Python 中的实用数据挖掘
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 中的实用数据挖掘相关的知识,希望对你有一定的参考价值。
本文是 2014 年 12 月我在布拉格经济大学做的名为‘ Python 数据科学’讲座的笔记。欢迎通过 @RadimRehurek 进行提问和评论。
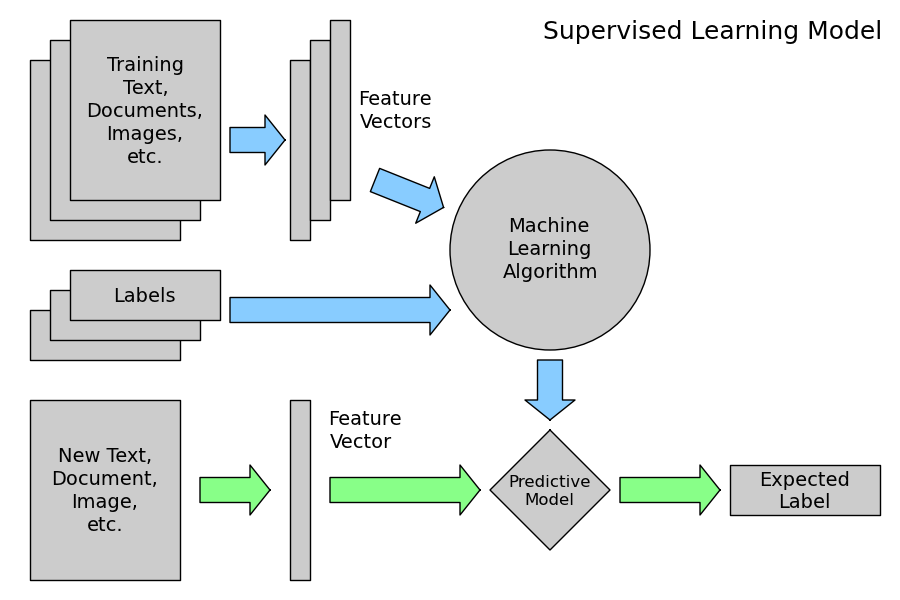
本次讲座的目的是展示一些关于机器学习的高级概念。该笔记中用具体的代码来做演示,大家可以在自己的电脑上运行(需要安装 IPython,如下所示)。
本次讲座的听众需要了解一些基础的编程(不一定是 Python),并拥有一点基本的数据挖掘背景。本次讲座不是机器学习专家的“高级演讲”。
这些代码实例创建了一个有效的、可执行的原型系统:一个使用“spam”(垃圾信息)或“ham”(非垃圾信息)对英文手机短信(”短信类型“的英文)进行分类的 app。

整套代码使用 Python 语言。 python 是一种在管线(pipeline)的所有环节(I/O、数据清洗重整和预处理、模型训练和评估)都好用的通用语言。尽管 python 不是唯一选择,但它灵活、易于开发,性能优越,这得益于它成熟的科学计算生态系统。Python 庞大的、开源生态系统同时避免了任何单一框架或库的限制(以及相关的信息丢失)。
$ ipython notebook data_science_python.ipynb|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
%matplotlib inline
import matplotlib.pyplot as plt
import csv
from textblob import TextBlob
import pandas
import sklearn
import cPickle
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import SVC, LinearSVC
from sklearn.metrics import classification_report, f1_score, accuracy_score, confusion_matrix
from sklearn.pipeline import Pipeline
from sklearn.grid_search import GridSearchCV
from sklearn.cross_validation import StratifiedKFold, cross_val_score, train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.learning_curve import learning_curve
|
第一步:加载数据,浏览一下
|
1
2
3
4
5
|
$ <span class="kw">ls</span> -l data
<span class="kw">total</span> 1352
<span class="kw">-rw-r--r--@</span> 1 kofola staff 477907 Mar 15 2011 SMSSpamCollection
<span class="kw">-rw-r--r--@</span> 1 kofola staff 5868 Apr 18 2011 readme
<span class="kw">-rw-r-----@</span> 1 kofola staff 203415 Dec 1 15:30 smsspamcollection.zip
|
|
1
2
|
messages = [line.rstrip() for line in open(‘./data/SMSSpamCollection‘)]
print len(messages)
|
|
1
2
|
for message_no, message in enumerate(messages[:10]):
print message_no, message
|
|
1
2
3
4
5
6
7
8
9
10
|
0 ham Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...
1 ham Ok lar... Joking wif u oni...
