Python11 RabbitMQ Redis
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python11 RabbitMQ Redis相关的知识,希望对你有一定的参考价值。
本节内容
1.RabbitMQ
2.Redis
RabbitMQ队列
安装 http://www.rabbitmq.com/install-standalone-mac.html
安装python rabbitMQ module
pip install pika or easy_instal pika or 源码
https://pypi.python.org/pypi/pika
实现最简单的队列通信
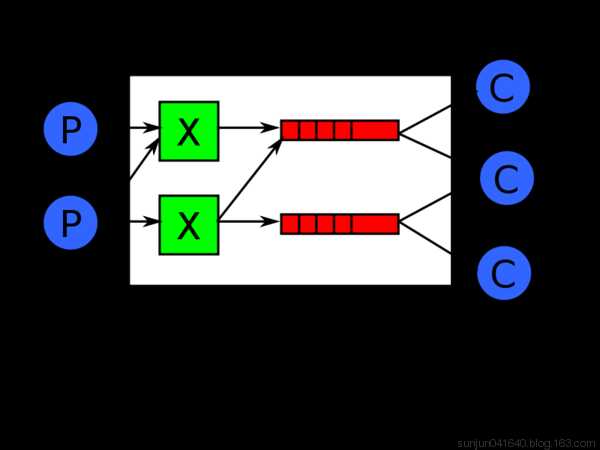
send端
import pika
# 申明一个链接
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
# 申明一个管道
channel = connection.channel()
# 申明一个队列
channel.queue_declare(queue="queue1")
# 发布队列消息
channel.basic_publish(exchange="",
routing_key="queue1",
body="hello from rabbitMQ send client")
print("send data out..")
connection.close()
recv端
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel = connection.channel()
# 这里为什么还要申明一下这个管道里面的队列,因为作为一个接收端,我们是无法察觉到发送端是否已经申明这个队列或者发送数据
# 这里我们为了不让系统报错就需要这样申明一下,如果你能确定已经在另一端申明了这个queue也可以忽略注释掉,当然这都是建议
channel.queue_declare(queue="queue1")
# 这里先不解释,但是body大家一眼就能看出来是传递的message
def callback(ch, method, properties, body):
print("recv from send client:", body)
# 消费与准备,消费的回掉函数叫callback,队列是queue1,no_ack
channel.basic_consume(callback,
queue="queue1",
no_ack=False)
# no_ack = True 之后消息会轮询,即如果有2个recv端,a先接收一条,然后b接收一条,然后a,看ab起来的顺序轮询接收
# 实际上,no_ack代表没有回执如果true消息只发送给a一次,如果是false的话,a断了会将a所有的消息全部重新发给b,因为没有回执确认
print("waiting for message....")
channel.start_consuming()
远程连接rabbirMQ server,需要配置权限:
首先在rabbitmq server上创建一个账户:
1 sudo rabbitmqctl add_user dandy password.1
同时还要配置权限,允许从外面访问
1 sudo rabbitmqctl set_permissions -p / dandy".*" ".*" ".*"
set_permissions [-p vhost] {user} {conf} {write} {read}
- vhost
-
The name of the virtual host to which to grant the user access, defaulting to /.
- user
-
The name of the user to grant access to the specified virtual host.
- conf
-
A regular expression matching resource names for which the user is granted configure permissions.
- write
-
A regular expression matching resource names for which the user is granted write permissions.
- read
-
A regular expression matching resource names for which the user is granted read permissions.
客户端连接的时候需要配置认证参数
credentials = pika.PlainCredentials(‘dandy‘, ‘password.1‘)
connection = pika.BlockingConnection(pika.ConnectionParameters(
‘10.211.55.5‘,5672,‘/‘,credentials))
channel = connection.channel()
消息持久化
队列持久化语法:(发送接收端都需要加上)
channel.queue_declare(queue=‘hello‘, durable=True)
消息持久化语法:
channel.basic_publish(exchange=‘‘, routing_key="task_queue", body=message, properties=pika.BasicProperties( delivery_mode = 2, # 消息持久化 ))举个栗子:
producer
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters("localhost")
) # 实例化一个链接
channel = connection.channel() # 实例化一个管道
channel.queue_declare(queue="queue1", durable=True) # 实例化一个队列
channel.basic_publish(exchange="",
routing_key="queue1",
body="hello world123----00000",
properties=pika.BasicProperties(
delivery_mode=2,
)) # properties消息持久化,需要先队列持久化
# 发布管道的队列
print("producer send hello world !")
