prometheus基础介绍
Posted 戈伍昂的领悟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了prometheus基础介绍相关的知识,希望对你有一定的参考价值。
Prometheus简介
Prometheus是一套开源的系统监控报警框架,作为新一代的云原生监控系统,目前已经有上千个贡献者参与到Prometheus的研发工作上,并且超过120+项的第三方集成。
Prometheus非常适合记录纯数字的时间序列,既可以是以主机为中心的监控,也可以是以服务为导向的动态架构。在微服务的世界,它支持多维度的数据集合,查询功能非常强大。
Prometheus用于评估可用性。如果想要100%的精准度,比如每个请求的清单,那么,Prometheus可能不是一个好的选择,因为它收集上来的数据可能没这么细致、完整。
Prometheus 的组件与架构
Prometheus 的生态系统包括多个组件,大部分的组件都是用Go语言编写的,因此部署非常方便,而这些组件大部分都是可选的,Prometheus的基本架构如下图所示:
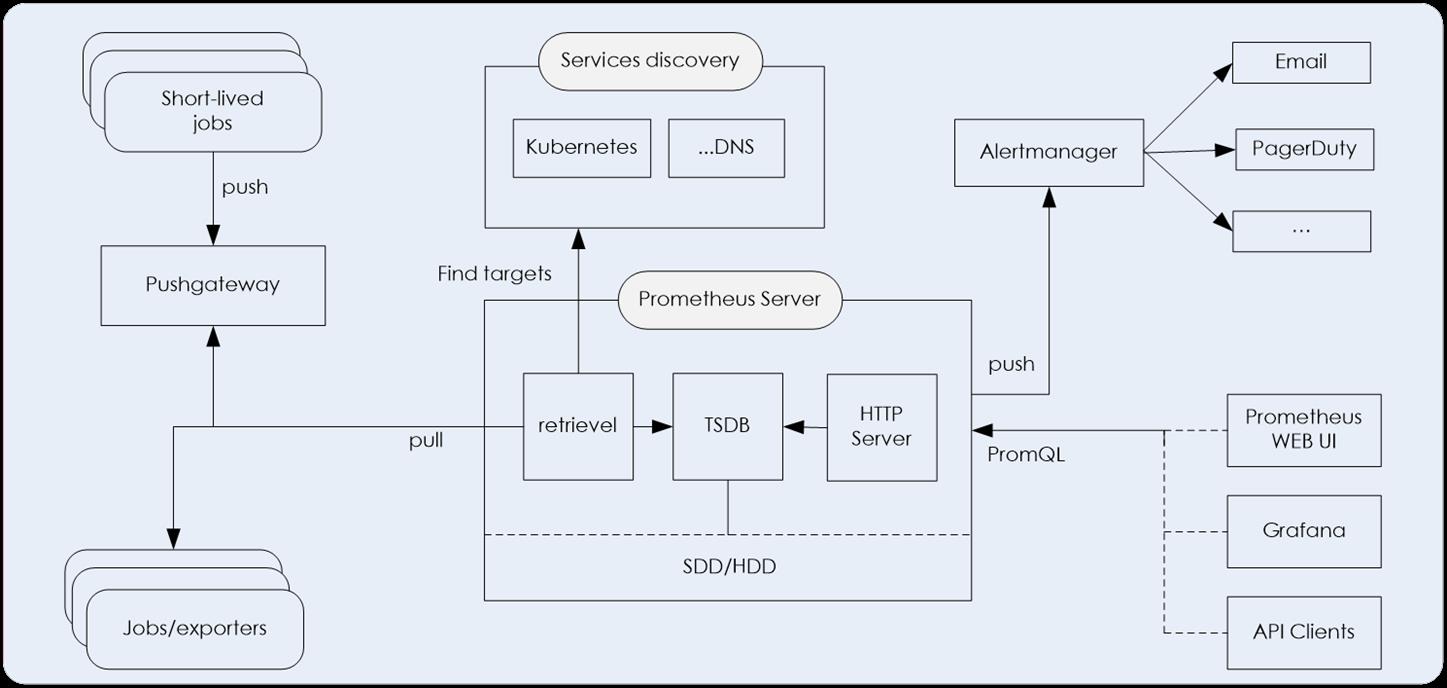
对几个主要组件介绍如下:
- Prometheus Server
Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。
- 推送网关(push gateway)
主要是用来接收由Client push过来的指标数据,在指定的时间间隔,由Prometheus Server来抓取。
- Exporter
主要用来采集数据,并通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的接口,即可获取到需要采集的监控数据。
常见的Exporter有很多,例如node_exporter、mysqld_exporter、statsd_exporter、blackbox_exporter、haproxy_exporter等等,支持如 HAProxy,StatsD,Graphite,Redis 此类的服务监控。
- 告警管理器(Alertmanager)
管理告警,主要是负责实现监控报警功能。
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。
Prometheus数据模型
promethes监控中对于采集过来的数据统称为metrics数据,当我们需要为某个系统、某个服务做监控统计时,就需要用到Metrics数据。因此,metric是对采样数据的总称,注意,metrics并不代表某种具体的数据格式,它是对于度量计算单位的抽象。
Prometheus中存储的数据为时间序列T-S(time-series),是由 metric 的名字和一系列的标签(key/value键值对)来唯一标识的,不同的标签代表不同的时间序列。格式如下:
<metric name><label name>=<label value>, …
-
metric名字:该名字表示一个可以度量的指标,名字需要有表达的含义,一般用于表示 metric 的功能
例如prometheus_http_requests_total, 表示http请求的总数。
其中,metric 名字由 ASCII 字符,数字,下划线,以及冒号组成。
-
标签:标签可以使 Prometheus的数据更加丰富,能够区分具体不同的实例。
例如:
prometheus_http_requests_totalcode="200"
表示所有http请求中状态码为200的请求。当code="403"时,就变成一个新的metric。标签中的键由ASCII字符,数字,以及下划线组成。
时间序列的样本数据包括一个float64的值和一个毫秒级的unix时间戳,这些数据是按照某个时序以时间维度采集的数据。
Prometheus样本
在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(metric):指标名称和描述当前样本特征的 labelsets;
- 时间戳(timestamp):一个精确到毫秒的时间戳;
- 样本值(value): 一个 folat64 的浮点型数据表示当前样本的值。
表示方式:
通过如下表达方式表示指定指标名称和指定标签集合的时间序列:
<metric name><label name>=<label value>, ...
例如,指标名称为 api_http_requests_total,标签为 method="POST" 和 handler="/messages" 的时间序列可以表示为:
api_http_requests_totalmethod="POST", handler="/messages"
Prometheus的常见数据类型
Prometheus 客户端库主要提供四种主要的数据类型,分别为:
Counter
Counter是计数器类型:
- Counter 用于累计值,例如记录请求次数、任务完成数、错误发生次数。
- 一直增加,不会减少。
- 重启进程后,会被重置。
例如:http_response_totalmethod="GET",endpoint="/api/tracks" 100
http_response_totalmethod="GET",endpoint="/api/tracks" 160
