HugePage介绍实现分析配置和使用
Posted 规格严格-功夫到家-哈工大威海人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HugePage介绍实现分析配置和使用相关的知识,希望对你有一定的参考价值。
cgroup其他部分 IO + hugepage
cgroup还有其他一些限制特性,如io,pid,hugetlb等,这些用处不多,参见Cgroupv1。下面介绍下与系统性能相关的io和hugepage,cgroup的io介绍参考Cgroup - Linux的IO资源隔离
linux IO
linux io涉及到对文件(磁盘设备)的读写性能,对io的优化主要分为
- 磁盘相关参数调优
- 文件系统参数调优,一般为io调度器选择和调度器参数调优
- 文件系统挂载(mount)参数调优
使用如下命令查看当前系统支持的调度器
# dmesg | grep -i scheduler [ 1.343756] io scheduler noop registered [ 1.343759] io scheduler deadline registered (default) [ 1.343784] io scheduler cfq registered [ 1.343787] io scheduler mq-deadline registered [ 1.343789] io scheduler kyber registered
使用如下命令查看当前磁盘支持的调度器,方括号表示当前生效的调度器
# cat /sys/block/sda/queue/scheduler
noop [deadline] cfq
调度器的参数位于/sys/block/sda/queue/iosched/
Noop:该算法实现了最简单的FIFO队列,所有I/O请求大致按照先来后到的顺序进行操作,特别适用于固态硬盘
- 在IO调度器下方有更加智能的IO调度设备。如果您的Block Device Drivers是Raid,或者SAN,NAS等存储设备,这些设备会更好地组织IO请求,不用IO调度器去做额外的调度工作;
- 上层应用程序比IO调度器更懂底层设备。或者说上层应用程序到达IO调度器的IO请求已经是它经过精心优化的,那么IO调度器就不需要画蛇添足,只需要按序执行上层传达下来的IO请求即可。
- 对于一些非旋转磁头氏的存储设备,使用Noop的效果更好。因为对于旋转磁头式的磁盘来说,IO调度器的请求重组要花费一定的CPU时间,但是对于SSD磁盘来说,这些重组IO请求的CPU时间可以节省下来,因为SSD提供了更智能的请求调度算法,不需要内核去画蛇添足。这篇文章提及了SSD中使用Noop效果会更好。
CFQ:给所有进程分配等同的块设备使用的时间片,进程在时间片内,可以将产生的IO请求提交给块设备进行处理,时间片结束,进程的请求将排进它自己的队列,等待下次调度的时候进行处理,适用于通用服务器。
Deadline:保证每个IO请求在一定的时间内一定要被服务到,以此来避免某个请求饥饿,deadline在大多数多线程应用场景和数据库应用场景下表现的性能要优于cfq
可以通过直接修改/sys/block/sda/queue/scheduler文件来临时修改调度器类型,永久修改可以参考如下命令
grubby --grub --update-kernel=ALL --args="elevator=deadline"
在遇到系统读写过慢时,可以采用如下步骤进行定位。(注:该系统的模拟故障由dd if=/dev/zero of=loadfile bs=1M count=5000触发):
- 首先使用top命令查看当前io等待情况,如下可以看到当前io等待时间为84.7
Tasks: 77 total, 2 running, 75 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.7 us, 14.6 sy, 0.0 ni, 0.0 id, 84.7 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 1014908 total, 63716 free, 69912 used, 881280 buff/cache KiB Swap: 0 total, 0 free, 0 used. 779008 avail Mem
- 使用iostat查看具体磁盘使用情况(当前系统只有一块磁盘),主要关注以下几个值
util:采集周期内用于IO操作的时间比率,该值过高直接说明IO占比过高,下面util已经升到了97.19%,IO已经很高了
await:平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位),该值过高说明IO队列可能比较长,IO队列长度可以参考avgqu-sz(平均等待处理的IO请求队列长度)
svctm:平均每次IO请求的处理时间(毫秒为单位),正常情况下该值与await相差不大,差距越大,越说明IO过高。
IO有读写之分,如下例中明显写操作IO影响了性能,且设备为磁盘sda
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util sda 0.00 0.00 1.04 227.08 4.17 108850.00 954.34 124.40 1056.26 87.00 1060.71 4.26 97.19
-
- 使用iotop -P查看当前IO占用率最高的进程,可以看到是一个PID为15162的进程,其IO达到了80.05%
Total DISK READ : 0.00 B/s | Total DISK WRITE : 403.22 M/s Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 411.90 M/s PID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 15162 be/4 root 0.00 B/s 403.22 M/s 0.00 % 80.05 % dd if=/dev/zero... ...