connection.close() # 关闭链接
consumer
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost")) #
channel = connection.channel()
channel.queue_declare(queue="queue1", durable=True)
# durable=True 持久化队列
def callback(ch, method, properties, body):
print("recv:", body) # callback 回调函数
#ch.basic_ack(delivery_tag=method.delivery_tag) # 跟producer手动确认 如果没有这一句的话,之前的消息就全部没有确认,consumer断开队列就会发给下一个consumer
# 消费管道中的queue1队列
channel.basic_consume(callback,
queue="queue1",
#no_ack=True
) # no acknowledgement 没有确认
# 如果no_ack 没有加,消息会轮询发送给consumer(启动多个)a消息发给C1,b消息发给C2,c消息发给C1 这样的顺序
channel.start_consuming()
# 轮询机制 按顺序发给多个consumer启动项
消息持久化其实是为了在服务器或者客户端down了的情况下,我们可以让队列,消息强制的持久化的一种解决方式或手段。
这里放一个service ,
# D:\\Program Files\\RabbitMQ Server\\rabbitmq_server-3.6.12\\sbin
备注一下可能会有点乱,但是总结下来就是
1.如果no_ack=True,有A,B2个consumer的时候,会A接收一条,B接收一条,轮询下去。A断开消息不会传给B,轮询是一直存在的。
2.如果no_ack=False,有A,B2个consumer的时候,也还是A接收一条,B接收一条,轮询下去。但是如果A断了,A所有的接收信息其实都没有确认,会全部传给B
3.原方法basic_consume里面是no_ack=False,表示不需要确认消息。
4.当然了,我们可以手动确认一下,语法ch.basic_ack(delivery_tag=method.delivery_tag)
广播模式
消息公平分发
首先,如果rabbitMQ只管按顺序把消息发给各个消费者身上,而不考虑消费者的负载均衡,很可能出现这样一个状况,有一台配置不高的机器上面会堆积很多的消息处理不完,而配置很高的那一台处理起来则很轻松,闲置了机器。为解决这类问题,可以在各个consumer 加上这样一句话,perfetch=1 ,意思就是告诉RabbitMQ,消息还没有处理完,暂时不要发消息给我了。
channel.basic_qos(prefetch_count=1)
将这句话加在channel.basic_consume(*****)之前就好了。
消息发布与订阅
之前的例子基本都是1对1的消息发送,这时候你想要玩一个广播型的一对多,即消息发送到指定的queue,但是消息能被所以的queue收到。类似广播效果,这时候就要用到exchange了。
Exchange在定义的时候是有类型的,用来决定到底哪些queue是符合条件的,可以接收消息。
fanout:所有bind到此exchange的queue都可以接收消息
direct:通过routingkey和exchange决定的那个唯一的queue可以接收消息
topic:所有符合routingKey的routingkey所绑定的queue可以接收消息
表达式符号说明:
#代表一个或多个字符,*代表任何字符
例:#.a会匹配a.a,aasdqwda.a等等
*.a会匹配a.a,1.a,6.a等
注:使用RoutingKey为#,Exchange Type为Topic的时候相当于使用fanout, headers:通过headers来决定把消息发给哪些queue
fanout
消息发布者:
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters(host="localhost")
)
channel = connection.channel()
channel.exchange_declare(exchange="logs",
exchange_type="fanout")
# 广播模式,发送给所有接收者
msg = "hello, this is from fanout | random msg ........"
channel.basic_publish(exchange="logs",
routing_key="",
body=msg)
print("Producer Send %s" % msg)
connection.close()
消息接收者:
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters(host="localhost")
) # 实例化 声明一个连接
channel = connection.channel() # 实例化,声明一个管道
channel.exchange_declare(exchange="logs",
exchange_type="fanout")
result = channel.queue_declare(exclusive=True) # 根据管道生成一个队列随机数名称
queue_name = result.method.queue # 获取对列名
print("random queue name: ",queue_name)
channel.queue_bind(exchange="logs",
queue= queue_name) # 绑定管道
print("waiting for test1...")
def callback(ch, method, properties, body):
print("body: ", body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
有选择的接收消息direct(exchange_type=direct)
RabbitMQ还支持根据关键字发送,即队列绑定关键字,发送者将根据关键字发送消息到exchange,exchange根据关键字判断发给指定的队列。
direct发送:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel = connection.channel()
channel.exchange_declare(exchange="direct_log",
exchange_type="direct")
security = "error"
msg = "this is from info security."
channel.basic_publish(exchange="direct_log",
routing_key=security,
body= msg)
print("send from %s: %s".center(60,"-") %(security, msg))
connection.close()
direct消息接收:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost")) # 创建连接
channel = connection.channel() # 实例化管道
channel.exchange_declare(exchange="direct_log",
exchange_type="direct")
result = channel.queue_declare(exclusive=True) # 实例化出一个随机队列
queue_name = result.method.queue # 获取队列名
severities = ["info","error"]
# 循环绑定特定队列
for severity in severities:
channel.queue_bind(exchange="direct_log",
queue=queue_name,
routing_key=severity)
print("\\033[31;1mdirect_consumer is waiting for msg.\\033[0m")
def callback(ch, method, properties, body):
print("%s: %s" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
# 有点像logging的等级级别对吧。。。
更细致的消息过滤topic
类别名称,细致搜索接收,过滤,#接收所有;举个例子
发送端
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel = connection.channel()
channel.exchange_declare(exchange="topic_log",
exchange_type="topic")
routing_key = sys.argv[1] if len(sys.argv)>1 else "anonymous.info" #可以查一下argv的用法。
mes = " ".join(sys.argv[2:]) or "hellp world !"
