Python面向对象-高级用法
Posted Geoffrey
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python面向对象-高级用法相关的知识,希望对你有一定的参考价值。
1.魔法函数
python中常见的内置类型

什么是魔法函数?
python的魔法函数总被双下划线包围,它们可以给你的类增加特殊的方法。如果你的对象实现了这些方法中的一个,那么这个方法就会在特殊情况下被调用,你可以定义想要
的行为,而这一切都是自动发生的。
魔法函数一览

魔法函数举例
1.1.__getitem__
把对象变成可迭代的对象
例子:
class Company(object):
def __init__(self,employee_list):
self.employee = employee_list
#魔法函数,给类加可迭代类型
def __getitem__(self, item):
return self.employee[item]
company = Company([\'11\',\'22\',\'33\'])
#加了魔法函数“__getitem__”,类就成了可迭代的了
for em in company:
print(em) #11,22,33
如果不用魔法函数循环出每个员工的方法
class Company(object):
def __init__(self,employee_list):
self.employee = employee_list
company = Company([\'11\',\'22\',\'33\'])
for em in company.employee:
print(em)
还可以切片和获取长度
class Company(object):
def __init__(self,employee_list):
self.employee = employee_list
#魔法函数
def __getitem__(self, item):
return self.employee[item]
company = Company([\'11\',\'22\',\'33\'])
#可以切片
company1 = company[:2]
#可以判断len长度
print(len(company1)) #2
for em in company1:
print(em) #11,22
1.2.__len__
class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
#
# def __getitem__(self, item):
# return self.employee[item]
def __len__(self):
return len(self.employee)
company = Company(["11", "22", "33"])
#如果不加魔法函数,len(company)会报错的
print(len(company)) #3
1.3. __repr__和__str__
1.安装交互环境(jupyter)
pip install -i https://pypi.douban.com/simple ipython
pip install -i https://pypi.douban.com/simple notebook
#启动
ipython notebook
2.__repr__和__str__的用法


2.深入类和对象
1.1.鸭子类型和多态
“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
我们并不关心对象是什么类型,到底是不是鸭子,只关心行为。
实例一:
# 鸭子类型和多态简单实例
class Dog(object):
def say(self):
print(\'a dog\')
class Cat(object):
def say(self):
print(\'a cat\')
class Duck(object):
def say(self):
print(\'a duck\')
animal_list = [Dog,Cat,Duck]
for animal in animal_list:
animal().say()
#运行结果
a dog
a cat
a duck
实例二:
类只要实现了__getitem__方法,它就是可迭代的,并不关心对象的本身,只关心行为,然后就可以当做extend的参数。
class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
def __getitem__(self, item):
return self.employee[item]
company = Company(["11", "22", "33"])
a = [\'derek1\',\'derek2\']
name_set = set()
name_set.add(\'tom1\')
name_set.add((\'tom2\'))
#extend里面的参数介绍
#def extend(self, iterable): # real signature unknown; restored from __doc__
#""" L.extend(iterable) -> None -- extend list by appending elements from the iterable """
#extend里面可以添加任何可迭代的参数,给类添加一个魔法函数__getitem__,类就变成可迭代的,所以可以extend进去
a.extend(company)
print(a) #[\'derek1\', \'derek2\', \'11\', \'22\', \'33\']
a.extend(name_set)
print(a) #[\'derek1\', \'derek2\', \'11\', \'22\', \'33\', \'tom2\', \'tom1\']
1.2.抽象基类(abc模块)
抽象基类的作用类似于JAVA中的接口。在接口中定义各种方法,然后继承接口的各种类进行具体方法的实现。抽象基类就是定义各种方法而不做具体实现的类,任何继承自抽象基类的类必须实现这些方法,否则无法实例化
(1)判断类时候有某种属性
#判断类是否有某种属性
class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
def __len__(self):
return len(self.employee)
com = Company(["11", "22", "33"])
#hasattr判断类有没有某种属性,方法也是类的属性
print(hasattr(com,"__len__")) #True
#虽然用hasattr可以判断,但正确的方式是定义一个抽象基类
#我们在某些情况下希望判定某个对象的类型,可以用抽象基类
from collections.abc import Sized
print(isinstance(com,Sized)) #True
# print(len(com))
class Sized(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __len__(self):
return 0
@classmethod
def __subclasshook__(cls, C):
if cls is Sized:
return _check_methods(C, "__len__")
return NotImplemented
(2)abc模块
简单抽象基类实例
#模拟一个抽象基类
#写一个抽象基类,它的子类必须要重写抽象基类里面的方法
import abc
#定义一个抽象基类
class CacheBase(metaclass=abc.ABCMeta):
@abc.abstractclassmethod
def get(self,key):
pass
@abc.abstractclassmethod
def set(self,key,value):
pass
#子类,必须有抽象基类里面的方法,get和set
#假入不写set方法会报错
class RedisCache(CacheBase):
def get(self,key):
pass
# def set(self,key,value):
# pass
redis_cache = RedisCache()
#模拟一个抽象基类
#写一个抽象基类,它的子类必须要重写抽象基类里面的方法
import abc
#定义一个抽象基类
class CacheBase(metaclass=abc.ABCMeta):
@abc.abstractclassmethod
def get(self,key):
pass
@abc.abstractclassmethod
def set(self,key,value):
pass
#子类,必须有抽象基类里面的方法,get和set
#假入不写set方法会报错
class RedisCache(CacheBase):
def get(self,key):
pass
def set(self,key,value):
pass
redis_cache = RedisCache()

(3)abc里面所有的抽象基类
from collections.abc import *
所有的抽象基类
# Copyright 2007 Google, Inc. All Rights Reserved.
# Licensed to PSF under a Contributor Agreement.
"""Abstract Base Classes (ABCs) for collections, according to PEP 3119.
