JAVA中如何高效的实现SQL的like语法?
Posted 轻风博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JAVA中如何高效的实现SQL的like语法?相关的知识,希望对你有一定的参考价值。

本文主要介绍了一些主流的解析器是怎么实现like的语法逻辑,接着作者分析了几种实现方式的优劣,最终采用状态机的方式,针对场景一步一步进行性能优化。提及
最近在优化项目的like语法,那既然谈到了SQL,我们不妨来看看一些主流的解析器是怎么实现like的语法逻辑。这里需要提一下主流的两种SQL解析器,它们分别是ANTLR和Calcite。
/** SQL @code LIKE function. */
public static boolean like(String s,String pattern)
final String regex = Like.sqlToRegexLike(pattern, null);
return Pattern.matches(regex, s);
/** Translates a SQL LIKE pattern to Java regex pattern.*/
static String sqlToRegexLike(String sqlPattern,char escapeChar)
int i;
final int len = sqlPattern.length();
final StringBuilder javaPattern = new StringBuilder(len + len);
for (i = 0; i < len; i++)
char c = sqlPattern.charAt(i);
if (JAVA_REGEX_SPECIALS.indexOf(c) >= 0)
javaPattern.append(\'\\\\\');
if (c == escapeChar)
if (i == (sqlPattern.length() - 1))
throw invalidEscapeSequence(sqlPattern, i);
char nextChar = sqlPattern.charAt(i + 1);
if ((nextChar == \'_\')
|| (nextChar == \'%\')
|| (nextChar == escapeChar))
javaPattern.append(nextChar);
i++;
else
throw invalidEscapeSequence(sqlPattern, i);
else if (c == \'_\')
javaPattern.append(\'.\');
else if (c == \'%\')
javaPattern.append("(?s:.*)");
else
javaPattern.append(c);
return javaPattern.toString();
...
try
Pattern pattern = patterns.get(buildKey(right, escTmp), new Callable<Pattern>()
@Override
public Pattern call() throws Exception
return Pattern.compile(buildPattern(right, escTmp), Pattern.CASE_INSENSITIVE);
);
Matcher m = pattern.matcher(left);
return m.matches() ? 1l : 0l;
catch (ExecutionException e)
throw new FunctionException(e.getCause());
...到此,综上来看,不少项目是基于正则表达式来完成的,接下来我整理了下我最近实现的几种方式:
正则表达式实现
public static boolean like(final String dest, final String pattern)
String regex = regexParse(pattern);
regex = regex.replace("_",".").replace("%",".*?");
Pattern p = Pattern.compile(regex,Pattern.CASE_INSENSITIVE | Pattern.DOTALL);
return p.matcher(dest).matches();
这种方式在代码层面简单明了,但是性能非常差,多次replace的使用就已经进行了多次遍历,这里有个可以优化的点,对于单个字符做替换可以选择用replaceChars(str, searchChar, replaceChar)这个方案。
贪婪模式
懒惰模式
独占模式
简单算法实现
public static boolean like(final String dest, final String pattern)
int destPointer = 0, patternPointer = 0;
int destRecall = -1, patternRecall = -1;
final int patternLen = pattern.length();
final int destLen = dest.length();
while( destPointer < destLen)
......
......
