Python解析xml
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python解析xml相关的知识,希望对你有一定的参考价值。
XML 被设计用来传输和存储数据。
HTML 被设计用来显示数据。
XML(eXtensible Markup Language)指可扩展标记语言,被设计用来传输和存储数据,已经日趋成为当前许多新生技术的核心,在不同的领域都有着不同的应用。它是web发展到一定阶段的必然产物,既具有SGML的核心特征,又有着HTML的简单特性,还具有明确和结构良好等许多新的特性。
python解析XML常见的有三种方法:一是xml.dom.*模块,它是W3C DOM API的实现,若需要处理DOM API则该模块很适合,注意xml.dom包里面有许多模块,须区分它们间的不同;二是xml.sax.*模块,它是SAX API的实现,这个模块牺牲了便捷性来换取速度和内存占用,SAX是一个基于事件的API,这就意味着它可以“在空中”处理庞大数量的的文档,不用完全加载进内存;三是xml.etree.ElementTree模块(简称 ET),它提供了轻量级的Python式的API,相对于DOM来说ET 快了很多,而且有很多令人愉悦的API可以使用,相对于SAX来说ET的ET.iterparse也提供了 “在空中” 的处理方式,没有必要加载整个文档到内存,ET的性能的平均值和SAX差不多,但是API的效率更高一点而且使用起来很方便。
Python解析xml的三种方式为:Element tree、DOM、SAX
Element tree:
Element类型是一种灵活的容器对象,用于在内存中存储层次数据结构。可以说是list和dictionary的交叉,它生来就是为了处理XML,它在Python标准库中有两种实现:一种是纯Python实现的,如xml.etree.ElementTree,另一种是速度快一点的xml.etree.cElementTree。注意:尽量使用C语言实现的那种,因为它速度更快,而且消耗的内存更少。
Element tree会将xml文件解析为元素树。
每个element都有一系列相关属性:
- 标签,用于标识该元素表示哪种数据(即元素类型)
- 一些属性,存储在Python dictionary中
- 一个文本字符串
- 一个可选的尾字符串
- 一些孩子elements,存储在Python sequence中
abc.xml文件如下
<?xml version="1.0"?> <!--主节点为data 孩子节点为country,也就是二级tag--> <data> <country name="Singapore" area="Asia"> <rank>4</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama" area="NA"> <rank>68</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
使用Element tree解析的python代码如下:
import xml.etree.ElementTree as ET #在这里还可以使用c实现的 速度更快,写法如下
‘‘‘try:
import xml.etree.ElementTree as ET
except ImportError:
import xml.etree.cElementTree as ET‘‘‘
import sys try: tree = ET.parse(‘abc.xml‘) #打开xml文件生成解析对象 # root = ET.fromstring(‘xml字符串‘) #解析xml字符串时,解析函数生成元素树 root = tree.getroot() #得到根节点 except Exception as e: print(‘parse object error‘) sys.exit(1) print(root.tag, "---", root.attrib) #root.tag值为data,而列属性attrib不存在值 for child in root: #遍历子节点 print(child.tag, "---", child.attrib) #child节点的tag属性,子节点的列属性存在值 print("*"*10) print(‘year:‘+root[0][1].text) #root[0]为第一个子节点:第一个country print(root[0].tag, root[0][1].text) # root[0]的意思是第一个子节点的tag属性, 所以root[0][1].text意思就是:访问文本内容得到第一个子节点的第二个标签数据,这种方法是通过根节点来得到的,还可以通过根节点的遍历查找拿到。 print("*"*10) for cons in root.findall(‘country‘): #从根节点开始遍历寻找country节点 rank = cons.find(‘rank‘).text #想拿到子节点中rank标签对嵌入的值 neighbor = cons.find(‘neighbor‘).get(‘name‘) # 查找country中neighbor这个tag ,然后再拿到列中name属性 name = cons.get(‘name‘) #子节点的get方法直接拿到列中想要的属性 area = cons.get(‘area‘) #同上 print(‘country:‘+name+‘\\narea:‘+area+‘\\nranking:‘+rank+‘\\nneighbor:‘+neighbor+‘\\n‘)
结果如下:
data --- {} country --- {‘name‘: ‘Singapore‘, ‘area‘: ‘Asia‘} country --- {‘name‘: ‘Panama‘, ‘area‘: ‘NA‘} ********** year:2011 country 2011 ********** country:Singapore area:Asia ranking:4 neighbor:Malaysia country:Panama area:NA ranking:68 neighbor:Costa Rica
同时Element还可以迭代遍历子树:
for country in root.iter(‘country‘): print(country.attrib) #同时迭代出的字树也可以拿到列属性,
#name = country.get(‘name‘)
#不仅一个列可以拿到,相同子节点所有文本内容都可拿到....