Unit tests are in test_collections.
"""
from abc import ABCMeta, abstractmethod
import sys
__all__ = ["Awaitable", "Coroutine",
"AsyncIterable", "AsyncIterator", "AsyncGenerator",
"Hashable", "Iterable", "Iterator", "Generator", "Reversible",
"Sized", "Container", "Callable", "Collection",
"Set", "MutableSet",
"Mapping", "MutableMapping",
"MappingView", "KeysView", "ItemsView", "ValuesView",
"Sequence", "MutableSequence",
"ByteString",
]
# This module has been renamed from collections.abc to _collections_abc to
# speed up interpreter startup. Some of the types such as MutableMapping are
# required early but collections module imports a lot of other modules.
# See issue #19218
__name__ = "collections.abc"
# Private list of types that we want to register with the various ABCs
# so that they will pass tests like:
# it = iter(somebytearray)
# assert isinstance(it, Iterable)
# Note: in other implementations, these types might not be distinct
# and they may have their own implementation specific types that
# are not included on this list.
bytes_iterator = type(iter(b\'\'))
bytearray_iterator = type(iter(bytearray()))
#callable_iterator = ???
dict_keyiterator = type(iter(.keys()))
dict_valueiterator = type(iter(.values()))
dict_itemiterator = type(iter(.items()))
list_iterator = type(iter([]))
list_reverseiterator = type(iter(reversed([])))
range_iterator = type(iter(range(0)))
longrange_iterator = type(iter(range(1 << 1000)))
set_iterator = type(iter(set()))
str_iterator = type(iter(""))
tuple_iterator = type(iter(()))
zip_iterator = type(iter(zip()))
## views ##
dict_keys = type(.keys())
dict_values = type(.values())
dict_items = type(.items())
## misc ##
mappingproxy = type(type.__dict__)
generator = type((lambda: (yield))())
## coroutine ##
async def _coro(): pass
_coro = _coro()
coroutine = type(_coro)
_coro.close() # Prevent ResourceWarning
del _coro
## asynchronous generator ##
async def _ag(): yield
_ag = _ag()
async_generator = type(_ag)
del _ag
### ONE-TRICK PONIES ###
def _check_methods(C, *methods):
mro = C.__mro__
for method in methods:
for B in mro:
if method in B.__dict__:
if B.__dict__[method] is None:
return NotImplemented
break
else:
return NotImplemented
return True
class Hashable(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __hash__(self):
return 0
@classmethod
def __subclasshook__(cls, C):
if cls is Hashable:
return _check_methods(C, "__hash__")
return NotImplemented
class Awaitable(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __await__(self):
yield
@classmethod
def __subclasshook__(cls, C):
if cls is Awaitable:
return _check_methods(C, "__await__")
return NotImplemented
class Coroutine(Awaitable):
__slots__ = ()
@abstractmethod
def send(self, value):
"""Send a value into the coroutine.
Return next yielded value or raise StopIteration.
"""
raise StopIteration
@abstractmethod
def throw(self, typ, val=None, tb=None):
"""Raise an exception in the coroutine.
Return next yielded value or raise StopIteration.
"""
if val is None:
if tb is None:
raise typ
val = typ()
if tb is not None:
val = val.with_traceback(tb)
raise val
def close(self):
"""Raise GeneratorExit inside coroutine.
"""
try:
self.throw(GeneratorExit)
except (GeneratorExit, StopIteration):
pass
else:
raise RuntimeError("coroutine ignored GeneratorExit")
@classmethod
def __subclasshook__(cls, C):
if cls is Coroutine:
return _check_methods(C, \'__await__\', \'send\', \'throw\', \'close\')
return NotImplemented
Coroutine.register(coroutine)
class AsyncIterable(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __aiter__(self):
return AsyncIterator()
@classmethod
def __subclasshook__(cls, C):
if cls is AsyncIterable:
return _check_methods(C, "__aiter__")
return NotImplemented
class AsyncIterator(AsyncIterable):
__slots__ = ()
@abstractmethod
async def __anext__(self):
"""Return the next item or raise StopAsyncIteration when exhausted."""
raise StopAsyncIteration
def __aiter__(self):
return self
@classmethod
def __subclasshook__(cls, C):
if cls is AsyncIterator:
return _check_methods(C, "__anext__", "__aiter__")
return NotImplemented
class AsyncGenerator(AsyncIterator):
__slots__ = ()
async def __anext__(self):
"""Return the next item from the asynchronous generator.
When exhausted, raise StopAsyncIteration.
"""
return await self.asend(None)
@abstractmethod
async def asend(self, value):
"""Send a value into the asynchronous generator.
Return next yielded value or raise StopAsyncIteration.
"""
raise StopAsyncIteration
@abstractmethod
async def athrow(self, typ, val=None, tb=None):
"""Raise an exception in the asynchronous generator.
Return next yielded value or raise StopAsyncIteration.
"""
if val is None:
if tb is None:
raise typ
val = typ()
if tb is not None:
val = val.with_traceback(tb)
raise val
async def aclose(self):
"""Raise GeneratorExit inside coroutine.