2 spam Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C‘s apply 08452810075over18‘s
3 ham U dun say so early hor... U c already then say...
4 ham Nah I don‘t think he goes to usf, he lives around here though
5 spam FreeMsg Hey there darling it‘s been 3 week‘s now and no word back! I‘d like some fun you up for it still? Tb ok! XxX std chgs to send, £1.50 to rcv
6 ham Even my brother is not like to speak with me. They treat me like aids patent.
7 ham As per your request ‘Melle Melle (Oru Minnaminunginte Nurungu Vettam)‘ has been set as your callertune for all Callers. Press *9 to copy your friends Callertune
8 spam WINNER!! As a valued network customer you have been selected to receivea £900 prize reward! To claim call 09061701461. Claim code KL341. Valid 12 hours only.
9 spam Had your mobile 11 months or more? U R entitled to Update to the latest colour mobiles with camera for Free! Call The Mobile Update Co FREE on 08002986030
|
|
1
2
3
|
messages = pandas.read_csv(‘./data/SMSSpamCollection‘, sep=‘t‘, quoting=csv.QUOTE_NONE,
names=["label", "message"])
print messages
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
label message
0 ham Go until jurong point, crazy.. Available only ...
1 ham Ok lar... Joking wif u oni...
2 spam Free entry in 2 a wkly comp to win FA Cup fina...
3 ham U dun say so early hor... U c already then say...
4 ham Nah I don‘t think he goes to usf, he lives aro...
5 spam FreeMsg Hey there darling it‘s been 3 week‘s n...
6 ham Even my brother is not like to speak with me. ...
7 ham As per your request ‘Melle Melle (Oru Minnamin...
8 spam WINNER!! As a valued network customer you have...
9 spam Had your mobile 11 months or more? U R entitle...
10 ham I‘m gonna be home soon and i don‘t want to tal...
11 spam SIX chances to win CASH! From 100 to 20,000 po...
12 spam URGENT! You have won a 1 week FREE membership ...
13 ham I‘ve been searching for the right words to tha...
14 ham I HAVE A DATE ON SUNDAY WITH WILL!!
15 spam XXXMobileMovieClub: To use your credit, click ...
16 ham Oh k...i‘m watching here:)
17 ham Eh u remember how 2 spell his name... Yes i di...
18 ham Fine if that?s the way u feel. That?s the way ...
19 spam England v Macedonia - dont miss the goals/team...
20 ham Is that seriously how you spell his name?
21 ham I‘m going to try for 2 months ha ha only joking
22 ham So ü pay first lar... Then when is da stock co...
23 ham Aft i finish my lunch then i go str down lor. ...
24 ham Ffffffffff. Alright no way I can meet up with ...
25 ham Just forced myself to eat a slice. I‘m really ...
26 ham Lol your always so convincing.
27 ham Did you catch the bus ? Are you frying an egg ...
28 ham I‘m back &amp; we‘re packing the car now, I‘ll...
29 ham Ahhh. Work. I vaguely remember that! What does...
... ... ...
5544 ham Armand says get your ass over to epsilon
5545 ham U still havent got urself a jacket ah?
5546 ham I‘m taking derek &amp; taylor to walmart, if I...
5547 ham Hi its in durban are you still on this number
5548 ham Ic. There are a lotta childporn cars then.
5549 spam Had your contract mobile 11 Mnths? Latest Moto...
5550 ham No, I was trying it all weekend ;V
5551 ham You know, wot people wear. T shirts, jumpers, ...
5552 ham Cool, what time you think you can get here?
5553 ham Wen did you get so spiritual and deep. That‘s ...
5554 ham Have a safe trip to Nigeria. Wish you happines...
5555 ham Hahaha..use your brain dear
5556 ham Well keep in mind I‘ve only got enough gas for...
5557 ham Yeh. Indians was nice. Tho it did kane me off ...
5558 ham Yes i have. So that‘s why u texted. Pshew...mi...
5559 ham No. I meant the calculation is the same. That ...
5560 ham Sorry, I‘ll call later
5561 ham if you aren‘t here in the next &lt;#&gt; hou...
5562 ham Anything lor. Juz both of us lor.
5563 ham Get me out of this dump heap. My mom decided t...
5564 ham Ok lor... Sony ericsson salesman... I ask shuh...
5565 ham Ard 6 like dat lor.
5566 ham Why don‘t you wait ‘til at least wednesday to ...
5567 ham Huh y lei...
5568 spam REMINDER FROM O2: To get 2.50 pounds free call...
