Python day02心得
Posted ︻◣_蝸犇り~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python day02心得相关的知识,希望对你有一定的参考价值。
模块初识
os:所有跟系统有关的操作基本都是用此模块
os.system("df -h") 调用系统命令,结果输出打印在屏幕上,返回值为执行结果(0或1)
os.mknod(file_name) 创建空文件
os.mkdir(dir_name) 创建文件夹
os.path.exists(path) 判断path是否存在,返回True/False
os.path.isfile(path) 判断path是否是一个存在的文件,返回True/False
os.path.isdir(path) 判断path是否是一个存在的文件,返回True/False
sys.argv 脚本执行的参数 ,列表形式
$ python test.py helo world[\'test.py\', \'helo\', \'world\'] #把执行脚本时传递的参数获取到了深浅copy说明
import copy
person = ["name",["saving",100]]
浅copy
1. p1 = copy.copy(name)
2. p2 = person[:]
3. p3 = list(person)
深copy
p4 = copy.deepcopy(person)
例子:
>>> import copy
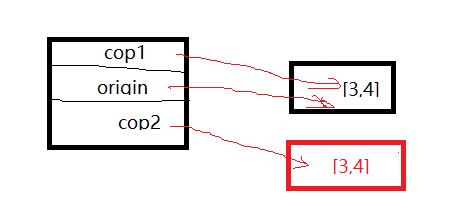
>>> origin = [1, 2, [3, 4]]
#origin 里边有三个元素:1, 2,[3, 4]
>>> cop1 = copy.copy(origin)
>>> cop2 = copy.deepcopy(origin)
>>> cop1 == cop2
True
>>> cop1 is cop2
False
#cop1 和 cop2 看上去相同,但已不再是同一个object
>>> origin[2][0] = "hey!"
>>> origin
[1, 2, [\'hey!\', 4]]
>>> cop1
[1, 2, [\'hey!\', 4]]
>>> cop2
[1, 2, [3, 4]]
#把origin内的子list [3, 4] 改掉了一个元素,观察 cop1 和 cop2
pyc解释
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
Python是一门先编译后解释的语言,PyCodeObject是Python编译器真正编译成的结果。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
数据类型
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,数学中表示复数是什么?。
int(整型)
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)(有理数)
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
"hello world"
字符串拼接
方法1:直接通过加号(+)操作符连接,但效率太低,每出现一次+号会在内存中重新开辟一块空间
website = \'python\' + \'tab\' + \'.com
方法2:join方法,效率高
listStr = [\'python\', \'tab\', \'.com\']