channel.basic_publish(exchange="topic_log",
routing_key=routing_key,
body=mes)
print("send %s: %s".center(50, "-") % (routing_key, mes))
connection.close()
接收端
import pika
import sys
connection = pika.BlockingConnection(
pika.ConnectionParameters("localhost")
)
channel = connection.channel()
channel.exchange_declare(exchange="topic_log",
exchange_type="topic")
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s[binding_key]...\\n" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange="topic_log",
queue= queue_name,
routing_key=binding_key)
print("\\033[31;1mConsume is waiting for information...\\033[0m")
def callback(ch, method, properties,body):
print("%s: %s" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
Remote Procedure Call (RPC)
To illustrate how an RPC service could be used we‘re going to create a simple client class. It‘s going to expose a method named call which sends an RPC request and blocks until the answer is received:
1 fibonacci_rpc = FibonacciRpcClient() 2 result = fibonacci_rpc.call(4) 3 print("fib(4) is %r" % result)
RPC Server
#!/user/bin/env python
# -*-coding: utf-8-*-
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel = connection.channel()
channel.queue_declare(queue="rpc_queue")
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def on_request(ch, method, props, body):
n = int(body)
print("fib[%s]" % n)
response = fib(n)
ch.basic_publish(exchange="",
routing_key=props.reply_to, # 返回给哪个消息队列
properties=pika.BasicProperties(correlation_id=props.correlation_id), # 将传过来的uuid回传确认
body=str(response))
ch.basic_ack(delivery_tag=method.delivery_tag) # 手动确认
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue="rpc_queue")
print("waiting for RPC request")
channel.start_consuming() # 开始消费队列消息,并发布新的消息给队列
RPC Client:
import pika,uuid
class FibonacciRpcClient(object):
def __init__(self):
"""构造函数中实现实例化连接,管道,随机队列"""
self.connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
self.channel = self.connection.channel()
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue # 将随机队列名赋值给callback_queue
self.channel.basic_consume(self.on_response,
no_ack=True,
queue=self.callback_queue) # 定义预消费,等待start
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id: # 判断uuid是否一致,有点像验证文件传输后的md5值
self.response = body
def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4()) # 生成一个验证用的uuid
self.channel.basic_publish(exchange="",
routing_key="rpc_queue",
properties=pika.BasicProperties( # properties里面传了2个参数,定义一个返回队列,给一个标记的返回ID
reply_to=self.callback_queue,
correlation_id= self.corr_id,),
body=str(n))
while self.response is None:
self.connection.process_data_events() # 这边其实就是start consuming...发送数据出去了。
return int(self.response)
fibo = FibonacciRpcClient() # 实例化类
print("Requesting 30")
response = fibo.call(7) # 调用call方法
print("server response:", response)
实际上来说就是实现了2端通信,A发送信息给B,B接收处理了再回传给A。
缓存数据库介绍
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,泛指非关系型的数据库,随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
NoSQL数据库的四大分类
NoSQL数据库的四大分类表格分析
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value)[3] | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。[3] | Key 指向 Value 的键值对,通常用hash table来实现[3] | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据[3] |
| 列存储数据库[3] | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库[3] | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库[3] | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。[3] |
Redis
介绍
redis是业界主流的key-value nosql 数据库之一。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis优点