#rank = country.find(‘rank‘).text
for neighbor in root.iter(‘neighbor‘): print(neighbor.attrib)
结果:
{‘name‘: ‘Singapore‘, ‘area‘: ‘Asia‘}
{‘name‘: ‘Panama‘, ‘area‘: ‘NA‘}
{‘name‘: ‘Malaysia‘, ‘direction‘: ‘N‘}
{‘name‘: ‘Costa Rica‘, ‘direction‘: ‘W‘}
{‘name‘: ‘Colombia‘, ‘direction‘: ‘E‘}
ElementTree.write() 提供了修改xml文件的方法
#此处剔除排名大于50的国家 for country in root.iter(‘country‘): rank = int(country.find(‘rank‘).text) if rank > 50: root.remove(country) tree.write(‘output.xml‘)
结果另一个country字树被剔除,output.xml如下:
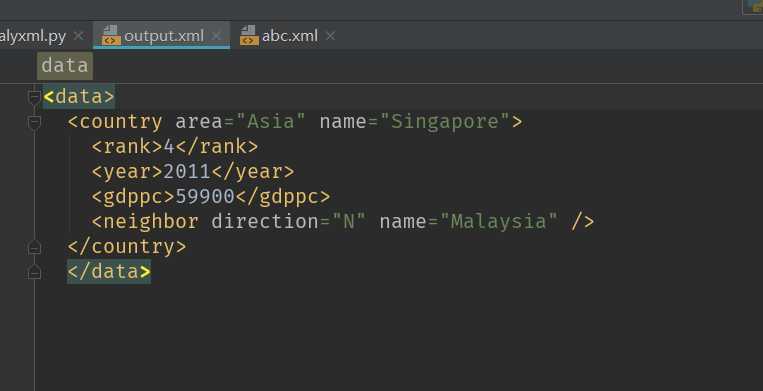
如何修改子节点中标签的属性?
修改rank排名。每个国家前进一名
#使每个国家排名前进一名 for rank in root.iter(‘rank‘): # uprank = int() print(rank.text) uprank = int(rank.text) - 1 rank.text = str(uprank) tree.write(‘out.xml‘)
结果
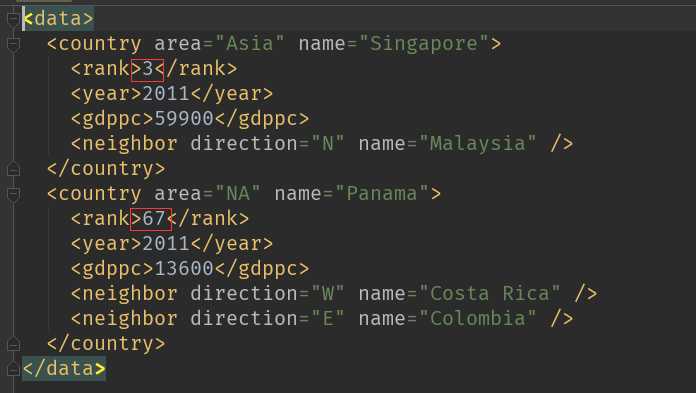
还可以为标签添加属性
for rank in root.iter(‘rank‘): # uprank = int() print(rank.text) uprank = int(rank.text) - 1 rank.text = str(uprank) rank.set(‘after_modify‘, ‘success‘) #使用set方法即可修改 tree.write(‘out.xml‘)
out.xml
<data> <country area="Asia" name="Singapore"> <rank after_modify="success">3</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor direction="N" name="Malaysia" /> </country> <country area="NA" name="Panama"> <rank after_modify="success">67</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor direction="W" name="Costa Rica" /> <neighbor direction="E" name="Colombia" /> </country> </data>
细则参见官方文档:xml.etree.ElementTree
DOM和SAX可以参考其他的博客
以上是关于Python解析xml的主要内容,如果未能解决你的问题,请参考以下文章
Android 逆向使用 Python 解析 ELF 文件 ( Capstone 反汇编 ELF 文件中的机器码数据 | 创建反汇编解析器实例对象 | 设置汇编解析器显示细节 )(代码片段