知乎使用指南
Posted Meteor的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知乎使用指南相关的知识,希望对你有一定的参考价值。
知乎食用指南
目前知乎近版本有一下恶心人的地方那个
- 加入大量广告,每次刷新都夹杂大量广告
- 为了增加广告,将左右翻页变成恶心的上下滑动翻译,在滑动中间增加广告,并且明显感受到左右滑动比上下滑动要好
- 杂七杂八内容太多,导致内容卡顿
从初中的时候就开始看知乎,结果知乎越来越恶心,以下是解决方法
解决方法
使用知乎老版本即可,
在知乎低版本中使用的是左右滑动翻页,但是在低版本中一些功能不能正常食用,如刷新获取问题等
食用放那个发
在豌豆荚app 中可以获取到知乎所有版本的历史记录,从中可以直接下载老版本
知乎版本选择的是5.22.1这个版本
- 完全没广告
- 左右滑动
- 功能正常,功能完全够用
步骤
- 下载豌豆荚搜索知乎
- 进入知乎,选择历史版本
- 下载
5.22.1版本,时间差不多是2018年7月26日,安装包是39.91MB,(认准这个信息) - 关闭系统的软件自动更新,防止知乎自动更新到最新版本
本文来自博客园,作者:Meteor_Z,转载请注明原文链接:https://www.cnblogs.com/Meteor-Z/p/17277843.html
使用selenium模拟登录知乎
网上流传着许多抓取知乎数据的代码,抓取它的数据有一个问题一定绕不过去,那就是模拟登录,今天我们就来聊聊知乎的模拟登录。
获取知乎内容的方法有两种,一种是使用request,想办法携带cookies等必要参数去请求数据,但是使用requests的话,不仅要解析Cookies,还要获取XSRF,比较麻烦,所以我想到了selenium。
