python简介变量输入输出
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python简介变量输入输出相关的知识,希望对你有一定的参考价值。
开头扯个淡:
好记性不如烂笔头,还真是这道理!!
一、了解编程
编程的目的:
编程语言就是用来开发程序让计算机工作,解放你的双手
编程语言:
就像人类语言一样,编程语言就是计算机与人沟通的语言
程序:
程序就是编程语言写下的代码文件
二、编程语言分类
机器语言:
机器语言是用二进制代码表示的计算机能直接识别和执行的一种机器指令的集合。
优点:灵活、直接执行和速度快。
缺点:不同型号的计算机其机器语言是不相通的,按着一种计算机的机器指令编制的程序,不能在另一种计算机上执行。
汇编语言:
汇编语言的实质和机器语言是相同的,都是直接对硬件操作,只不过指令采用了英文缩写的,标识符更容易识别和记忆。它同样需要编程者将每一步具体的操作用命令的形式写出来。 优点:能完成一般高级语言所不能实现的操作,而且源程序经汇编生成的可执行文件比较小,且执行速度很快。
缺点:源程序比较冗长、复杂、容易出错,而且使用汇编语言编程需要有更多的计算机专业知识。
高级语言:
明确地讲,高级语言就是说人话,用人类能读懂的(比如英文)字符编程。高级语言是绝大多数编程者的选择。和汇编语言相比,它不但将许多相关的机器指令合成为单条指令并且去掉了与具体操作有关但与完成工作无关的细节,例如使用堆栈、寄存器等。
优点:大大简化了程序中的指令。同时,由于省略了很多细节,编程者也就不需要有太多的专业知识。
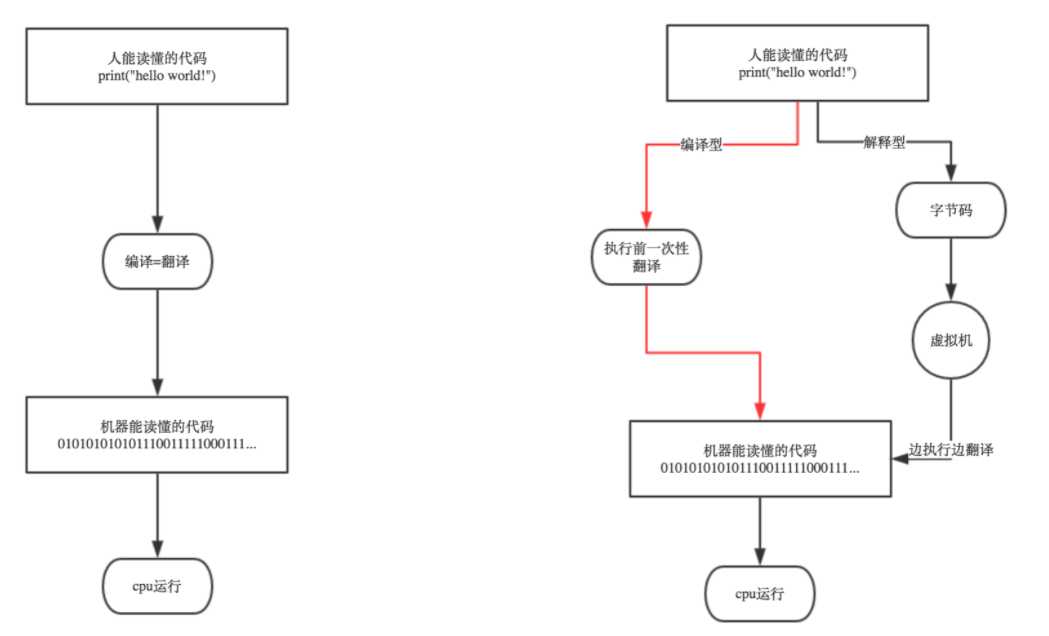
缺点:高级语言所编制的程序不能直接被计算机识别,必须经过转换才能被执行。
转换方式分类
解释类:应用程序源代码一边由相应语言的解释器“翻译”成目标代码,一边执行
优点:这种方式比较灵活,调试程序极为方便,程序一旦出错,立即调试立即就可以测试结果
缺点:效率比较低,而且不能生成可独立执行的可执行文件,应用程序不能脱离其解释器。只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
编译类:编译是指在程序执行之前,就将程序源代码“翻译”成机器指令,并保存成二进制文件
优点:编译后的代码可以直接在机器上运行,运行速度比解释型要高。
缺点:调试程序麻烦,程序一旦需要修改,必须先修改源代码,再重新编译后拿到二进制文件才能执行。
编程语言经历了:机器语言-------->汇编语言------------>高级语言
既然高级语言执行效率低,那么为什么要用它????
高级语言肯定没有机器和汇编快,但是现在硬件技术发达,主要就是注重开发效率!!时间就是金钱!!
开始python!(基于3.6.1)
python创始人是吉多·范罗苏姆(Guido van Rossum),在1989年圣诞节打发时间开发的,作为ABC的继承(卧槽,看看人家)
python的应用涉及各个方面!具体就不说了,太多
python是解释型的语言:
python在执行过程中会生成字节码文件,但是字节码文件不会保存下来,下一次就会重新解释执行
python的字节码文件其实也会保留,只有被当模块导入时才会保留
pyhon代码不能加密(现在都流行开源,加什么密!)
python解释器的种类:
- Cpython(最常用的版本)
Python的官方版本,使用C语言实现,使用最为广泛,CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上。 - Jyhton
Pytho的ava实现,Jython会将Python代码动态编译成Java字节码,然后在JVM上运行。 - IronPython
Python的C#实现,IronPython将Python代码编译成C#字节码,然后在CLR上运行。(与Jython类似) - PyPy(特殊)
Python实现的Python,将Python的字节码字节码再编译成机器码。 - RubyPython、Brython ...
下载安装:
上网查,一大把,很easy,别忘了配置环境变量
注意:linux中是自带的,如果想换新版本,需要再安装一个pyhon
多版本共存:
windows
在环境变量中加入两个python版本的路径,系统会从头开始找解释器,所以在命令行中输入pyhon就会执行第一个版本的python.exe文件;
我们将该程序文件名改为 python3.exe(3版本) 和 python2.exe(2版本) ,这样就可以自由选择了(其中的pip安装工具也同理)
linux
1.源码安装新版本(user/local)
2.将新版本bin目录加到 etc下的bashrc后面(避免 yum 出错)
yum工具是python写的,系统默认安装python
永久修改环境变量:
vim /etc/profile
在文件最后加入并保存:

输入: source /etc/profile 立即生效 (或者重新开终端)
将bin目录的python 解释器改为python3
mv python python3

这样 python 默认使用python2,python3 使用 3版本
注意yum 命令出错,它默认找user/bin下的python


第一个python程序!!
一、交互模式
输入python进入解释器

敲一行处一行结果,用于调试
退出(exit())后代码就没有了,不能永久保存代码
二、文件模式
windows
借助文本保存代码

执行

注:之后文件名都要改成 .py 结尾,用于区分
linux中

可以使用 ./ 执行,要在文件中加入文件头指定解释器(只在linux中)
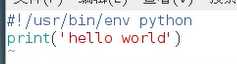
加执行权限

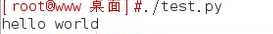
指定编码格式

python执行程序阶段:
1.启动解释器
2.解释器把文件内容读到内存
3.解释器解释执行代码
python注释:
单行 #
多行 ‘‘‘内容‘‘‘ """内容"""
python脚本穿参数(暂时了解下就得)
想要如下方式穿参数

先导入模块
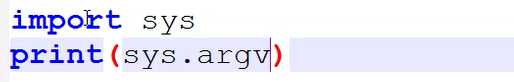
参数被传入了

pyc文件(导入保留,开始有说)
直接执行,目录内没有pyc文件

以导入的方式执行(-m)

这样dir查看目录,就会有pyc文件,这个pyc可以直接运行
变量
可以变化的量,记录着状态
变量可以是任意类型
变量名规范:
只能是 字母、数字或下划线的任意组合
第一个字符不能是数字
以下关键字不能声明为变量名
[‘and‘, ‘as‘, ‘assert‘, ‘break‘, ‘class‘, ‘continue‘, ‘def‘, ‘del‘, ‘elif‘, ‘else‘, ‘except‘, ‘exec‘, ‘finally‘, ‘for‘, ‘from‘, ‘global‘, ‘if‘, ‘import‘, ‘in‘, ‘is‘, ‘lambda‘, ‘not‘, ‘or‘, ‘pass‘, ‘print‘, ‘raise‘, ‘return‘, ‘try‘, ‘while‘, ‘with‘, ‘yield‘]
声明和引用
声明
变量名 = 变量值 name = shuai # 两者是一种绑定的关系
引用
print(name) # shuai
定义变量的原理
定义一个变量,就在内存中开辟一个“屋子”存放着值,然后变量名指向这个房间;
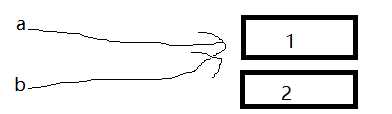
如下图:
a 指向 1,当 a 变为指向2时,那么与 1 的关系就断开了,但是 1还是存在的(可以多个变量指向一个值(同一块地址))

内存回收:
变量会占内存,对于引用计数为零的变量值(没有绑定变量名的内存值),就会被自动清理
查看变量内存地址(id):
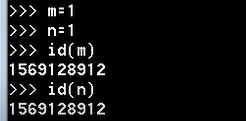
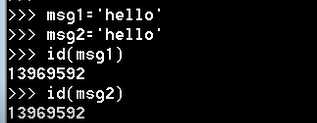
这里没有开辟新的空间存放 n 和 msg2 的值 ???? 这不就跟之前变量定义相悖了??
python优化了,对于这种较小的值,内存中存在的话就直接指向,省去一些内存开销
输入输出
输入:
input() 接收用户输入
type() 查看类型
s = input(‘输入:‘) # 输入:1 print(s) # 1 print(type(s)) #<class ‘str‘>
input会将所有输入的内容都转换为 字符串
在2版本中:
input() 输入什么数据类型,就是什么数据类型
raw_input() 与3版本 input() 一样
s = input(‘输入:‘) # 输入:1 print(s) # 1 print(type(s)) #<class ‘int‘>
列子:
import getpass
name = input(‘用户名:‘)
pwd = getpass.getpass(‘密码:‘)
print(name,pwd)
getpass 将密码改为不显示输入
注:现在这个getpass只在命令行有效
输出:
print()
打印到屏幕,多个元素用 , 分隔
%s 格式化符号,逗号只能在后面接着打印,%s 可以在任意位置
print(‘ %s是一个%s‘ %(‘这小子’,‘帅哥‘) )
注意: 3版本中 print 是函数,需要有括号,2版本不需要
以上是关于python简介变量输入输出的主要内容,如果未能解决你的问题,请参考以下文章