5569 spam This is the 2nd time we have tried 2 contact u...
5570 ham Will ü b going to esplanade fr home?
5571 ham Pity, * was in mood for that. So...any other s...
5572 ham The guy did some bitching but I acted like i‘d...
5573 ham Rofl. Its true to its name
[5574 rows x 2 columns]
|
|
1
|
messages.groupby(‘label‘).describe()
|
|
message
|
||
| label | ||
| ham | count | 4827 |
| unique | 4518 | |
| top | Sorry, I’ll call later | |
| freq | 30 | |
| spam | count | 747 |
| unique | 653 | |
| top | Please call our customer service representativ… | |
| freq | 4 |
|
1
2
|
messages[‘length‘] = messages[‘message‘].map(lambda text: len(text))
print messages.head()
|
|
1
2
3
4
5
6
|
label message length
0 ham Go until jurong point, crazy.. Available only ... 111
1 ham Ok lar... Joking wif u oni... 29
2 spam Free entry in 2 a wkly comp to win FA Cup fina... 155
3 ham U dun say so early hor... U c already then say... 49
4 ham Nah I don‘t think he goes to usf, he lives aro... 61
|
|
1
|
messages.length.plot(bins=20, kind=‘hist‘)
|
|
1
|
<matplotlib.axes._subplots.AxesSubplot at 0x10dd7a990>
|

|
1
|
messages.length.describe()
|
|
1
2
3
4
5
6
7
8
9
|
count 5574.000000
mean 80.604593
std 59.919970
min 2.000000
25% 36.000000
50% 62.000000
75% 122.000000
max 910.000000
Name: length, dtype: float64
|
|
1
|
print list(messages.message[messages.length > 900])
|
|
1
2
3
4
5
6
7
8
9
10
11
|
["For me the love should start with attraction.i should feel that I need her every time
around me.she should be the first thing which comes in my thoughts.I would start the day and
end it with her.she should be there every time I dream.love will be then when my every
breath has her name.my life should happen around her.my life will be named to her.I would
cry for her.will give all my happiness and take all her sorrows.I will be ready to fight
with anyone for her.I will be in love when I will be doing the craziest things for her.love
will be when I don‘t have to proove anyone that my girl is the most beautiful lady on the
whole planet.I will always be singing praises for her.love will be when I start up making
chicken curry and end up makiing sambar.life will be the most beautiful then.will get every
morning and thank god for the day because she is with me.I would like to say a lot..will
tell later.."]
|
|
1
|
messages.hist(column=‘length‘, by=‘label‘, bins=50)
|
|
1
2
|
array([<matplotlib.axes._subplots.AxesSubplot object at 0x11270da50>,
<matplotlib.axes._subplots.AxesSubplot object at 0x1126c7750>], dtype=object)
|

第二步:数据预处理
|
1
2
3
|
def split_into_tokens(message):
message = unicode(message, ‘utf8‘) # convert bytes into proper unicode
return TextBlob(message).words
|
|
1
|
messages.message.head()
|
|
1
2
3
4
5
6
|
0 Go until jurong point, crazy.. Available only ...
1 Ok lar... Joking wif u oni...
2 Free entry in 2 a wkly comp to win FA Cup fina...
3 U dun say so early hor... U c already then say...
4 Nah I don‘t think he goes to usf, he lives aro...
Name: message, dtype: object
|
|
1
|
messages.message.head().apply(split_into_tokens)
|
|
1
2
3
4
5
6
|
0 [Go, until, jurong, point, crazy, Available, o...
1 [Ok, lar, Joking, wif, u, oni]
2 [Free, entry, in, 2, a, wkly, comp, to, win, F...
3 [U, dun, say, so, early, hor, U, c, already, t...
4 [Nah, I, do, n‘t, think, he, goes, to, usf, he...
Name: message, dtype: object
|
- 大写字母是否携带信息?
- 单词的不同形式(“goes”和“go”)是否携带信息?
- 叹词和限定词是否携带信息?
换句话说,我们想对文本进行更好的标准化。
我们使用 textblob 获取 part-of-speech (POS) 标签:
|
1
|
TextBlob("Hello world, how is it going?").tags # list of (word, POS) pairs
|
|
1
2
3
4
5
6
|
[(u‘Hello‘, u‘UH‘),
(u‘world‘, u‘NN‘),
(u‘how‘, u‘WRB‘),
(u‘is‘, u‘VBZ‘),
(u‘it‘, u‘PRP‘),
(u‘going‘, u‘VBG‘)]
|
|
1
2
3
4
5
6
7
|
def split_into_lemmas(message):
message = unicode(message, ‘utf8‘).lower()
words = TextBlob(message).words
# for each word, take its "base form" = lemma
return [word.lemma for word in words]
messages.message.head().apply(split_into_lemmas)
|
|
1
2
3
4
5
6
|
0 [go, until, jurong, point, crazy, available, o...
