skywalking插件工作原理剖析
Posted wind-wound
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了skywalking插件工作原理剖析相关的知识,希望对你有一定的参考价值。
1. 官方插件二次开发
前面在介绍
skywalking-agent目录时,提到了它有一个插件目录,并支持动态的开发插件。其实skywalking默认已经提供大部分框架的插件了,一般情况下不需要额外开发新的插件,可以直接改造已有的插件,使其适配自己的业务。下面介绍如何二次开发SpringMVC插件以采集业务参数。
(1)下载插件源码
在skywalking 8.7.0及以前的版本,插件的源码是直接放在skywalking主项目中的。在8.7.0以后的版本,把插件移出去了。(这一点好坑,我在skywalking最新版本里找了好久没找到插件的源码)。
下面分析的源码来自于skywalking 8.7.0版本。
-
插件源码位置:skywalking/apm-sniffer/apm-sdk-plugin(下面有个spring-plugins目录,里面就是spring相关的插件)
由于我的项目中用的SpringMVC是5.x的版本,因此主要关注下图中标记的两个目录。

顺便提一句skywalking 8.7.0以后版本的源码:
- URL:https://github.com/apache/skywalking-java
- 插件源码位置:skywalking-java/apm-sniffer/apm-sdk-plugin
(2)由SpringMVC插件窥探整个框架
① SpringMVC插件模块一览

一眼看过去,眼前一黑。仔细看就会发现,这里面的类主要分两大类,以Instrumentation和Interceptor结尾。Interceptor结尾的一般是拦截器,熟悉java agent技术的同学一般会知道Instrumentation,这个其实就是agent技术中的核心类,它可以加载Class文件,甚至可以修改Class文件。
我们发现有两个类名比较熟悉:ControllerInstrumentation和RestControllerInstrumentation,Controller和RestController就是SpringMVC中常用的两个注解,本项目中使用的是RestController注解,就以此类为入口吧。
这里不对java agent对额外的说明了,想要看懂skywalking框架,必须要先了解java agent。
② RestControllerInstrumentation类源码
public class RestControllerInstrumentation extends AbstractControllerInstrumentation
// 这玩意就是RestController注解
public static final String ENHANCE_ANNOTATION = "org.springframework.web.bind.annotation.RestController";
@Override
protected String[] getEnhanceAnnotations()
return new String[] ENHANCE_ANNOTATION;
可以发现,ENHANCE_ANNOTATION这个属性的值就是SpringMVC中那个注解类。enhance是增强的意思,很好理解,这里就是要增强RestController注解的功能。看下getEnhanceAnnotations()方法在哪里被调用了。
③ AbstractControllerInstrumentation类源码
AbstractControllerInstrumentation类是RestControllerInstrumentation的父类,在enhanceClass()方法中调用了getEnhanceAnnotations()方法。这样就串起来了,这里实际上就是增强了被RestController注解修饰的类的功能。那么到底是怎么增强的呢?
public abstract class AbstractControllerInstrumentation extends AbstractSpring5Instrumentation
@Override
public ConstructorInterceptPoint[] getConstructorsInterceptPoints() // 忽略
@Override
public InstanceMethodsInterceptPoint[] getInstanceMethodsInterceptPoints()
// 这里声明了方法切入点,返回的是一个数组,说明可以有多个切入点
return new InstanceMethodsInterceptPoint[]
new DeclaredInstanceMethodsInterceptPoint()
@Override
public ElementMatcher<MethodDescription> getMethodsMatcher()
// 这里是被RequestMapping注解的方法作为一个切入点
return byMethodInheritanceAnnotationMatcher(named("org.springframework.web.bind.annotation.RequestMapping"));
@Override
public String getMethodsInterceptor()
// 这里是此切入点的拦截器
return Constants.REQUEST_MAPPING_METHOD_INTERCEPTOR;
@Override
public boolean isOverrideArgs()
return false;
,
new DeclaredInstanceMethodsInterceptPoint()
@Override
public ElementMatcher<MethodDescription> getMethodsMatcher()
// 这里是被GetMapping、PostMapping等注解的方法作为一个切入点
return byMethodInheritanceAnnotationMatcher(named("org.springframework.web.bind.annotation.GetMapping"))
.or(byMethodInheritanceAnnotationMatcher(named("org.springframework.web.bind.annotation.PostMapping")))
.or(byMethodInheritanceAnnotationMatcher(named("org.springframework.web.bind.annotation.PutMapping")))
.or(byMethodInheritanceAnnotationMatcher(named("org.springframework.web.bind.annotation.DeleteMapping")))
.or(byMethodInheritanceAnnotationMatcher(named("org.springframework.web.bind.annotation.PatchMapping")));
@Override
public String getMethodsInterceptor()
// 这里是此切入点的拦截器
return Constants.REST_MAPPING_METHOD_INTERCEPTOR;
@Override
public boolean isOverrideArgs()
return false;
;
@Override
protected ClassMatch enhanceClass()
// 这里是是增强类的功能
return ClassAnnotationMatch.byClassAnnotationMatch(getEnhanceAnnotations());
protected abstract String[] getEnhanceAnnotations();
public class Constants
public static final String REQUEST_MAPPING_METHOD_INTERCEPTOR = "org.apache.skywalking.apm.plugin.spring.mvc.commons.interceptor.RequestMappingMethodInterceptor";
public static final String REST_MAPPING_METHOD_INTERCEPTOR = "org.apache.skywalking.apm.plugin.spring.mvc.commons.interceptor.RestMappingMethodInterceptor";
在getInstanceMethodsInterceptPoints()方法中,可以看到很多熟悉的注解,比如PostMapping。结合一下方法名,可以大胆的推测,这里其实就是定义对象实例方法的拦截切入点。再看下getMethodsInterceptor()方法中使用的两个常量,以REST_MAPPING_METHOD_INTERCEPTOR为例,它的值就是个类名:RestMappingMethodInterceptor,那这个类肯定就是负责增强功能的拦截器。进入这个拦截器瞧瞧。
