python操作RabbitMQ
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python操作RabbitMQ相关的知识,希望对你有一定的参考价值。
介绍
RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
安装
RabbitMQ 下载地址:http://www.rabbitmq.com/install-standalone-mac.html
安装配置epel源 $ rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm 安装erlang $ yum -y install erlang 安装RabbitMQ $ yum -y install rabbitmq-server
使用
官方使用文档:http://www.rabbitmq.com/getstarted.html
1.实现最简单的队列通信

#!/usr/bin/env python #一个简单的发数据send端,一对一模式(生产者) import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host=‘localhost‘)) #初始化连接,连接到RabbitMQ channel = connection.channel() #生成一个连接管道 channel.queue_declare(queue=‘hello‘) #声明一个队列名
#生产消息 channel.basic_publish(exchange=‘‘, routing_key=‘hello‘, #要发送到那个队列中 body=‘Hello World!‘ #发送的内容 ) print(" [x] Sent ‘Hello World!‘") connection.close() #关闭RabbitMQ的连接
#!/usr/bin/env python
#一个简单的recvive端,一对一模式(消费者)
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host=‘localhost‘)) #初始化连接,连接到RabbitMQ
channel = connection.channel() #生成一个连接管道
channel.queue_declare(queue=‘hello‘) #这里也要声明一下队列的名称,如果客户端启动,服务端没有启动,没有声明会报错
def callback(ch, method, properties, body): #定义一个接收到消息之后的回调函数
print(" [x] Received %r" % body)
#消费消息
channel.basic_consume(callback, #当接收到一个消息之后回调CALLBACk函数处理
queue=‘hello‘, #定义那个队列中去取,消息
no_ack=True #这个意思是不返回确认,消息处理完成之后返回确认,RabbitMQ从队列中删除,一般不用
)
print(‘ [*] Waiting for messages. To exit press CTRL+C‘)
channel.start_consuming() #启动连接,如果没有数据接收就会一直等待,不会停止
2. Work Queues

在这种模式下,RabbitMQ会默认把p发的消息依次分发给各个消费者(c),跟负载均衡差不多
RabbitMQ持久化与公平分发
1)acknowledgment 消息不丢失的方法
生效方法:channel.basic_consume(consumer_callback, queue, no_ack=False, exclusive=False, consumer_tag=None, arguments=None)
即no_ack=False(默认为False,即必须有确认标识),在回调函数consumer_callback中,未收到确认标识,那么,RabbitMQ会重新将该任务添加到队列中。(消费者端)
2) 消息持久化
虽然有了消息反馈机制,但是如果rabbitmq自身挂掉的话,那么任务还是会丢失。所以需要将任务持久化存储起来。声明持久化存储
channel.queue_declare(queue=‘hello‘, durable=True) # 声明队列持久化
Ps: 但是这样程序会执行错误,因为‘hello’这个队列已经存在,并且是非持久化的,rabbitmq不允许使用不同的参数来重新定义存在的队列。因此需要重新定义一个队列
channel.queue_declare(queue=‘test_queue‘, durable=True) # 声明队列持久化
注意:如果仅仅是设置了队列的持久化,仅队列本身可以在rabbit-server宕机后保留,队列中的信息依然会丢失,如果想让队列中的信息或者任务保留,还需要做以下设置:
channel.basic_publish(exchange=‘‘,
routing_key="test_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # 使消息或任务也持久化存储
))
消息队列持久化包括3个部分:
(1)exchange持久化,在声明时指定durable => 1
(2)queue持久化,在声明时指定durable => 1
(3)消息持久化,在投递时指定delivery_mode=> 2(1是非持久化)
如果exchange和queue都是持久化的,那么它们之间的binding也是持久化的。如果exchange和queue两者之间有一个持久化,一个非持久化,就不允许建立绑定。
3) 消息公平分发