1 [ok, lar, joking, wif, u, oni]
2 [free, entry, in, 2, a, wkly, comp, to, win, f...
3 [u, dun, say, so, early, hor, u, c, already, t...
4 [nah, i, do, n‘t, think, he, go, to, usf, he, ...
Name: message, dtype: object
|
第三步:数据转换为向量
现在,我们将每条消息(词干列表)转换成机器学习模型可以理解的向量。
用词袋模型完成这项工作需要三个步骤:
每个向量的维度等于 SMS 语料库中包含的独立词的数量。
|
1
2
|
bow_transformer = CountVectorizer(analyzer=split_into_lemmas).fit(messages[‘message‘])
print len(bow_transformer.vocabulary_)
|
|
1
|
8874
|
这里我们使用强大的 python 机器学习训练库 scikit-learn (sklearn),它包含大量的方法和选项。
我们取一个信息并使用新的 bow_tramsformer 获取向量形式的词袋模型计数:
|
1
2
|
message4 = messages[‘message‘][3]
print message4
|
|
1
|
U dun say so early hor... U c already then say...
|
|
1
2
3
|
bow4 = bow_transformer.transform([message4])
print bow4
print bow4.shape
|
|
1
2
3
4
5
6
7
8
9
10
|
(0, 1158) 1
(0, 1899) 1
(0, 2897) 1
(0, 2927) 1
(0, 4021) 1
(0, 6736) 2
(0, 7111) 1
(0, 7698) 1
(0, 8013) 2
(1, 8874)
|
message 4 中有 9 个独立词,它们中的两个出现了两次,其余的只出现了一次。可用性检测,哪些词出现了两次?
|
1
2
|
print bow_transformer.get_feature_names()[6736]
print bow_transformer.get_feature_names()[8013]
|
|
1
2
|
say
u
|
整个 SMS 语料库的词袋计数是一个庞大的稀疏矩阵:
|
1
2
3
4
|
messages_bow = bow_transformer.transform(messages[‘message‘])
print ‘sparse matrix shape:‘, messages_bow.shape
print ‘number of non-zeros:‘, messages_bow.nnz
print ‘sparsity: %.2f%%‘ % (100.0 * messages_bow.nnz / (messages_bow.shape[0] * messages_bow.shape[1]))
|
|
1
2
3
|
sparse matrix shape: (5574, 8874)
number of non-zeros: 80272
sparsity: 0.16%
|
最终,计数后,使用 scikit-learn 的 TFidfTransformer 实现的 TF-IDF 完成词语加权和归一化。
|
1
2
3
|
tfidf_transformer = TfidfTransformer().fit(messages_bow)
tfidf4 = tfidf_transformer.transform(bow4)
print tfidf4
|
|
1
2
3
4
5
6
7
8
9
|
(0, 8013) 0.305114653686
(0, 7698) 0.225299911221
(0, 7111) 0.191390347987
(0, 6736) 0.523371210191
(0, 4021) 0.456354991921
(0, 2927) 0.32967579251
(0, 2897) 0.303693312742
(0, 1899) 0.24664322833
(0, 1158) 0.274934159477
|
单词 “u” 的 IDF(逆向文件频率)是什么?单词“university”的 IDF 又是什么?
|
1
2
|
print tfidf_transformer.idf_[bow_transformer.vocabulary_[‘u‘]]
print tfidf_transformer.idf_[bow_transformer.vocabulary_[‘university‘]]
|
|
1
2
|
2.85068150539
8.23975323521
|
将整个 bag-of-words 语料库转化为 TF-IDF 语料库。
|
1
2
|
messages_tfidf = tfidf_transformer.transform(messages_bow)
print messages_tfidf.shape
|
|
1
|
(5574, 8874)
|
第四步:训练模型,检测垃圾信息
我们使用向量形式的信息来训练 spam/ham 分类器。这部分很简单,有很多实现训练算法的库文件。
这里我们使用 scikit-learn,首先选择 Naive Bayes 分类器:
|
1
|
%time spam_detector = MultinomialNB().fit(messages_tfidf, messages[‘label‘])
|
|
1
2
|
CPU times: user 4.51 ms, sys: 987 μs, total: 5.49 ms
Wall time: 4.77 ms
|
我们来试着分类一个随机信息:
|
1
2
|
print ‘predicted:‘, spam_detector.predict(tfidf4)[0]
print ‘expected:‘, messages.label[3]
|
|
1
2
|
predicted: ham
expected: ham
|
太棒了!你也可以用自己的文本试试。
有一个很自然的问题是:我们可以正确分辨多少信息?