我直接控制Chrome请求知乎,然后模拟输入用户名和密码,这样不也可以吗,嘿嘿
接下来说一下大体流程:
首先控制selenium模拟请求知乎登录界面:https://www.zhihu.com/signup?next=%2F
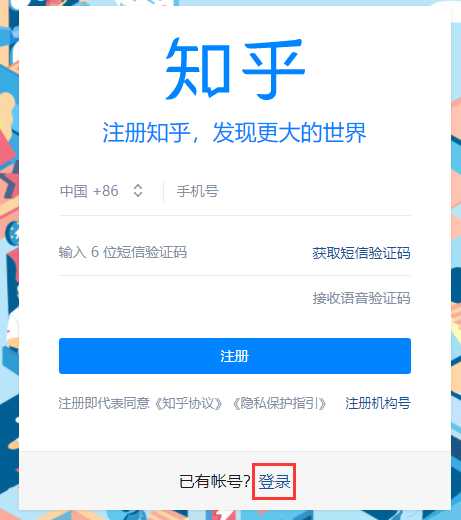
但是默认为注册,所以需要控制鼠标来点击上边那个登录按钮,就变成这样了。
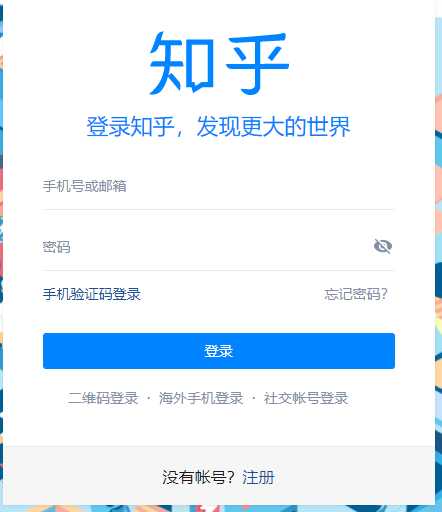
然后我们在控制浏览器找到输入用户名、密码的这两个input标签,使用send_keys()来将用户名密码输入进去即可,部分代码如下:
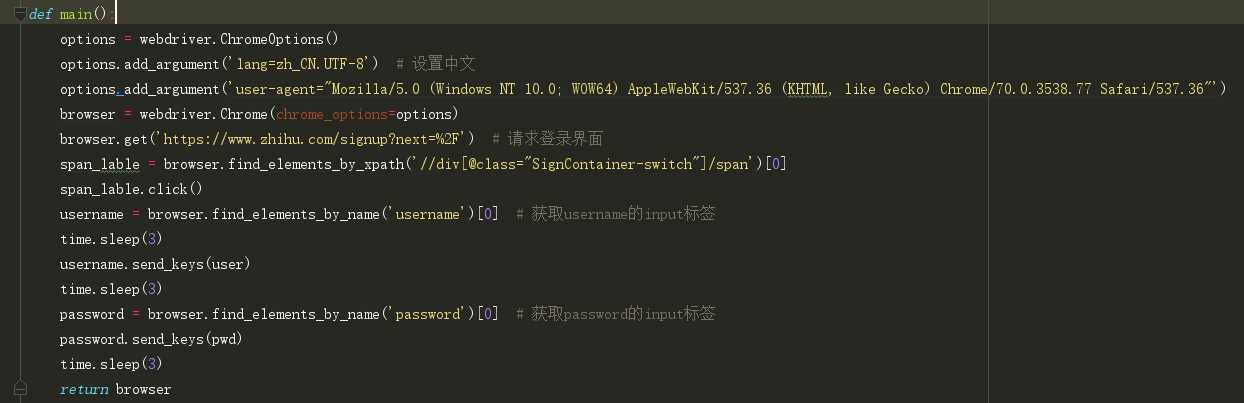
但就在我正要点击登录按钮时问题出现了:验证码
经过测试,知乎的验证码分为两种,而且两种验证码所对应的代码是不一样的:
第一种:4位英文数字组成的图片,用户输入对应的英文数字即可。
第二种:纯中文组成的图片,用户使用鼠标来点击图片中倒立的汉字进行验证。
但是我发现验证码也不是次次都出现的,而且如果验证码要出现,当用户输入完密码之后就可以看见了。
而且即使验证码没有在页面中显示出来,却并不代表没有验证码,验证码那一部分代码还是存在的,只是在存放验证码图片的<img>标签那儿图片链接显示为null而已。
那么当一个用户在登录知乎,输入完用户名、密码之后会遇到两大类、四小类(一共四种情况):
(一)无验证码:用户输入完用户名、密码之后没有看见验证码
(1):(英文数字验证码)代码部分中<img>的class为englishImg, src为null

(2):(纯中文验证码)代码部分中<img>的class为chineseImg, src为null

