python迭代器生成器和yield语句
Posted -柚子皮-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python迭代器生成器和yield语句相关的知识,希望对你有一定的参考价值。
http://blog.csdn.net/pipisorry/article/details/22107553
一、迭代器(iterator)
迭代器:是一个实现了迭代器协议的对象,Python中的迭代器协议就是有next方法的对象会前进到下一结果,而在一系列结果的末尾是,则会引发StopIteration。
迭代器对象要求支持迭代器协议的对象,在Python中,支持迭代器协议就是实现对象的__iter__()和next()方法。其中__iter__()方法返回迭代器对象本身;next()方法(在python3中使用__next__()代替了next方法)返回容器的下一个元素,在结尾时引发StopIteration异常,这并不是错误的发生,而是告诉外部调用者迭代完成了,外部的调用者尝试去捕获这个异常去做进一步的处理。当我们使用for语句的时候,for语句就会自动的通过__iter__()方法来获得迭代器对象,并且通过next()方法来获取下一个元素。
好处是:每次只从对象中读取一条数据,不会造成内存的过大开销。迭代是一点一点读取数据,而不是一次性加载所有数据到内存,对于超大数据来说迭代读取速度快。
不过迭代器是有限制的,例如:不能向后移动,不能回到开始,也无法复制一个迭代器,因此要再次进行迭代只能重新生成一个新的迭代器对象。
举个栗子
比如要逐行读取一个文件的内容,利用readlines()方法,我们可以这么写:
for line in open("test.txt").readlines():
print line
这样虽然可以工作,但不是最好的方法。因为他实际上是把文件一次加载到内存中,然后逐行打印。当文件很大时,这个方法的内存开销就很大了。
利用file的迭代器,我们可以这样写:
for line in open("test.txt"): #use file iterators
print line
这是最简单也是运行速度最快的写法,他并没显式的读取文件,而是利用迭代器每次读取下一行。
python迭代工具模块[Python - itertools模块]
迭代器和可迭代对象
python对象转换成迭代器
iter() 函数用来生成迭代器。如iter([1,2,3])。
自定义迭代器
示例1
普通的迭代器只能迭代一轮,一轮之后重复调用是无效的。解决这种问题的方法是,你可以定义一个可迭代的容器类:
class LoopIter(object):
def __init__(self, data):
self.data = data
# 必须在 __iter__ 中 yield 结果
def __iter__(self):
for index, letter in enumerate(self.data):
if letter == 'a':
yield index
这样的话,将类的实例迭代重复多少次都没问题:
for _ in indexs:
print(_)
# loop 1
print('loop 2')
for _ in indexs:
print(_)
但要注意的是,仅仅是实现__iter__方法的迭代器,只能通过for循环来迭代;想要通过next方法迭代的话则需要使用iter方法:
next(indexs) # TypeError: 'LoopIter' object is not an iterator
iter_indexs = iter(indexs)
next(iter_indexs) # 8
示例2
下面例子中实现了一个MyRange的类型,这个类型中实现了__iter__()方法,通过这个方法返回对象本身作为迭代器对象;同时,实现了next()方法用来获取容器中的下一个元素,当没有可访问元素后,就抛出StopIteration异常。
class MyRange(object):
def __init__(self, n):
self.idx = 0
self.n = n
def __iter__(self):
return self
def next(self):
if self.idx < self.n:
val = self.idx
self.idx += 1
return val
else:
raise StopIteration()这个自定义类型跟内建函数xrange很类似。
在上面的例子中,myRange这个对象就是一个可迭代对象,同时它本身也是一个迭代器对象。
对于一个可迭代对象,如果它本身又是一个迭代器对象,就没有办法支持多次迭代。(iter返回的是本身self)

为了解决上面的问题,可以分别定义可迭代类型对象和迭代器类型对象;然后可迭代类型对象的__iter__()方法可以获得一个迭代器类型的对象。
分开定义的好处在于, 当对可迭代对象使用iter()转变时,返回一个新的迭代器对象, 这时不受先前产生的相应迭代器对象影响。
看下面的实现:
class Zrange:
def __init__(self, n):
self.n = n
def __iter__(self):
return ZrangeIterator(self.n)
class ZrangeIterator:
def __init__(self, n):
self.i = 0
self.n = n
def __iter__(self):
return self
def next(self):
if self.i < self.n:
i = self.i
self.i += 1
return i
else:
raise StopIteration()
zrange = Zrange(3)
print zrange is iter(zrange)
print [i for i in zrange]
print [i for i in zrange]
代码的运行结果为:

其实,通过下面代码可以看出,list类型也是按照上面的方式,list本身是一个可迭代对象,通过iter()方法可以获得list的迭代器对象:

zrange = Zrange(3)
print zrange is iter(zrange)
#>>> True
print [i for i in zrange]
#>>>[1,2,3]
print [i for i in zrange]
#>>>[1,2,3]
# 若不区分可迭代对象和迭代器, 即这里列表生成式中使用ZrangeIterator的话, 第二次调用时迭代器已被迭代完,第二次会为空集.
zzrange=ZrangeIterator(3);
print [i for i in zzrange]
#>>>[1,2,3]
print [i for i in zzrange]
#>>>[]
皮皮Blog
二、生成器(constructor)
在Python中,使用生成器可以很方便的支持迭代器协议。生成器通过生成器函数产生,生成器函数可以通过常规的def语句来定义,但是不用return返回,而是用yield一次返回一个结果,在每个结果之间挂起和继续它们的状态,来自动实现迭代协议。也就是说,yield是一个语法糖,内部实现支持了迭代器协议,同时yield内部是一个状态机,维护着挂起和继续的状态。
生成器函数在Python中与迭代器协议的概念联系在一起。简而言之,包含yield语句的函数会被特地编译成生成器。当函数被调用时,他们返回一个生成器对象,这个对象支持迭代器接口。
函数也许会有个return语句,但它的作用是用来yield产生值的。不像一般的函数会生成值后退出,生成器函数在生成值后会自动挂起并暂停他们的执行和状态,他的本地变量将保存状态信息,这些信息在函数恢复时将再度有效。
生成器的使用
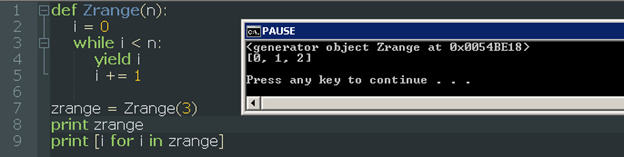
例子中定义了一个生成器函数,函数返回一个生成器对象,然后就可以通过for语句进行迭代访问了。
其实,生成器函数返回生成器的迭代器。 “生成器的迭代器”这个术语通常被称作”生成器”。要注意的是生成器就是一类特殊的迭代器。作为一个迭代器,生成器必须要定义一些方法,其中一个就是next()。如同迭代器一样,我们可以使用next()函数来获取下一个值。
Note: 这里的函数Zrange必须要生成实例,不能使用Zrange(3).__next__()形式调用,这相当于每次新生成了一个Zrange对象,这样里面的循环每次调用都只会循环一次!
生成器执行流程
生成器是怎么工作的?从上面的例子也可以看到,生成器函数跟普通的函数是有很大差别的。加入一些打印信息,进一步看看生成器的执行流程:

通过结果可以看到:
- 当调用生成器函数的时候,函数只是返回了一个生成器对象,并没有 执行。
-
当next()方法第一次被调用的时候,生成器函数才开始执行,执行到yield语句处停止
- next()方法的返回值就是yield语句处的参数(yielded value)
- 当继续调用next()方法的时候,函数将接着上一次停止的yield语句处继续执行,并到下一个yield处停止;如果后面没有yield就抛出StopIteration异常
Generator expressions生成器表达式
为什么要有生成器表达式
列表解析可能出现的问题:List comprehensions have one possible problem, and that is they build the list in memory right away. If your dealing with big data sets, that can be a big problem, but even with small lists, it is still extra overhead that might not be needed.
If you are only going to loop over the results once it has no gain in building this list. So if you can give up being able to index into the result, and do other list operations, you can use a generator expression, which uses very similar syntax, but creates a lazy object, that computes nothing until you ask for a value.
列表推导也可能会有一些负面效应,那就是整个列表必须一次性加载于内存之中,这对上面举的例子而言不是问题,甚至扩大若干倍之后也都不是问题。但是总会达到极限,内存总会被用完。
针对上面的问题,生成器(Generator)能够很好的解决。生成器表达式不会一次将整个列表加载到内存之中,而是生成一个生成器对象(Generator objector),所以一次只加载一个列表元素。
除非特殊的原因,应该经常在代码中使用生成器表达式。但除非是面对非常大的列表,否则是不会看出明显区别的。
# generator expression for the square of all the numbers squares = (num * num for num in numbers)
# where you would likely get a memory problem otherwise with open('/some/number/file', 'r') as f: squares = (int(num) * int(num) for num in f) # do something with these numbers |
生成器表达式是在python2.4中引入的,当序列过长, 而每次只需要获取一个元素时,应当考虑使用生成器表达式而不是列表解析。和列表解析一样,只不过生成器表达式是被()括起来的:(expr for iter_var in iterable if cond_expr)
生成器表达式并不是创建一个列表, 而是返回一个生成器,这个生成器在每次计算出一个条目后,把这个条目”产生”(yield)出来。 生成器表达式使用了”惰性计算”(lazy evaluation),只有在检索时才被赋值(evaluated),所以在列表比较长的情况下使用内存上更有效。
使用生成器
考虑使用生成器来改写直接返回列表的函数
# 定义一个函数,其作用是检测字符串里所有 a 的索引位置,最终返回所有 index 组成的数组
def get_a_indexs(string):
result = []
for index, letter in enumerate(string):
if letter == 'a':
result.append(index)
return result
用列表方法有几个小问题:
每次获取到符合条件的结果,都要调用append方法。但实际上我们的关注点根本不在这个方法,它只是我们达成目的的手段,实际上只需要index就好了
返回的result可以继续优化
数据都存在result里面,如果数据量很大的话,会比较占用内存
因此,使用生成器generator会更好。生成器是使用yield表达式的函数,调用生成器时,它不会真的执行,而是返回一个迭代器,每次在迭代器上调用内置的next函数时,迭代器会把生成器推进到下一个yield表达式:
def get_a_indexs(string):
for index, letter in enumerate(string):
if letter == 'a':
yield index
获取到一个生成器以后,可以正常的遍历它:
string = 'this is a test to find a\\' index'
indexs = get_a_indexs(string)
for i in indexs:
print(i)
# 或者这样
try:
while True:
print(next(indexs))
except StopIteration:
print('finish!')
# 生成器在获取完之后如果继续通过 next() 取值,则会触发 StopIteration 错误, 但通过 for 循环遍历时会自动捕获到这个错误
如果你还是需要一个列表,那么可以将函数的调用结果作为参数,再调用list方法
results = get_a_indexs('this is a test to check a')
results_list = list(results)
举个栗子

从这个例子中可以看到,生成器表达式产生的生成器,它自身是一个可迭代对象,同时也是迭代器本身。
递归生成器
生成器可以向函数一样进行递归使用的,下面看一个简单的例子,对一个序列进行全排列:
def permutations(li):
if len(li) == 0:
yield li
else:
for i in range(len(li)):
li[0], li[i] = li[i], li[0]
for item in permutations(li[1:]):
yield [li[0]] + item
for item in permutations(range(3)):
print item代码的结果为:

生成器的send()和close()方法
send(value):
从前面了解到,next()方法可以恢复生成器状态并继续执行,其实send()是除next()外另一个恢复生成器的方法。
Python 2.5中,yield语句变成了yield表达式,也就是说yield可以有一个值,而这个值就是send()方法的参数,所以send(None)和next()是等效的。同样,next()和send()的返回值都是yield语句处的参数(yielded value)
关于send()方法需要注意的是:调用send传入非None值前,生成器必须处于挂起状态,否则将抛出异常。也就是说,第一次调用时,要使用next()语句或send(None),因为没有yield语句来接收这个值。
close():
这个方法用于关闭生成器,对关闭的生成器后再次调用next或send将抛出StopIteration异常。
下面看看这两个方法的使用:

生成器语句yield
1. 包含yield的函数
假如你看到某个函数包含了yield,这意味着这个函数已经是一个Generator,它的执行会和其他普通的函数有很多不同。
def h():
print('To be brave')
yield 5
h()
Note:调用h()之后,print 语句并没有执行!
2. yield是一个表达式
Python2.5以前,yield是一个语句,但现在2.5中,yield是一个表达式(Expression),比如:
m = yield 5
表达式(yield 5)的返回值将赋值给m,所以,认为 m = 5 是错误的。那么如何获取(yield 5)的返回值呢?需要用到后面要介绍的send(msg)方法。
3. 透过next()语句看原理
h()被调用后并没有执行,因为它有yield表达式,因此,我们通过next()语句将恢复Generator执行,并直到下一个yield表达式处。
def h():
print('Wen Chuan')
yield 5
print 'Fighting!'
c = h()
c.__next__()
c.next()调用后,h()开始执行,直到遇到yield 5,因此输出结果:
Wen Chuan
当我们再次调用c.next()时,会继续执行,直到找到下一个yield表达式。由于后面没有yield了,因此会拋出异常:
Wen Chuan
Fighting!
Traceback (most recent call last):
File "/home/evergreen/Codes/yidld.py", line 11, in <module>
c.__next__()
StopIteration
4. send(msg) 与 next()
再来看另外一个非常重要的函数send(msg)。其实next()和send()在一定意义上作用是相似的,区别是send()可以传递yield表达式的值进去,而next()不能传递特定的值,只能传递None进去。因此,c.next() 和 c.send(None) 作用是一样的。
def h():
print('Wen Chuan',)
m = yield 5 # Fighting!
print(m)
d = yield 12
print('We are together!')
c = h()
c.__next__() #相当于c.send(None)
c.send('Fighting!') #(yield 5)表达式被赋予了'Fighting!'
输出的结果为:
Wen Chuan Fighting!
Note:第一次调用时,请使用next()语句或是send(None),不能使用send发送一个非None的值,否则会出错的,因为没有yield语句来接收这个值。
5. send(msg) 与 next()的返回值
send(msg) 和 next()是有返回值的,返回的是下一个yield表达式的参数。比如yield 5,则返回 5 。前面例子中,通过for遍历 Generator,其实是每次都调用了Next(),而每次Next()的返回值正是yield的参数,即我们开始认为被压进去的。
def h():
print('Wen Chuan',)
m = yield 5 # Fighting!
print (m)
d = yield 12
print('We are together!')
c = h()
m = c.__next__() #m 获取了yield 5 的参数值 5
d = c.send('Fighting!') #d 获取了yield 12 的参数值12
print('We will never forget the date', m, '.', d)
输出结果:
Wen Chuan Fighting!
We will never forget the date 5 . 12
6. throw() 与 close()中断 Generator
中断Generator是一个非常灵活的技巧,可以通过throw抛出一个GeneratorExit异常来终止Generator。Close()方法作用是一样的,其实内部它是调用了throw(GeneratorExit)的。我们看:
def close(self):
try:
self.throw(GeneratorExit)
except (GeneratorExit, StopIteration):
pass
else:
raise RuntimeError("generator ignored GeneratorExit")
# Other eceptions are not caught
因此,当我们调用了close()方法后,再调用next()或是send(msg)的话会抛出一个异常:
Traceback (most recent call last):
File "/home/evergreen/Codes/yidld.py", line 14, in <module>
d = c.send('Fighting!') #d 获取了yield 12 的参数值12
StopIteration
[What does the yield keyword do in Python?]
Note:注意python2和python3中迭代器、生成器和yield语句的区别[python2和python3的区别、转换及共存]
yield使用示例
1 通过两阶列表推导式遍历目录
import os
def tree(top):
for path, names, fnames in os.walk(top):
for fname in fnames:
yield os.path.join(path, fname)
for name in tree('C:\\Users\\XXX\\Downloads\\Test'):
print name
2 列表值按需引用
lz发现的一个较好的应用场景是,绘图时颜色的取用
colors = ['aqua', 'darkorange', 'cornflowerblue']
在函数中yield colors就不用在函数外使用下标调用颜色了。
一个更好的代替是
colors = cycle(['aqua', 'darkorange', 'cornflowerblue'])
plt.plot(f_pos, t_pos, color=colors.__next__(), lw=2, label='AUC = %.2f' % auc_area)
3 无穷循环器
from:http://blog.csdn.net/pipisorry/article/details/22107553
ref:http://www.jb51.net/article/15717.htm
以上是关于python迭代器生成器和yield语句的主要内容,如果未能解决你的问题,请参考以下文章