"""
try:
await self.athrow(GeneratorExit)
except (GeneratorExit, StopAsyncIteration):
pass
else:
raise RuntimeError("asynchronous generator ignored GeneratorExit")
@classmethod
def __subclasshook__(cls, C):
if cls is AsyncGenerator:
return _check_methods(C, \'__aiter__\', \'__anext__\',
\'asend\', \'athrow\', \'aclose\')
return NotImplemented
AsyncGenerator.register(async_generator)
class Iterable(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __iter__(self):
while False:
yield None
@classmethod
def __subclasshook__(cls, C):
if cls is Iterable:
return _check_methods(C, "__iter__")
return NotImplemented
class Iterator(Iterable):
__slots__ = ()
@abstractmethod
def __next__(self):
\'Return the next item from the iterator. When exhausted, raise StopIteration\'
raise StopIteration
def __iter__(self):
return self
@classmethod
def __subclasshook__(cls, C):
if cls is Iterator:
return _check_methods(C, \'__iter__\', \'__next__\')
return NotImplemented
Iterator.register(bytes_iterator)
Iterator.register(bytearray_iterator)
#Iterator.register(callable_iterator)
Iterator.register(dict_keyiterator)
Iterator.register(dict_valueiterator)
Iterator.register(dict_itemiterator)
Iterator.register(list_iterator)
Iterator.register(list_reverseiterator)
Iterator.register(range_iterator)
Iterator.register(longrange_iterator)
Iterator.register(set_iterator)
Iterator.register(str_iterator)
Iterator.register(tuple_iterator)
Iterator.register(zip_iterator)
class Reversible(Iterable):
__slots__ = ()
@abstractmethod
def __reversed__(self):
while False:
yield None
@classmethod
def __subclasshook__(cls, C):
if cls is Reversible:
return _check_methods(C, "__reversed__", "__iter__")
return NotImplemented
class Generator(Iterator):
__slots__ = ()
def __next__(self):
"""Return the next item from the generator.
When exhausted, raise StopIteration.
"""
return self.send(None)
@abstractmethod
def send(self, value):
"""Send a value into the generator.
Return next yielded value or raise StopIteration.
"""
raise StopIteration
@abstractmethod
def throw(self, typ, val=None, tb=None):
"""Raise an exception in the generator.
Return next yielded value or raise StopIteration.
"""
if val is None:
if tb is None:
raise typ
val = typ()
if tb is not None:
val = val.with_traceback(tb)
raise val
def close(self):
"""Raise GeneratorExit inside generator.
"""
try:
self.throw(GeneratorExit)
except (GeneratorExit, StopIteration):
pass
else:
raise RuntimeError("generator ignored GeneratorExit")
@classmethod
def __subclasshook__(cls, C):
if cls is Generator:
return _check_methods(C, \'__iter__\', \'__next__\',
\'send\', \'throw\', \'close\')
return NotImplemented
Generator.register(generator)
class Sized(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __len__(self):
return 0
@classmethod
def __subclasshook__(cls, C):
if cls is Sized:
return _check_methods(C, "__len__")
return NotImplemented
class Container(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __contains__(self, x):
return False
@classmethod
def __subclasshook__(cls, C):
if cls is Container:
return _check_methods(C, "__contains__")
return NotImplemented
class Collection(Sized, Iterable, Container):
__slots__ = ()
@classmethod
def __subclasshook__(cls, C):
if cls is Collection:
return _check_methods(C, "__len__", "__iter__", "__contains__")
return NotImplemented
class Callable(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __call__(self, *args, **kwds):
return False
@classmethod
def __subclasshook__(cls, C):
if cls is Callable:
return _check_methods(C, "__call__")
return NotImplemented
### SETS ###
class Set(Collection):
"""A set is a finite, iterable container.
This class provides concrete generic implementations of all
methods except for __contains__, __iter__ and __len__.
To override the comparisons (presumably for speed, as the
semantics are fixed), redefine __le__ and __ge__,
then the other operations will automatically follow suit.
"""
__slots__ = ()
def __le__(self, other):
if not isinstance(other, Set):
return NotImplemented
if len(self) > len(other):
return False
for elem in self:
if elem not in other:
return False
return True
def __lt__(self, other):
if not isinstance(other, Set):
return NotImplemented
return len(self) < len(other) and self.__le__(other)
def __gt__(self, other):
if not isinstance(other, Set):
return NotImplemented
return len(self) > len(other) and self.__ge__(other)
def __ge__(self, other):
if not isinstance(other, Set):
return NotImplemented
if len(self) < len(other):
return False
for elem in other:
if elem not in self:
return False
return True
def __eq__(self, other):
if not isinstance(other, Set):
return NotImplemented
return len(self) == len(other) and self.__le__(other)
@classmethod
def _from_iterable(cls, it):
\'\'\'Construct an instance of the class from any iterable input.
Must override this method if the class constructor signature
does not accept an iterable for an input.
\'\'\'
return cls(it)
def __and__(self, other):
if not isinstance(other, Iterable):
return NotImplemented
return self._from_iterable(value for value in other if value in self)
__rand__ = __and__
def isdisjoint(self, other):
\'Return True if two sets have a null intersection.\'
for value in other:
if value in self:
return False
return True
def __or__(self, other):
if not isinstance(other, Iterable):
return NotImplemented
chain = (e for s in (self, other) for e in s)
return self._from_iterable(chain)
__ror__ = __or__
def __sub__(self, other):
if not isinstance(other, Set):
if not isinstance(other, Iterable):
return NotImplemented
other = self._from_iterable(other)
return self._from_iterable(value for value in self
if value not in other)
def __rsub__(self, other):
if not isinstance(other, Set):
if not isinstance(other, Iterable):
return NotImplemented
other = self._from_iterable(other)
return self._from_iterable(value for value in other
if value not in self)
def __xor__(self, other):
if not isinstance(other, Set):
if not isinstance(other, Iterable):
return NotImplemented
other = self._from_iterable(other)
return (self - other) | (other - self)
__rxor__ = __xor__
def _hash(self):
"""Compute the hash value of a set.
Note that we don\'t define __hash__: not all sets are hashable.
But if you define a hashable set type, its __hash__ should
call this function.
This must be compatible __eq__.
