python学习笔记——拾壹
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python学习笔记——拾壹相关的知识,希望对你有一定的参考价值。
协程和io多路复用的区别
都继承了相同的类 libevent.so
协程也可以理解是io多路复用
io多路复用更偏向io一点
协程是更上层的一种封装 偏向于函数的切换。
RabbitMQ 消息队列
1.单发送单接收
2.单发送多接收
3.广播、订阅模式
4.有选择的接收消息 Routing (按路线发送接收)
5.更细致的消息过滤 Topics (按topic发送接收)
6.RPC
进程queue :
在父进程与子进程进行交互,或者同属于同一以父进程下的多个子进程交互。
rabbitMq:两个独立的程序程序 或者 在java和python的程序通信,不同机器的 通讯, 这时需要一个中间的代理。RabbitMQ。
为什么生产者已经声明了管道,消费者还要再次声明?
如果生产者首先启动,管道已经创建,不会有问题。
如果消费者首先启动,没有声明管道,会报错
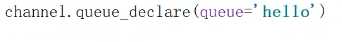
在windows安装了RabbitMQ
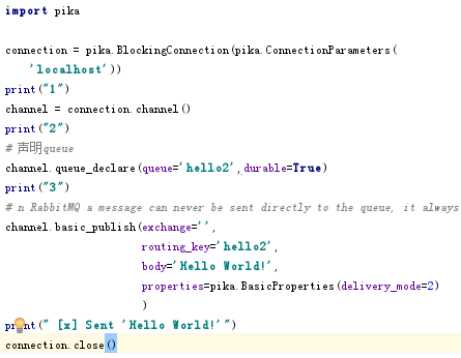
生产者
消费者
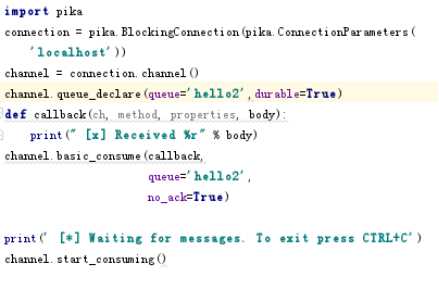
消费者的 callback函数
ch代表管道的内存对象
methon 队列的信息
body 数据
数据处理在此

rabbitMQ的消费者 消费数据是轮询方式的
如果启动3个消费者a b c
生产者第1次生产数据,a收到
生产者第2次生产数据,b收到
生产者第3次生产数据,c收到
生产者第4次生产数据,a收到
如此循环往复,公平的把消息分给每个消费者,做到了负载均衡
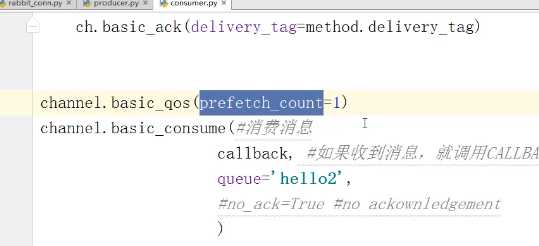
注意下图,有参数no_ack
True代表 无论消费者是否把消息处理完,都不给生产者回应,不关心消息。
False代表 默认是False,消息处理完给生产者回应
RabbitMQ根据消费者的回应而删除消息,如果消息处理到一半,消费者挂掉,那么
消息,不会删除,而是发给其他消费者。

windos 下使用以下命令 查到 当前的队列和其中的消息数

数据持久化
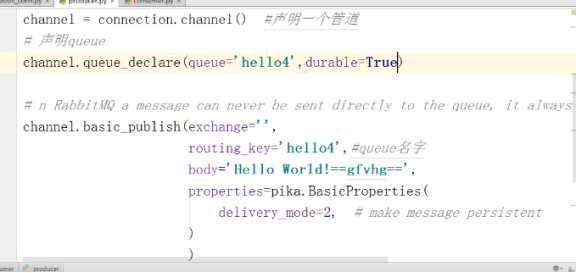
在创建管道时 设置durable=True 持久化队列 在生产者和服务端都需要写

在发送消息时 设置如下图 持久化消息 生产者
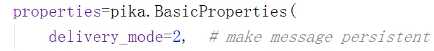
完整如下图:
rabbitMQ的负载均衡
在消费者端 设置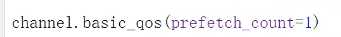
如此设置之后 如果当前的消费者处理的消息超过1条,就会被转发到其他的消费者上。所有的消费者都设置,处理消息快的消费者,处理完一条消息会接着处理,处理慢的就会先把当前的消息处理完,再接收下个消息。这样就做到了负责均衡。
设置广播模式 消息订阅
订阅发布 可以同时给绑定相同转发器的消费这发送消息,但是消息就像广播一样,虽然你不在听了。但是消息还是正常发送,错过了的消息不会再出现。
生产者
exchange=“log”是转发器
type=‘fanout’
不用再声明queue 需要在消费者声明queue


消费者:

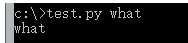
sys.argv[] 获取外部的参数
比如保存一个test.py
import sys
a=sys.argv[1]
print(a)
运行 时加一个参数 what 结果如下 得到what
具体解释:E:\\python学习\\学习网页\\Python中 sys.argv[]的用法简明解释
sys.exit()的退出比较优雅,调用后会引发SystemExit异常,可以捕获此异常,执行异常处理中的代码
os._exit()直接将python解释器退出,余下的语句不会执行
exit(0):无错误退出
exit(1):有错误退出
有选择的接受消息
生产者在发送消息需要
test_p.py error helle_word
test_p.py(生产者的文件) error(加上类型) helle_word(内容)
消费者在发送消息需要
test_c.py error info
test_c.py(消费者的文件) error info(加上类型,可以多写几个)
当然 把error换成 sb都可以,只是生产者和消费者的类型如果对不上就收不到消息
以上是关于python学习笔记——拾壹的主要内容,如果未能解决你的问题,请参考以下文章