一次线上OOM问题的个人复盘
Posted 扣钉日记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一次线上OOM问题的个人复盘相关的知识,希望对你有一定的参考价值。
原创:扣钉日记(微信公众号ID:codelogs),欢迎分享,非公众号转载保留此声明。
上个月,我们一个java服务上线后,偶尔会发生内存OOM(Out Of Memory)问题,但由于OOM导致服务不响应请求,健康检查多次不通过,最后部署平台kill了java进程,这导致定位这次OOM问题也变得困难起来。
最终,在多次review代码后发现,是SQL意外地查出大量数据导致的,如下:
<sql id="conditions">
<where>
<if test="outerId != null">
and `outer_id` = #outerId
</if>
<if test="orderType != null and orderType != \'\'">
and `order_type` = #orderType
</if>
...
</where>
</sql>
<select id="queryListByConditions" resultMap="orderResultMap">
select * from order <include refid="conditions"/>
</select>
查询逻辑类似上面的示例,在Service层有个根据outer_id的查询方法,然后直接调用了Mapper层一个通用查询方法queryListByConditions。
但我们有个调用量极低的场景,可以不传outer_id这个参数,导致这个通用查询方法没有添加这个过滤条件,导致查了全表,进而导致OOM问题。
我们内部对这个问题进行了复盘,考虑到OOM问题还是蛮常见的,所以给大家也分享下。
事前
在OOM问题发生前,为什么测试阶段没有发现问题?
其实在编写技术方案时,是有考虑到这个场景的,但在提测时,忘记和测试同学沟通此场景,导致遗漏了此场景的测试验证。
关于测试用例不全面,其实不管是疏忽问题、经验问题、质量意识问题或人手紧张问题,从人的角度来说,都很难彻底避免,人没法像机器那样很听话的、不疏漏的执行任何指令。
既然人做不到,那就让机器来做,这就是单元测试、自动化测试的优势,通过逐步积累测试用例,可覆盖的场景就会越来越多。
当然,实施单元测试等方案,也会增加不少成本,需要权衡质量与研发效率谁更重要,毕竟在需求不能砍的情况下,质量与效率只能二选其一,这是任何一本项目管理的书都提到过的。
事中
在感知到OOM问题发生时,由于进程被部署平台kill,导致现场丢失,难以快速定位到问题点。
一般java里面是推荐使用-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/dump/这种JVM参数来保存现场的,这两个参数的意思是,当JVM发生OOM异常时,自动dump堆内存到文件中,但在我们的场景中,这个方案难以生效,如下:
- 在堆占满之前,会发生很多次FGC,jvm会尽最大努力腾挪空间,导致还没有OOM时,系统实际已经不响应了,然后被kill了,这种场景无dump文件生成。
- 就算有时幸运,JVM发生了OOM异常开始dump,由于dump文件过大(我们约10G),导致dump文件还没保存完,进程就被kill了,这种场景dump文件不完整,无法使用。
为了解决这个问题,有如下2种方案:
方案1:利用k8s容器生命周期内的Hook
我们部署平台是套壳k8s的,k8s提供了preStop生命周期钩子,在容器销毁前会先执行此钩子,只要将jmap -dump命令放入preStop中,就可以在k8s健康检查不通过并kill容器前将内存dump出来。
要注意的是,正常发布也会调用此钩子,需要想办法绕过,我们的办法是将健康检查也做成脚本,当不通过时创建一个临时文件,然后在preStop脚本中判断存在此文件才dump,preStop脚本如下:
if [ -f "/tmp/health_check_failed" ]; then
echo "Health check failed, perform dumping and cleanups...";