while(patternPointer < patternLen && pattern.chatAt(patternPointer) == \'%\')
patternPointer++;
return patternPointer == patternLen;
有个场景我们不得不去考虑,那就是回溯的情况,举个例子:
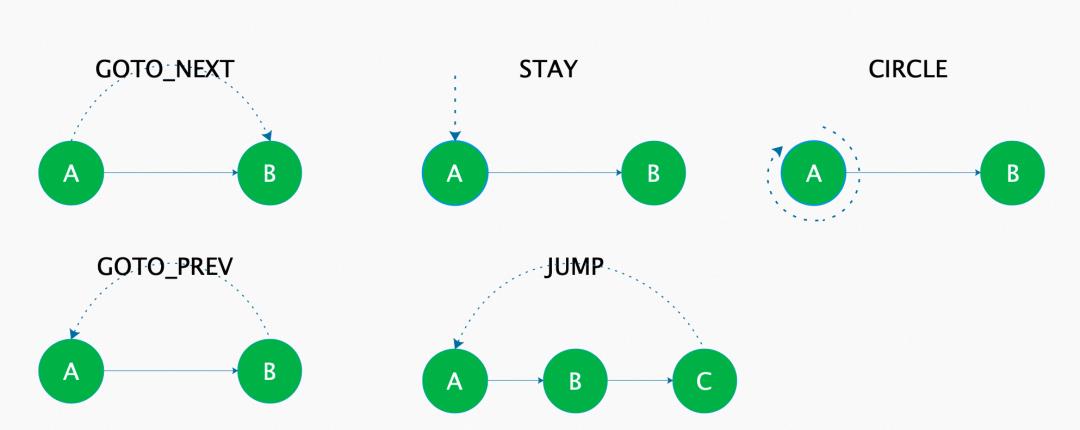
有限状态机实现
穷举法
查表法
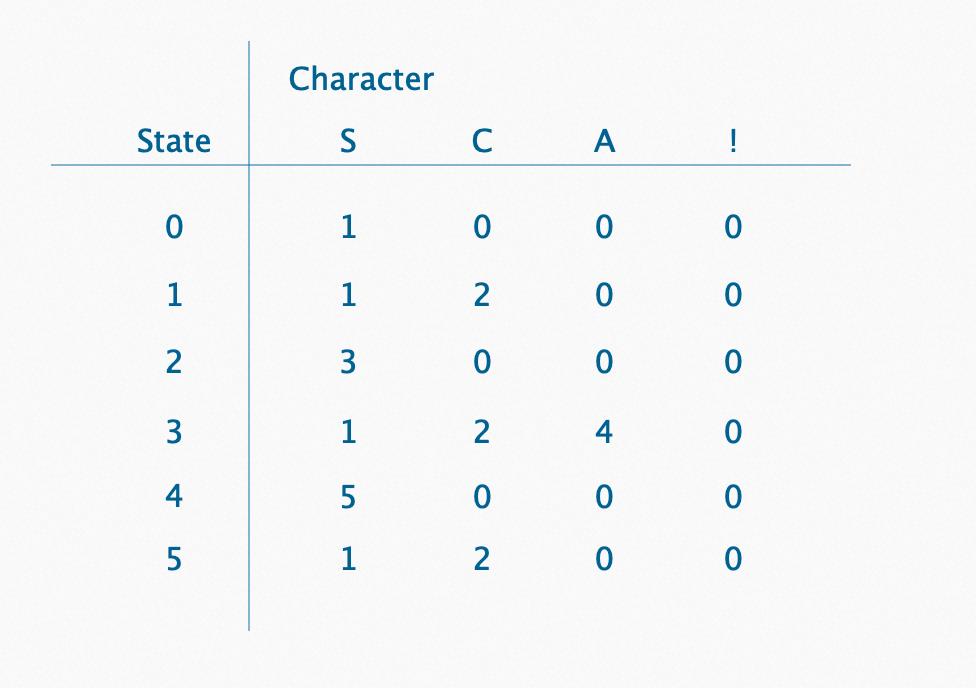

状态模式
public void compile(final String pattern)
...
LikeStateMachine machine = LikeStateMachine.build(pattern);
...
构建的过程就是我们把pattern解析加载的过程,我采用的方式是构建链表的方式。实现就是遍历构建的过程,compile时间复杂度O(n)



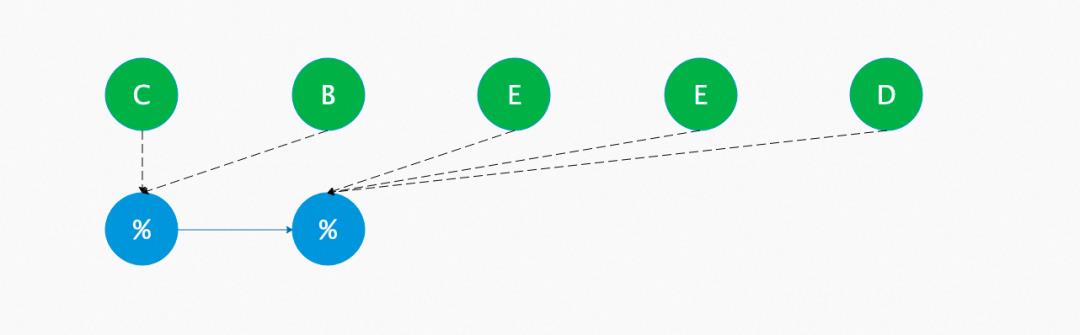
回溯场景优化


常用场景优化
public LikeParserResult compile(final String pattern)
return parseLikeExpress(pattern);
....
