python爬虫笔记
Posted 隨风.NET
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫笔记相关的知识,希望对你有一定的参考价值。
1.抓取网页并保存到txt中.解决控制台乱码问题
#_*_coding:utf-8_*_
import urllib2
response = urllib2.urlopen(\'http://hws.m.taobao.com/cache/wdetail/5.0/?id=540698103032\')
cont = response.read()
file1 = open("./1.txt","w")
file1.write(cont)
file1.close()
print cont.decode("utf-8").encode("gbk")
2.操作json
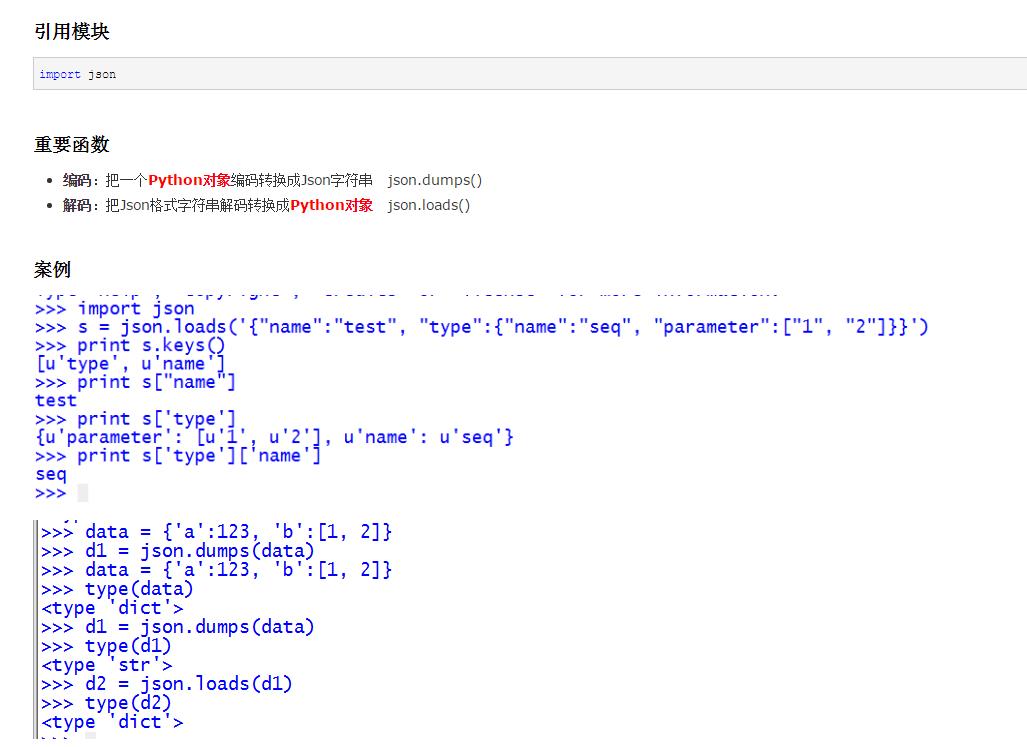
3.循环数组
https://www.cnblogs.com/Owen-ET/p/6932272.html
4.操作mssql
https://www.cnblogs.com/qianlifeng/archive/2012/02/06/2340367.html
https://www.cnblogs.com/lrzy/p/4346781.html
以上是关于python爬虫笔记的主要内容,如果未能解决你的问题,请参考以下文章