬件的成本”。
如果你也在关注和学习性能,或者有觉得有出入的地方,那么欢迎一起来积极讨论,挖掘出即好用又高效的压测方案!
获取更多关于Python和自动化测试的文章,请扫描如下二维码!

以上是关于张同乐-从零开始,打造高效可靠的Locust性能测试的主要内容,如果未能解决你的问题,请参考以下文章