读SQL进阶教程笔记03_自连接
Posted 躺柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读SQL进阶教程笔记03_自连接相关的知识,希望对你有一定的参考价值。
1. 针对相同的表进行的连接
1.1. 相同的表的自连接和不同表间的普通连接并没有什么区别,自连接里的“自”这个词也没有太大的意义
1.2. 与多表之间进行的普通连接相比,自连接的性能开销更大
-
1.2.1. 特别是与非等值连接结合使用的时候
-
1.2.2. 用于自连接的列推荐使用主键或者在相关列上建立索引
2. 组合
2.1. 有顺序的有序对(ordered pair)
2.2. 无顺序的无序对(unordered pair)
3. 示例
3.1.
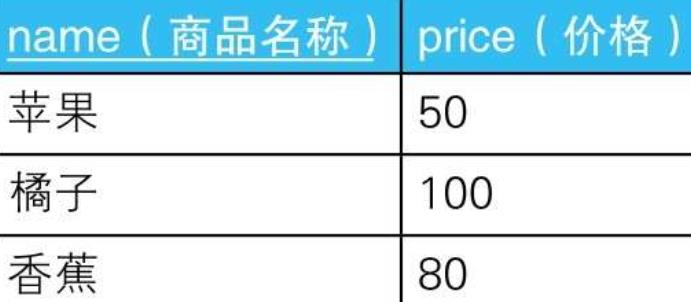
3.2. --用于获取可重排列的SQL语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2;
- 3.2.1. 可重排列,所以结果行数9
3.3. --用于获取排列的SQL语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2
WHERE P1.name <> P2.name;
- 3.3.1. 排除掉由相同元素构成的对,结果行数为排列6
3.4. --用于获取组合的SQL语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2
WHERE P1.name > P2.name;
- 3.4.1. 只与“字符顺序比自己靠前”的商品进行配对,结果行数为组合3
3.5. --用于获取组合的SQL语句:扩展成3列
SELECT P1.name AS name_1, P2.name AS name_2, P3.name AS name_3
FROM Products P1, Products P2, Products P3
WHERE P1.name > P2.name
AND P2.name > P3.name;
3.6. ">”和“<”等比较运算符不仅可以用于比较数值大小,也可以用于比较字符串(比如按字典序进行比较)或者日期
4. 删除重复行
4.1. 示例
-
4.1.1. --用于删除重复行的SQL语句(1):使用极值函数
DELETE FROM Products P1 WHERE rowid < ( SELECT MAX(P2.rowid) FROM Products P2 WHERE P1.name = P2. name AND P1.price = P2.price ) ;- 4.1.1.1. Oracle数据库里的rowid
-
4.1.2. --用于删除重复行的SQL语句(2):使用非等值连接
DELETE FROM Products P1 WHERE EXISTS ( SELECT * FROM Products P2 WHERE P1.name = P2.name AND P1.price = P2.price AND P1.rowid < P2.rowid );
4.2. 如果从物理表的层面来理解SQL语句,抽象度是非常低的
4.3. “表”“视图”这样的名称只反映了不同的存储方法,而存储方法并不会影响到SQL语句的执行和结果
4.4. 无论表还是视图,本质上都是集合——集合是SQL能处理的唯一的数据结构
5. 查找局部不一致的列
5.1. 示例
-
5.1.1. --用于查找是同一家人但住址却不同的记录的SQL语句
SELECT DISTINCT A1.name, A1.address FROM Addresses A1, Addresses A2 WHERE A1.family_id = A2.family_id AND A1.address <> A2.address ; -
5.1.2. --用于查找价格相等但商品名称不同的记录的SQL语句
SELECT DISTINCT P1.name, P1.price FROM Products P1, Products P2 WHERE P1.price = P2.price AND P1.name <> P2.name; -
5.1.3. 如果改用关联子查询,就不需要DISTINCT了
6. 排序
6.1. 示例
-
6.1.1. --排序:使用窗口函数
SELECT name, price, RANK() OVER (ORDER BY price DESC) AS rank_1, DENSE_RANK() OVER (ORDER BY price DESC) AS rank_2 FROM Products;-
6.1.1.1. 在出现相同位次后,rank_1跳过了之后的位次,rank_2没有跳过,而是连续排序
-
6.1.1.2. 依赖于具体数据库来实现的方法
-
-
6.1.2. --排序从1开始。如果已出现相同位次,则跳过之后的位次
SELECT P1.name, P1.price, (SELECT COUNT(P2.price) FROM Products P2 WHERE P2.price > P1.price) + 1 AS rank_1 FROM Products P1 ORDER BY rank_1;-
6.1.2.1. 不依赖于具体数据库来实现的方法
-
6.1.2.2. 去掉标量子查询后边的+1,就可以从0开始给商品排序
-
6.1.2.3. 如果修改成COUNT(DISTINCT P2.price),那么存在相同位次的记录时,就可以不跳过之后的位次,而是连续输出(相当于DENSE_RANK函数)
-
7. 同心圆状的递归集合
7.1. 示例
- 7.1.1.