④ RestMappingMethodInterceptor类源码
// 这里省略了大量的代码
public class RestMappingMethodInterceptor extends AbstractMethodInterceptor
@Override
public String getRequestURL(Method method)
// 这里是从注解中解析请求url
return ParsePathUtil.recursiveParseMethodAnnotation(method, m ->
String requestURL = null;
GetMapping getMapping = AnnotationUtils.getAnnotation(m, GetMapping.class);
if (getMapping != null)
if (getMapping.value().length > 0)
requestURL = getMapping.value()[0];
else if (getMapping.path().length > 0)
requestURL = getMapping.path()[0];
return requestURL;
);
@Override
public String getAcceptedMethodTypes(Method method)
// 这里是从注解中解析请求类型
return ParsePathUtil.recursiveParseMethodAnnotation(method, m ->
if (AnnotationUtils.getAnnotation(m, GetMapping.class) != null)
return "GET";
else
return null;
);
这个类里的两个方法都是工具方法,仅仅解析了请求url和类型。其他的功能实现肯定在它的父类AbstractMethodInterceptor里。
⑤ AbstractMethodInterceptor类源码
// 这里省略了大量的代码,只保留了核心的部分
public abstract class AbstractMethodInterceptor implements InstanceMethodsAroundInterceptor
public abstract String getRequestURL(Method method);
public abstract String getAcceptedMethodTypes(Method method);
@Override
public void beforeMethod(EnhancedInstance objInst, Method method, Object[] allArguments, Class<?>[] argumentsTypes,
MethodInterceptResult result) throws Throwable
// 这是在被切入的方法执行前,要执行的逻辑
Object request = ContextManager.getRuntimeContext().get(REQUEST_KEY_IN_RUNTIME_CONTEXT);
if (request != null)
StackDepth stackDepth = (StackDepth) ContextManager.getRuntimeContext().get(CONTROLLER_METHOD_STACK_DEPTH);
if (stackDepth == null)
final ContextCarrier contextCarrier = new ContextCarrier();
// 如果请求类是继承自servlet-api提供的HttpServletRequest类,则走此方法
if (IN_SERVLET_CONTAINER && HttpServletRequest.class.isAssignableFrom(request.getClass()))
final HttpServletRequest httpServletRequest = (HttpServletRequest) request;
// AbstractSpan是skywalking中日志的一个载体,用于采集数据
AbstractSpan span = ContextManager.createEntrySpan(operationName, contextCarrier);
// 采集请求URL
Tags.URL.set(span, httpServletRequest.getRequestURL().toString());
// 采集请求的类型,如GET、POST
Tags.HTTP.METHOD.set(span, httpServletRequest.getMethod());
// 标记是SpringMVC的日志
span.setComponent(ComponentsDefine.SPRING_MVC_ANNOTATION);
// 标记是HTTP请求
SpanLayer.asHttp(span);
if (SpringMVCPluginConfig.Plugin.SpringMVC.COLLECT_HTTP_PARAMS)
// 采集请求参数
RequestUtil.collectHttpParam(httpServletRequest, span);
if (!CollectionUtil.isEmpty(SpringMVCPluginConfig.Plugin.Http.INCLUDE_HTTP_HEADERS))
// 采集请求头
RequestUtil.collectHttpHeaders(httpServletRequest, span);
else
throw new IllegalStateException("this line should not be reached");
stackDepth = new StackDepth();
ContextManager.getRuntimeContext().put(CONTROLLER_METHOD_STACK_DEPTH, stackDepth);
stackDepth.increment();
@Override
public Object afterMethod(EnhancedInstance objInst, Method method, Object[] allArguments, Class<?>[] argumentsTypes,
Object ret) throws Throwable
// 这是在被切入的方法执行后,要执行的逻辑
这个类中就是增强的功能,可以看出它能在被切入的方法之前和之后增强功能,在被请求注解类(如PostMapping)注解的方法执行前,它可以采集到请求的url、请求头、请求内容等等。那么在方法执行后,它肯定也可以采集到响应内容。
⑥ 小结
看到这里,SpringMVC插件采集的原理基本上可以猜到了,就是实现了拦截器,拦截了被注解的请求接口方法,并在方法执行前后采集数据。
且先不管这个拦截器到底是怎么工作的,看到这里,基本上已经明了该如何采集自定义的业务数据了,就是直接修改AbstractMethodInterceptor源码即可。
(3)业务请求参数采集
① 默认的请求参数采集
if (SpringMVCPluginConfig.Plugin.SpringMVC.COLLECT_HTTP_PARAMS)
// 采集请求参数
RequestUtil.collectHttpParam(serverHttpRequest, span);
看到采集参数的条件是COLLECT_HTTP_PARAMS,点进去看,好像是个配置类,默认是关闭的,那可以先把它打开。
public class SpringMVCPluginConfig
public static class Plugin
@PluginConfig(root = SpringMVCPluginConfig.class)
public static class SpringMVC
// 是否采集请求参数的开关,默认是关闭的
public static boolean COLLECT_HTTP_PARAMS = false;
去skywalking-agent/config/agent.config配置文件中搜一下,果然找到了:
# 采集SpringMVC请求参数的开关
plugin.springmvc.collect_http_params=$SW_PLUGIN_SPRINGMVC_COLLECT_HTTP_PARAMS:false
然后再看采集的方法RequestUtil.collectHttpParam(serverHttpRequest, span):
public class RequestUtil
public static void collectHttpParam(HttpServletRequest request, AbstractSpan span)
// 获取请求参数
final Map<String, String[]> parameterMap = request.getParameterMap();
if (parameterMap != null && !parameterMap.isEmpty())
String tagValue = CollectionUtil.toString(parameterMap);
tagValue = SpringMVCPluginConfig.Plugin.Http.HTTP_PARAMS_LENGTH_THRESHOLD > 0 ?