(二)有验证码:用户输入完用户名、密码之后会看见验证码
(1):(英文数字验证码)代码部分中<img>的class为englishImg, src为base64编码的图片路径
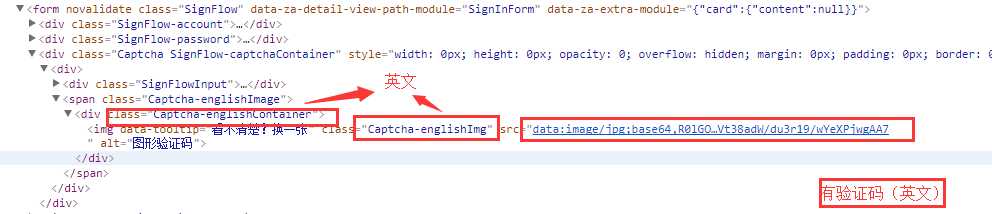
(2):(纯中文验证码)代码部分中<img>的class为chineseImg, src为base64编码的图片路径

既然分为两大类四小类,那我们就挨个的处理,首先在输入用户名改密码密码后判断有没有验证码显示出来,若没有,则直接点击登录按钮进行登录;
这是我辨别验证码类型的部分代码:
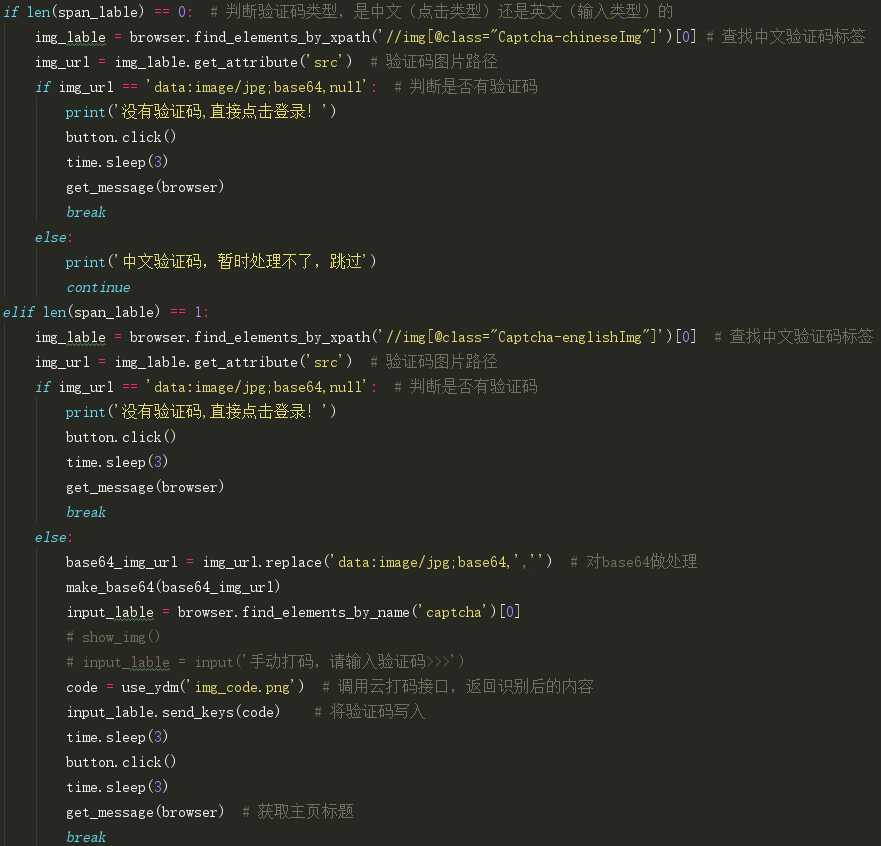
若有验证码显示出来,则再进行细分,是中文点击验证码还是英文数字输入验证码,辨别验证码类型后再分别进行处理。
首先说一下中文验证码:嘿嘿嘿,时间比较仓促,这个我就没有识别,我看别人都是将验证码保存至本地然后对每个中文的位置进行大致定位,然后人工输入倒立的字的序号,然后计算出该字在图片中的位置,在操控鼠标进行模拟点击。
下面我们说说英文数字验证码:这个主要有两种解决方案
第一种:人工打码。当验证码出现时,将经过base64编码的图片进行解码然后保存至本地,然后将图片展示出来进行人工识别,再在控制台中输入识别后的结果,最后李勇模拟浏览器将结果输入到登录页面中进行登录。
第二种:借助第三方打码平台自动打码,首先将验证码保存至本地,然后接入第三方打码平台的接口进行机器打码,最后将结果输入登录界面。
在这里我详细说说第三方打码的过程:
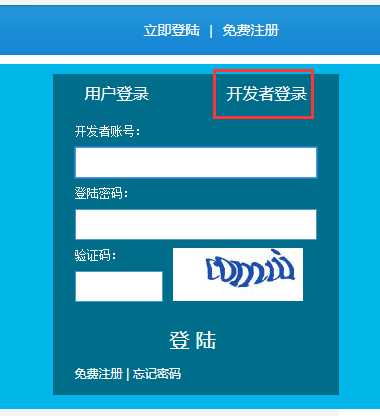
我是用的是“云打码”平台的接口(然后无意间发发现了他们平台一个错别字,是登录,不是登陆),首先注册一个开发者账号:
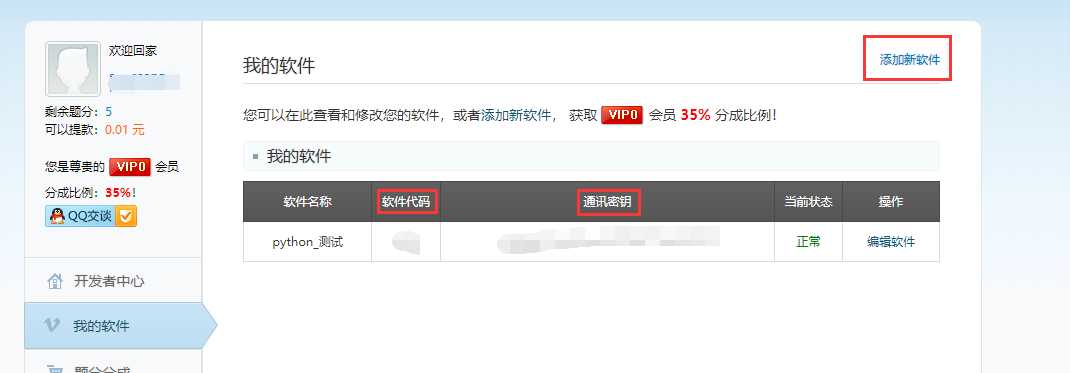
进去之后点击我的软件,新建一个自己的软件(名字随便填),然后会获得一个软件代码(id),通讯密钥(key),这两个参数在调用接口时要用。
然后联系官网上的客服,以开发者的身份向他索要测试分(云打码平台是收费的,没有题分,无法识别验证码)
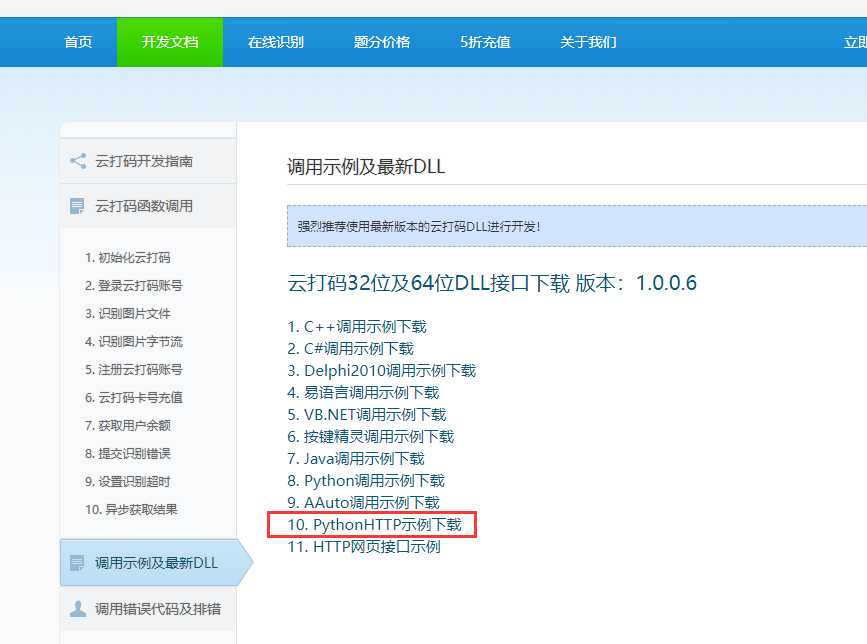
然后在官网上的开发文档中选择调用示例及最新DLL,点击PythonHTTP示例下载,下载接口Demo
然后将Demo中的必要参数改一改(如username、password、id、Key等)最后在记得的代码中调用一下即可。
在验证码全部处理完毕之后再进行模拟登录就可以正常的访问知乎中的内容了,最终我获取了知乎首页的文章标题
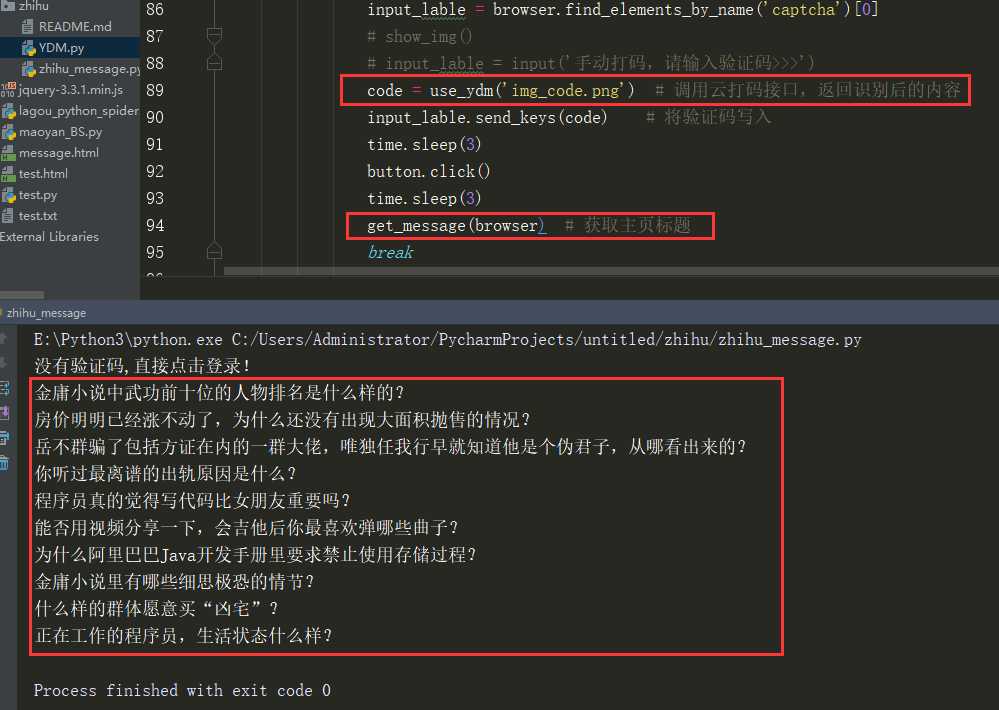
ps: 在一切处理好之后我在模拟点击登录时又碰到了一个问题,切切都处理好了,在点击登录按钮后并没有进入登录页面,而是显示 “Miss argument grant_type ” 查询资料说是浏览器版本问题,当我将Chrome从70降到60后问题就解决了。
ps: 本次代码我全部在我的github上: https://github.com/songsa1/Python_song (60版本的Chrome和对应的webdriver的百度云链接在项目的readme中)
欢迎大家来关注我的个人公众号:“进阶的爬虫” 我会定期在公众号中分享爬虫的教程、项目案例,还有互联网圈中的一些新闻、趣事儿。

以上是关于知乎使用指南的主要内容,如果未能解决你的问题,请参考以下文章