Python爬取博客园新闻代码
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬取博客园新闻代码相关的知识,希望对你有一定的参考价值。
核心模块:
requests :安装指令 pip3 install requests
BeautifulSoup :安装指令 pip3 install beautifulsoup4
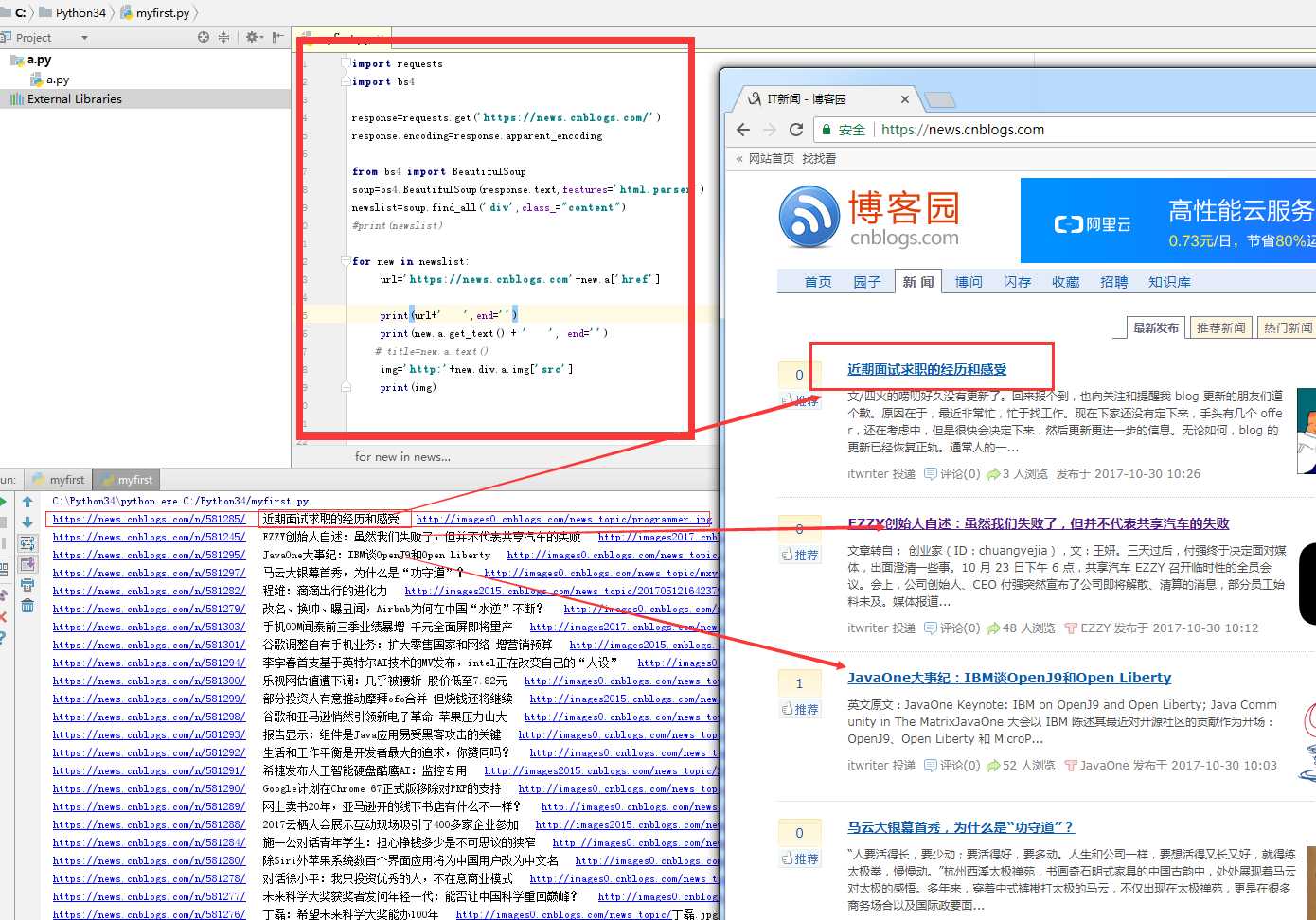
代码:
import requests import bs4 import os response=requests.get(‘https://news.cnblogs.com/‘) response.encoding=response.apparent_encoding from bs4 import BeautifulSoup soup=bs4.BeautifulSoup(response.text,features=‘html.parser‘) newslist=soup.find_all(‘div‘,class_="content") #print(newslist) for new in newslist: url=‘https://news.cnblogs.com‘+new.a[‘href‘] print(url+‘ ‘,end=‘‘) print(new.a.get_text() + ‘ ‘, end=‘‘) img=‘http:‘+new.div.a.img[‘src‘] print(img) #下载图片 downloadimg=requests.get(img) path=os.getcwd()+‘/‘+img.split(‘/‘)[-1] with open(path,‘wb‘) as f: f.write(downloadimg.content)
以上是关于Python爬取博客园新闻代码的主要内容,如果未能解决你的问题,请参考以下文章