|
1
2
|
all_predictions = spam_detector.predict(messages_tfidf)
print all_predictions
|
|
1
|
[‘ham‘ ‘ham‘ ‘spam‘ ..., ‘ham‘ ‘ham‘ ‘ham‘]
|
|
1
2
3
|
print ‘accuracy‘, accuracy_score(messages[‘label‘], all_predictions)
print ‘confusion matrixn‘, confusion_matrix(messages[‘label‘], all_predictions)
print ‘(row=expected, col=predicted)‘
|
|
1
2
3
4
5
|
accuracy 0.969501255831
confusion matrix
[[4827 0]
[ 170 577]]
(row=expected, col=predicted)
|
|
1
2
3
4
5
|
plt.matshow(confusion_matrix(messages[‘label‘], all_predictions), cmap=plt.cm.binary, interpolation=‘nearest‘)
plt.title(‘confusion matrix‘)
plt.colorbar()
plt.ylabel(‘expected label‘)
plt.xlabel(‘predicted label‘)
|
|
1
|
<matplotlib.text.Text at 0x11643f6d0>
|

|
1
|
print classification_report(messages[‘label‘], all_predictions)
|
|
1
2
3
4
5
6
|
precision recall f1-score support
ham 0.97 1.00 0.98 4827
spam 1.00 0.77 0.87 747
avg / total 0.97 0.97 0.97 5574
|
有相当多的指标都可以用来评估模型性能,至于哪个最合适是由任务决定的。比如,将“spam”错误预测为“ham”的成本远低于将“ham”错误预测为“spam”的成本。
第五步:如何进行实验?
在上述“评价”中,我们犯了个大忌。为了简单的演示,我们使用训练数据进行了准确性评估。永远不要评估你的训练数据。这是错误的。
这样的评估方法不能告诉我们模型的实际预测能力,如果我们记住训练期间的每个例子,训练的准确率将非常接近 100%,但是我们不能用它来分类任何新信息。
一个正确的做法是将数据分为训练集和测试集,在模型拟合和调参时只能使用训练数据,不能以任何方式使用测试数据,通过这个方法确保模型没有“作弊”,最终使用测试数据评价模型可以代表模型真正的预测性能。
|
1
2
3
4
|
msg_train, msg_test, label_train, label_test =
train_test_split(messages[‘message‘], messages[‘label‘], test_size=0.2)
print len(msg_train), len(msg_test), len(msg_train) + len(msg_test)
|
|
1
|
4459 1115 5574
|
让我们回顾整个流程,将所有步骤放入 scikit-learn 的 Pipeline 中:
|
1
2
3
4
5
6
7
8
9
10
11
|
def split_into_lemmas(message):
message = unicode(message, ‘utf8‘).lower()
words = TextBlob(message).words
# for each word, take its "base form" = lemma
return [word.lemma for word in words]
pipeline = Pipeline([
(‘bow‘, CountVectorizer(analyzer=split_into_lemmas)), # strings to token integer counts
(‘tfidf‘, TfidfTransformer()), # integer counts to weighted TF-IDF scores
(‘classifier‘, MultinomialNB()), # train on TF-IDF vectors w/ Naive Bayes classifier
])
|
在这个例子里,一切进展顺利:
|
1
2
3
4
5
6
7
8
|
scores = cross_val_score(pipeline, # steps to convert raw messages into models
msg_train, # training data
label_train, # training labels
cv=10, # split data randomly into 10 parts: 9 for training, 1 for scoring
scoring=‘accuracy‘, # which scoring metric?
n_jobs=-1, # -1 = use all cores = faster
)
print scores
|
|
1
2
|
[ 0.93736018 0.96420582 0.94854586 0.94183445 0.96412556 0.94382022
0.94606742 0.96404494 0.94831461 0.94606742]
|
得分确实比训练全部数据时差一点点( 5574 个训练例子中,准确性 0.97),但是它们相当稳定:
|
1
|
print scores.mean(), scores.std()
|
|
1
|
0.9504386476 0.00947200821389
|
我们自然会问,如何改进这个模型?这个得分已经很高了,但是我们通常如何改进模型呢?