StringUtil.cut(tagValue, SpringMVCPluginConfig.Plugin.Http.HTTP_PARAMS_LENGTH_THRESHOLD) : tagValue;
// 将请求参数写入日志http.params字段中
Tags.HTTP.PARAMS.set(span, tagValue);
可以看到,获取请求参数是用的request.getParameterMap()方法,如果你的接口使用的表单方式提交,那么恭喜,参数可以被采集起来。如果使用application/json协议提交参数,不好意思,它采集不到。我的项目里都是后者,因此要额外开发。
② 自定义业务参数采集
使用application/json协议提交的参数,是不方便从request中直接解析出来的。而这里的Object[] allArguments是切入点方法的入参,刚好就是请求参数,因此这里就直接利用其解析请求参数。
if (SpringMVCPluginConfig.Plugin.SpringMVC.COLLECT_HTTP_PARAMS)
if (!StringUtils.isEmpty(httpServletRequest.getContentType())
&& httpServletRequest.getContentType().contains(MediaType.APPLICATION_JSON_VALUE))
// 采集使用application/json协议提交的参数
recordJsonReqLog(allArguments, span, httpServletRequest.getHeader("X_TRACEID"));
else
RequestUtil.collectHttpParam(httpServletRequest, span);
// 记录业务参数的方法
private void recordJsonReqLog(Object[] allArguments, AbstractSpan span, String traceId)
// 记录业务的调用链ID
if (!StringUtils.isEmpty(traceId))
span.tag(new StringTag("traceId"), traceId);
if (allArguments != null && allArguments.length > 0)
// 记录请求参数
String param = GSON.toJson(allArguments[0]);
span.tag(new StringTag("http.req"), param);
try
// 解析请求参数
JsonObject jsonObject = GSON.fromJson(param, JsonObject.class);
JsonObject data = jsonObject.getAsJsonObject("data");
if (data == null)
// 如果没有data参数,直接解析外层参数
data = jsonObject;
// 记录业务参数
Optional.ofNullable(data.get("account")).ifPresent(jsonElement
-> span.tag(new StringTag("account"), jsonElement.getAsString()));
Optional.ofNullable(data.get("userId")).ifPresent(jsonElement
-> span.tag(new StringTag("userId"), jsonElement.getAsString()));
Optional.ofNullable(data.get("deviceId")).ifPresent(jsonElement
-> span.tag(new StringTag("deviceId"), jsonElement.getAsString()));
catch (JsonSyntaxException e)
采集响应参数的思路和上面一样,这里不做介绍了。
(4)使用插件
上面修改的是AbstractMethodInterceptor类,这个类所在模块为apm-springmvc-annotation-commons,所以直接使用maven命令打包,将生成的产物apm-springmvc-annotation-commons-8.7.0.jar拷贝到skywalking-agent/plugins目录下,然后重新构建项目并部署,即可生效。
(5)小结
看到这里,基本上我们已经学会skywalking的一些高级用法了,可以做一些简单的插件二次开发,足以应对项目中大部分业务数据的采集。其他的插件和SpringMVC插件类似,代码的结构基本上差不多。
2. 插件原理剖析
上面的SpringMVC插件源码,我们跟到拦截器
Interceptor,就停止了,那么拦截器到底是如何加载的呢?值得好好研究研究。(不得不说,skywalkig的源码写得是真的很复杂,但是确实很牛B。)在研究之前,我要先介绍一下Byte Buddy。
(1)Byte Buddy介绍
runtime code generation for the Java virtual machine
上面这段话摘自github上该项目的简介,翻译过来就是针对JVM虚拟机的运行时代码生成。这不就是动态代理么?话不多说,先上一段代码:
// agent探针类
public class ToStringAgent
// 探针入口
public static void premain(String arguments, Instrumentation instrumentation)
// AgentBuilder是Byte Buddy中的一个构建器
new AgentBuilder.Default()
// 拦截被ToString注解的类
.type(isAnnotatedWith(ToString.class))
// 被拦截的类要增强的功能
.transform(new AgentBuilder.Transformer()
// DynamicType.Builder是Byte Buddy中用于生成代码的一个重要的构建器
@Override
public DynamicType.Builder transform(DynamicType.Builder builder,
TypeDescription typeDescription,
ClassLoader classloader)
// 拦截名称为toString的方法
return builder.method(ElementMatchers.named("toString"))
// 使用ToStringInterceptor拦截器增强toString方法的功能
.intercept(MethodDelegation.to(ToStringInterceptor.class));
).installOn(instrumentation);
// 拦截器
public class ToStringInterceptor
// RuntimeType是Byte Buddy中应用于拦截器的注解,被它注解的方法就是运行时拦截器要执行的目标方法
@RuntimeType
// Origin注解的就是被代理的目标方法,AllArguments注解的是被代理的目标方法的参数,SuperCall注解的是被代理方法的调用器
public static Object intercept(@Origin Method method, @AllArguments Object[] args, @SuperCall Callable<?> callable)
throws Exception
System.out.println("被代理的方法执行前,执行了拦截器");
try
// 执行被代理的方法
return callable.call();
finally
System.out.println("被代理的方法执行后,执行了拦截器");
这段代码,要使用java agent技术来应用到项目中。它实现的功能就是,拦截项目中被ToString注解的类中的toString()方法,拦截器可以拿到目标方法执行时的所有信息,包括方法的入参,并且在目标方法执行前后,执行一段额外的逻辑。
看这实现的功能是不是有点眼熟,这不就是Lombok中注解实现的功能么?
(2)skywalking插件执行原理
在1-2节中,我们跟源码跟到了AbstractMethodInterceptor类,继续从这个类入手。
// 这里省略了大量的代码,只保留了核心的部分
public abstract class AbstractMethodInterceptor implements InstanceMethodsAroundInterceptor
@Override
public void beforeMethod(EnhancedInstance objInst, Method method, Object[] allArguments, Class<?>[] argumentsTypes,
MethodInterceptResult result) throws Throwable
// 这是在被切入的方法执行前,要执行的逻辑
@Override
public Object afterMethod(EnhancedInstance objInst, Method method, Object[] allArguments, Class<?>[] argumentsTypes,
Object ret) throws Throwable
// 这是在被切入的方法执行后,要执行的逻辑
① beforeMethod()方法在哪里调用的?

