初学python3-爬取cnnvd漏洞信息
Posted 默不知然
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初学python3-爬取cnnvd漏洞信息相关的知识,希望对你有一定的参考价值。
因为工作需要cnnvd漏洞信息,以前用着集客搜、八爪鱼之类的工具,但对其效果和速度都不满意。最近开始接触学习爬虫,作为初学者,还需要慢慢完善。先记录下第一个爬虫。还想着在多进程和IP代理方向改善学习。
这个是运行情况,速度还是无法忍受,多进程在数据获取应该能快很多,IP代理应该能忽视短时间多次访问被限制的问题,从而可以提高速度。
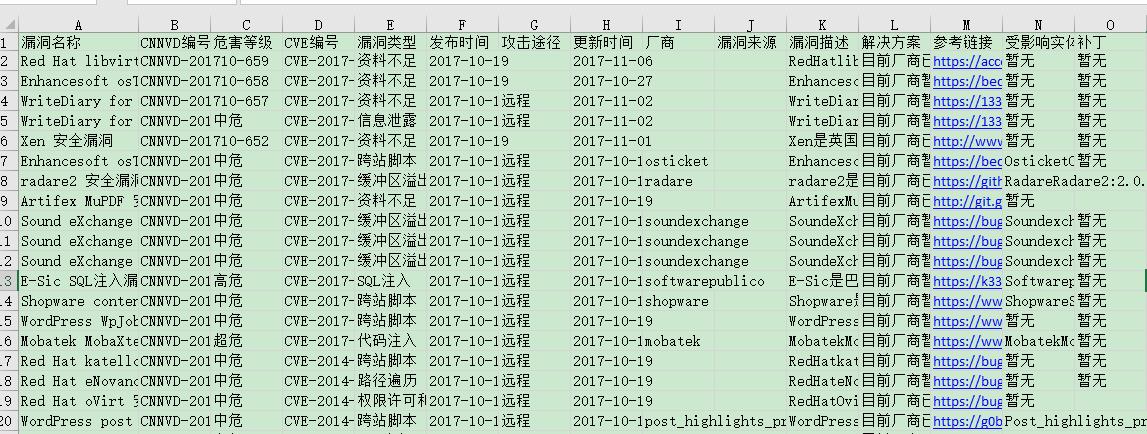
输出 excel 如图:
以下是整个代码:
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # by 默不知然 import urllib.request from urllib import parse from bs4 import BeautifulSoup import http.cookiejar import xlwt import zlib import re import time import xlsxwriter import sys import datetime import pymysql \'\'\' 运行方法: python vulnerabilities_crawler 2017-10-01 2017-10-31 178 第一个为开始时间,第二个为结束时间,第三个为总页数。 \'\'\' #获得漏洞详情链接列表 def vulnerabilities_url_list(url,start_time,end_time): header = { \'User-Agent\': \'Mozilla/5.0 (Linux; Android 4.1.2; Nexus 7 Build/JZ054K) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19\', \'Accept-Encoding\': \'gzip, deflate\', \'Referer\': \'http://cnnvd.org.cn/web/vulnerability/queryLds.tag\' } data = { \'qstartdate\':\'2017-10-30\', #---------------》开始日期 \'qenddate\':\'2017-10-31\' #---------------》结束日期 } data[\'qstartdate\'] = start_time data[\'qenddate\'] = end_time data = parse.urlencode(data).encode(\'utf-8\') vulnerabilities_url_html = urllib.request.Request(url,headers=header,data=data) vulnerabilities_url_cookie = http.cookiejar.CookieJar() vulnerabilities_url_opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(vulnerabilities_url_cookie)) vulnerabilities_url_html = vulnerabilities_url_opener.open(vulnerabilities_url_html) vulnerabilities_url_html = zlib.decompress(vulnerabilities_url_html.read(), 16+zlib.MAX_WBITS) vulnerabilities_url_html = vulnerabilities_url_html.decode() #提取漏洞详情链接 response = r\'href="(.+?)" target="_blank" class="a_title2"\' vulnerabilities_link_list = re.compile(response).findall(vulnerabilities_url_html) #添加http前序 i = 0 for link in vulnerabilities_link_list: vulnerabilities_lists.append(\'http://cnnvd.org.cn\'+vulnerabilities_link_list[i]) i+=1 print("已完成爬行第%d个漏洞链接"%i) time.sleep(0.2) #漏洞信息爬取函数 def vulnerabilities_data(url): header = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0\', \'Accept-Encoding\': \'gzip, deflate, sdch\', } vulnerabilities_data_html = urllib.request.Request(url,headers=header) vulnerabilities_data_cookie = http.cookiejar.CookieJar() vulnerabilities_data_opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(vulnerabilities_data_cookie)) vulnerabilities_data_html = vulnerabilities_data_opener.open(vulnerabilities_data_html) vulnerabilities_data_html = zlib.decompress(vulnerabilities_data_html.read(), 16+zlib.MAX_WBITS) vulnerabilities_data_html = vulnerabilities_data_html.decode() global vulnerabilities_result_list