All sets ought to compare equal if they contain the same
elements, regardless of how they are implemented, and
regardless of the order of the elements; so there\'s not much
freedom for __eq__ or __hash__. We match the algorithm used
by the built-in frozenset type.
"""
MAX = sys.maxsize
MASK = 2 * MAX + 1
n = len(self)
h = 1927868237 * (n + 1)
h &= MASK
for x in self:
hx = hash(x)
h ^= (hx ^ (hx << 16) ^ 89869747) * 3644798167
h &= MASK
h = h * 69069 + 907133923
h &= MASK
if h > MAX:
h -= MASK + 1
if h == -1:
h = 590923713
return h
Set.register(frozenset)
class MutableSet(Set):
"""A mutable set is a finite, iterable container.
This class provides concrete generic implementations of all
methods except for __contains__, __iter__, __len__,
add(), and discard().
To override the comparisons (presumably for speed, as the
semantics are fixed), all you have to do is redefine __le__ and
then the other operations will automatically follow suit.
"""
__slots__ = ()
@abstractmethod
def add(self, value):
"""Add an element."""
raise NotImplementedError
@abstractmethod
def discard(self, value):
"""Remove an element. Do not raise an exception if absent."""
raise NotImplementedError
def remove(self, value):
"""Remove an element. If not a member, raise a KeyError."""
if value not in self:
raise KeyError(value)
self.discard(value)
def pop(self):
"""Return the popped value. Raise KeyError if empty."""
it = iter(self)
try:
value = next(it)
except StopIteration:
raise KeyError
self.discard(value)
return value
def clear(self):
"""This is slow (creates N new iterators!) but effective."""
try:
while True:
self.pop()
except KeyError:
pass
def __ior__(self, it):
for value in it:
self.add(value)
return self
def __iand__(self, it):
for value in (self - it):
self.discard(value)
return self
def __ixor__(self, it):
if it is self:
self.clear()
else:
if not isinstance(it, Set):
it = self._from_iterable(it)
for value in it:
if value in self:
self.discard(value)
else:
self.add(value)
return self
def __isub__(self, it):
if it is self:
self.clear()
else:
for value in it:
self.discard(value)
return self
MutableSet.register(set)
### MAPPINGS ###
class Mapping(Collection):
__slots__ = ()
"""A Mapping is a generic container for associating key/value
pairs.
This class provides concrete generic implementations of all
methods except for __getitem__, __iter__, and __len__.
"""
@abstractmethod
def __getitem__(self, key):
raise KeyError
def get(self, key, default=None):
\'D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None.\'
try:
return self[key]
except KeyError:
return default
def __contains__(self, key):
try:
self[key]
except KeyError:
return False
else:
return True
def keys(self):
"D.keys() -> a set-like object providing a view on D\'s keys"
return KeysView(self)
def items(self):
"D.items() -> a set-like object providing a view on D\'s items"
return ItemsView(self)
def values(self):
"D.values() -> an object providing a view on D\'s values"
return ValuesView(self)
def __eq__(self, other):
if not isinstance(other, Mapping):
return NotImplemented
return dict(self.items()) == dict(other.items())
__reversed__ = None
Mapping.register(mappingproxy)
class MappingView(Sized):
__slots__ = \'_mapping\',
def __init__(self, mapping):
self._mapping = mapping
def __len__(self):
return len(self._mapping)
def __repr__(self):
return \'0.__class__.__name__(0._mapping!r)\'.format(self)
class KeysView(MappingView, Set):
__slots__ = ()
@classmethod
def _from_iterable(self, it):
return set(it)
def __contains__(self, key):
return key in self._mapping
def __iter__(self):
yield from self._mapping
KeysView.register(dict_keys)
class ItemsView(MappingView, Set):
__slots__ = ()
@classmethod
def _from_iterable(self, it):
return set(it)
def __contains__(self, item):
key, value = item
try:
v = self._mapping[key]
except KeyError:
return False
else:
return v is value or v == value
def __iter__(self):
for key in self._mapping:
yield (key, self._mapping[key])
ItemsView.register(dict_items)
class ValuesView(MappingView):
__slots__ = ()
def __contains__(self, value):
for key in self._mapping:
v = self._mapping[key]
if v is value or v == value:
return True
return False
def __iter__(self):
for key in self._mapping:
yield self._mapping[key]
ValuesView.register(dict_values)
class MutableMapping(Mapping):
__slots__ = ()
"""A MutableMapping is a generic container for associating
key/value pairs.
This class provides concrete generic implementations of all
methods except for __getitem__, __setitem__, __delitem__,
__iter__, and __len__.
"""
@abstractmethod
def __setitem__(self, key, value):
raise KeyError
@abstractmethod
def __delitem__(self, key):
raise KeyError
__marker = object()
def pop(self, key, default=__marker):
\'\'\'D.pop(k[,d]) -> v, remove specified key and return the corresponding value.
If key is not found, d is returned if given, otherwise KeyError is raised.
\'\'\'
try:
value = self[key]
except KeyError:
if default is self.__marker:
raise
return default
else:
del self[key]
return value
def popitem(self):
\'\'\'D.popitem() -> (k, v), remove and return some (key, value) pair
as a 2-tuple; but raise KeyError if D is empty.
\'\'\'
try:
key = next(iter(self))
except StopIteration:
raise KeyError
value = self[key]
del self[key]
return key, value
def clear(self):
\'D.clear() -> None. Remove all items from D.\'
try:
while True:
self.popitem()
except KeyError:
pass
def update(*args, **kwds):
\'\'\' D.update([E, ]**F) -> None. Update D from mapping/iterable E and F.