public boolean match(final String dest, LikeParserResult likeParserResult)
switch (likeParserResult.getMatchResult())
case LikeMatchResult.TYPE.ALLMATCH:
return true;
case LikeMatchResult.TYPE.EQUALS:
return doEquals(dest, likeParserResult.getFinalPattern());
case LikeMatchResult.TYPE.STARTSWITH:
return doStartsWith(dest, likeParserResult.getFinalPattern());
case LikeMatchResult.TYPE.ENDSWITH:
return doEndsWith(dest, likeParserResult.getFinalPattern());
case LikeMatchResult.TYPE.CONTAINS:
return doContain(dest, likeParserResult.getFinalPattern());
default:
//或者别的实现
return likeParserResult.getLikeStateMachine().match(dest);
上面给出的代码是为了清楚的看到里面运行,最终根据自己擅长的代码风格(函数式Function,接口等),还可以进一步优化和精简。
...
public LikeParserResult compile(final String pattern)
return parseLikeExpress(pattern);
public boolean match(final String dest, LikeParserResult likeParserResult)
return likeParserResult.getMatcher().match(dest);
...
public class StartsWithMatcher implements Matcher
...
@Override
public Boolean match(String dest)
return dest.startsWith(this.pattern);
...压测数据对比
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
最后
本文来自博客园,作者:古道轻风,转载请注明原文链接:https://www.cnblogs.com/88223100/p/How-to-efficiently-implement-SQL-like-syntax-in-JAVA.html
SQL Server参数化SQL语句中的like和in查询的语法(C#)
sql语句进行 like和in 参数化,按照正常的方式是无法实现的
//SqlParameter 会把where insert delete等字符原样的插入写入查询到sql语句中,而不会让这些关键字产生效果。。。。。。
我们一般的思维是:
Like参数化查询:
string sqlstmt = "select * from users where user_name like '%@word%' or mobile like '%@word%'";
SqlParameter[] Parameters=new SqlParameter[1];
Parameters[0] = new SqlParameter("@word", "123");
In参数化查询:
string sqlstmt = "select * from users where user_id in (@user_ids)";
SqlParameter[] Parameters = new SqlParameter[1];
Parameters[0] = new SqlParameter("@user_ids", "1001,1002,1006");
可是这样放在程序里面是无法执行的,即使不报错,也是搜索不出来结果的。
正确解法如下:
like 参数:
string sqlstmt = "select * from users where user_name like '%'+ @word + '%' or mobile like '%'+ @word + '%'";
SqlParameter[] Parameters=new SqlParameter[1];
Parameters[0] = new SqlParameter("@word", "123");
in 参数
string sqlstmt = "exec('select * from users where user_id in ('+@user_ids+')')";
string sqlstmt = $"select * from users where user_id in('string.Join("','",@user_ids)');//貌似这种写法也是可以的,
SqlParameter[] Parameters = new SqlParameter[1];
Parameters[0] = new SqlParameter("@user_ids", "1001,1002,1006");
原理解释:
SQL参数化查询,其实是可以在SQL的IDE(Microsoft SQL Server Management Studio)中测试的。
打开Microsoft SQL Server Management Studio,新建查询,在窗口中写入以下命令:
-- Like参数化查询命令
DECLARE @word VARCHAR(255);
SET @word='123';
SELECT * from users where user_name like '%'+@word+'%' or mobile like '%'+@word+'%';
这就是Like参数化查询的等效命令;
同理,以下是In参数话查询命令:
DECLARE @user_ids VARCHAR(255);
SET @user_ids='1001,1002,1006';
exec('select * from users where user_id in ('+@user_ids+')');以上是关于JAVA中如何高效的实现SQL的like语法?的主要内容,如果未能解决你的问题,请参考以下文章
SQL Server参数化SQL语句中的like和in查询的语法(C#)
SQL Server参数化SQL语句中的like和in查询的语法(C#)
SQL Server参数化SQL语句中的like和in查询的语法(C#)
mysql中Mysql模糊查询like效率,以及更高效的写法和sql优化方法