-
异常快速 : Redis是非常快的,每秒可以执行大约110000设置操作,81000个/每秒的读取操作。
-
支持丰富的数据类型 : Redis支持最大多数开发人员已经知道如列表,集合,可排序集合,哈希等数据类型。
这使得在应用中很容易解决的各种问题,因为我们知道哪些问题处理使用哪种数据类型更好解决。 -
操作都是原子的 : 所有 Redis 的操作都是原子,从而确保当两个客户同时访问 Redis 服务器得到的是更新后的值(最新值)。
-
MultiUtility工具:Redis是一个多功能实用工具,可以在很多如:缓存,消息传递队列中使用(Redis原生支持发布/订阅),在应用程序中,如:Web应用程序会话,网站页面点击数等任何短暂的数据;
安装Redis环境
$sudo apt-get update $sudo apt-get install redis-server
启动 Redis
$redis-server
查看 redis 是否还在运行
$redis-cli
redis 127.0.0.1:6379>
redis 127.0.0.1:6379> ping PONG
Python操作Redis
1 sudo pip install redis 2 or 3 sudo easy_install redis 4 or 5 源码安装 6 7 详见:https://github.com/WoLpH/redis-py
在Ubuntu上安装Redis桌面管理器
要在Ubuntu 上安装 Redis桌面管理,可以从 http://redisdesktop.com/download 下载包并安装它。
Redis API使用
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
连接方式
1,操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
import redis r = redis.Redis(host=‘10.211.55.4‘, port=6379) r.set(‘foo‘, ‘Bar‘) print r.get(‘foo‘)
2,连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
操作
1,string操作
redis中的string在内存中按照一个name对应一个value来存储。
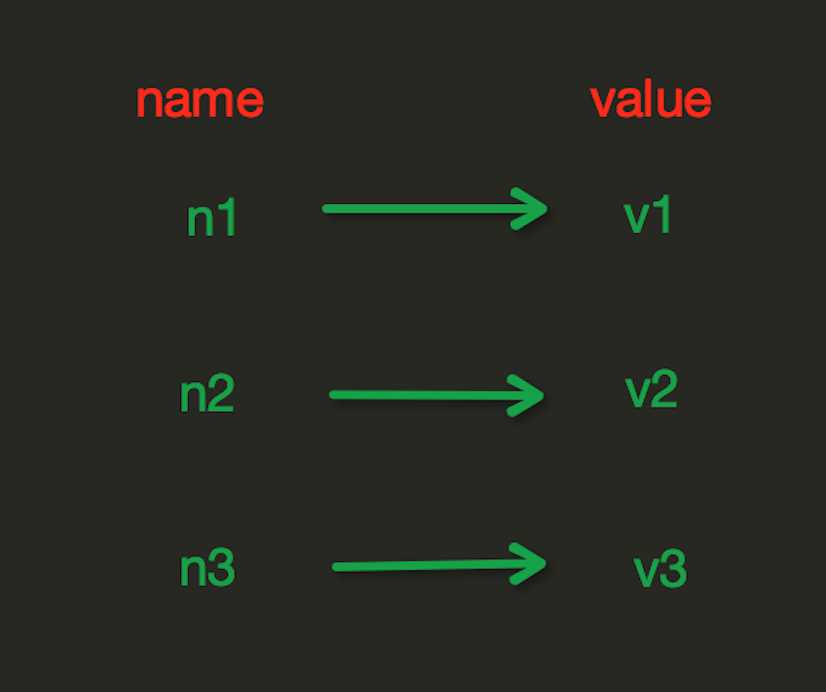
set(name, value, ex=None, px=None, nx=False, xx=False) 在redis中设置值,默认是不存在则创建,存在则修改。
参数:ex,过期时间(秒)
px,过期时间(毫秒) nx,如果设置为True,则只有name不存在时,当前set操作才执行 xx,如果设置为True,则只有name存在时,当前set操作才执行setnx(name, value)
设置值,只有name不存在时才执行设置操作
setex(name, value, time)
# 设置值 # 参数: # time,过期时间(数字秒 或 timedelta对象)psetex(name, time_ms, value)
# 设置值 # 参数: # time_ms,过期时间(数字毫秒 或 timedelta对象)mset(*args, **kwargs)
批量设置值 如: mset(k1=‘v1‘, k2=‘v2‘) 或 mget({‘k1‘: ‘v1‘, ‘k2‘: ‘v2‘})
get(name) # 获取值
mget(keys, *args)
批量获取 如: mget(‘ylr‘, ‘wupeiqi‘) 或 r.mget([‘ylr‘, ‘wupeiqi‘])
getset(name, value) # 设置新的值并获取出原来的值
getrange(key, start, end)
# 获取子序列(根据字节获取,非字符) # 参数: # name,Redis 的 name # start,起始位置(字节) # end,结束位置(字节) # 如: "dandy" ,0-1表示 "da"
setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加) # 参数: # offset,字符串的索引,字节(一个汉字三个字节) # value,要设置的值
setbit(name, offset, value)
# 对name对应值的二进制表示的位进行操作 # 参数: # name,redis的name # offset,位的索引(将值变换成二进制后再进行索引) # value,值只能是 1 或 0 # 注:如果在Redis中有一个对应: n1 = "foo", 那么字符串foo的二进制表示为:01100110 01101111 01101111 所以,如果执行 setbit(‘n1‘, 7, 1),则就会将第7位设置为1, 那么最终二进制则变成 01100111 01101111 01101111,即:"goo" # 扩展,转换二进制表示: # source = "海贼王" source = "foo" for i in source: num = ord(i) print bin(num).replace(‘b‘,‘‘) 特别的,如果source是汉字 "海贼王"怎么办? 答:对于utf-8,每一个汉字占 3 个字节,那么 "海贼王" 则有 9个字节 对于汉字,for循环时候会按照 字节 迭代,那么在迭代时,将每一个字节转换 十进制数,然后再将十进制数转换成二进制 11100110 10101101 10100110 11100110 10110010 10011011 11101001 10111101 10010000
getbit(name, offset) # 获取name对应的值的二进制表示中的某位的值(0或者1)
bitcount(key, start=None, end=None)
# 获取name对应的值的二进制表示中 1 的个数 # 参数: # key,Redis的name # start,位起始位置 # end,位结束位置
strlen(name) # 返回name对应值的字节长度(汉字三个字节)
incr(self, name, amount=1)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 # 参数: # name,Redis的name # amount,自增数(必须是整数) # 注:同incrby
incrbyfloat(self, name, amount=1.0)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 # 参数: # name,Redis的name # amount,自增数(浮点型)
decr(self, name, amount=1) # 跟incr 差不多,不过是自减。
append(key, value)
# 在redis name对应的值后面追加内容 # 参数: key, redis的name value, 要追加的字符串
来波xshell:(redis-cli)
127.0.0.1:6379> set name dandy OK 127.0.0.1:6379> getrange name 0 1 "da" 127.0.0.1:6379> setrange name 4 renee (integer) 9 127.0.0.1:6379> get name "dandrenee" 127.0.0.1:6379> get name "dandrenee" 127.0.0.1:6379> incr login_users (integer) 1 127.0.0.1:6379> incr login_users (integer) 2 127.0.0.1:6379> incr login_users (integer) 3 127.0.0.1:6379> incr login_users (integer) 4 127.0.0.1:6379> decr login_users (integer) 3 127.0.0.1:6379> decr login_users (integer) 2 127.0.0.1:6379> decr login_users (integer) 1 127.0.0.1:6379> decr login_users (integer) 0 127.0.0.1:6379> append name appendtest (integer) 19 127.0.0.1:6379> get name "dandreneeappendtest"