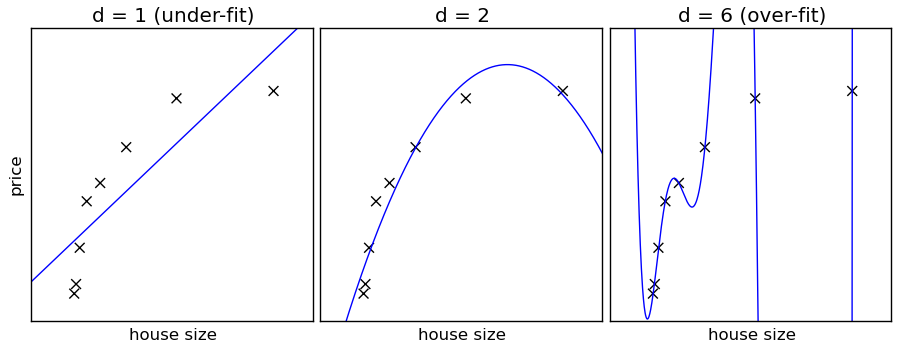
换句话说:
- 高偏差 = 分类器比较固执。它有自己的想法,数据能够改变的空间有限。另一方面,也没有多少过度拟合的空间(左图)。
- 低偏差 = 分类器更听话,但也更神经质。大家都知道,让它做什么就做什么可能造成麻烦(右图)。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=-1, train_sizes=np.linspace(.1, 1.0, 5)):
"""
Generate a simple plot of the test and traning learning curve.
Parameters
----------
estimator : object type that implements the "fit" and "predict" methods
An object of that type which is cloned for each validation.
title : string
Title for the chart.
X : array-like, shape (n_samples, n_features)
Training vector, where n_samples is the number of samples and
n_features is the number of features.
y : array-like, shape (n_samples) or (n_samples, n_features), optional
Target relative to X for classification or regression;
None for unsupervised learning.
ylim : tuple, shape (ymin, ymax), optional
Defines minimum and maximum yvalues plotted.
cv : integer, cross-validation generator, optional
If an integer is passed, it is the number of folds (defaults to 3).
Specific cross-validation objects can be passed, see
sklearn.cross_validation module for the list of possible objects
n_jobs : integer, optional
Number of jobs to run in parallel (default 1).
"""
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, ‘o-‘, color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, ‘o-‘, color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
|
|
1
|
%time plot_learning_curve(pipeline, "accuracy vs. training set size", msg_train, label_train, cv=5)
|
|
1
2
|
CPU times: user 382 ms, sys: 83.1 ms, total: 465 ms
Wall time: 28.5 s
|
|
1
|
<module ‘matplotlib.pyplot‘ from ‘/Volumes/work/workspace/vew/sklearn_intro/lib/python2.7/site-packages/matplotlib/pyplot.pyc‘>
|

随着性能的提升,训练和交叉验证都表现良好,我们发现由于数据量较少,这个模型难以足够复杂/灵活地捕获所有的细微差别。在这种特殊案例中,不管怎样做精度都很高,这个问题看起来不是很明显。
关于这一点,我们有两个选择:
- 使用更多的训练数据,增加模型的复杂性;
- 使用更复杂(更低偏差)的模型,从现有数据中获取更多信息。
在过去的几年里,随着收集大规模训练数据越来越容易,机器越来越快。方法 1 变得越来越流行(更简单的算法,更多的数据)。简单的算法(如 Naive Bayes)也有更容易解释的额外优势(相对一些更复杂的黑箱模型,如神经网络)。
第六步:如何调整参数?