这里有好几个类都调用了beforeMethod()方法,这里我直接揭晓答案了,SpringMVC的拦截器走的是InstMethodsInter。下面那个带OverrideArgs的类,和1-2节中AbstractControllerInstrumentation类中构建拦截器切入点中的isOverrideArgs()方法应该有关,由于SpringMVC拦截器该方法返回的是false,因此不看这个类。
② 核心拦截器InstMethodsInter
public class InstMethodsInter
private static final ILog LOGGER = LogManager.getLogger(InstMethodsInter.class);
private InstanceMethodsAroundInterceptor interceptor;
// 构造方法
public InstMethodsInter(String instanceMethodsAroundInterceptorClassName, ClassLoader classLoader)
try
// 使用类加载器加载拦截器到JVM中。这里要加载的原因是,插件拦截器都在独立的jar包,不在agent主程序里
interceptor = InterceptorInstanceLoader.load(instanceMethodsAroundInterceptorClassName, classLoader);
catch (Throwable t)
throw new PluginException("Can\'t create InstanceMethodsAroundInterceptor.", t);
// 拦截器的主方法,看到RuntimeType、AllArguments这些注解没,都是Byte Buddy里的
@RuntimeType
public Object intercept(@This Object obj, @AllArguments Object[] allArguments, @SuperCall Callable<?> zuper,
@Origin Method method) throws Throwable
EnhancedInstance targetObject = (EnhancedInstance) obj;
MethodInterceptResult result = new MethodInterceptResult();
try
// 拦截器在代理方法执行前执行beforeMethod方法
interceptor.beforeMethod(targetObject, method, allArguments, method.getParameterTypes(), result);
catch (Throwable t)
LOGGER.error(t, "class[] before method[] intercept failure", obj.getClass(), method.getName());
// 接收被代理的方法执行的结果
Object ret = null;
try
if (!result.isContinue())
ret = result._ret();
else
// 执行被代理的方法
ret = zuper.call();
catch (Throwable t)
try
// 拦截器捕获被代理的方法的异常
interceptor.handleMethodException(targetObject, method, allArguments, method.getParameterTypes(), t);
catch (Throwable t2)
LOGGER.error(t2, "class[] handle method[] exception failure", obj.getClass(), method.getName());
throw t;
finally
try
// 拦截器在代理方法执行后执行afterMethod方法
ret = interceptor.afterMethod(targetObject, method, allArguments, method.getParameterTypes(), ret);
catch (Throwable t)
LOGGER.error(t, "class[] after method[] intercept failure", obj.getClass(), method.getName());
return ret;
看到@RuntimeType注解就松了一口气了,这就是Byte Buddy中拦截器的写法。
③ 核心拦截器在哪里用的?
直接点击InstMethodsInter类,看它在哪里用到了:
// 这里仅保留了核心代码
public abstract class ClassEnhancePluginDefine extends AbstractClassEnhancePluginDefine
private static final ILog LOGGER = LogManager.getLogger(ClassEnhancePluginDefine.class);
// 增强类实例的核心方法
protected DynamicType.Builder<?> enhanceInstance(TypeDescription typeDescription,
DynamicType.Builder<?> newClassBuilder, ClassLoader classLoader,
EnhanceContext context) throws PluginException
// 获取实例类方法拦截切入点
InstanceMethodsInterceptPoint[] instanceMethodsInterceptPoints = getInstanceMethodsInterceptPoints();
boolean existedMethodsInterceptPoints = false;
if (instanceMethodsInterceptPoints != null && instanceMethodsInterceptPoints.length > 0)
existedMethodsInterceptPoints = true;
if (existedConstructorInterceptPoint)
// 增强构造方法
if (existedMethodsInterceptPoints)
// 增强实例类方法
for (InstanceMethodsInterceptPoint instanceMethodsInterceptPoint : instanceMethodsInterceptPoints)
// 判断是否属于要拦截的目标方法的条件
ElementMatcher.Junction<MethodDescription> junction = not(isStatic())
// getMethodsMatcher()在上面1-2节也提到了
.and(instanceMethodsInterceptPoint.getMethodsMatcher());