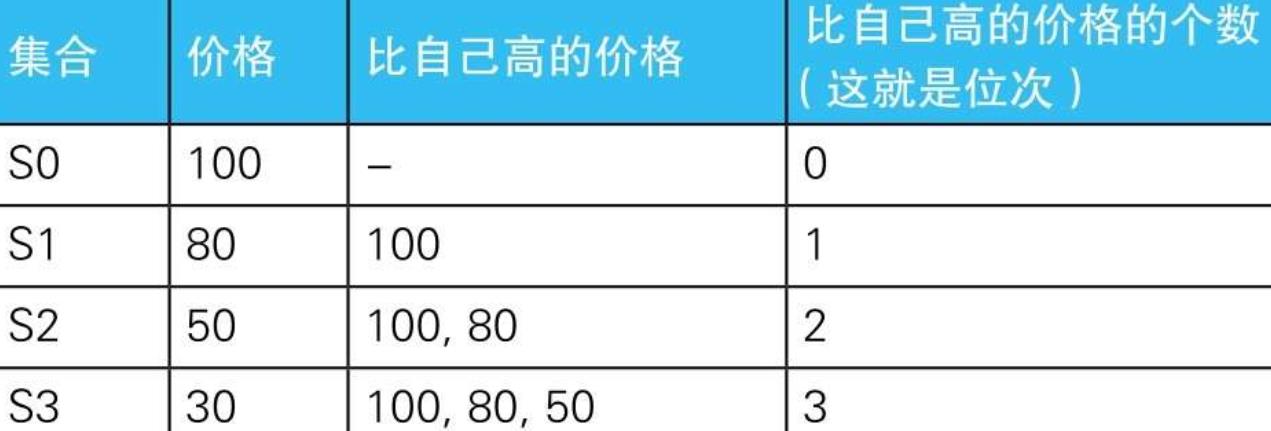
-
7.1.2. --排序:使用自连接
SELECT P1.name, MAX(P1.price) AS price, COUNT(P2.name) +1 AS rank_1 FROM Products P1 LEFT OUTER JOIN Products P2 ON P1.price < P2.price GROUP BY P1.name ORDER BY rank_1;- 7.1.2.1. 外连接就是这样一个用于将第1名也存储在结果里的小技巧
-
7.1.3. --排序:改为内连接
SELECT P1.name, MAX(P1.price) AS price, COUNT(P2.name) +1 AS rank_1 FROM Products P1 INNER JOIN Products P2 ON P1.price < P2.price GROUP BY P1.name ORDER BY rank_1;- 7.1.3.1. 没有比橘子价格更高的水果,所以它被连接条件P1.price < P2.price排除掉了
-
7.1.4. --不聚合,查看集合的包含关系
SELECT P1.name, P2.name FROM Products P1 LEFT OUTER JOIN Products P2 ON P1.price < P2.price;
读SQL进阶教程笔记05_关联子查询
1. 关联子查询
1.1. 关联子查询和自连接在很多时候都是等价的
1.2. 使用SQL进行行间比较时,发挥主要作用的技术是关联子查询,特别是与自连接相结合的“自关联子查询”
1.3. 缺点
-
1.3.1. 代码的可读性不好
- 1.3.1.1. 特别是在计算累计值和移动平均值的例题里,与聚合一起使用后,其内部处理过程非常难理解
-
1.3.2. 性能不好
- 1.3.2.1. 特别是在SELECT子句里使用标量子查询时,性能可能会变差
2. 增长、减少、维持现状
2.1. 使用基于时间序列的表进行时间序列分析
2.2. 示例
- 2.2.1. --求与上一年营业额一样的年份(1):使用关联子查询
SELECT year, sale
FROM Sales S1
WHERE sale = (SELECT sale
FROM Sales S2
WHERE S2.year = S1.year -1)
ORDER BY year;
-
2.2.2. S2.year = S1.year -1这个条件起到了将要比较的数据偏移一行的作用
-
2.2.3. --求与上一年营业额一样的年份(2):使用自连接
SELECT S1.year, S1.sale
FROM Sales S1,
Sales S2
WHERE S2.sale = S1.sale
AND S2.year = S1.year -1
ORDER BY year;
3. 用列表展示与上一年的比较结果
3.1. 示例
- 3.1.1. --求出是增长了还是减少了,抑或是维持现状(1):使用关联子查询
SELECT S1.year, S1.sale,
CASE WHEN sale =
(SELECT sale
FROM Sales S2
WHERE S2.year = S1.year -1) THEN\'→\'--持平
WHEN sale >
(SELECT sale
FROM Sales S2
WHERE S2.year = S1.year -1) THEN\'↑\'--增长
WHEN sale <
(SELECT sale
FROM Sales S2
WHERE S2.year = S1.year -1) THEN\'↓\'--减少
ELSE\'—\'END AS var
FROM Sales S1
ORDER BY year;
- 3.1.2. --求出是增长了还是减少了,抑或是维持现状(2):使用自连接查询(最早的年份不会出现在结果里)