pid=`ps h -o pid --sort=-pmem -C java|head -n1|xargs`;
if [[ $pid ]]; then
jmap -dump:format=b,file=/home/work/logs/applogs/heap.hprof $pid
fi
else
echo "No health check failure detected. Exiting gracefully.";
fi
注:也可以考虑在堆占用高时才dump内存,效果应该差不多。
方案2:容器中挂脚本监控堆占用,占用高时自动dump
#!/bin/bash
while sleep 1; do
now_time=$(date +%F_%H-%M-%S)
pid=`ps h -o pid --sort=-pmem -C java|head -n1|xargs`;
[[ ! $pid ]] && unset n pre_fgc; sleep 1m; continue;
data=$(jstat -gcutil $pid|awk \'NR>1print $4,$(NF-2)\');
read old fgc <<<"$data";
echo "$now_time: $old $fgc";
if [[ $(echo $old|awk \'$1>80print $0\') ]]; then
(( n++ ))
else
(( n=0 ))
fi
if [[ $n -ge 3 || $pre_fgc && $fgc -gt $pre_fgc && $n -ge 1 ]]; then
jstack $pid > /home/dump/jstack-$now_time.log;
if [[ "$@" =~ dump ]];then
jmap -dump:format=b,file=/home/dump/heap-$now_time.hprof $pid;
else
jmap -histo $pid > /home/dump/histo-$now_time.log;
fi
unset n pre_fgc; sleep 1m; continue;
fi
pre_fgc=$fgc
done
每秒检查老年代占用,3次超过80%或发生一次FGC后还超过80%,记录jstack、jmap数据,此脚本保存为jvm_old_mon.sh文件。
然后在程序启动脚本中加入nohup bash jvm_old_mon.sh dump &即可,添加dump参数时会执行jmap -dump导全部堆数据,不添加时执行jmap -histo导对象分布情况。
事后
为了避免同类OOM case再次发生,可以对查询进行兜底,在底层对查询SQL改写,当发现查询没有limit时,自动添加limit xxx,避免查询大量数据。
优点:对数据库友好,查询数据量少。
缺点:添加limit后可能会导致查询漏数据,或使得本来会OOM异常的程序,添加limit后正常返回,并执行了后面意外的处理。
我们使用了Druid连接池,使用Druid Filter实现的话,大致如下:
public class SqlLimitFilter extends FilterAdapter
// 匹配limit 100或limit 100,100
private static final Pattern HAS_LIMIT_PAT = Pattern.compile(
"LIMIT\\\\s+[\\\\d?]+(\\\\s*,\\\\s*[\\\\d+?])?\\\\s*$", Pattern.CASE_INSENSITIVE);
private static final int MAX_ALLOW_ROWS = 20000;
/**
* 若查询语句没有limit,自动加limit
* @return 新sql
*/
private String rewriteSql(String sql)
String trimSql = StringUtils.stripToEmpty(sql);
// 不是查询sql,不重写
if (!StringUtils.lowerCase(trimSql).startsWith("select"))
return sql;
// 去掉尾部分号
boolean hasSemicolon = false;
if (trimSql.endsWith(";"))