vulnerabilities_result_list=[] #抓取信息列表命名 #添加漏洞信息详情 vulnerabilities_detainled_soup1 = BeautifulSoup(vulnerabilities_data_html,\'html.parser\') vulnerabilities_detainled_data = vulnerabilities_detainled_soup1.find(\'div\',attrs={\'class\':\'detail_xq w770\'}) ##定义 漏洞信息详情 块的soup vulnerabilities_detainled_data = vulnerabilities_detainled_data.decode() vulnerabilities_detainled_soup = BeautifulSoup(vulnerabilities_detainled_data,\'html.parser\') #二次匹配 vulnerabilities_detainled_data_list = vulnerabilities_detainled_soup.find_all(\'li\') #标签a信息汇总 try: vulnerabilities_name = vulnerabilities_detainled_soup.h2.string #漏洞名称 except: vulnerabilities_name = \'\' vulnerabilities_result_list.append(vulnerabilities_name) try: vulnerabilities_cnnvd_num = vulnerabilities_detainled_soup.span.string #cnnvd编号 vulnerabilities_cnnvd_num = re.findall(r"\\:([\\s\\S]*)",vulnerabilities_cnnvd_num)[0] except: vulnerabilities_cnnvd_num = \'\' vulnerabilities_result_list.append(vulnerabilities_cnnvd_num) try: #漏洞等级 vulnerabilities_rank = vulnerabilities_detainled_soup.a.decode() vulnerabilities_rank = re.search(u\'([\\u4e00-\\u9fa5]+)\',vulnerabilities_rank).group(0) except: vulnerabilities_rank = \'\' vulnerabilities_result_list.append(vulnerabilities_rank) vulnerabilities_cve_html = vulnerabilities_detainled_data_list[2].decode() #漏洞cve编号 vulnerabilities_cve_soup = BeautifulSoup(vulnerabilities_cve_html,\'html.parser\') try: vulnerabilities_cve = vulnerabilities_cve_soup.a.string vulnerabilities_cve = vulnerabilities_cve.replace("\\r","").replace("\\t","").replace("\\n","").replace(" ","") except: vulnerabilities_cve = \'\' vulnerabilities_result_list.append(vulnerabilities_cve) vulnerabilities_type_html = vulnerabilities_detainled_data_list[3].decode() #漏洞类型 vulnerabilities_type_soup = BeautifulSoup(vulnerabilities_type_html,\'html.parser\') try: vulnerabilities_type = vulnerabilities_type_soup.a.string vulnerabilities_type = vulnerabilities_type.replace("\\r","").replace("\\t","").replace("\\n","").replace(" ","") except: vulnerabilities_type = \'\' vulnerabilities_result_list.append(vulnerabilities_type) vulnerabilities_time_html = vulnerabilities_detainled_data_list[4].decode() #发布时间 vulnerabilities_time_soup = BeautifulSoup(vulnerabilities_time_html,\'html.parser\') try: vulnerabilities_time = vulnerabilities_time_soup.a.string vulnerabilities_time = vulnerabilities_time.replace("\\r","").replace("\\t","").replace("\\n","") except: vulnerabilities_time = \'\' vulnerabilities_result_list.append(vulnerabilities_time) vulnerabilities_attack_html = vulnerabilities_detainled_data_list[5].decode() #威胁类型 vulnerabilities_attack_soup = BeautifulSoup(vulnerabilities_attack_html,\'html.parser\') try: vulnerabilities_attack = vulnerabilities_attack_soup.a.string vulnerabilities_attack = vulnerabilities_attack.replace("\\r","").replace("\\t","").replace("\\n","") except: vulnerabilities_attack = \'\' vulnerabilities_result_list.append(vulnerabilities_attack) vulnerabilities_update_html = vulnerabilities_detainled_data_list[6].decode() #更新时间 vulnerabilities_update_soup = BeautifulSoup(vulnerabilities_update_html,\'html.parser\') try: vulnerabilities_update = vulnerabilities_update_soup.a.string vulnerabilities_update = vulnerabilities_update.replace("\\r","").replace("\\t","").replace("\\n","") except: vulnerabilities_update = \'\' vulnerabilities_result_list.append(vulnerabilities_update) vulnerabilities_firm_html = vulnerabilities_detainled_data_list[7].decode() #厂商 vulnerabilities_firm_soup = BeautifulSoup(vulnerabilities_firm_html,\'html.parser\') try: vulnerabilities_firm = vulnerabilities_firm_soup.a.string vulnerabilities_firm = vulnerabilities_firm.replace("\\r","").replace("\\t","").replace("\\n","") except: vulnerabilities_firm = \'\' vulnerabilities_result_list.append(vulnerabilities_firm) vulnerabilities_source_html = vulnerabilities_detainled_data_list[8].decode() #漏洞来源 vulnerabilities_source_soup = BeautifulSoup(vulnerabilities_source_html,\'html.parser\') try: vulnerabilities_source = vulnerabilities_source_soup.a.string vulnerabilities_source = vulnerabilities_source.replace("\\r","").replace("\\t","").replace("\\n","") except: vulnerabilities_source = \'\' vulnerabilities_result_list.append(vulnerabilities_source) #添加漏洞简介详情 vulnerabilities_title_html = vulnerabilities_detainled_soup1.find(\'div\',attrs={\'class\':\'d_ldjj\'}) #定义 漏洞简介 块的soup vulnerabilities_title_html = vulnerabilities_title_html.decode() vulnerabilities_title_soup2 = BeautifulSoup(vulnerabilities_title_html,\'html.parser\') try: vulnerabilities_titles1 = vulnerabilities_title_soup2.find_all(name=\'p\')[0].string vulnerabilities_titles2 = vulnerabilities_title_soup2.find_all(name=\'p\')[1].string vulnerabilities_titles = vulnerabilities_titles1 + vulnerabilities_titles2 vulnerabilities_titles = vulnerabilities_titles.replace(\' \',\'\').replace(\'\\t\',\'\').replace(\'\\r\',\'\').replace(\'\\n\',\'\') except: vulnerabilities_titles = \'\' vulnerabilities_result_list.append(vulnerabilities_titles) #漏洞公告 vulnerabilities_notice_html = vulnerabilities_detainled_soup1.find(\'div\',attrs={\'class\':\'d_ldjj m_t_20\'}) #定义 漏洞公告 块的soup vulnerabilities_notice_html = vulnerabilities_notice_html.decode() vulnerabilities_notice_soup2 = BeautifulSoup(vulnerabilities_notice_html,\'html.parser\') try: vulnerabilities_notice1 = vulnerabilities_notice_soup2.find_all(name=\'p\')[0].string vulnerabilities_notice2 = vulnerabilities_notice_soup2.find_all(name=\'p\')[1].string vulnerabilities_notice = vulnerabilities_notice1+vulnerabilities_notice2 vulnerabilities_notice = vulnerabilities_notice.replace(\'\\n\',\'\').replace(\'\\r\',\'\').replace(\'\\t\',\'\') except: vulnerabilities_notice = \'\' vulnerabilities_result_list.append(vulnerabilities_notice) #参考网址 vulnerabilities_reference_html = vulnerabilities_detainled_soup1.find_all(\'div\',attrs={\'class\':\'d_ldjj m_t_20\'})[1] #定义 参考网址 块的soup vulnerabilities_reference_html = vulnerabilities_reference_html.decode() vulnerabilities_reference_soup2 = BeautifulSoup(vulnerabilities_reference_html,\'html.parser\') try: vulnerabilities_reference = vulnerabilities_reference_soup2.find_all(name=\'p\')[1].string vulnerabilities_reference = vulnerabilities_reference.replace(\'\\n\',\'\').replace(\'\\r\',\'\').replace(\'\\t\',\'\').replace(\'链接:\',\'\') except: vulnerabilities_reference = \'\' vulnerabilities_result_list.append(vulnerabilities_reference) #受影响实体 vulnerabilities_effect_html = vulnerabilities_detainled_soup1.find_all(\'div\',attrs={\'class\':\'d_ldjj m_t_20\'})[2] #定义 受影响实体 块的soup vulnerabilities_effect_html = vulnerabilities_effect_html.decode() vulnerabilities_effect_soup2 = BeautifulSoup(vulnerabilities_effect_html,\'html.parser\') try: vulnerabilities_effect = vulnerabilities_effect_soup2.find_all(name=\'p\')[0].string vulnerabilities_effect = vulnerabilities_effect.replace(\'\\n\',\'\').replace(\'\\r\',\'\').replace(\'\\t\',\'\').replace(\' \',\'\') except: try: vulnerabilities_effect = vulnerabilities_effect_soup2.find_all(name=\'a\')[0].string vulnerabilities_effect = vulnerabilities_effect.replace(\'\\n\',\'\').replace(\'\\r\',\'\').replace(\'\\t\',\'\').replace(\' \',\'\') except: vulnerabilities_effect = \'\' vulnerabilities_result_list.append(vulnerabilities_effect) #补丁 vulnerabilities_patch_html = vulnerabilities_detainled_soup1.find_all(\'div\',attrs={\'class\':\'d_ldjj m_t_20\'})[3] #定义 补丁 块的soup vulnerabilities_patch_html = vulnerabilities_patch_html.decode() vulnerabilities_patch_soup2 = BeautifulSoup(vulnerabilities_patch_html,\'html.parser\') try: vulnerabilities_patch = vulnerabilities_patch_soup2.find_all(name=\'p\')[0].string vulnerabilities_patch = vulnerabilities_patch.replace(\'\\n\',\'\').replace(\'\\r\',\'\').replace(\'\\t\',\'\').replace(\' \',\'\') except: vulnerabilities_patch = \'\' vulnerabilities_result_list.append(vulnerabilities_patch) #漏洞信息写入excel def vulnerabilities_excel(excel): workbook = xlsxwriter.Workbook(\'vulnerabilities_data.xlsx\') worksheet = workbook.add_worksheet() row = 0 col = 0 worksheet.write(row,0,\'漏洞名称\') worksheet.write(row,1,\'CNNVD编号\') worksheet.write(row,2,\'危害等级\') worksheet.write(row,3,\'CVE编号\') worksheet.write(row,4,\'漏洞类型\') worksheet.write(row,5,\'发布时间\') worksheet.write(row,6,\'攻击途径\') worksheet.write(row,7,\'更新时间\') worksheet.write(row,8,\'厂商\') worksheet.write(row,9,\'漏洞来源\') worksheet.write(row,10,\'漏洞描述\') worksheet.write(row,11,\'解决方案\') worksheet.write(row,12,\'参考链接\') worksheet.write(row,13,\'受影响实体\') worksheet.write(row,14,\'补丁\') row = 1 for i in range(len(excel)): worksheet.write(row,col,excel[i][0]) worksheet.write(row,col+1,excel[i][1]) worksheet.write(row,col+2,excel[i][2]) worksheet.write(row,col+3,excel[i][3]) worksheet.write(row,col+4,excel[i][4]) worksheet.write(row,col+5,excel[i][5]) worksheet.write(row,col+6,excel[i][6]) worksheet.write(row,col+7,excel[i][7]) worksheet.write(row,col+8,excel[i][8]) worksheet.write(row,col+9,excel[i][9]) worksheet.write(row,col+10,excel[i][10]) worksheet.write(row,col+11,excel[i][11]) worksheet.write(row,col+12,excel[i][12]) worksheet.write(row,col+13,excel[i][13]) worksheet.write(row,col+14,excel[i][14]) row += 1 workbook.close() #漏洞信息写入数据库 def vulnerabilities_mysql(excel): db = pymysql.connect(\'127.0.0.1\',\'root\',\'xxxx\',\'spider\',charset=\'utf8\') cursor = db.cursor() for i in range(len(excel)): sql="INSERT INTO cnnvd(vulnerabilities_name,cnnvd_num,vulnerabilities_rank,cve_num,vulnerabilities_type,release_time,attack_path,update_time,company,vulnerabilities_source,vulnerabilities_data,solution,reference,object,path) VALUES(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s);" try: cursor.execute(sql,(excel[i][0],excel[i][1],excel[i][2],excel[i][3],excel[i][4],excel[i][5],excel[i][6],excel[i][7],excel[i][8],excel[i][9],excel[i][10],excel[i][11],excel[i][12],excel[i][13],excel[i][14])) except: print(\'写入数据库失败\') print(\'写入数据库完毕!!!\') db.commit() db.close() #爬取代理ip def main(): #调用漏洞列表函数并获得漏洞链接列表 begin = datetime.datetime.now() global vulnerabilities_lists vulnerabilities_lists=[] j = 1 page_count = sys.argv[3] page_count = int(page_count) start_time = sys.argv[1] end_time = sys.argv[2] while j<=page_count: try: vulnerabilities_url = \'http://cnnvd.org.cn/web/vulnerability/queryLds.tag?pageno=%d&repairLd=\'%j vulnerabilities_url_list(vulnerabilities_url,start_time,end_time) print("已完成爬行第%d页"%j) print(\'\\n\') time.sleep(2) j+=1 except: print(\'爬取失败,等待5秒后重新爬取。\') time.sleep(5) #调用漏洞信息函数并爬取漏洞信息 vulnerabilities_result_lists = [] a=0 while a < len(vulnerabilities_lists): try: vulnerabilities_data(vulnerabilities_lists[a]) vulnerabilities_result_lists.append(vulnerabilities_result_list) a+=1 print("完成爬行第%d个漏洞信息"%a) time.sleep(1) except: print(\'爬取失败,等待5秒后重新爬取。\') time.sleep(5) #漏洞信息写入excel vulnerabilities_excel(vulnerabilities_result_lists) #漏洞信息写入MySQL #vulnerabilities_mysql(vulnerabilities_result_lists) #爬行结束 end = datetime.datetime.now() total_time = end - begin print (\'漏洞信息爬取结束\') print (\'应该爬行漏洞数量: \',len(vulnerabilities_lists)) print (\'爬行时间: \',total_time) if __name__ == \'__main__\': main()
以上是关于初学python3-爬取cnnvd漏洞信息的主要内容,如果未能解决你的问题,请参考以下文章