Python成长之路
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python成长之路相关的知识,希望对你有一定的参考价值。
基础篇
第一章 Python发展、安装、使用
1、Python简介
2、Python安装
3、第一个Python程序
4、变量
5、字符编码与二进制
6、字符编码的区别
7、if - else流程判断
8、while循环
第一章 Python发展、安装、使用
Python的简介
说到Python语言,就不得不说一下它的创始为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
下面看下最新的TIOBE排行榜。
由上图可以看出python已经连续在2016、2017都处在第五的位置,在前五的编程语言中只有python任处于增长的趋势,从中可以看出Python已经被这个行业所承认。
Python现在所能应用的场景有:
Web应用开发
Python经常被用于Web开发。比如,通过mod_wsgi模块,Apache可以运行用Python编写的Web程序。Python定义了WSGI标准应用接口来协调Http服务器与基于Python的Web程序之间的通信。一些Web框架,如Django,TurboGears,web2py,Zope等,可以让程序员轻松地开发和管理复杂的Web程序。
操作系统管理、服务器运维的自动化脚本
在很多操作系统里,Python是标准的系统组件。 大多数Linux发行版以及NetBSD、OpenBSD和Mac OS X都集成了Python,可以在终端下直接运行Python。有一些Linux发行版的安装器使用Python语言编写,比如Ubuntu的Ubiquity安装器,Red Hat Linux和Fedora的Anaconda安装器。Gentoo Linux使用Python来编写它的Portage包管理系统。Python标准库包含了多个调用操作系统功能的库。通过pywin32这个第三方软件 包,Python能够访问Windows的COM服务及其它Windows API。使用IronPython,Python程序能够直接调用.Net Framework。一般说来,Python编写的系统管理脚本在可读性、性能、代码重用度、扩展性几方面都优于普通的shell脚本。
科学计算
NumPy,SciPy,Matplotlib可以让Python程序员编写科学计算程序。
桌面软件
PyQt、PySide、wxPython、PyGTK是Python快速开发桌面应用程序的利器。
服务器软件(网络软件)
Python对于各种网络协议的支持很完善,因此经常被用于编写服务器软件、网络爬虫。第三方库Twisted支持异步网络编程和多数标准的网络协议(包含客户端和服务器),并且提供了多种工具,被广泛用于编写高性能的服务器软件。
游戏
很多游戏使用C++编写图形显示等高性能模块,而使用Python或者Lua编写游戏的逻辑、服务器。相较于Python,Lua的功能更简单、体积更小;而Python则支持更多的特性和数据类型。
构思实现,产品早期原型和迭代
YouTube、Google、Yahoo!、NASA都在内部大量地使用Python。
还有其他的一些诸如数据分析人工智能方面的应用。
Python的几种解释器
CPython
当我们从Python官方网站下载并安装好Python 3.5后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
CPython是使用最广的Python解释器。
IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。
CPython用">>>"作为提示符,而IPython用"In [序号]":作为提示符。
PyPy
PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。
绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。
Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
Python的一些特点
Python是一个解释型、动态类型语强定义类型的编程语言,它拥有非常庞大的库,具有非常高的开发效率、可移植性、可扩展、可嵌入性。当然它也有一些缺点就是代码的执行速度慢、代码不能加密、线程不能利用多cpu等问题。
总的来说编程语言是用来实现工程师思想的一个工具没有什么好坏之分只有你能不能利用好它的特性,不要拿一个程序的缺点和另外一个程序的有点进行对比。
Python的安装
Window 平台安装 Python:
以下为在 Window 平台上安装 Python 的简单步骤:
- 打开WEB浏览器访问https://www.python.org/downloads/windows/
- 在下载列表中选择你想下载版本,在这里我选择的是最新python3的版本 。
- 要使用安装程序 python-XYZ.msi, Windows系统必须支持Microsoft Installer 2.0搭配使用。只要保存安装文件到本地计算机,然后运行它,看看你的机器支持MSI。Windows XP和更高版本已经有MSI,很多老机器也可以安装MSI。
- 下载后,双击下载包,进入Python安装向导,安装非常简单,你只需要使用默认的设置一直在点击"下一步"直到安装完成即可。
- 然后就是配置环境变量 【右键计算机】-->【属性】-->【高级系统设置】-->【高级】-->【环境变量】-->【在系统变量下选择path】-->【选择编辑】-->【把Python安装目录复制到这行的最后面记住在复制安装目录时要打英文的分隔符;】
Unix & Linux 平台安装 Python
一般情况下现在的Linux默认安装python2,如果没有安装就按照下面的步骤安装:
- 打开WEB浏览器访问http://www.python.org/download/
- 选择适用于Unix/Linux的源码压缩包。
- 下载及解压压缩包。
- 如果你需要自定义一些选项修改Modules/Setup
- 执行 ./configure 脚本
- make
- make install
执行以上操作后,Python会安装在 /usr/local/bin 目录中,Python库安装在/usr/local/lib/pythonXX,XX为你使用的Python的版本号。
MAC 平台安装 Python
现在的Mac都默认有环境变量只要到官网下载相应的版本就能够使用
编写第一个Python程序
我是用的编程的软件是pycharm在里面创建相应的文件就ok,关于怎么使用pycharm自己可以上网搜寻相关的文章。
执行的结果是:
如果实在Linux系统中在脚本中的顶个要加上 #!/usr/bin/env python 这个的意思就是在执行程序的时候,会去取你机器的path中指定的第一个python来执行你的脚本。这样写是为了防止有的Python不是安装在默认的地方。在执行程序的时候几个给这个文件相应的执行权限即:chmod a+x *.py 后就可以在当前的目录下执行:./*.py 。或者再不给权限的时候直接python *.py同样有效。
变量
变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
[‘and‘, ‘as‘, ‘assert‘, ‘break‘, ‘class‘, ‘continue‘, ‘def‘, ‘del‘, ‘elif‘, ‘else‘, ‘except‘, ‘exec‘, ‘finally‘, ‘for‘, ‘from‘, ‘global‘, ‘if‘, ‘import‘, ‘in‘, ‘is‘, ‘lambda‘, ‘not‘, ‘or‘, ‘pass‘, ‘print‘, ‘raise‘, ‘return‘, ‘try‘, ‘while‘, ‘with‘, ‘yield‘]
变量命名的习惯
想要成为一个优秀的程序员首先我们要有良好的编程习惯,当你的代码越写越多的时候会发现你定义的变量也会越来越多,为了增加代码的易读性和方便调试,给变量起名时一定要遵循一定的命名习惯,你起的变量名称最好能让人一眼就大概知道这个变量是干什么用的,比如,getUserName一看就知道,这个变量应该是要获取用户的姓名。
check_current_conn_count代表是要检查现在的连接数,只有这样,别人才能在看你的代码时知道你的这些变量的作用,而如果你把变量名全起成了var1,var2,var3…..varN,这样别人在阅读代码时根本不值有这个变量是干什么用,给别人阅读代码或者调试时带来困难这样别人会边看边骂死你,同时你自己时间长了一不知道他们的意义。
变量名的定义在能表达清楚它的作用的前提下最越简洁越好,能用一个单词表述清楚的尽量就不要用两个。变量起名时一般有这么几种写法,你觉得哪种最简洁,你就选哪种吧。
CheckCurrentConnCount
check_current_conn_count
checkCurrentConnCount
不好的起名:
CHECKCURRENTCONNCOUNT
Var1 var2 var3 varN
Checkcurrentconncount
变量的赋值:
在Python中变量的赋值相当于引用机制,如上面的列子:系统先在内存中把相应的“yangpan”这个字符串存储进去,然后把变量name指向内存中存储“yangpan”的那个地址如图所示:
在Python中我们创建一个变量name,再把这个变量name赋值给下一个变量name2。实际上是使变量name2指向内存中的地址和变量name指向内存的地址相同的位置。当变量name改变赋值后变量name指向内存中的地址发生改变,变量name2指向内存中的地址不会发生改变。具体在内存中的变化如下图:
注意:
1、 赋值变量时如name = “china yang”注意这个必须要用英文的双引号括起来,双引号里面的字母或数字不是连续的外面必须要有双引号
2、 name2 = name 这个不加双引号表示把变量name赋值给name2
3、 name3 = “name”这个表示把字符串”name”赋值给name3
4、 name4 = True 这个是布尔值,一般用作逻辑判断。
常量
刚才说到了变量,还有一概念就是常量,所谓常量就是不能变的变量,比如常用的数学常数π就是一个常量。在Python中,通常用全部大写的变量名表示常量:
PI = 3.14159265359
但事实上PI仍然是一个变量,Python根本没有任何机制保证PI不会被改变,所以,用全部大写的变量名表示常量只是一个习惯上的用法,如果你一定要改变变量PI的值,也没人能拦住你。
字符编码
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符‘0‘和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
|
字符 |
ASCII |
Unicode |
UTF-8 |
|
A |
01000001 |
00000000 01000001 |
01000001 |
|
中 |
x |
01001110 00101101 |
11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
上面这个关于字符编码的是看见Alex老师的。个人感觉写的简要明了,能够很好的理解
if- else流程判断
在说if语句是先说一下Python中的一个内建函数input(),通过读取控制台的输入与用户实现交互
if语句:
语法如下:
if expression:
do this
elif sxpression:
do this
....