// 这里就是Byte Buddy中构建方法拦截器的核心写法。
newClassBuilder = newClassBuilder.method(junction)
// 设置拦截器
.intercept(MethodDelegation.withDefaultConfiguration()
.to(new InstMethodsInter(interceptor, classLoader)));
return newClassBuilder;
这个类中可以看出,它将拦截器与被拦截的类编织到一起了。继续跟踪enhanceInstance()方法在哪里调用,一路找过去,最终到了Transformer类。
④ SkyWalkingAgent探针的入口
最终跟到了SkyWalkingAgent.Transformer类,看到这里,基本上就明白了:
public class SkyWalkingAgent
private static ILog LOGGER = LogManager.getLogger(SkyWalkingAgent.class);
// Agent探针的入口
public static void premain(String agentArgs, Instrumentation instrumentation) throws PluginException
// 加载插件
final PluginFinder pluginFinder = new PluginFinder(new PluginBootstrap().loadPlugins());
// Byte Buddy的构建器
AgentBuilder agentBuilder = new AgentBuilder...;
// type()判断是否需要由插件拦截
agentBuilder.type(pluginFinder.buildMatch())
// 这里就是设置拦截器
.transform(new Transformer(pluginFinder))
.with(AgentBuilder.RedefinitionStrategy.RETRANSFORMATION)
.with(new RedefinitionListener())
.with(new Listener())
.installOn(instrumentation);
// Byte Buddy的拦截器
private static class Transformer implements AgentBuilder.Transformer
@Override
public DynamicType.Builder<?> transform(final DynamicType.Builder<?> builder,
final TypeDescription typeDescription,
final ClassLoader classLoader,
final JavaModule module)
LoadedLibraryCollector.registerURLClassLoader(classLoader);
// 取出插件
List<AbstractClassEnhancePluginDefine> pluginDefines = pluginFinder.find(typeDescription);
if (pluginDefines.size() > 0)
// Byte Buddy中用于生成代码的一个重要的构建器
DynamicType.Builder<?> newBuilder = builder;
EnhanceContext context = new EnhanceContext();
// 遍历插件
for (AbstractClassEnhancePluginDefine define : pluginDefines)
// 在这里加载插件中的拦截器,最终调用了上面提到的ClassEnhancePluginDefine.enhanceInstance()方法
DynamicType.Builder<?> possibleNewBuilder = define.define(
typeDescription, newBuilder, classLoader, context);
if (possibleNewBuilder != null)
newBuilder = possibleNewBuilder;
return newBuilder;
return builder;
在skywalking探针的入口方法中,就已经加载了所有插件的拦截器,并将拦截器和需要拦截的方法关联到了一起,剩下的功能,就交给Byte Buddy了。
(3)小结
看到这里,skywalking探针工作的原理,就已经清楚了。skywalking是利用了java agent和Byte Buddy两项技术,来实现无侵入式的拦截。如果不了解这两项技术,直接看源码会一脸懵B。
云原生网关 APISIX 的核心流程以源码分析的方式剖析其工作原理
云原生网关 APISIX 的核心流程以源码分析的方式剖析其工作原理
✨博主介绍
🌊 作者主页:苏州程序大白
🌊 作者简介:🏆CSDN人工智能域优质创作者🥇,苏州市凯捷智能科技有限公司创始之一,目前合作公司富士康、歌尔等几家新能源公司
💬如果文章对你有帮助,欢迎关注、点赞、收藏
💅 有任何问题欢迎私信,看到会及时回复
💅关注苏州程序大白,分享粉丝福利## APISIX介绍:
Apache APISIX 是一个动态、实时、高性能的 API 网关, 提供负载均衡、动态上游、灰度发布、服务熔断、身份认证、可观测性等丰富的流量管理功能。
你可以使用 Apache APISIX 来处理传统的南北向流量,以及服务间的东西向流量, 也可以当做 k8s ingress controller 来使用。
Apache APISIX 的技术架构如下图所示:

特性
你可以把 Apache APISIX 当做流量入口,来处理所有的业务数据,包括动态路由、动态上游、动态证书、 A/B 测试、金丝雀发布(灰度发布)、蓝绿部署、限流限速、抵御恶意攻击、监控报警、服务可观测性、服务治理等。
- 全平台
- 云原生: 平台无关,没有供应商锁定,无论裸机还是 Kubernetes,APISIX 都可以运行。
- 运行环境: OpenResty 和 Tengine 都支持。
- 支持 ARM64: 不用担心底层技术的锁定。
- 多协议
- TCP/UDP 代理: 动态 TCP/UDP 代理。
- Dubbo 代理: 动态代理 HTTP 请求到 Dubbo 后端。
- 动态 MQTT 代理: 支持用
client_id对 MQTT 进行负载均衡,同时支持 MQTT 3.1.* 和 5.0 两个协议标准。 - gRPC 代理:通过 APISIX 代理 gRPC 连接,并使用 APISIX 的大部分特性管理你的 gRPC 服务。
- gRPC 协议转换:支持协议的转换,这样客户端可以通过 HTTP/JSON 来访问你的 gRPC API。
- Websocket 代理
- Proxy Protocol
- Dubbo 代理:基于 Tengine,可以实现 Dubbo 请求的代理。
- HTTP(S) 反向代理
- SSL:动态加载 SSL 证书。
- 全动态能力