SELECT S1.year, S1.sale,
CASE WHEN S1.sale = S2.sale THEN\'→\'
WHEN S1.sale > S2.sale THEN\'↑\'
WHEN S1.sale < S2.sale THEN\'↓\'
ELSE\'—\'END AS var
FROM Sales S1, Sales S2
WHERE S2.year = S1.year -1
ORDER BY year;
4. 时间轴有间断时
4.1. 和过去最临近的时间进行比较
4.2. 示例
- 4.2.1. --查询与过去最临近的年份营业额相同的年份
SELECT year, sale
FROM Sales2 S1
WHERE sale =
(SELECT sale
FROM Sales2 S2
WHERE S2.year =
(SELECT MAX(year) --条件2:在满足条件1的年份中,年份最早的一个
FROM Sales2 S3
WHERE S1.year > S3.year)) --条件1:与该年份相比是过去的年份
ORDER BY year;
- 4.2.2. 自连接版本
SELECT S1.year AS year,
S1.year AS year
FROM Sales2 S1, Sales2 S2
WHERE S1.sale = S2.sale
AND S2.year = (SELECT MAX(year)
FROM Sales2 S3
WHERE S1.year > S3.year)
ORDER BY year;
- 4.2.3. --求每一年与过去最临近的年份之间的营业额之差(1):结果里不包含最早的年份
SELECT S2.year AS pre_year,
S1.year AS now_year,
S2.sale AS pre_sale,
S1.sale AS now_sale,
S1.sale - S2.sale AS diff
FROM Sales2 S1, Sales2 S2
WHERE S2.year = (SELECT MAX(year)
FROM Sales2 S3
WHERE S1.year > S3.year)
ORDER BY now_year;
- 4.2.4. --求每一年与过去最临近的年份之间的营业额之差(1):结果里不包含最早的年份
SELECT S2.year AS pre_year,
S1.year AS now_year,
S2.sale AS pre_sale,
S1.sale AS now_sale,
S1.sale - S2.sale AS diff
FROM Sales2 S1, Sales2 S2
WHERE S2.year = (SELECT MAX(year)
FROM Sales2 S3
WHERE S1.year > S3.year)
ORDER BY now_year;
- 4.2.5. 使用极值函数时会发生排序
5. 移动累计值和移动平均值
5.1. 示例
- 5.1.1. --求累计值:使用窗口函数
SELECT prc_date, prc_amt,
SUM(prc_amt) OVER (ORDER BY prc_date) AS onhand_amt
FROM Accounts;
-
5.1.2. 引入窗口函数的目的原本就是解决这类问题,因此这里的代码非常简洁
- 5.1.2.1. 如果选用的数据库支持窗口函数,也可以考虑使用窗口函数
-
5.1.3. 从性能方面来看,表的扫描和数据排序也都只进行了一次
- 5.1.3.1. 依赖于具体的数据库的
-
5.1.4. --求累计值:使用冯·诺依曼型递归集合
SELECT prc_date, A1.prc_amt,
(SELECT SUM(prc_amt)
FROM Accounts A2