If E present and has a .keys() method, does: for k in E: D[k] = E[k]
If E present and lacks .keys() method, does: for (k, v) in E: D[k] = v
In either case, this is followed by: for k, v in F.items(): D[k] = v
\'\'\'
if not args:
raise TypeError("descriptor \'update\' of \'MutableMapping\' object "
"needs an argument")
self, *args = args
if len(args) > 1:
raise TypeError(\'update expected at most 1 arguments, got %d\' %
len(args))
if args:
other = args[0]
if isinstance(other, Mapping):
for key in other:
self[key] = other[key]
elif hasattr(other, "keys"):
for key in other.keys():
self[key] = other[key]
else:
for key, value in other:
self[key] = value
for key, value in kwds.items():
self[key] = value
def setdefault(self, key, default=None):
\'D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D\'
try:
return self[key]
except KeyError:
self[key] = default
return default
MutableMapping.register(dict)
### SEQUENCES ###
class Sequence(Reversible, Collection):
"""All the operations on a read-only sequence.
Concrete subclasses must override __new__ or __init__,
__getitem__, and __len__.
"""
__slots__ = ()
@abstractmethod
def __getitem__(self, index):
raise IndexError
def __iter__(self):
i = 0
try:
while True:
v = self[i]
yield v
i += 1
except IndexError:
return
def __contains__(self, value):
for v in self:
if v is value or v == value:
return True
return False
def __reversed__(self):
for i in reversed(range(len(self))):
yield self[i]
def index(self, value, start=0, stop=None):
\'\'\'S.index(value, [start, [stop]]) -> integer -- return first index of value.
Raises ValueError if the value is not present.
\'\'\'
if start is not None and start < 0:
start = max(len(self) + start, 0)
if stop is not None and stop < 0:
stop += len(self)
i = start
while stop is None or i < stop:
try:
v = self[i]
if v is value or v == value:
return i
except IndexError:
break
i += 1
raise ValueError
def count(self, value):
\'S.count(value) -> integer -- return number of occurrences of value\'
return sum(1 for v in self if v is value or v == value)
Sequence.register(tuple)
Sequence.register(str)
Sequence.register(range)
Sequence.register(memoryview)
class ByteString(Sequence):
"""This unifies bytes and bytearray.
XXX Should add all their methods.
"""
__slots__ = ()
ByteString.register(bytes)
ByteString.register(bytearray)
class MutableSequence(Sequence):
__slots__ = ()
"""All the operations on a read-write sequence.
Concrete subclasses must provide __new__ or __init__,
__getitem__, __setitem__, __delitem__, __len__, and insert().
"""
@abstractmethod
def __setitem__(self, index, value):
raise IndexError
@abstractmethod
def __delitem__(self, index):
raise IndexError
@abstractmethod
def insert(self, index, value):
\'S.insert(index, value) -- insert value before index\'
raise IndexError
def append(self, value):
\'S.append(value) -- append value to the end of the sequence\'
self.insert(len(self), value)
def clear(self):
\'S.clear() -> None -- remove all items from S\'
try:
while True:
self.pop()
except IndexError:
pass
def reverse(self):
\'S.reverse() -- reverse *IN PLACE*\'
n = len(self)
for i in range(n//2):
self[i], self[n-i-1] = self[n-i-1], self[i]
def extend(self, values):
\'S.extend(iterable) -- extend sequence by appending elements from the iterable\'
for v in values:
self.append(v)
def pop(self, index=-1):
\'\'\'S.pop([index]) -> item -- remove and return item at index (default last).
Raise IndexError if list is empty or index is out of range.
\'\'\'
v = self[index]
del self[index]
return v
def remove(self, value):
\'\'\'S.remove(value) -- remove first occurrence of value.
Raise ValueError if the value is not present.
\'\'\'
del self[self.index(value)]
def __iadd__(self, values):
self.extend(values)
return self
MutableSequence.register(list)
MutableSequence.register(bytearray) # Multiply inheriting, see ByteString

1.3.使用isinstance而不是type
(1)语法
isinstance(object, classinfo)
其中,object 是变量,classinfo 是类型即 (tuple,dict,int,float,list,bool等) 和 class类
若参数 object 是 classinfo 类的实例,或者 object 是 classinfo 类的子类的一个实例, 返回 True。
若 object 不是一个给定类型的的对象, 则返回结果总是False。
若 classinfo 不是一种数据类型或者由数据类型构成的元组,将引发一个 TypeError 异常。
(2)isinstance简单用法
>>> isinstance(1,int)
True