- 热更新和热插件: 无需重启服务,就可以持续更新配置和插件。
- 代理请求重写: 支持重写请求上游的
host、uri、schema、enable_websocket、headers信息。 - 输出内容重写: 支持自定义修改返回内容的
status code、body、headers。 - Serverless: 在 APISIX 的每一个阶段,你都可以添加并调用自己编写的函数。
- 动态负载均衡:动态支持有权重的 round-robin 负载平衡。
- 支持一致性 hash 的负载均衡:动态支持一致性 hash 的负载均衡。
- 健康检查:启用上游节点的健康检查,将在负载均衡期间自动过滤不健康的节点,以确保系统稳定性。
- 熔断器: 智能跟踪不健康上游服务。
- 代理镜像: 提供镜像客户端请求的能力。
- 流量拆分: 允许用户逐步控制各个上游之间的流量百分比。
- 精细化路由
- 支持全路径匹配和前缀匹配
- 支持使用 Nginx 所有内置变量做为路由的条件,所以你可以使用
cookie,args等做为路由的条件,来实现灰度发布、A/B 测试等功能 - 支持各类操作符做为路由的判断条件,比如
"arg_age", ">", 24 - 支持自定义路由匹配函数
- IPv6:支持使用 IPv6 格式匹配路由
- 支持路由的自动过期(TTL)
- 支持路由的优先级
- 支持批量 Http 请求
- 支持通过GraphQL属性过滤路由
- 安全防护
- 运维友好
- OpenTracing 可观测性: 支持 Apache Skywalking 和 Zipkin。
- 对接外部服务发现:除了内置的 etcd 外,还支持 Consul 和 Nacos,以及 Eureka。
- 监控和指标: Prometheus
- 集群:APISIX 节点是无状态的,创建配置中心集群请参考 etcd Clustering Guide。
- 高可用:支持配置同一个集群内的多个 etcd 地址。
- 控制台: 操作 APISIX 集群。
- 版本控制:支持操作的多次回滚。
- CLI: 使用命令行来启动、关闭和重启 APISIX。
- 单机模式: 支持从本地配置文件中加载路由规则,在 kubernetes(k8s) 等环境下更友好。
- 全局规则:允许对所有请求执行插件,比如黑白名单、限流限速等。
- 高性能:在单核上 QPS 可以达到 18k,同时延迟只有 0.2 毫秒。
- 故障注入
- REST Admin API: 使用 REST Admin API 来控制 Apache APISIX,默认只允许 127.0.0.1 访问,你可以修改
conf/config.yaml中的allow_admin字段,指定允许调用 Admin API 的 IP 列表。同时需要注意的是,Admin API 使用 key auth 来校验调用者身份,在部署前需要修改conf/config.yaml中的admin_key字段,来保证安全。 - 外部日志记录器:将访问日志导出到外部日志管理工具。(HTTP Logger, TCP Logger, Kafka Logger, UDP Logger)
- Helm charts
- 高度可扩展
- 自定义插件: 允许挂载常见阶段,例如
init,rewrite,access,balancer,header filter,body filter和log阶段。 - 插件可以用 Java/Go 编写
- 自定义负载均衡算法:可以在
balancer阶段使用自定义负载均衡算法。 - 自定义路由: 支持用户自己实现路由算法。
- 自定义插件: 允许挂载常见阶段,例如
项目概述
APISIX 是基于 OpenResty 开发的 API 网关,与 OpenResty 的请求生命周期一致,APISIX 利用 Lua Nginx Module 提供的 *_by_lua 添加 Hook。
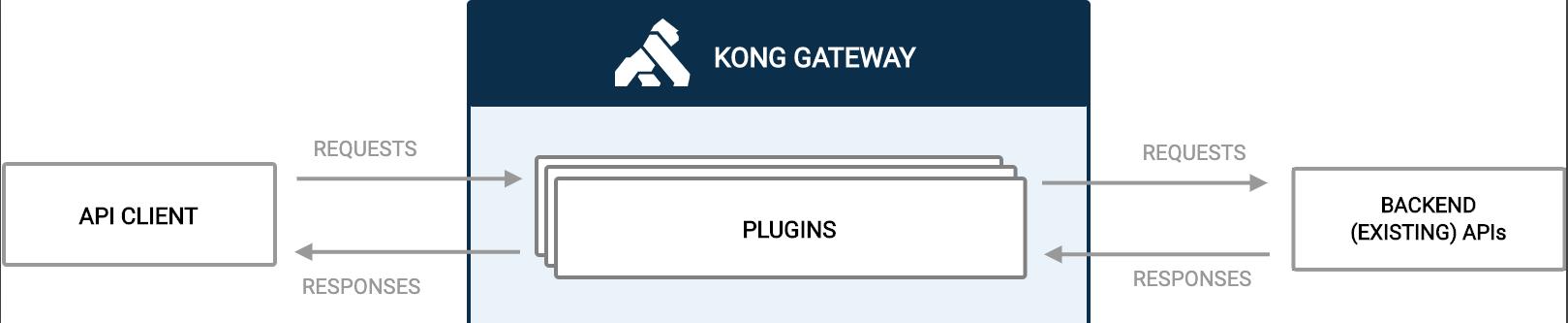
APISIX 抽象了 Route、Service、Upstream、Plugin、Consumer 等数据模型,与 Kong 网关如出一辙。

基本上可以看作 APISIX 是 Kong 网关的重构——运用大量 LuaJIT、OpenResty 技巧优化性能、简化复杂的数据结构、替换储存引擎为 etcd 等。
值得一提的是,在 APISIX 的一个 issue 中,项目开发者说不确定是什么原因,我们看看 Kong 网关是怎么解决的吧。
“Kong是如何解决类似问题的?"
生态概述
Kong 网关开源生态有的,APISIX 基本都有或者正在做。包含:Kubernetes Ingress Controller、Mesh、Dashboard。
插件方面比 Kong 开源版本多了 Skywalking APM 数据上报、Traffit 流量拆分、Mirror 流量镜像等功能。
基本流程
本节概述 APISIX 的目录结构,以及其启动流程。
目录结构
$ tree -L 2
.
├── apisix
│ ├── admin # Admin API
│ ├── api_router.lua
│ ├── balancer # 负载均衡器
│ ├── balancer.lua
│ ├── cli # CLI, Lua 脚本
│ ├── constants.lua # 常量
│ ├── consumer.lua
│ ├── control
│ ├── core # 主要是封装的公共方法
│ ├── core.lua
│ ├── debug.lua
│ ├── discovery # 服务发现, 支持 consul, eruka, dns
│ ├── http
│ ├── init.lua # _by_lua 函数入口
│ ├── patch.lua
│ ├── plugin_config.lua
│ ├── plugin.lua # 插件
│ ├── plugins
│ ├── router.lua # Router
│ ├── schema_def.lua # jsonschema 定义
│ ├── script.lua
│ ├── ssl
│ ├── ssl.lua
│ ├── stream
│ ├── timers.lua # timer 封装
│ ├── upstream.lua
│ └── utils
├── bin
│ └── apisix # apisix CLI, shell 脚本
├── ci # CI 脚本
├── conf # 默认配置文件
├── deps
├── docs
├── Makefile # 快捷指令
├── rockspec # luarocks 包管理
├── t # Test::Nginx 测试
└── utils # Shell 脚本
启动流程

CLI 默认会用 LuaJIT 启动,若版本不够便退回到 Lua 5.1 解释器执行。
# 查找 APISIX LUA 包路径
# shell -s 判断文件是否存在且 size > 0
# ref: https://stackoverflow.com/questions/53319817/what-is-the-meaning-of-n-z-x-l-d-etc-in-shell-script
if [ -s './apisix/cli/apisix.lua' ]; then
...