2,Hash操作
hash表现形式上有些像pyhton中的dict,可以存储一组关联性较强的数据 , redis中Hash在内存中的存储格式如下图:
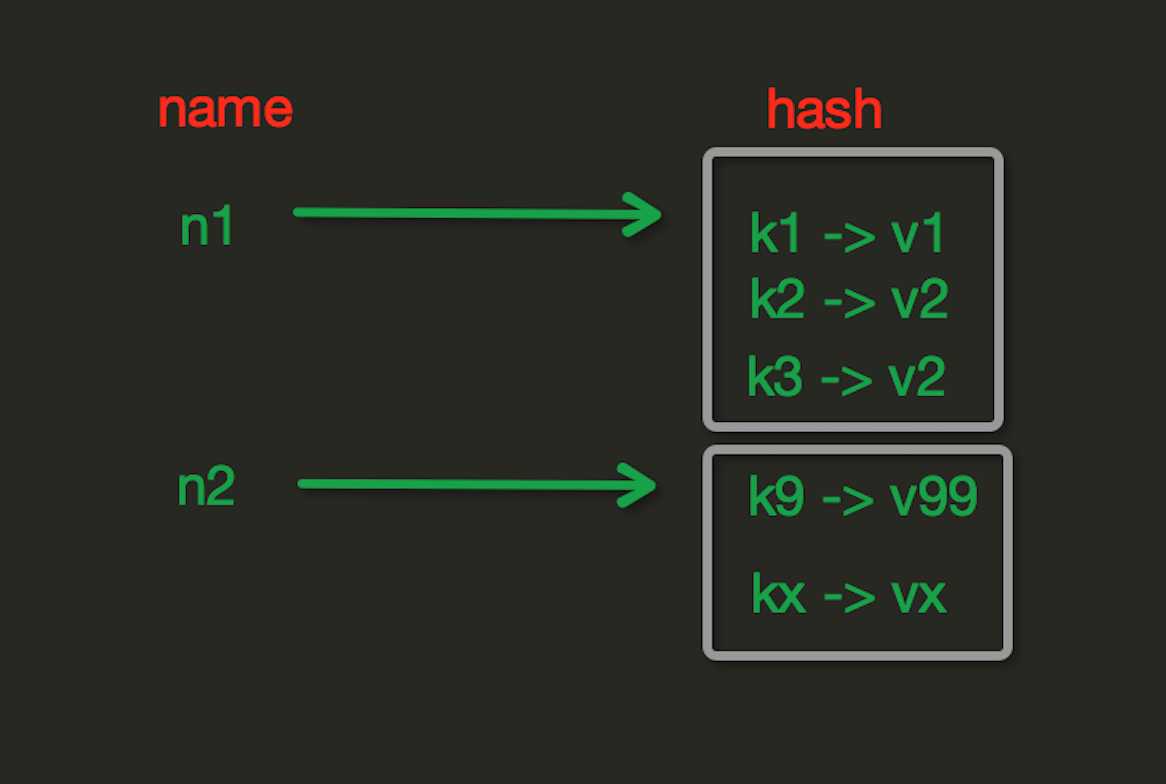
有点类似与字典的操作:
hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改) # 参数: # name,redis的name # key,name对应的hash中的key # value,name对应的hash中的value # 注: # hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name, mapping)
# 在name对应的hash中批量设置键值对
# 参数:
# name,redis的name
# mapping,字典,如:{‘k1‘:‘v1‘, ‘k2‘: ‘v2‘}
# 如:
# r.hmset(‘xx‘, {‘k1‘:‘v1‘, ‘k2‘: ‘v2‘})
hget(name,key) # 在hash,即这个字典里获取key的value
hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值 # 参数: # name,reids对应的name # keys,要获取key集合,如:[‘k1‘, ‘k2‘, ‘k3‘] # *args,要获取的key,如:k1,k2,k3 # 如: # r.mget(‘xx‘, [‘k1‘, ‘k2‘]) # 或 # print r.hmget(‘xx‘, ‘k1‘, ‘k2‘)
hgetall(name) # 获取name对应hash的所有键值
hlen(name) # 获取name对应的hash中键值队的个数
hkeys(name) # 获取name对应的hash中所有的key值
hvals(name) # 获取name对应的hash中所有的value的值
hexists(name,key) # 检查name对应的hash是否存在当前传入的key
hdel(name,*keys) # 将那么对应的hash中指定的key键值对删除
hincrby(name, key, count=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount # 参数: # name,redis中的name # key, hash对应的key # amount,自增数(整数)
hincrbyfloat(name, key, amount=1.0) # 跟上面的差不多只是不仅仅加整数
hscan(name, cursor=0, match=None, count=None)
Start a full hash scan with:
HSCAN myhash 0
Start a hash scan with fields matching a pattern with:
HSCAN myhash 0 MATCH order_*
Start a hash scan with fields matching a pattern and forcing the scan command to do more scanning with:
HSCAN myhash 0 MATCH order_* COUNT 1000
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
# 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# 第一次:cursor1, data1 = r.hscan(‘xx‘, cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan(‘xx‘, cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
# 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# for item in r.hscan_iter(‘xx‘):
# print item
实例:
127.0.0.1:6379> hset dict name dandy (integer) 0 127.0.0.1:6379> hget dict name "dandy" 127.0.0.1:6379> hmset dict sex man school oldboy OK 127.0.0.1:6379> hget dict (error) ERR wrong number of arguments for ‘hget‘ command 127.0.0.1:6379> hmget dict name sex school 1) "dandy" 2) "man" 3) "oldboy" 127.0.0.1:6379> hgetall dict 1) "name" 2) "dandy" 3) "sex" 4) "man" 5) "school" 6) "oldboy" 127.0.0.1:6379> hlen dict (integer) 3 127.0.0.1:6379> hkeys dict 1) "name" 2) "sex" 3) "school" 127.0.0.1:6379> hvals dict 1) "dandy" 2) "man" 3) "oldboy" 127.0.0.1:6379> hexists dict aaa (integer) 0 127.0.0.1:6379> hexists dict name (integer) 1 127.0.0.1:6379> hdel dict name (integer) 1 127.0.0.1:6379> hgetall dict 1) "sex" 2) "man" 3) "school" 4) "oldboy"
127.0.0.1:6379> hincrby dict name 1
(integer) 1
127.0.0.1:6379> hgetall dict
1) "sex"
2) "man"
3) "school"
4) "oldboy"
5) "name"
6) "1"
127.0.0.1:6379> hincrby dict name
(error) ERR wrong number of arguments for ‘hincrby‘ command
127.0.0.1:6379> hincrby dict name 1
(integer) 2
127.0.0.1:6379> hincrby dict name 11
(integer) 13
127.0.0.1:6379> hgetall dict
1) "sex"
2) "man"
3) "school"
4) "oldboy"
5) "name"
6) "13"
127.0.0.1:6379> hscan dict 0 match n*
1) "0"
2) 1) "name"
2) "dandy"
3,List
List操作,redis中的list在内存中是按照一个name对应一个list来存储的。如图:
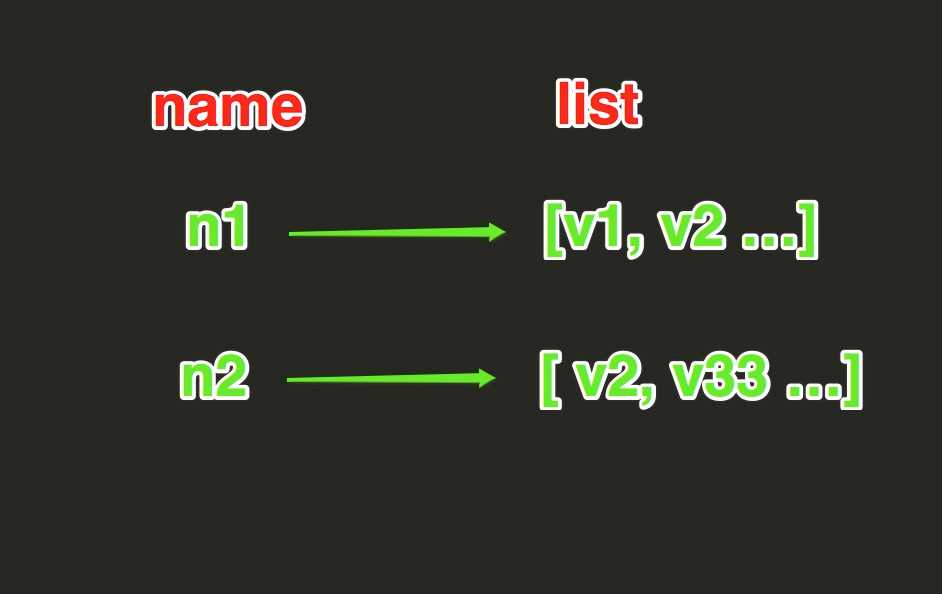
lpush(name, values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边