如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列
带消息持久化+公平分发的完整代码
生产者端:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host=‘localhost‘))
channel = connection.channel()
channel.queue_declare(queue=‘task_queue‘, durable=True)
message = ‘ ‘.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange=‘‘,
routing_key=‘task_queue‘,
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
print(" [x] Sent %r" % message)
connection.close()
消费者端:
#!/usr/bin/env python
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host=‘localhost‘))
channel = connection.channel()
channel.queue_declare(queue=‘task_queue‘, durable=True)
print(‘ [*] Waiting for messages. To exit press CTRL+C‘)
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(body.count(b‘.‘)) #模拟处理操作
print(" [x] Done")
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1) #消息公平分发,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了
channel.basic_consume(callback,
queue=‘task_queue‘)
channel.start_consuming()
3. 发布订阅
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
exchange_type = fanout
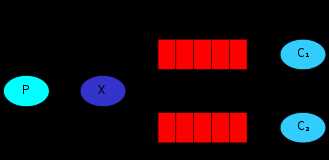
发布者:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host=‘localhost‘))
channel = connection.channel()
channel.exchange_declare(exchange=‘logs‘,
exchange_type=‘fanout‘)
message = ‘ ‘.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange=‘logs‘,
routing_key=‘‘,
body=message)
print(" [x] Sent %r" % message)
connection.close()
订阅者:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host=‘localhost‘))
channel = connection.channel()
channel.exchange_declare(exchange=‘logs‘,
exchange_type=‘fanout‘)
result = channel.queue_declare(exclusive = True) #不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue
channel.queue_bind(exchange = ‘logs‘, #绑定
queue = queue_name)
print(‘ [*] Waiting for logs. To exit press CTRL+C‘)
print(‘randome queuename:‘,queue_name)
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue = queue_name,
no_ack = True
)
channel.start_consuming()
4. 有选择的接受消息(关键字发送)
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
exchange_type = direct
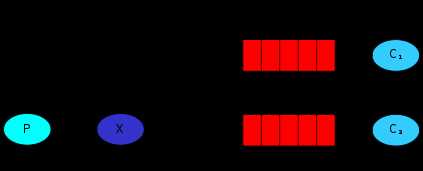
publisher:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host = ‘localhost‘))
channel = connection.channel()
channel.exchange_declare(exchange = ‘direct_logs‘,
exchange_type = ‘direct‘)
severity = sys.argv[1] if len(sys.argv) > 1 else ‘info‘
message = ‘ ‘.join(sys.argv[2:]) or ‘Hello World!‘
channel.basic_publish(exchange = ‘direct_logs‘,
routing_key = severity,
body = message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
subscriber:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host = ‘localhost‘))
channel = connection.channel()
channel.exchange_declare(exchange = ‘direct_logs‘,
exchange_type = ‘direct‘)
result = channel.queue_declare(exclusive = True)
queue_name = result.method.queue
severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\\n" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange = ‘direct_logs‘,
queue = queue_name,
routing_key = severity)
print(‘ [*] Waiting for logs. To exit press CTRL+C‘)
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue = queue_name,
no_ack = True)
channel.start_consuming()
5. 更细致的消息过滤(模糊匹配)
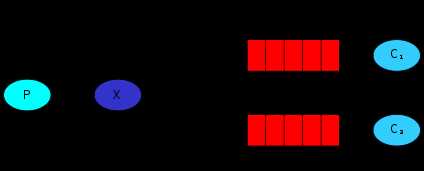
exchange_type = topic
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
- # 表示可以匹配 0 个 或 多个 单词
- * 表示只能匹配 一个 单词
发送者路由值 队列中 error.info.warning error.* //不匹配 error.info.warning error.# //匹配
消费者:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host = ‘localhost‘))
channel = connection.channel()
channel.exchange_declare(exchange = ‘topic_logs‘,
exchange_type = ‘topic‘)
result = channel.queue_declare(exclusive = True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\\n" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange = ‘topic_logs‘,
queue = queue_name,
routing_key = binding_key)
print(‘ [*] Waiting for logs. To exit press CTRL+C‘)
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue = queue_name,
no_ack = True)
channel.start_consuming()
生产者:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host = ‘localhost‘))
channel = connection.channel()
channel.exchange_declare(exchange = ‘topic_logs‘,
exchange_type = ‘topic‘)
routing_key = sys.argv[1] if len(sys.argv) > 1 else ‘anonymous.info‘
message = ‘ ‘.join(sys.argv[2:]) or ‘Hello World!‘
channel.basic_publish(exchange = ‘topic_logs‘,
routing_key = routing_key,
body = message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
其他


#添加账户 sudo rabbitmqctl add_user musker 123.com # 设置用户为administrator角色 sudo rabbitmqctl set_user_tags musker administrator # 设置权限 sudo rabbitmqctl set_permissions -p "/" musker‘.‘‘.‘‘.‘ # 然后重启rabbiMQ服务 sudo /etc/init.d/rabbitmq-server restart # 可以使用的用户远程连接rabbitmq server了。 credentials = pika.PlainCredentials("musker","123.com") connection = pika.BlockingConnection(pika.ConnectionParameters(‘192.168.14.47‘,credentials=credentials)) #查看队列和消息数量 rabbitmqctl list_queues
以上是关于python操作RabbitMQ的主要内容,如果未能解决你的问题,请参考以下文章