fi
# shell -e 判断文件是否存在
if [[ -e $OR_EXEC && "$OR_VER" =~ "1.19" ]]; then
# use the luajit of openresty
echo "$LUAJIT_BIN $APISIX_LUA $*"
exec $LUAJIT_BIN $APISIX_LUA $*
elif [[ "$LUA_VERSION" =~ "Lua 5.1" ]]; then
# OpenResty version is not 1.19, use Lua 5.1 by default
# shell &* 传递所有 args
# ref: https://stackoverflow.com/questions/4824590/propagate-all-arguments-in-a-bash-shell-script
echo "lua $APISIX_LUA $*"
exec lua $APISIX_LUA $*
fi
启动过程中:
- 调用
popen执行 CMD 命令; - 使用 luasocket 库发起 HTTP 请求(非 OpenResty 运行时);
- 使用 ltn12 sink 进行流处理;
- 创建 etcd prefix,value 为
init;
基本类型操作
基本上为了追求极致性能,能用 FFI 调用实现的都用了。
字符串
使用 FFI 调用 libc 函数 memcmp 进行字符串比较内存地址的前 n 长度是否相同。
local ffi = require("ffi")
local C = ffi.C
-- ref: https://www.cplusplus.com/reference/cstring/memcmp/
-- ref: https://www.tutorialspoint.com/c_standard_library/c_function_memcmp.htm
ffi.cdef[[
int memcmp(const void *s1, const void *s2, size_t n);
]]
接收类型是 const void *,不可变类型可以直接传入 Lua string 类型。
如果你的 C 函数接受
const char *或者等价的const unsigned char/int8_t/... *这样的参数类型, 可以直接传递 Lua string 进去,而无需另外准备一个ffi.new申请的数组。
string 前缀比较,比较 s, prefix 内存地址的前 n (#prefix) 长度是否相同。
-- 用 ffi 扩展 string 方法
function _M.has_prefix(s, prefix)
if type(s) ~= "string" or type(prefix) ~= "string" then
error("unexpected type: s:" .. type(s) .. ", prefix:" .. type(prefix))
end
if #s < #prefix then
return false
end
-- 比较 s, prefix 内存地址的前 n (#prefix) 长度是否相同
local rc = C.memcmp(s, prefix, #prefix)
return rc == 0
end
同理比较后缀:
C.memcmp(ffi_cast("char *", s) + #s - #suffix, suffix, #suffix)
Table
Table 是 Lua 中最常用的类型了,与其他语言比较的话相当于 PHP 的 Array 一样实用。
Lua Table 需要注意的地方其一:
table.new(narray, nhash)
这个函数,会预先分配好指定的数组和哈希的空间大小,而不是在插入元素时自增长,这也是它的两个参数 narray 和 nhash 的含义。 如果不使用这个函数,自增长是一个代价比较高的操作,会涉及到空间分配、resize 和 rehash 等,我们应该尽量避免。
table.new 的文档并没有出现在 LuaJIT 的官网,而是深藏在 GitHub 项目的 扩展文档 里,用谷歌也很难找到,所以很多人并不知道这个函数的存在。
超出预设的空间大小,也可以正常使用,只不过性能会退化,也就失去了使用 table.new 的意义。
需要根据实际场景,来预设好 table.new 中数组和哈希空间的大小,这样才能在性能和内存占用上找到一个平衡点。3
Lua Table 需要注意的地方其二:
table.insert 虽然是一个很常见的操作,但性能并不乐观。 如果不是根据指定下标来插入元素,那么每次都需要调用 LuaJIT 的 lj_tab_len 来获取数组的长度,以便插入队尾。获取 table 长度的时间复杂度为 O(n) 。
参考 APISIX 作者给 ingress-nginx 项目提的 Table 操作优化 PR:used table functions of LuaJIT for better performance.
OpenResty Fork 的 LuaJIT 新增的 table 函数4:
- table.isempty
- table.isarray
- table.nkeys
- table.clone
回到 APISIX 封装的 Table 操作符:
-- 自行构建 index 插入 table, 比 table.insert 效率高
function _M.insert_tail(tab, ...)
local idx = #tab
-- 遍历输入的参数
for i = 1, select('#', ...) do
idx = idx + 1
tab[idx] = select(i, ...)
end
return idx
end
select('#', ...) 获取输入参数的数量,select(i, ...) 获取第 n 个参数,Table 的遍历中大量使用该结构。
try_read_attr 实现了 path.node.x 的 table 访问方式,便于读取多层级配置项。
function _M.try_read_attr(tab, ...)
for i = 1, select('#', ...) do
local attr = select(i, ...)
if type(tab) ~= "table" then
return nil
end
tab = tab[attr]
end
return tab
end
使用示例:
local size = core_tab.try_read_attr(local_conf, "graphql", "max_size")
if size then
max_size = size
end
工具类
APISIX 封装了许多工具类,这些工具共同组成了 APISIX 的 PDK(Plugin Development Kit),利用这些方法,插件开发能够增速许多。
JSON 操作
local delay_tab = setmetatable(data = "", force = false,
__tostring = function(self)
local res, err = encode(self.data, self.force)
if not res then
ngx.log(ngx.WARN, "failed to encode: ", err,
" force: ", self.force)
end
return res
end
)
-- this is a non-thread safe implementation
-- it works well with log, eg: log.info(..., json.delay_encode(...))
function _M.delay_encode(data, force)
delay_tab.data = data
delay_tab.force = force
return delay_tab
end
设置了元表的 __tostring 方法,在字符串转换时才使用匿名函数调用 json.encode,在日志打印时,被忽略的日志会不执行 JSON 压缩,避免额外的性能损耗。
LRU 缓存
lua-resty-lrucache 在写入时会清理 TTL 过期的缓存,读时如果数据过期了,会作为第二个参数返回:
function _M.get(self, key)
local hasht = self.hasht
local val = hasht[key]
if val == nil then
return nil
end
local node = self.key2node[key]
-- print(key, ": moving node ", tostring(node), " to cache queue head")
local cache_queue = self.cache_queue
queue_remove(node)
queue_insert_head(cache_queue, node)
if node.expire >= 0 and node.expire < ngx_now() then
-- print("expired: ", node.expire, " > ", ngx_now())
return nil, val, node.user_flags
end
return val, nil, node.user_flags
end

local function fetch_valid_cache(lru_obj, invalid_stale, item_ttl,
item_release, key, version)
local obj, stale_obj = lru_obj:get(key)
if obj and obj.ver == version then
return obj
end
-- 如果 TTL 到期的数据版本号仍一致, 重新 set 该缓存
if not invalid_stale and stale_obj and stale_obj.ver == version then
lru_obj:set(key, stale_obj, item_ttl)
return stale_obj
end
-- release 回调
if item_release and obj then
item_release(obj.val)
end
return nil
end
-- 返回创建 LRU 的匿名函数
local function new_lru_fun(opts)
local item_count, item_ttl
if opts and opts.type == 'plugin' then
item_count = opts.count or PLUGIN_ITEMS_COUNT
item_ttl = opts.ttl or PLUGIN_TTL
else
item_count = opts and opts.count or GLOBAL_ITEMS_COUNT
item_ttl = opts and opts.ttl or GLOBAL_TTL
end
local item_release = opts and opts.release
local invalid_stale = opts and opts.invalid_stale
-- 是否使用并发锁
local serial_creating = opts and opts.serial_creating
-- 参数为 LRU size
local lru_obj = lru_new(item_count)
return function (key, version, create_obj_fun, ...)