使用lsof查看该进程打开的文件,可以看到/home/loadfile的大小达到了4564156416
# lsof -p 15394 lsof: WARNING: can‘t stat() fuse.gvfsd-fuse file system /run/user/1000/gvfs Output information may be incomplete. COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME dd 15394 root cwd DIR 253,0 63 50444361 /home dd 15394 root rtd DIR 253,0 238 64 / dd 15394 root txt REG 253,0 74952 50454589 /usr/bin/dd dd 15394 root mem REG 253,0 106075056 17088179 /usr/lib/locale/locale-archive dd 15394 root mem REG 253,0 2151672 162056 /usr/lib64/libc-2.17.so dd 15394 root mem REG 253,0 163400 162049 /usr/lib64/ld-2.17.so dd 15394 root 0r CHR 1,5 0t0 6479 /dev/zero dd 15394 root 1w REG 253,0 4564156416 52606435 /home/loadfile dd 15394 root 2u CHR 136,0 0t0 3 /dev/pts/0
确定/home/loadfile文件的挂载路径,为根路径
# df /home/ Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/centos-root 17811456 10109916 7701540 57% /
查看根路径挂载的磁盘(本例中为一块磁盘,可以忽略该步骤),为发生IO性能问题的磁盘sda,到此基本可以确认是因为进程15162引发了IO问题。注:可以使用如“time dd if=/dev/zero bs=1M count=2048 of=direct_2G”命令测试磁盘性能
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 20G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 19G 0 part ├─centos-root 253:0 0 17G 0 lvm / └─centos-swap 253:1 0 2G 0 lvm [SWAP]
linux 大页
Linux采用了通用的分页模型,用以减少进程使用的页表以及增加对内存的索引。在Linux-2.6.10版本中, Linux采用了三级分页模型. 而从2.6.11开始普遍采用了四级分页模型,32位系统中取消了PUD和PMD,为二级分页模型。注:每个进程都有其自身的页面目录PGD
- 页全局目录(Page Global Directory)
- 页上级目录(Page Upper Directory)
- 页中间目录(Page Middle Directory)
- 页表(Page Table)
下面是一个线性地址包含的个字段以及个字段的用途
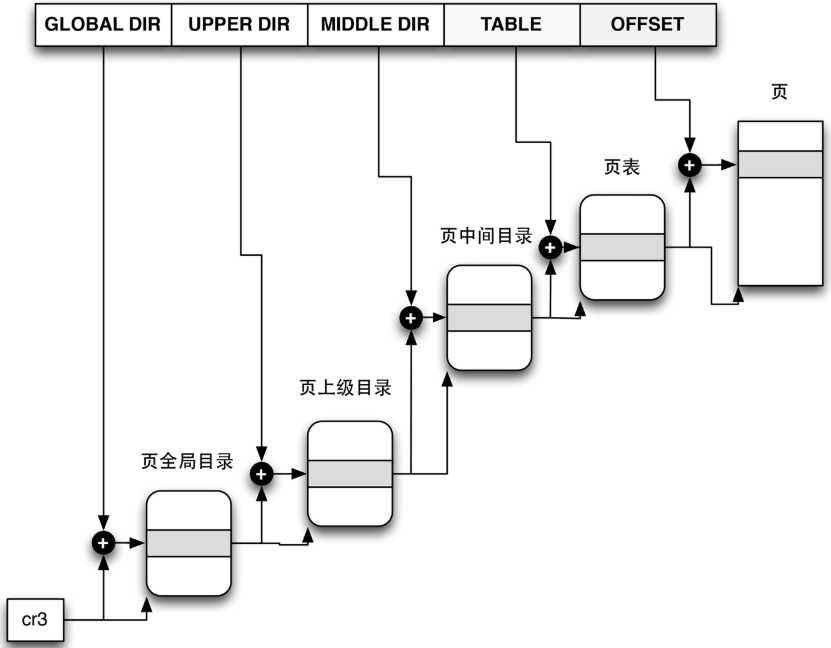
注:CR3中含有页目录表物理内存基地址,因此该寄存器也被称为页目录基地址寄存器PDBR(Page-Directory Base address Register),用于定位进程PGD
对于32位系统来说,如果采用4K的分页大小,每个PGD含1024个目录,每个目录含1024个PT,每个PT可寻址4K物理内存,总计4G。从上述可以看出,当进程需要访问实际物理内存时需要经过多级页才行,为了增加地址访问效率,linux使用了一种页缓存,TLB(translation lookaside buffer)。当需要访问物理地址时会首先从TLB中寻找,若找到则称为TLB hit,否则称为TLB miss。
