python网络爬虫之requests库 二
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python网络爬虫之requests库 二相关的知识,希望对你有一定的参考价值。
前面一篇在介绍request登录CSDN网站的时候,是采用的固定cookie的方式,也就是先通过抓包的方式得到cookie值,然后将cookie值加在发送的数据包中发送到服务器进行认证。
就好比获取如下的数据。然后加入到header信息中去
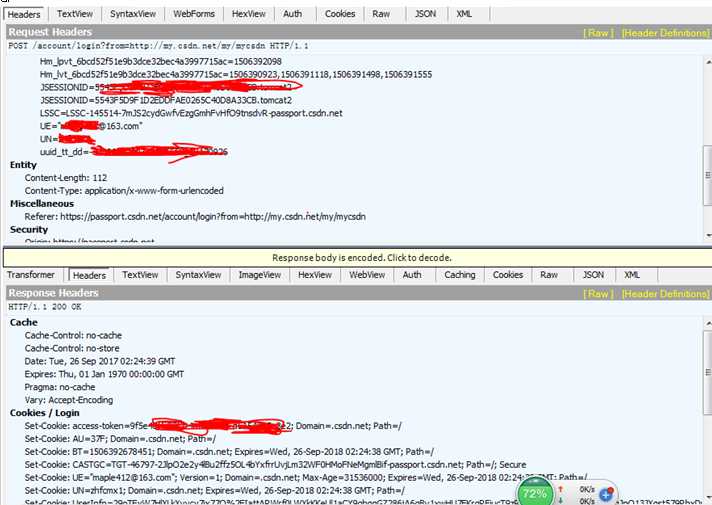
构造的cookie值
cookie={‘JSESSIONID‘:‘5543aaaaaaaaaaaaaaaabbbbbB.tomcat2‘,
‘uuid_tt_dd‘:‘-411111111111119_20170926‘,‘JSESSIONID‘:‘2222222222222220265C40D8A33CB.tomcat2‘,
‘UN‘:‘XXXXX‘,‘UE‘:‘[email protected]‘,‘BT‘:‘334343481‘,‘LSSC‘:‘LSSC-145514-7aaaaaaaaaaazgGmhFvHfO9taaaaaaaR-passport.csdn.net‘,
‘Hm_lvt_6bcd52f51bbbbbb2bec4a3997715ac‘:‘15044213,150656493,15064444445,1534488843‘,‘Hm_lpvt_6bcd52f51bbbbbbbe32bec4a3997715ac‘:‘1506388843‘,
‘dc_tos‘:‘oabckz‘,‘dc_session_id‘:‘15063aaaa027_0.7098840409889817‘,‘__message_sys_msg_id‘:‘0‘,‘__message_gu_msg_id‘:‘0‘,‘__message_cnel_msg_id‘:‘0‘,‘__message_district_code‘:‘000000‘,‘__message_in_school‘:‘0‘}
但是这样的实现方式有一个问题,就是每次都需要获取到服务器发送的cookie值,自动化程度大大减低。其实requests库还有个功能可以在后续的报文交互中保存cookie值并自动发送.我们自管构造post的数据就可以了
首先来看下每次登陆的时候递交的值。有username, password还有lt,execution,_eventId这些字段。
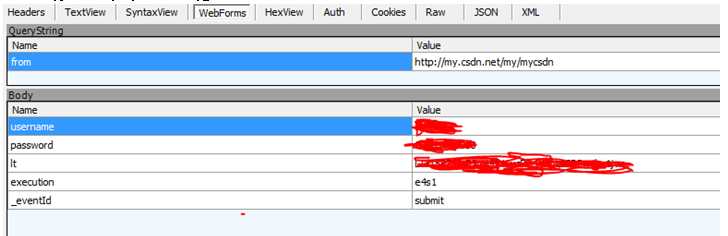
这些字段从哪获取呢, 通过查看CSDN网页登录的数据,找到了这几个字段,原来是输入框元素里面的属性数据

知道了所有数据的来源,那么就来构造程序代码:
header={‘Host‘:‘passport.csdn.net‘,‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36‘,
"Accept-Language":"zh-CN,zh;q=0.8",
"Accept-Encoding":"gzip, deflate",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
}
header1={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36‘,
"Accept-Language":"zh-CN,zh;q=0.8",
"Accept-Encoding":"gzip, deflate",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
}
url2=‘http://passport.csdn.net/account/login‘
‘‘‘建立一个session,这个session会保存交互过程中的cookie并在交互过程中发送‘‘‘
r=requests.Session()
s2=r.get(url2)
html=BeautifulSoup(s2.text,"html.parser")
‘‘‘通过BeautifulSoup的方法来爬去lt,execution的值‘‘‘
for input in html.find_all(‘input‘):
if ‘name‘ in input.attrs and input.attrs[‘name‘] == ‘lt‘:
lt=input.attrs[‘value‘]
if ‘name‘ in input.attrs and input.attrs[‘name‘] == ‘execution‘:
e1=input.attrs[‘value‘]
pay_load={‘username‘:‘xxxxx‘,‘password‘:‘xxxxxxx‘,‘lt‘:lt,‘execution‘:e1,‘_eventId‘:‘submit‘}
s=r.post(url2,headers=header,data=pay_load)
‘‘‘获取我的博客内容‘‘‘
s1=r.get(‘http://my.csdn.net/my/mycsdn‘,headers=header1)
通过这样的方式就避免了每次登陆都需要先获取cookie值,可以在任意时间进行自动登录。比固定cookie值登录的方法要方便很多
以上是关于python网络爬虫之requests库 二的主要内容,如果未能解决你的问题,请参考以下文章