website = \'\'.join(listStr)
方法3:替换,常用方法
website = \'%s%s%s\' % (\'python\', \'tab\', \'.com\')
位运算

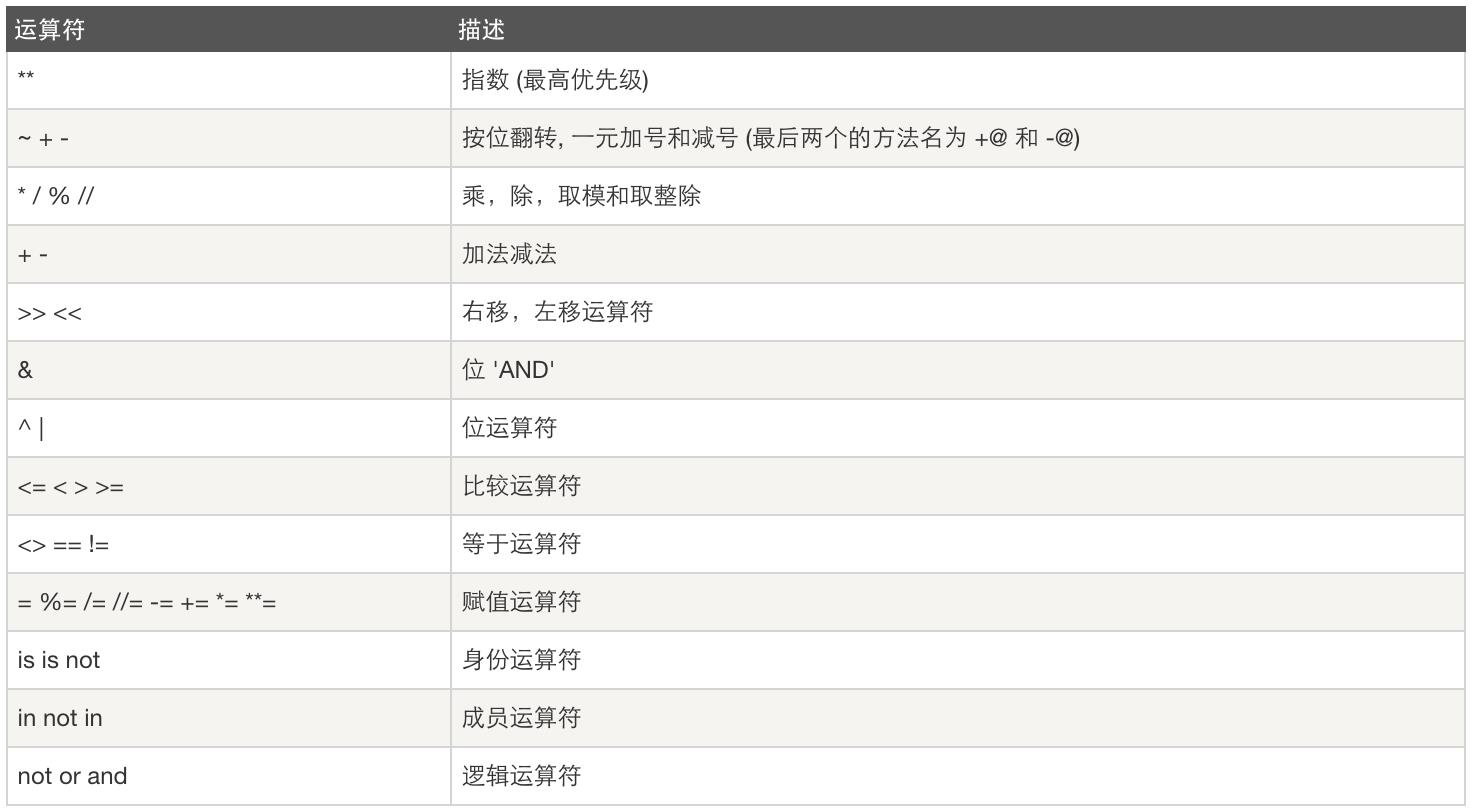
#!/usr/bin/python a = 60 # 60 = 0011 1100b = 13 # 13 = 0000 1101c = 0 c = a & b; # 12 = 0000 1100print "Line 1 - Value of c is ", c c = a | b; # 61 = 0011 1101print "Line 2 - Value of c is ", c c = a ^ b; # 49 = 0011 0001 #相同为0,不同为1print "Line 3 - Value of c is ", c c = ~a; # -61 = 1100 0011print "Line 4 - Value of c is ", c c = a << 2; # 240 = 1111 0000print "Line 5 - Value of c is ", c c = a >> 2; # 15 = 0000 1111print "Line 6 - Value of c is ", c运算符优先级
元组、字典、列表
元组:只能创建和查,不能修改(方法:count 、 index)
列表: 增、删、改、查、索引、切片(方法:append、insert、pop、del、index、len)
列表扩展:
>>> names [\'Alex\', \'Tenglan\', \'Rain\', \'Tom\', \'Amy\'] >>> b = [1,2,3] >>> names.extend(b) >>> names [\'Alex\', \'Tenglan\', \'Rain\', \'Tom\', \'Amy\', 1, 2, 3]
字典(无序):增、删、改、查、索引(方法:get、clear、popitem)
#setdefault(字典中有就不变,没有就添加)
>>> info.setdefault("stu1106","Alex")
\'Alex\'
>>> info
{\'stu1102\': \'LongZe Luola\', \'stu1103\': \'XiaoZe\', \'stu1106\': \'Alex\'}
#update
>>> info
{\'stu1102\': \'LongZe Luola\', \'stu1103\': \'XiaoZe\', \'stu1106\': \'Alex\'}
>>> b = {1:2,3:4, "stu1102":"bala"}
>>> info.update(b)
>>> info
{\'stu1102\': \'bala\', 1: 2, 3: 4, \'stu1103\': \'XiaoZe\', \'stu1106\': \'Alex\'}
#通过一个列表生成默认dict,有个没办法解释的坑,少用吧这个
>>> dict.fromkeys([1,2,3],\'testd\')
{1: \'testd\', 2: \'testd\', 3: \'testd\'}
补充
enumerate用法:
for index,item in enumerate(proc_name):
index ----> 下标
item ------> 元素
以上是关于Python day02心得的主要内容,如果未能解决你的问题,请参考以下文章