>>>
>>> isinstance(\'1\',str)
True
>>>
>>> isinstance(1,list)
False
(3)type()与isinstance()的区别:
- 共同点:两者都可以判断对象类型
- 不同点:对于一个 class 类的子类对象类型判断,type就不行了,而 isinstance 可以。
class A:
pass
class B(A):
pass
b = B()
#判断b是不是B的类型
print(isinstance(b,B)) #True
# b是不是A的类型呢,也是的
#因为B继承A,isinstance内部会去检查继承链
print(isinstance(b,A)) #True
print(type(b) is B) #True
#b指向了B()对象,虽然A是B的父类,但是A是另外一个对象,它们的id是不相等的
print(type(b) is A) #False
1.4.类变量和实例变量
python的类变量和实例变量,顾名思义,类变量是指跟类的变量,而实例变量,指跟类的具体实例相关联的变量
class A:
#类变量
bb = 11
def __init__(self,x,y):
#实例变量
self.x = x
self.y = y
a = A(2,3)
A.bb = 111111
print(a.x,a.y,a.bb) # 2 3 111111
print(A.bb) # 111111
a.bb = 2222 #实际上会在实例对象a里面新建一个属性bb
print(a.bb) # 2222
print(A.bb) # 111111
1.5.类和实例属性的查找顺序

class D:
pass
class C(D):
pass
class B(D):
pass
class A(B,C):
pass
#顺序:A,B,C,D
#__mro__,类的属性查找顺序
print(A.__mro__) #(<class \'__main__.A\'>, <class \'__main__.B\'>, <class \'__main__.C\'>, <class \'__main__.D\'>, <class \'object\'>)

class D:
pass
class E:
pass
class C(E):
pass
class B(D):
pass
class A(B,C):
pass
#顺序:A,B,D,C,E
#__mro__,类的属性查找顺序
print(A.__mro__)
#(<class \'__main__.A\'>, <class \'__main__.B\'>, <class \'__main__.D\'>, <class \'__main__.C\'>, <class \'__main__.E\'>, <class \'object\'>)
1.6.类方法,静态方法,和实例方法
实例:
class Date():
#构造函数
def __init__(self,year,month,day):
self.year = year
self.month = month
self.day = day
#实例方法
def tomorrow(self):
self.day += 1
# 静态方法不用写self
@staticmethod
def parse_from_string(date_str):
year, month, day = tuple(date_str.split("-"))
# 静态方法不好的地方是采用硬编码,如果用类方法的话就不会了
return Date(int(year), int(month), int(day))
#类方法
@classmethod
def from_string(cls, date_str):
year, month, day = tuple(date_str.split("-"))
# cls:传进来的类,而不是像静态方法把类写死了
return cls(int(year), int(month), int(day))
def __str__(self):
return \'%s/%s/%s\'%(self.year,self.month,self.day)
if __name__ == "__main__":
new_day = Date(2018,5,9)
#实例方法
new_day.tomorrow()
print(new_day) #2018/5/10
#静态方法
date_str = \'2018-05-09\'
new_day = Date.parse_from_string(date_str)
print(new_day) #2018/5/9
# 类方法
date_str = \'2018-05-09\'
new_day = Date.from_string(date_str)
print(new_day) # 2018/5/9
1.7.python对象的自省机制
在计算机编程中,自省是指一种能力:检查某些事物以确定它是什么、它知道什么以及它能做什么。自省向程序员提供了极大的灵活性和控制力。
class Person:
\'\'\'人类\'\'\'
name = "user"
class Student(Person):
def __init__(self,school_name):
self.school_name = school_name
if __name__ == "__main__":
user = Student(\'仙剑\')
#通过 __dict__ 查询有哪些属性
print(user.__dict__) #\'school_name\': \'仙剑\'
print(Person.__dict__) #\'__module__\': \'__main__\', \'__doc__\': \'人类\', \'name\': \'user\', \'__dict__\': <attribute \'__dict__\' of \'Person\' objects>, \'__weakref__\': <attribute \'__weakref__\' of \'Person\' objects>
print(Person.__doc__) #人类
#可以添加属性
user.__dict__[\'school_addr\'] = \'北京\'
print(user.school_addr) #北京
#dir也可以查看属性,比__dict__功能更强大
print(dir(user))
#[\'__class__\', \'__delattr__\', \'__dict__\', \'__dir__\', \'__doc__\', \'__eq__\', \'__format__\', \'__ge__\', \'__getattribute__\', \'__gt__\', \'__hash__\', \'__init__\', \'__init_subclass__\', \'__le__\', \'__lt__\', \'__module__\', \'__ne__\', \'__new__\', \'__reduce__\', \'__reduce_ex__\', \'__repr__\', \'__setattr__\', \'__sizeof__\', \'__str__\', \'__subclasshook__\', \'__weakref__\', \'name\', \'school_addr\', \'school_name\']
1.8.super函数
super执行的顺序
class A:
def __init__(self):
print(\'A\')
class B(A):
def __init__(self):
print(\'B\')
super().__init__()
class C(A):
def __init__(self):
print(\'C\')
super().__init__()
class D(B,C):
def __init__(self):
print(\'D\')
super(D, self).__init__()
if __name__ == \'__main__\':
print(D.__mro__) #(<class \'__main__.D\'>, <class \'__main__.B\'>, <class \'__main__.C\'>, <class \'__main__.A\'>, <class \'object\'>)
d = D()
#执行结果
D
B
C
A
1.9.with语句(上下文管理器)
#上下文管理器
class Sample:
def __enter__(self):
print(\'enter\')
#获取资源
return self
def __exit__(self, exc_type, exc_val, exc_tb):
#释放资源
print(\'exit\')
def do_something(self):
print(\'doing something\')
#会自动执行enter和exit方法
with Sample() as sample:
sample.do_something()
# 运行结果
enter
doing something
exit
3.python元类编程
1.1.propety动态属性
在面向对象编程中,我们一般把名词性的东西映射成属性,动词性的东西映射成方法。在python中他们对应的分别是属性self.xxx和类方法。但有时我们需要的属性需要根据其他属性动态的计算,此时如果直接使用属性方法处理,会导致数据不同步。下面介绍@property方法来动态创建类属性。