# 如:
# r.lpush(‘oo‘, 11,22,33)
# 保存顺序为: 33,22,11
# 扩展:
# rpush(name, values) 表示从右向左操作
lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
# 更多:
# rpushx(name, value) 表示从右向左操作
llen(name) # name对应的list元素的个数
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值
# 参数:
# name,redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据
r.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值
# 参数:
# name,redis的name
# index,list的索引位置
# value,要设置的值
r.lrem(name, value, num)
# 在name对应的list中删除指定的值
# 参数:
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
# 更多:
# rpop(name) 表示从右向左操作
lindex(name, index)
# 在name对应的列表中根据索引获取列表元素
lrange(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
# 参数:
# src,要取数据的列表的name
# dst,要添加数据的列表的name
ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
blpop(keys, timeout)
# 将多个列表排列,按照从左到右去pop对应列表的元素
# 参数:
# keys,redis的name的集合
# timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
# 更多:
# r.brpop(keys, timeout),从右向左获取数据
brpoplpush(src, dst, timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
# 参数:
# src,取出并要移除元素的列表对应的name
# dst,要插入元素的列表对应的name
# timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞


1 127.0.0.1:6379> lpush list 11 22 33 2 (integer) 3 3 127.0.0.1:6379> llen list 4 (integer) 3 5 127.0.0.1:6379> linsert list before 22 17.5 6 (integer) 4 7 127.0.0.1:6379> lrange list 0 -1 8 1) "33" 9 2) "17.5" 10 3) "22" 11 4) "11" 12 127.0.0.1:6379> lset list 2 23 13 OK 14 127.0.0.1:6379> lrange list 0 -1 15 1) "33" 16 2) "17.5" 17 3) "23" 18 4) "11" 19 127.0.0.1:6379> lrem list 11 2 20 (integer) 0 21 127.0.0.1:6379> lrange list 0 -1 22 1) "33" 23 2) "17.5" 24 3) "23" 25 4) "11" 26 127.0.0.1:6379> lrem list 11 1 27 (integer) 0 28 127.0.0.1:6379> lrange list 0 -1 29 1) "33" 30 2) "17.5" 31 3) "23" 32 4) "11" 33 127.0.0.1:6379> lrem list 11 34 (error) ERR wrong number of arguments for ‘lrem‘ command 35 127.0.0.1:6379> lrem list 11 0 36 (integer) 0 37 127.0.0.1:6379> lrange list 0 -1 38 1) "33" 39 2) "17.5" 40 3) "23" 41 4) "11" 42 127.0.0.1:6379> lrem list 1 1 43 (integer) 0 44 127.0.0.1:6379> lrange list 0 -1 45 1) "33" 46 2) "17.5" 47 3) "23" 48 4) "11" 49 127.0.0.1:6379> help lrem 50 51 LREM key count value 52 summary: Remove elements from a list 53 since: 1.0.0 54 group: list 55 56 127.0.0.1:6379> lrem list 2 11 57 (integer) 1 58 127.0.0.1:6379> lrange list 0 -1 59 1) "33" 60 2) "17.5" 61 3) "23" 62 127.0.0.1:6379> lpush list 44 63 (integer) 4 64 127.0.0.1:6379> lrange list 0 -1 65 1) "44" 66 2) "33" 67 3) "17.5" 68 4) "23" 69 127.0.0.1:6379> lpop list 70 "44" 71 127.0.0.1:6379> lrange list 0 -1 72 1) "33" 73 2) "17.5" 74 3) "23" 75 127.0.0.1:6379> lindex list 1 76 "17.5" 77 127.0.0.1:6379> lpush list2 1.1 2.2 3.3 4.4 78 (integer) 4 79 127.0.0.1:6379> rpoplpush list list2 80 "23" 81 127.0.0.1:6379> lrange list 0 -1 82 1) "33" 83 2) "17.5" 84 127.0.0.1:6379> lrange list2 0 -1 85 1) "23" 86 2) "4.4" 87 3) "3.3" 88 4) "2.2" 89 5) "1.1" 90 127.0.0.1:6379> ltrim list2 1 2 91 OK 92 127.0.0.1:6379> lrange list2 0 -1 93 1) "4.4" 94 2) "3.3" 95 127.0.0.1:6379> blpop list2 3.3 3 96 1) "list2" 97 2) "4.4" 98 127.0.0.1:6379> blpop list2 3.3 100 99 1) "list2" 100 2) "3.3" 101 127.0.0.1:6379> blpop list2 3.3 100 102 1) "list2" 103 2) "4.4" 104 (18.32s) 105 127.0.0.1:6379> lrange list2 0 -1 106 1) "3.3" 107 127.0.0.1:6379> lrange list 0 -1 108 1) "33" 109 2) "17.5" 110 127.0.0.1:6379> brpoplpush list2 list 0 111 "3.3" 112 127.0.0.1:6379> brpoplpush list list2 0 113 "17.5"
4,set集合操作
set操作,set集合不允许重复列表
sadd(name,values) # name对应的集合中添加元素
scard(name) # 获取name对应的集合中元素个数