Counter 类型数据可以让用户方便的了解事件产生的速率的变化,在PromQL内置的相关操作函数可以提供相应的分析.
比如以HTTP应用请求量来进行说明:
-
通过
rate()函数获取HTTP请求量的增长率rate(http_requests_total[5m]) -
通过
topk()查询当前系统中,访问量前10的HTTP地址topk(10, http_requests_total)
Gauge
Gauge是测量器类型:
- Gauge是常规数值,例如温度变化、内存使用变化。
- 可变大,可变小。
- 重启进程后,会被重置
例如:
memory_usage_byteshost="master-01" 100
memory_usage_byteshost="master-01" 30
memory_usage_byteshost="master-01" 50
memory_usage_byteshost="master-01" 80
对于 Gauge 类型的监控指标,通过 PromQL 内置函数 delta() 可以获取样本在一段时间内的变化情况
例如,计算 CPU 温度在两小时内的差异:
dalta(cpu_temp_celsiushost="zeus"[2h])
你还可以通过PromQL 内置函数 predict_linear() 基于简单线性回归的方式,对样本数据的变化趋势做出预测。
例如,基于 2 小时的样本数据,来预测主机可用磁盘空间在 4 个小时之后的剩余情况:
predict_linear(node_filesystem_freejob="node"[2h], 4 * 3600) < 0
Histogram
histogram是柱状图,在Prometheus系统的查询语言中,有三种作用:
- 在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中. 后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
- 对每个采样点值累计和(sum)
- 对采样点的次数累计和(count)
度量指标名称: [basename]_上面三类的作用度量指标名称
[basename]_bucketle="上边界", 这个值为小于等于上边界的所有采样点数量[basename]_sum总和[basename]_count次数
小结:如果定义一个度量类型为Histogram,则Prometheus会自动生成三个对应的指标
Histogram 类型的样本会提供三种指标(假设指标名称为 ):
样本的值分布在 bucket 中的数量,命名为 <basename>_bucketle="<上边界>"。
解释的更通俗易懂一点,这个值表示指标值小于等于上边界的所有样本数量。
1、在总共2次请求当中。http 请求响应时间 <=0.005 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="0.005", 0.0
2、在总共2次请求当中。http 请求响应时间 <=0.01 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="0.01", 0.0
3、在总共2次请求当中。http 请求响应时间 <=0.025 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="0.025", 0.0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="0.05", 0.0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="0.075", 0.0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="0.1", 0.0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="0.25", 0.0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="0.5", 0.0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="0.75", 0.0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="1.0", 0.0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="2.5", 0.0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="5.0", 0.0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="7.5", 2.0
4、在总共2次请求当中。http 请求响应时间 <=10 秒 的请求次数为 2
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="10.0", 2.0
io_namespace_http_requests_latency_seconds_histogram_bucketpath="/",method="GET",code="200",le="+Inf", 2.0