WHERE A1.prc_date >= A2.prc_date ) AS onhand_amt
FROM Accounts A1
ORDER BY prc_date;
- 5.1.5. --求移动累计值(1):使用窗口函数
SELECT prc_date, prc_amt,
SUM(prc_amt) OVER (ORDER BY prc_date
ROWS 2 PRECEDING) AS onhand_amt
FROM Accounts;
- 5.1.6. --求移动累计值(2):不满3行的时间区间也输出
SELECT prc_date, A1.prc_amt,
(SELECT SUM(prc_amt)
FROM Accounts A2
WHERE A1.prc_date >= A2.prc_date
AND (SELECT COUNT(*)
FROM Accounts A3
WHERE A3.prc_date
BETWEEN A2.prc_date AND A1.prc_date ) <= 3 )
AS mvg_sum
FROM Accounts A1
ORDER BY prc_date;
-
5.1.7. A3.prc_date在以A2.prc_date为起点,以A1.prc_date为终点的区间内移动
-
5.1.8. --移动累计值(3):不满3行的区间按无效处理
SELECT prc_date, A1.prc_amt,
(SELECT SUM(prc_amt)
FROM Accounts A2
WHERE A1.prc_date >= A2.prc_date
AND (SELECT COUNT(*)
FROM Accounts A3
WHERE A3.prc_date
BETWEEN A2.prc_date AND A1.prc_date ) <= 3
HAVING COUNT(*) =3) AS mvg_sum --不满3行数据的不显示
FROM Accounts A1
ORDER BY prc_date;
5.2. 基本思路是使用冯·诺依曼型递归集合
6. 查询重叠的时间区间
6.1. 示例
- 6.1.1. --求重叠的住宿期间
SELECT reserver, start_date, end_date
FROM Reservations R1
WHERE EXISTS
(SELECT *
FROM Reservations R2
WHERE R1.reserver <> R2.reserver --与自己以外的客人进行比较
AND ( R1.start_date BETWEEN R2.start_date AND R2.end_date
--条件(1):自己的入住日期在他人的住宿期间内
OR R1.end_date BETWEEN R2.start_date AND R2.end_date));
--条件(2):自己的离店日期在他人的住宿期间内
- 6.1.2. --升级版:把完全包含别人的住宿期间的情况也输出
SELECT reserver, start_date, end_date
FROM Reservations R1
WHERE EXISTS
(SELECT *
FROM Reservations R2
WHERE R1.reserver <> R2.reserver
AND ( ( R1.start_date BETWEEN R2.start_date
AND R2.end_date
OR R1.end_date BETWEEN R2.start_date
AND R2.end_date)
OR ( R2.start_date BETWEEN R1.start_date
AND R1.end_date
AND R2.end_date BETWEEN R1.start_date
AND R1.end_date)));
以上是关于读SQL进阶教程笔记03_自连接的主要内容,如果未能解决你的问题,请参考以下文章