sdiff(keys, *args) # 在第一个name对应的集合中且不在其他name对应的集合的元素集合
sdiffstore(dest,keys,*args)
# 获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
sinter(keys, *args)# 获取多个name对应集合的并集
sinterstore(dest, keys, *args)
# 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
sismember(name, value)
# 检查value是否是name对应的集合的成员
smember(name) # 获取name对应的集合的所有成员
smove(src, dst, value)
# 将某个成员从一个集合中移动到另外一个集合
spop(name)
# 从集合的右侧(尾部)移除一个成员,并将其返回
srandmember(name, numbers)
# 从name对应的集合中随机获取 numbers 个元素
srem(name, values)
# 在name对应的集合中删除某些值
sunion(keys, *args)
# 获取多一个name对应的集合的并集
sunionstore(dest,keys, *args)
# 获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
sscan(name, cursor=0, match=None, count=None)
sscan_iter(name, match=None, count=None)
# 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
1 127.0.0.1:6379> sadd set1 11 11 22 33 33 44 55 44 2 (integer) 5 3 127.0.0.1:6379> scard set1 4 (integer) 5 5 127.0.0.1:6379> sadd set2 11 22 34 45 56 56 6 (integer) 5 7 127.0.0.1:6379> sdiff set1 set2 8 1) "33" 9 2) "44" 10 3) "55" 11 127.0.0.1:6379> sdiffstore set111 set1 set2 12 (integer) 3 13 127.0.0.1:6379> sinter set1 set2 14 1) "11" 15 2) "22" 16 127.0.0.1:6379> sismember set1 100 17 (integer) 0 18 127.0.0.1:6379> smove set1 set2 55 19 (integer) 1 20 127.0.0.1:6379> smember set1 21 (error) ERR unknown command ‘smember‘ 22 127.0.0.1:6379> smembers set1 23 1) "11" 24 2) "22" 25 3) "33" 26 4) "44" 27 127.0.0.1:6379> smembers set2 28 1) "11" 29 2) "22" 30 3) "34" 31 4) "45" 32 5) "55" 33 6) "56" 34 127.0.0.1:6379> spop set2 35 "56" 36 127.0.0.1:6379> srandmember set2 2 37 1) "34" 38 2) "22" 39 127.0.0.1:6379> smembers set2 40 1) "11" 41 2) "22" 42 3) "34" 43 4) "45" 44 5) "55" 45 127.0.0.1:6379> srem set2 11 22 46 (integer) 2 47 127.0.0.1:6379> smembers set2 48 1) "34" 49 2) "45" 50 3) "55" 51 127.0.0.1:6379> smembers set1 52 1) "11" 53 2) "22" 54 3) "33" 55 4) "44" 56 127.0.0.1:6379> sadd set1 34 57 (integer) 1 58 127.0.0.1:6379> sunion set1 set2 59 1) "11" 60 2) "22" 61 3) "33" 62 4) "34" 63 5) "44" 64 6) "45" 65 7) "55"
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素
# 如:
# zadd(‘zz‘, ‘n1‘, 1, ‘n2‘, 2)
# 或
# zadd(‘zz‘, n1=11, n2=22)
zcard(name)
# 获取name对应的有序集合元素的数量
zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数
zincrby(name, value, amount)
# 自增name对应的有序集合的 name 对应的分数
r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素
# 参数:
# name,redis的name
# start,有序集合索引起始位置(非分数)
# end,有序集合索引结束位置(非分数)
# desc,排序规则,默认按照分数从小到大排序
# withscores,是否获取元素的分数,默认只获取元素的值
# score_cast_func,对分数进行数据转换的函数
# 更多:
# 从大到小排序
# zrevrange(name, start, end, withscores=False, score_cast_func=float)
# 按照分数范围获取name对应的有序集合的元素
# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)
# 从大到小排序
# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始)
# 更多:
# zrevrank(name, value),从大到小排序
zrem(name, values)
# 删除name对应的有序集合中值是values的成员 # 如:zrem(‘zz‘, [‘s1‘, ‘s2‘])
zremrangebyrank(name, min, max)
# 根据排行范围删除
zremrangebyscore(name, min, max)
# 根据分数范围删除
zscore(name, value)
# 获取name对应有序集合中 value 对应的分数
zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作 # aggregate的值为: SUM MIN MAX
zunionstore(dest, keys, aggregate=None)
# 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作 # aggregate的值为: SUM MIN MAX
zscan(name, cursor=0, match=None, count=None, score_cast_func=float)
zscan_iter(name, match=None, count=None,score_cast_func=float)