所有样本值的大小总和,命名为 <basename>_sum。
5、实际含义: 发生的2次 http 请求总的响应时间为 13.107670803000001 秒
io_namespace_http_requests_latency_seconds_histogram_sumpath="/",method="GET",code="200", 13.107670803000001
样本总数,命名为 <basename>_count值和 <basename>_bucketle="+Inf" 相同。
6、实际含义: 当前一共发生了 2 次 http 请求
io_namespace_http_requests_latency_seconds_histogram_countpath="/",method="GET",code="200", 2.0
注意:
bucket 可以理解为是对数据指标值域的一个划分,划分的依据应该基于数据值的分布。
注意后面的采样点是包含前面的采样点的,假设 xxx_bucket...,le="0.01" 的值为 10,而 xxx_bucket...,le="0.05" 的值为 30,那么意味着这 30 个采样点中,有 10 个是小于 0.01s的,其余 20 个采样点的响应时间是介于0.01s 和 0.05s之间的。
可以通过 histogram_quantile() 函数来计算 Histogram 类型样本的分位数。
举个例子,假设样本的 9 分位数(quantile=0.9)的值为 x,即表示小于 x 的采样值的数量占总体采样值的 90%。
Histogram 还可以用来计算应用性能指标值(Apdex score)。
Summary
与 Histogram 类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算。
它也有三种作用:
- 对于每个采样点进行统计,并形成分位图。(如:正态分布一样,统计低于60分不及格的同学比例,统计低于80分的同学比例,统计低于95分的同学比例)
- 统计班上所有同学的总成绩(sum)
- 统计班上同学的考试总人数(count)
带有度量指标的[basename]的summary 在抓取时间序列数据有如命名。
- 观察时间的
φ-quantiles (0 ≤ φ ≤ 1), 显示为[basename]分位数="[φ]" [basename]_sum, 是指所有观察值的总和[basename]_count, 是指已观察到的事件计数值
样本值的分位数分布情况,命名为 <basename>quantile="<φ>"。
1、含义:这 12 次 http 请求中有 50% 的请求响应时间是 3.052404983s
io_namespace_http_requests_latency_seconds_summarypath="/",method="GET",code="200",quantile="0.5", 3.052404983
2、含义:这 12 次 http 请求中有 90% 的请求响应时间是 8.003261666s
io_namespace_http_requests_latency_seconds_summarypath="/",method="GET",code="200",quantile="0.9", 8.003261666
所有样本值的大小总和,命名为 <basename>_sum。
1、含义:这12次 http 请求的总响应时间为 51.029495508s
io_namespace_http_requests_latency_seconds_summary_sumpath="/",method="GET",code="200", 51.029495508
样本总数,命名为 <basename>_count。
1、含义:当前一共发生了 12 次 http 请求
io_namespace_http_requests_latency_seconds_summary_countpath="/",method="GET",code="200", 12.0
现在可以总结一下 Histogram 与 Summary 的异同:
它们都包含了 <basename>_sum 和 <basename>_count 指标
Histogram 需要通过 <basename>_bucket 来计算分位数,而 Summary 则直接存储了分位数的值。
prometheus_tsdb_wal_fsync_duration_secondsquantile="0.5" 0.012352463
prometheus_tsdb_wal_fsync_duration_secondsquantile="0.9" 0.014458005
prometheus_tsdb_wal_fsync_duration_secondsquantile="0.99" 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Promtheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s。
本文来自博客园,作者:厚礼蝎,转载请注明原文链接:https://www.cnblogs.com/guangdelw/p/17143646.html
以上是关于prometheus基础介绍的主要内容,如果未能解决你的问题,请参考以下文章