python下载百度贴吧的指定帖子的所有图片
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python下载百度贴吧的指定帖子的所有图片相关的知识,希望对你有一定的参考价值。
‘‘‘ Created on 2016年10月4日 @author: lee :下载百度贴吧的指定帖子的所有图片 ‘‘‘ import re import os import urllib.request def getHtml(url): res = urllib.request.urlopen(url) return res.read().decode(‘utf-8‘) def getMaxPage(home): """ :获取总共的页数 """ html = getHtml(home) #帖子的编号 id = home[home.rindex(‘/‘):] way = r‘max-page="([0-9]+)"‘ maxpage = re.findall(way,html) if len(maxpage) == 0: return 0 return maxpage[0] def getImg(way,html): res = re.findall(way, html) for i in res: if (i.startswith(‘http://imgsrc.baidu.com/‘)==False): res.remove(i) return res def download(list,path): """ :param list:the images‘s url :param path:the location to save images """ #创建文件夹 os.makedirs(path) i = 0 print (‘下载开始 共%d项‘%len(list)) for url in list: i+=1 urllib.request.urlretrieve(url,path+‘\\%s.jpg‘%i) print (‘第:%s个完成‘%i) print (‘全部完成‘) #*********************************************************# #帖子的主页 home = ‘http://tieba.baidu.com/p/4714184439‘ #保存的路径 path = ‘images‘ maxpage = getMaxPage(home) maxpage = int(maxpage) urls = [home] i = 1 while i<=maxpage: #取得每一页的url urls.append(home+‘?pn=%d‘%i) i+=1 way = r‘img.+src="(.+?\.jpg)" ‘ ls = [] for url in urls: #将每一页的图片链接都放到ls里面去 temp = getImg(way, getHtml(url)) ls.extend(temp) #去除ls里面的重复项 ls = list(set(ls)) download(ls,path)
完成效果:
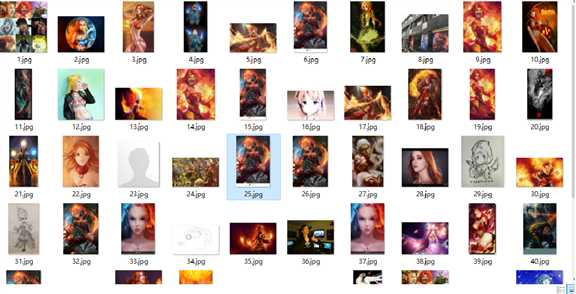
以上是关于python下载百度贴吧的指定帖子的所有图片的主要内容,如果未能解决你的问题,请参考以下文章