from datetime import datetime,date
class User:
def __init__(self,name,birthday):
self.name = name
self.birthday = birthday
self._age = 0
@property
def age(self):
return datetime.now().year - self.birthday.year
@age.setter
def age(self,value):
self._age = value
if __name__ == \'__main__\':
user = User("derek",date(year=1994,month=11,day=11))
user.age = 23
print(user._age) # 23
print(user.age) # 24 ,动态计算出来的
1.2.__getattr__和__getattribute__的区别
object.__getattr__(self, name)
找不到attribute的时候,会调用getattr,返回一个值或AttributeError异常。
object.__getattribute__(self, name)
无条件被调用,通过实例访问属性。如果class中定义了__getattr__(),则__getattr__()不会被调用(除非显示调用或引发AttributeError异常)
(1)调用一个不存在的属性
class User:
def __init__(self,info=):
self.info = info
# def __getattr__(self, item):
# return self.info[item]
if __name__ == \'__main__\':
user = User(info="name":"derek","age":24)
print(user.name)
会报错

(2)加了__getattr__之后就可以调用了
class User:
def __init__(self,info=):
self.info = info
#__getattr__是在查找不到属性的时候调用
def __getattr__(self, item):
return self.info[item]
if __name__ == \'__main__\':
user = User(info="name":"derek","age":24)
print(user.name) #derek
(3)__getattribute__
class User:
def __init__(self,info=):
self.info = info
#__getattr__是在查找不到属性的时候调用
def __getattr__(self, item):
return self.info[item]
#__getattribute不管属性存不存在,都访问这个
def __getattribute__(self, item):
return "zhang_derek"
if __name__ == \'__main__\':
user = User(info="name":"derek","age":24)
#不管属性存不存在,都走__getattribute__
print(user.name) #zhang_derek #即使属性存在也走__getattribute__
print(user.test) #zhang_derek #不存在的属性也能打印
print(user.company) #zhang_derek #不存在的属性也能打印
1.3.属性描述符
验证赋值的时候是不是int类型
#属性描述符
import numbers
#只要一个类实现了下面三种魔法函数中的一种,这个类就是属性描述符
class IntField:
def __get__(self, instance, owner):
return self.value
def __set__(self, instance, value):
if not isinstance(value,numbers.Integral):
raise ValueError("必须为int")
self.value = value
def __delete__(self, instance):
pass
class User:
age = IntField()
if __name__ == \'__main__\':
user = User()
user.age = 24
print(user.age)
如果user.age=24,值是int,可以正常打印
如果user.age=\'test\',传一个字符串,则会报错

1.4.__new__和__init__的区别
(1)__new__方法如果不返回对象,不会执行init方法
class User:
def __new__(cls, *args, **kwargs):
print("in new")
def __init__(self,name):
print("in init")
self.name = name
# new是用用来控制对象的生成过程,在对象生成之前
# init是用来完善对象的
# 如果new方法不返回对象,则不会调用init函数
if __name__ == \'__main__\':
user = User("derek")
运行结果:没有调用init方法

(2)返回对象就会执行init方法
class User:
def __new__(cls, *args, **kwargs):
print("in new") #in new
print(cls) #cls是当前class对象 <class \'__main__.User\'>
print(type(cls)) #<class \'type\'>
return super().__new__(cls) #必须返回class对象,才会调用__init__方法
def __init__(self,name):
print("in init") #in init
print(self) #self是class的实例对象 <__main__.User object at 0x00000000021B8780>
print(type(self)) #<class \'__main__.User\'>
self.name = name
# new是用用来控制对象的生成过程,在对象生成之前
# init是用来完善对象的
# 如果new方法不返回对象,则不会调用init函数
if __name__ == \'__main__\':
user = User(name="derek")
#总结
# __new__ 用来创建实例,在返回的实例上执行__init__,如果不返回实例那么__init__将不会执行
# __init__ 用来初始化实例,设置属性什么的
1.5.自定义元类
(1)前戏:通过传入不同的字符串动态的创建不同的类
def create_class(name):
if name == \'user\':
class User:
def __str__(self):
return "user"
return User
elif name == "company":
class Company:
def __str__(self):
return "company"
return Company
if __name__ == \'__main__\':
Myclass = create_class("user")
my_obj = Myclass()
print(my_obj) #user
print(type(my_obj)) #<class \'__main__.create_class.<locals>.User\'>
(2)用type创建
虽然上面的方法能够创建,但很麻烦,下面是type创建类的一个简单实例
# 一个简单type创建类的例子
#type(object_or_name, bases, dict)
#type里面有三个参数,第一个类名,第二个基类名,第三个是属性
User = type("User",(),"name":"derek")
my_obj = User()
print(my_obj.name) #derek
(3)不但可以定义属性,还可以定义方法
def say(self): #必须加self
return "i am derek"
User = type("User",(),"name":"derek","say":say)
my_obj = User()
print(my_obj.name) #derek
print(my_obj.say()) #i am derek
(4)让type创建的类继承一个基类
def say(self): #必须加self
return "i am derek"
class BaseClass:
def answer(self):
return "i am baseclass"
#type里面有三个参数,第一个类名,第二个基类名,第三个是属性
User = type("User",(BaseClass,),"name":"derek","say":say)
if __name__ == \'__main__\':
my_obj = User()
print(my_obj.name) # derek
print(my_obj.say()) # i am derek
print(my_obj.answer()) # i am baseclass
1.6.什么是元类?