hasSemicolon = true;
trimSql = trimSql.substring(0, trimSql.length() - 1);
// 还包含分号,说明是多条sql,不重写
if (trimSql.contains(";"))
return sql;
// 有limit语句,不重写
int idx = StringUtils.lowerCase(trimSql).indexOf("limit");
if (idx > -1 && HAS_LIMIT_PAT.matcher(trimSql.substring(idx)).find())
return sql;
StringBuilder sqlSb = new StringBuilder();
sqlSb.append(trimSql).append(" LIMIT ").append(MAX_ALLOW_ROWS);
if (hasSemicolon)
sqlSb.append(";");
return sqlSb.toString();
@Override
public PreparedStatementProxy connection_prepareStatement(FilterChain chain, ConnectionProxy connection, String sql)
throws SQLException
String newSql = rewriteSql(sql);
return super.connection_prepareStatement(chain, connection, newSql);
//...此处省略了其它重载方法
本来还想过一种方案,使用MySQL的流式查询并拦截jdbc层ResultSet.next()方法,在此方法调用超过指定次数时抛异常,但最终发现MySQL驱动在ResultSet.close()方法调用时,还是会读取剩余未读数据,查询没法提前终止,故放弃之。
一次线上数据库连接池故障复盘
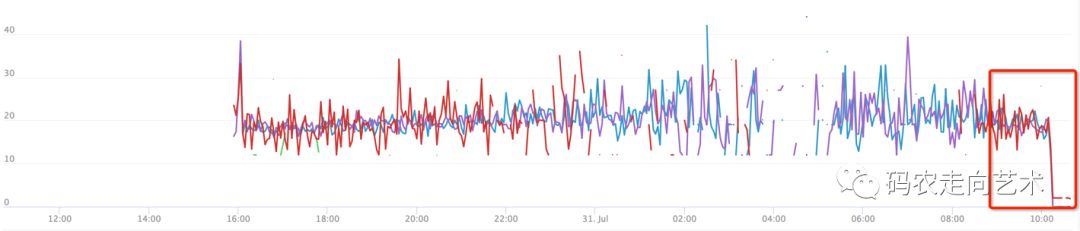
用户反馈系统不可用,立即检查监控大盘和系统日志,发现系统有毛刺,因为在服务不可用的情况下,用户多次请求,导致请求量剧增:
同时系统向下游系统的请求报文量骤降:
查看日志文件,发现dbcp连接池异常关闭:
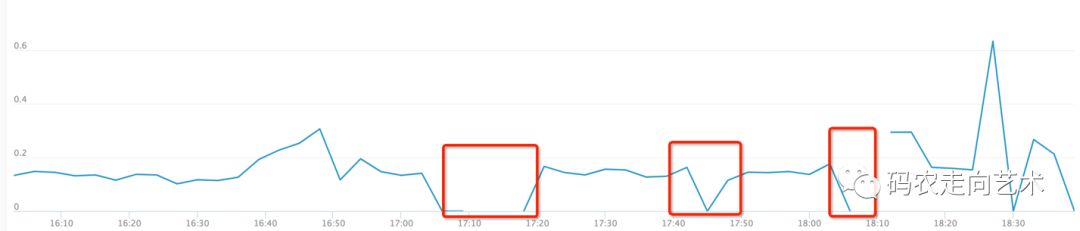
于是立即重启了进程,服务恢复正常。但过了20分钟左右,相同的问题再次发生,如下图所示,每隔一段时间,对外请求量消失:
此时,通过jstack –F 进程号>>stack.log生成stack快照,发现有很多WAITING的线程。
这个异常事实上跟日志文件中dbcp连接关闭是一个意思,但还未定位dbcp异常关闭的原因。通过IBM的jca工具打开stackdump文件。检查线程状态,发现runnable的几个线程都是同一个类的线程,都在调用一个外部依赖接口:
检查了一下该接口,发现该接口处于不可用状态,而calling该接口的方法启用了事务控制,使用spring的transactional注解中未添加超时时间,默认超时时间是-1,也就是最长时间;同时方法块中的resttemplate也未配置超时时间,所以当该接口超时异常时,事务一直处于挂起状态,导致事务超时,连接被关闭,运行一段时间dbcp连接全部被数据库端关闭,从而导致数据源关闭,整个进程被挂起。
经验总结:
1. 事故原因是启用数据库事务时,由于超时导致数据库连接被动关闭,触发dbcp关闭连接池,进程处于hang状态,所有请求不再处理。
2. 线上故障时,先记录现场log,例如jstack,heap,memory。
3. 然后再重启机器。
4. 重启后要持续观察一段时间,确保故障消失。
5. stack日志中有很多waiting线程,这些状态常常是表象,要重点检查runnable的线程。
6. 代码中,事务控制部分必须设置超时时间,要么及时提交,要么超时或异常回滚;事务控制的代码尽可能精简,只控制数据库访问部分。Spring的resttemplate用之前配置超时时间,连接数等关键参数。
推荐!推荐!推荐! 获取每天更新的码农场原创内容
码农走向艺术
以上是关于一次线上OOM问题的个人复盘的主要内容,如果未能解决你的问题,请参考以下文章