# 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
1 127.0.0.1:6379> zadd z1 n1 10 n2 20 n3 30 2 (error) ERR value is not a valid float 3 127.0.0.1:6379> zadd z1 10 n1 20 n2 4 (integer) 2 5 127.0.0.1:6379> zadd z1 30 n4 40 n6 6 (integer) 2 7 127.0.0.1:6379> zcard z1 8 (integer) 4 9 127.0.0.1:6379> zcount z1 10 50 10 (integer) 4 11 127.0.0.1:6379> zcount z1 10 20 12 (integer) 2 13 127.0.0.1:6379> zincrby z2 x1 10 14 (error) ERR value is not a valid float 15 127.0.0.1:6379> zincrby z2 10 x1 16 "10" 17 127.0.0.1:6379> zincrby z2 10 x2 18 "10" 19 127.0.0.1:6379> zrange z2 0 -1 20 1) "x1" 21 2) "x2" 22 127.0.0.1:6379> zrank z2 x1 23 (integer) 0 24 127.0.0.1:6379> zrank z2 x2 25 (integer) 1 26 127.0.0.1:6379> zrem z2 x1 27 (integer) 1 28 127.0.0.1:6379> zrange 0 -1 29 (error) ERR wrong number of arguments for ‘zrange‘ command 30 127.0.0.1:6379> zrange z2 0 -1 31 1) "x2" 32 127.0.0.1:6379> zscore x2 33 (error) ERR wrong number of arguments for ‘zscore‘ command 34 127.0.0.1:6379> zscore z2 x2 35 "10" 36 127.0.0.1:6379> zadd z11 10 n1 20 n2 30 n3 37 (integer) 3 38 127.0.0.1:6379> zadd z22 10 n1 19 n2 30 n4 39 (integer) 3 40 41 127.0.0.1:6379> zinterstore z33 z11 z22 SUM 42 (error) ERR value is not an integer or out of range 43 127.0.0.1:6379> 44 127.0.0.1:6379> 45 127.0.0.1:6379> zdd z1 10 dandy 99 renee 50 taylor 46 (error) ERR unknown command ‘zdd‘ 47 127.0.0.1:6379> zadd z1 10 dandy 99 renee 50 taylor 48 (integer) 3 49 127.0.0.1:6379> zadd z2 20 dandy 91 renee 90 taylor 50 (integer) 3 51 127.0.0.1:6379> zinterstore z3 2 z1 z2 52 (integer) 3 53 127.0.0.1:6379> zrange z1 0 -1 withscore 54 (error) ERR syntax error 55 127.0.0.1:6379> zrange z1 0 -1 withscores 56 1) "dandy" 57 2) "10" 58 3) "n1" 59 4) "10" 60 5) "n2" 61 6) "20" 62 7) "n4" 63 8) "30" 64 9) "n6" 65 10) "40" 66 11) "taylor" 67 12) "50" 68 13) "renee" 69 14) "99" 70 127.0.0.1:6379> zrange z2 withscores 71 (error) ERR wrong number of arguments for ‘zrange‘ command 72 127.0.0.1:6379> zrange z2 0 -1 withscores 73 1) "x2" 74 2) "10" 75 3) "dandy" 76 4) "20" 77 5) "taylor" 78 6) "90" 79 7) "renee" 80 8) "91" 81 127.0.0.1:6379> zrange z3 0 -1 withscores 82 1) "dandy" 83 2) "30" 84 3) "taylor" 85 4) "140" 86 5) "renee" 87 6) "190"
其他操作
delete(*names)
# 根据删除redis中的任意数据类型 del z22
exists(name)
# 检测redis的name是否存在
keys(pattern=‘*‘)
# 根据模型获取redis的name
# 更多:
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
expire(name ,time)
# 为某个redis的某个name设置超时时间
rename(src, dst)
# 对redis的name重命名为
move(name, db)
# 将redis的某个值移动到指定的db下 16个DB 0~15
randomkey()
# 随机获取一个redis的name(不删除)
type(name)
# 获取name对应值的类型
scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None)
# 同字符串操作,用于增量迭代获取key
管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
import redis pool = redis.ConnectionPool(host=‘10.211.55.4‘, port=6379) r = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False) pipe = r.pipeline(transaction=True) pipe.set(‘name‘, ‘dandy‘) pipe.set(‘role‘, ‘hero‘) pipe.execute()
发布订阅

Demo:
1 import redis 2 class RedisHelper: 3 def __init__(self): 4 self.__conn = redis.Redis(host="192.168.85.100") 5 self.chan_sub = "fm104.5" 6 self.chan_pub = "fm104.5" 7 8 def public(self,msg): 9 self.__conn.publish(self.chan_pub, msg) 10 return True 11 def subscribe(self): 12 pub = self.__conn.pubsub() 13 pub.subscribe(self.chan_sub) 14 pub.parse_response() 15 return pub
订阅:
from monitor.RedisHelper import RedisHelper
obj = RedisHelper()
redis_sub = obj.subscribe()
while True:
msg= redis_sub.parse_response()
print(msg)
发布者
from monitor.RedisHelper import RedisHelper obj = RedisHelper() obj.public(‘hello‘)
更多:
https://github.com/andymccurdy/redis-py/
http://doc.redisfans.com/
以上是关于Python11 RabbitMQ Redis的主要内容,如果未能解决你的问题,请参考以下文章