到目前为止,我们看到的只是冰山一角,还有许多其它参数需要调整。比如使用什么算法进行训练。
上面我们已经使用了 Navie Bayes,但是 scikit-learn 支持许多分类器:支持向量机、最邻近算法、决策树、Ensamble 方法等…
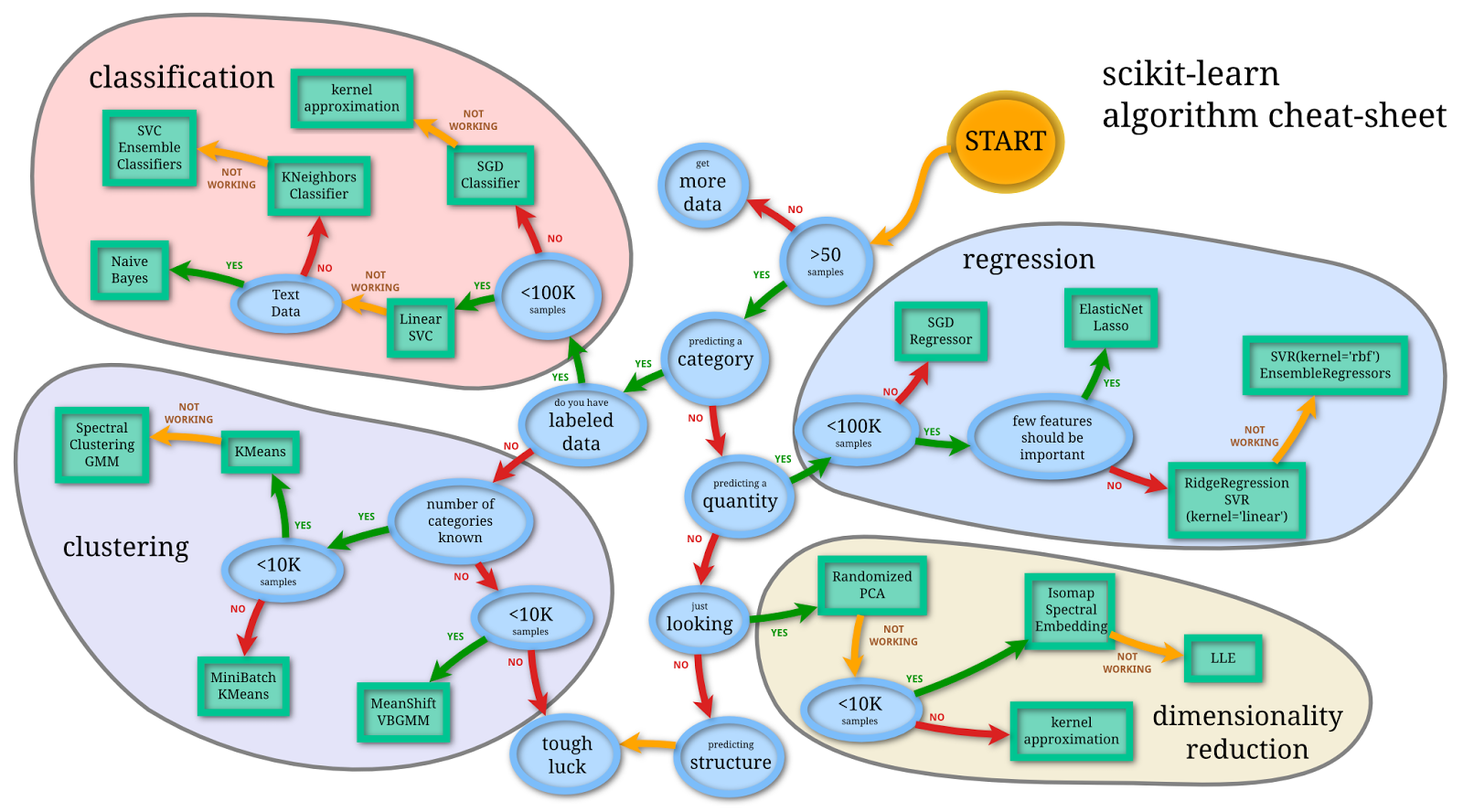
我们会问:IDF 加权对准确性有什么影响?消耗额外成本进行词形还原(与只用纯文字相比)真的会有效果吗?
让我们来看看:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
params = {
‘tfidf__use_idf‘: (True, False),
‘bow__analyzer‘: (split_into_lemmas, split_into_tokens),
}
grid = GridSearchCV(
pipeline, # pipeline from above
params, # parameters to tune via cross validation
refit=True, # fit using all available data at the end, on the best found param combination
n_jobs=-1, # number of cores to use for parallelization; -1 for "all cores"
scoring=‘accuracy‘, # what score are we optimizing?