这篇文章描述了使用系统默认4k分页下出现的性能问题,总结下来就是:64位系统下,一个进程访问的内存空间变大时,其PGD里面的页表项也会变大,如一个进程访问一个12G内存时,其页表需要24M,当300个进程同时需要访问这12G内存时,总的页表达到了7200MB,这么大的页表不仅占用大量内存空间,页增加了地址访问的负担(TLB miss也会大大增加)。解决办法是使用大页内存,通过增加单个分页大小,进而减少总体需要的分页的数目(同时也提升了TLB hit的几率)
可以看出,大页内存一般用于64位系统或32位系统启用了PAE(内存地址扩展)的情况。页表的使用情况可以参见/proc/meminfo中的PageTables字段
下面描述来自这里
典型地,内存管理器在 x86 系统上处理的内存页为 4 KB。实际的页大小是与体系结构相关的。对大部分用途来说,内存管理器以这样大小的页来管理内存是最有效的。不过,有一些应用程序要使用特别多的内存。大型数据库就是其中一个常见的例子。由于每个页都要由每个进程映射,必须创建页表条目来将虚拟地址映射到物理地址。如果您的一个进程要使用 4KB 的页来映射 1 GB 内存,这将用到 262,144 个页表条目来保持对那些页的追踪。如果每个页表条目消耗 8 个字节,那些每映射 1 GB 内存需要 2 MB 的开销。这本身就已经是非常可观的开销了,不过,如果有多个进程共享那些内存时,问题会变得更严重。在这种情况下,每个映射到同一块 1 GB 内存的进程将为页表条目付出自己 2 MB 的代价。如果有足够多的进程,内存在开销上的浪费可能会超过应用程序请求使用的内存数量。
解决这一问题的一个方法是使用更大的页。大部分新的处理器都支持至少一个小的和一个大的内存页大小。在 x86 上,大内存页的大小是 4 MB,或者,在物理地址扩展(PAE)打开的系统上是 2 MB。假定在前面的中使用页大小为 4 MB 的大内存页,同样 1 GB 内存只用 256 个页表条目就可以映射,而不需要 262,144 个。这样开销从 2 MB 变为 2,048 个字节。
大内存页的使用还可以通过减少 变换索引缓冲(translation lookaside buffer, TLB)的失败次数来提高性能。TLB 是一种页表的高速缓存,让那些在表中列出的页可以更快地进行虚拟地址到物理地址的转换。大内存页可以用更少的实际页来提供更多的内存,相当于较小的页大小,使用的大内存页越多,就有越多的内存可以通过 TLB 引用。
TIPS:
- 衡量IO资源的时候,一般使用两个单位,一个是数据读写的带宽,另一个是数据读写的IOPS。带宽就是以时间为单位的读写数据量,比如,100Mbyte/s。而IOPS是以时间为单位的读写次数。
- docker对io的的设置参数为--blkio-weight和--blkio-weight-device,一个是针对所有设备的,另一个是针对特定设备的,设置的都是相对比例,设置范围为0-1000
参考:
https://blog.csdn.net/gzh0222/article/details/8666657
https://www.ibm.com/developerworks/cn/linux/l-lo-io-scheduler-optimize-performance/index.html
https://zorro.gitbooks.io/poor-zorro-s-linux-book/content/linuxde-io-diao-du.html
http://bencane.com/2012/08/06/troubleshooting-high-io-wait-in-linux/
https://www.ibm.com/developerworks/cn/linux/l-memmod/index.html
https://www.ibm.com/developerworks/cn/linux/l-cn-hugetlb/
https://github.com/gatieme/LDD-LinuxDeviceDrivers/blob/master/study/kernel/02-memory/02-pagetable/01-develop/README.md
以上是关于HugePage介绍实现分析配置和使用的主要内容,如果未能解决你的问题,请参考以下文章