元类就是创建类的类,比如上面的type
在实际编码中,我们一般不直接用type去创建类,而是用元类的写法,自定义一个元类metaclass去创建
# 把User类创建的过程委托给元类去做,这样代码的分离性比较好
class MetaClass(type):
def __new__(cls, *args, **kwargs):
return super().__new__(cls,*args, **kwargs)
class User(metaclass=MetaClass):
def __init__(self,name):
self.name = name
def __str__(self):
return "test"
if __name__ == \'__main__\':
#python中类的实例化过程,会首先寻找metaclass,通过metaclass去创建User类
my_obj = User(name="derek")
print(my_obj) #test
4.自定义序列类
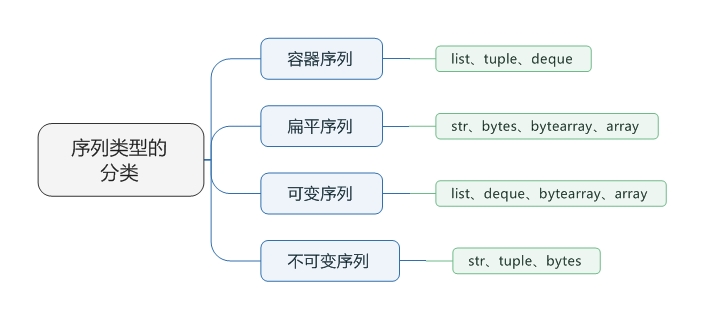
1.1.序列类型的分类
1.2.序列的+和+=,extend和append的区别
from collections import abc
a = [1,2,]
c = a + [3,4]
print(c) #[1, 2, 3, 4]
#如果 + 元祖则会报错, not tuple
# c = a + (3,4) #TypeError: can only concatenate list (not "tuple") to list
# + 是新生产一个list, += 是就地加,不会新生成list
#用+= 则可以是元祖,后面只要是可迭代的就行
#其原理是python内部抽象基类MutableSequence里面有个魔法函数__iadd__来实现的
a += (3,4) #[1, 2, 3, 4]
print(a)
a.extend((5,6))
print(a) #[1, 2, 3, 4, 5, 6]
a.append((7,8))
print(a) #[1, 2, 3, 4, 5, 6, (7, 8)]
#可以看到extend和append结果并不一样,append是把里面当一个值传进去,extend是迭代的传进去
1.3.实现可切片的对象
(1)切片的用法
#模式[start:end:step]
"""
其中,第一个数字start表示切片开始位置,默认为0;
第二个数字end表示切片截止(但不包含)位置(默认为列表长度);
第三个数字step表示切片的步长(默认为1)。
当start为0时可以省略,当end为列表长度时可以省略,
当step为1时可以省略,并且省略步长时可以同时省略最后一个冒号。
另外,当step为负整数时,表示反向切片,这时start应该比end的值要大才行。
"""
aList = [3, 4, 5, 6, 7, 9, 11, 13, 15, 17]
#切片返回的是一个新元素,不会改变原有的list
print (aList[::]) # 返回包含原列表中所有元素的新列表 [3, 4, 5, 6, 7, 9, 11, 13, 15, 17]
print (aList[::-1]) # 返回包含原列表中所有元素的逆序列表 [17, 15, 13, 11, 9, 7, 6, 5, 4, 3]
print (aList[::2]) # 隔一个取一个,获取偶数位置的元素 [3, 5, 7, 11, 15]
print (aList[1::2]) # 隔一个取一个,获取奇数位置的元素 [4, 6, 9, 13, 17]
print (aList[3:6]) # 指定切片的开始和结束位置 [6, 7, 9]
print(aList[0:100]) # 切片结束位置大于列表长度时,从列表尾部截断 [3, 4, 5, 6, 7, 9, 11, 13, 15, 17]
print(aList[100:]) # 切片开始位置大于列表长度时,返回空列表 []
# aList[len(aList):] = [9] # 在列表尾部增加元素
# aList[:0] = [1, 2] # 在列表头部插入元素
# aList[3:3] = [4] # 在列表中间位置插入元素
# aList[:3] = [1, 2] # 替换列表元素,等号两边的列表长度相等
# aList[3:] = [4, 5, 6] # 等号两边的列表长度也可以不相等
# aList[::2] = [0] * 3 # 隔一个修改一个
# print (aList)
# aList[::2] = [\'a\', \'b\', \'c\'] # 隔一个修改一个
# aList[::2] = [1,2] # 左侧切片不连续,等号两边列表长度必须相等 #会报错
# aList[:3] = [] # 删除列表中前3个元素
#删除
# del aList[:3] # 切片元素连续
# del aList[::2] # 切片元素不连续,隔一个删一个
(2)实现对象支持切片操作
from collections import abc
#Sequence协议
import numbers
class Group:
#支持切片操作
def __init__(self, group_name, company_name, staffs):
self.group_name = group_name
self.company_name = company_name
self.staffs = staffs
def __reversed__(self):
self.staffs.reverse()
def __getitem__(self, item):
#当前的类
cls = type(self)
#判断类是不是可切片的对象
if isinstance(item, slice):
return cls(group_name=self.group_name, company_name=self.company_name, staffs=self.staffs[item])
elif isinstance(item, numbers.Integral):
return cls(group_name=self.group_name, company_name=self.company_name, staffs=[self.staffs[item]])
def __len__(self):
return len(self.staffs)
def __iter__(self):
return iter(self.staffs)
def __contains__(self, item):
if item in self.staffs:
return True
else:
return False
staffs = ["derek1", "derek2", "derek3", "derek4"]
group = Group(company_name="alibaba", group_name="user", staffs=staffs)
#现在对象就成可切片的对象了
#__getitem__
for user in group:
print(user)
#运行结果
# derek1
# derek2
# derek3
# derek4
#__contains__
if \'derek1\' in group:
print(\'yes\')
1.4.列表生成式,字典推导式
# odd_list = []
# for i in range(21):
# if i%2 == 1:
# odd_list.append(i)
# print(odd_list) #[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
#列表生成式
#1.取出1-20之间的基数
odd_list = [i for i in range(21) if i %2 == 1]
print(odd_list) #[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
#2.取出1-20之间的基数的平方
def hadle_item(item):
return item * item
odd_list = [hadle_item(i) for i in range(21) if i %2 == 1]
print(odd_list) #[1, 9, 25, 49, 81, 121, 169, 225, 289, 361]
利用字典推导式把字典的key和value做转换:key:value变成value:key的形式
# 字典推导式的用法
my_dict = \'derek1\':11,\'derek2\':22,\'derek3\':33
reversed_dict = value:key for key,value in my_dict.items()
print(reversed_dict) #11: \'derek1\', 22: \'derek2\', 33: \'derek3\'
以上是关于Python面向对象-高级用法的主要内容,如果未能解决你的问题,请参考以下文章