cv=StratifiedKFold(label_train, n_folds=5), # what type of cross validation to use
)
|
|
1
2
3
|
%time nb_detector = grid.fit(msg_train, label_train)
print nb_detector.grid_scores_
|
|
1
2
3
|
CPU times: user 4.09 s, sys: 291 ms, total: 4.38 s
Wall time: 20.2 s
[mean: 0.94752, std: 0.00357, params: {‘tfidf__use_idf‘: True, ‘bow__analyzer‘: <function split_into_lemmas at 0x1131e8668>}, mean: 0.92958, std: 0.00390, params: {‘tfidf__use_idf‘: False, ‘bow__analyzer‘: <function split_into_lemmas at 0x1131e8668>}, mean: 0.94528, std: 0.00259, params: {‘tfidf__use_idf‘: True, ‘bow__analyzer‘: <function split_into_tokens at 0x11270b7d0>}, mean: 0.92868, std: 0.00240, params: {‘tfidf__use_idf‘: False, ‘bow__analyzer‘: <function split_into_tokens at 0x11270b7d0>}]
|
(首先显示最佳参数组合:在这个案例中是使用 idf=True 和 analyzer=split_into_lemmas 的参数组合)
快速合理性检查
|
1
2
|
print nb_detector.predict_proba(["Hi mom, how are you?"])[0]
print nb_detector.predict_proba(["WINNER! Credit for free!"])[0]
|
|
1
2
|
[ 0.99383955 0.00616045]
[ 0.29663109 0.70336891]
|
predict_proba 返回每类(ham,spam)的预测概率。在第一个例子中,消息被预测为 ham 的概率 >99%,被预测为 spam 的概率 <1%。如果进行选择模型会认为信息是 ”ham“:
|
1
2
|
print nb_detector.predict(["Hi mom, how are you?"])[0]
print nb_detector.predict(["WINNER! Credit for free!"])[0]
|
|
1
2
|
ham
spam
|
在训练期间没有用到的测试集的整体得分:
|
1
2
3
|
predictions = nb_detector.predict(msg_test)
print confusion_matrix(label_test, predictions)
print classification_report(label_test, predictions)
|
|
1
2
3
4
5
6
7
8
|
[[973 0]
[ 46 96]]
precision recall f1-score support
ham 0.95 1.00 0.98 973
spam 1.00 0.68 0.81 142
avg / total 0.96 0.96 0.96 1115
|
让我们尝试另一个分类器:支持向量机(SVM)。SVM 可以非常迅速的得到结果,它所需要的参数调整也很少(虽然比 Navie Bayes 稍多一点),在处理文本数据方面它是个好的起点。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
pipeline_svm = Pipeline([
(‘bow‘, CountVectorizer(analyzer=split_into_lemmas)),
(‘tfidf‘, TfidfTransformer()),
(‘classifier‘, SVC()), # <== change here
])
# pipeline parameters to automatically explore and tune
param_svm = [
{‘classifier__C‘: [1, 10, 100, 1000], ‘classifier__kernel‘: [‘linear‘]},
{‘classifier__C‘: [1, 10, 100, 1000], ‘classifier__gamma‘: [0.001, 0.0001], ‘classifier__kernel‘: [‘rbf‘]},
]
grid_svm = GridSearchCV(
pipeline_svm, # pipeline from above
param_grid=param_svm, # parameters to tune via cross validation
refit=True, # fit using all data, on the best detected classifier
n_jobs=-1, # number of cores to use for parallelization; -1 for "all cores"
scoring=‘accuracy‘, # what score are we optimizing?
cv=StratifiedKFold(label_train, n_folds=5), # what type of cross validation to use
)
|
|
1
2
3
|
%time svm_detector = grid_svm.fit(msg_train, label_train) # find the best combination from param_svm
print svm_detector.grid_scores_
|
|
1
2
3
|
CPU times: user 5.24 s, sys: 170 ms, total: 5.41 s
Wall time: 1min 8s
[mean: 0.98677, std: 0.00259, params: {‘classifier__kernel‘: ‘linear‘, ‘classifier__C‘: 1}, mean: 0.98654, std: 0.00100, params: {‘classifier__kernel‘: ‘linear‘, ‘classifier__C‘: 10}, mean: 0.98654, std: 0.00100, params: {‘classifier__kernel‘: ‘linear‘, ‘classifier__C‘: 100}, mean: 0.98654, std: 0.00100, params: {‘classifier__kernel‘: ‘linear‘, ‘classifier__C‘: 1000}, mean: 0.86432, std: 0.00006, params: {‘classifier__gamma‘: 0.001, ‘classifier__kernel‘: ‘rbf‘, ‘classifier__C‘: 1}, mean: 0.86432, std: 0.00006, params: {‘classifier__gamma‘: 0.0001, ‘classifier__kernel‘: ‘rbf‘, ‘classifier__C‘: 1}, mean: 0.86432, std: 0.00006, params: {‘classifier__gamma‘: 0.001, ‘classifier__kernel‘: ‘rbf‘, ‘classifier__C‘: 10}, mean: 0.86432, std: 0.00006, params |