else:
do this
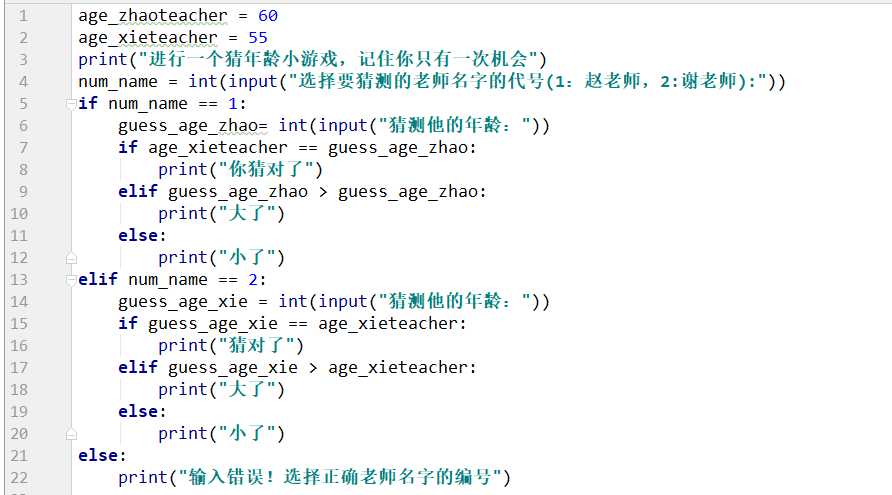
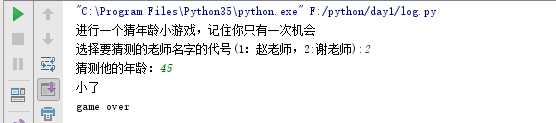
如果表达式中的expression的值为真(不为零的任何值都为真),或表达式成立,程序将执行缩进后的内容(务必要正确的缩进)。如果不成立执行下面的elif语句同样也是看expression的值为真(不为零的任何值都为真),或表达式成立。执行缩进后的内容。如果不成功就一直下面有的elif语句直到执行else语句时整个流程判断结束,或者在前面执行if语句或者elif语句成功时结束流程判断。一个简单猜年龄小游戏来实现这个流程判断。这个游戏只能玩一次


使用if-else语句中我们可以在判断语句中嵌套判断语句,如下面的小游戏。
while循环
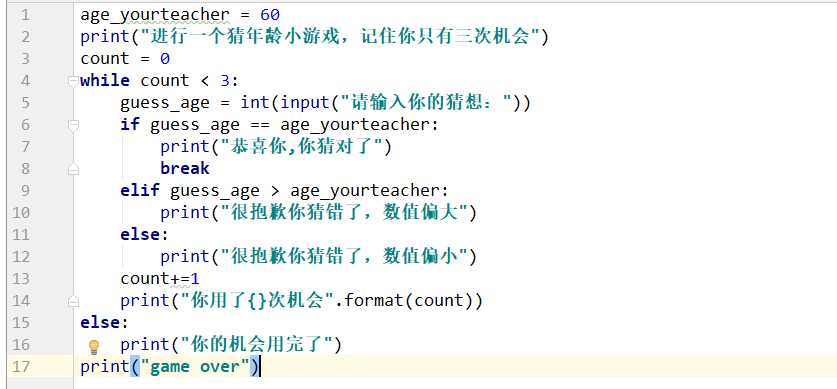
while循环语发结构
while expression:
while_suite
while中的expression非0或者Flash时,语句while_suite会连续不断地循环执行,直到expression的值为0或者Flash结束循环。

continue、break语句
再说到while循环时再来说一下跳出循环语句break和结束本次循环语句的continue的区别。再循环语句while中当执行到break语句时整个while循环的语句都将结束。然后当执行到continue语句时,如果while的expression的值为非0或者Flash时只是结束当前的循环,开始下一个循环直到执行break语句或者while中的expression的值为0或者Flash时,整个while循环才回结束。下面我们求1到100所有偶数相加的和:


由上面的2个列子可以愉悦的分辨出break语句时直接结束整个循环,而continue时结束当前的循环开始下一轮循环。
for循环
for循环可以遍历任何序列的项目现在在这我们简单的说下for循环的应用。
for <variable> in <sequence>:
<statements>
else:
<statements>


在说上面之前我们先说一下range函数,range函数会生成一个list列表。
range(i)中的i代表生成一个列表从0到i-1,也可以用xrange(i)表示关于
xrange输出的结果和range是一样的不过它不是立马生成一个list他返回的是一个生成器
所以xrange做循环的性能比range好,尤其是返回很大的时候!
尽量用xrange吧,除非你是要返回一个列表才用range。
现在说说for循环。
在上面的列子中我们可以看到我们每次在range(5)创建的list对象去一个值然后输出,再取一个值在输出,知道取完为止。这个就是for循环。
关于for循环我说的也不多,这个纯属新人。
本人第一次写博客,个人也感觉写的的好,但是我个人主要是加深下自己所学知识。我也会坚持写下去,希望以后在写博客时在加深自己的理解时,能够有所进步给一些小白带来帮助
以上是关于Python成长之路的主要内容,如果未能解决你的问题,请参考以下文章