-- 不支持的 yielding 的 Nginx phase 无法使用 resty.lock
if not serial_creating or not can_yield_phases[get_phase()] then
local cache_obj = fetch_valid_cache(lru_obj, invalid_stale,
item_ttl, item_release, key, version)
if cache_obj then
return cache_obj.val
end
local obj, err = create_obj_fun(...)
if obj ~= nil then
lru_obj:set(key, val = obj, ver = version, item_ttl)
end
return obj, err
end
local cache_obj = fetch_valid_cache(lru_obj, invalid_stale, item_ttl,
item_release, key, version)
if cache_obj then
return cache_obj.val
end
-- 当缓存失效时获取锁
-- 创建共享内存 lock
local lock, err = resty_lock:new(lock_shdict_name)
if not lock then
return nil, "failed to create lock: " .. err
end
local key_s = tostring(key)
log.info("try to lock with key ", key_s)
-- 获取 lock
local elapsed, err = lock:lock(key_s)
if not elapsed then
return nil, "failed to acquire the lock: " .. err
end
-- 再次获取缓存
cache_obj = fetch_valid_cache(lru_obj, invalid_stale, item_ttl,
nil, key, version)
if cache_obj then
lock:unlock()
log.info("unlock with key ", key_s)
return cache_obj.val
end
local obj, err = create_obj_fun(...)
if obj ~= nil then
lru_obj:set(key, val = obj, ver = version, item_ttl)
end
lock:unlock()
log.info("unlock with key ", key_s)
return obj, err
end
end
这段代码关联到两个 PR:
- bugfix(lrucache): when creating cached objects, use resty-lock to avoid repeated creation.
- change: make lrucache lock optional
使用 lua-resty-lock 通过共享内存竞争锁,用在缓存中避免缓存击穿,当该 Lib 出于 Luajit 限制,无法在 init_by_lua, init_worker_by_lua, header_filter_by_lua, body_filter_by_lua, balancer_by_lua, log_by_lua 阶段中使用。
引入的 serial_creating 属性用于判断插件是否需要启用锁。
Kong 使用的 lua-resty-mlcache 库内部也使用 resty.lock 防止缓存击穿(可选)。
后台任务
两个地方默认初始化了定时器(Nginx Timer)执行后台任务。
init_by_lua阶段创建 OpenResty 特权进程,负责执行特定的后台任务,不会干扰其他 Worker 进程,权限相当于 root;init_by_worker阶段创建 Background Timer,执行并发执行后台任务。
OpenResty 特权进程不能处理请求,只能由 Timer 触发,逻辑上编写 if type(ngx.process.type()) == "privileged agent" 只在特权进程中执行操作。5
Enables the privileged agent process in Nginx.
The privileged agent process does not listen on any virtual server ports like those worker processes. And it uses the same system account as the nginx master process, which is usually a privileged account like
root.The
init_worker_by_lua*directive handler still runs in the privileged agent process. And one can use the type function provided by this module to check if the current process is a privileged agent.6
-- worker 默认后台运行的 timer, 执行各种后台任务
local function background_timer()
if core.table.nkeys(timers) == 0 then
return
end
local threads =
for name, timer in pairs(timers) do
core.log.info("run timer[", name, "]")
-- 开启协程执行
local th, err = thread_spawn(timer)
if not th then
core.log.error("failed to spawn thread for timer [", name, "]: ", err)
goto continue
end
core.table.insert(threads, th)
::continue::
end
local ok, err = thread_wait(unpack(threads))
if not ok then
core.log.error("failed to wait threads: ", err)
end
end
function _M.init_worker()
local opts =
each_ttl = 0,
sleep_succ = 0,
check_interval = check_interval, -- 默认间隔为 1 秒
local timer, err = core.timer.new("background", background_timer, opts)
if not timer then
core.log.error("failed to create background timer: ", err)
return
end
core.log.notice("succeed to create background timer")
end
APISIX 引入特权进程的一个目的在于实现 Log Rotate 插件功能。
请求生命周期
ctx
Use
ngx.ctxwherever you can.ngx.varis much more expensive and is also limited to string values. The latter should only be used to exchange data with other nginx C modules.7
APISIX 中使用缓存 ngx.var 获取的结果, 在不同生命周期中传递。使用 lua-var-nginx-module Nginx C 模块和 FFI 获取变量,在没有开启 Nginx C 模块的情况下回退到 ngx.var 方式获取。APISIX 默认没有在构建脚本中加载 C 模块,提交的 PR feat: add lua-var-nginx-module 在编译 OpenResty 时添加了该模块。
function _M.set_vars_meta(ctx)
-- 从 table 池中获取/创建一个 hash 长度为 32 的 table
local var = tablepool.fetch("ctx_var", 0, 32)
if not var._cache then
var._cache =
end
-- 通过 resty.core.base 获取原始 request C 指针 (?)
-- ref: https://github.com/openresty/lua-resty-core/blob/master/lib/resty/core/base.lua
var