R语言分布滞后非线性模型(DLNM)研究发病率,死亡率和空气污染示例|附代码数据
Posted 大数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言分布滞后非线性模型(DLNM)研究发病率,死亡率和空气污染示例|附代码数据相关的知识,希望对你有一定的参考价值。
全文下载链接:http://tecdat.cn/?p=21317
最近我们被客户要求撰写关于分布滞后非线性模型(DLNM)的研究报告,包括一些图形和统计输出。
本文提供了运行分布滞后非线性模型的示例,同时描述了预测变量和结果之间的非线性和滞后效应,这种相互关系被定义为暴露-滞后-反应关联
数据集包含1987-2000年期间每日死亡率(CVD、呼吸道),天气(温度,相对湿度)和污染数据(PM10和臭氧)。数据是由健康影响研究所赞助的《国家发病率,死亡率和空气污染研究》(NMMAPS)的一部分[Samet et al.,2000a,b]。
该研究是关于随时间变化的职业暴露与癌症之间的关系。该研究包括250个风险集,每个风险集都有一个病例和一个对照,并与年龄相匹配。暴露数据以15岁至65岁之间的5岁年龄区间收集。
数据集药物包含模拟数据,来自一个假设的随机对照试验,对随时间变化剂量的药物的影响。该研究包括200名随机受试者,每人每天接受药物剂量,持续28天,每周都有变化。每隔7天报告一次。
DLNM方法
在这里,我提供了一个简短的摘要来介绍概念和定义。
暴露-滞后-反应关联
DLNM的建模类用于描述关联,在该关联中,暴露和结果之间的依赖关系会在时间上滞后。可以使用两个不同且互补的观点来描述此过程。我们可以说,在时间t处的暴露事件确定了在时间t +l处的未来风险。使用后向视角,时间t的风险由过去在时间t-l经历的一系列风险确定。这里的l是滞后,表示暴露和测得的结果之间的滞后。
DLNM统计模型
DLNM类提供了一个概念和分析框架,用于描述和估计暴露-滞后-反应关联。DLNM的统计发展基于以下选择:DLNM类为描述和估计暴露-滞后-反应关联提供了一个概念和分析框架。DLNM的统计发展基于该选择。
暴露-滞后-反应关联的一个简单情况是,预测变量空间中的关系(即暴露-滞后关系)是线性的。可以通过DLM对这种类型的关系进行建模。在这种情况下,关联仅取决于滞后反应函数,该函数模拟线性风险如何随滞后变化。滞后反应函数的不同选择(样条曲线,多项式,层次,阈值等)导致指定了不同的DLM,并暗示了滞后反应关系的替代假设。
DLNM解释
DLNM的结果可以通过使用3-D绘图提供沿两个维度变化的关联,通过为每个滞后和预测变量的拟合值构建预测网格来解释。
第一是与特定暴露值相关联的滞后反应曲线,定义为预测变量特定性关联。这被解释为与时间t风险相关的时间t +l的风险贡献序列。
第二是与特定滞后值相关联的暴露-反应曲线,该特定滞后值定义为滞后特定关联。这被解释为与在时间t处发生的暴露值相关联的在时间t +l处的暴露-反应关系。
第三个也是最重要的是与在考虑的滞后期内经历的整个暴露历史相关的暴露反应曲线,定义为总体累积关联。使用正向视角,这被解释为表示时间t发生的给定暴露期间[t,t+L]期间经历的净风险的暴露反应关系。
时间序列之外的应用
分布滞后模型首先是在很久以前的计量经济时间序列分析中提出的[Almon,1965],然后在环境流行病学Schwartz [2000]的时间序列数据中重新提出。DLNM的扩展是由Armstrong [2006]构想的。Gasparrini等人对时间序列数据的建模框架进行了重新评估。[2010]。有趣的是,已经在不同的研究领域中提出了这种暴露-滞后-反应关联的模型。一般的想法是通过特定函数加权过去的暴露,这些函数的参数由数据估算。在癌症流行病学[Hauptmann等,2000;Langholz等,1999;Richardson,2009;Thomas,1983;Vacek,1997]和药物流行病学[Abrahamowicz等]中,说明了类似于DLM的线性-暴露-反应关系模型。
基本函数
指定标准暴露反应和滞后反应关系的基本函数,例如多项式,分层或阈值函数。例如,样条线由推荐的包样条线中包含的函数ns()和bs()指定。多项式是通过函数poly()获得的。这是一个简单向量的转换示例:
poly(1:5,degree=3)
1 2 3
[1,] 0.2 0.04 0.008
[2,] 0.4 0.16 0.064
[3,] 0.6 0.36 0.216
[4,] 0.8 0.64 0.512
[5,] 1.0 1.00 1.000
attr(,"degree")
[1] 3
attr(,"scale")
[1] 5
attr(,"intercept")
[1] FALSE
attr(,"class")
[1] "poly" "matrix"
第一个未命名的参数x指定要转换的向量,而参数度设置多项式的度。定义分层函数是通过strata()指定的。
strata(1:5,breaks=c(2,4))[,]
1 2
[1,] 0 0
[2,] 1 0
[3,] 1 0
[4,] 0 1
[5,] 0 1
结果是带有附加类别“层”的基础矩阵。转换是定义对比的虚拟参数化。参数break定义了层的右开放区间的下边界。
阈值函数通过thr()指定。一个例子:
thr(1:5,thr.value=3,side="d")[,]
1 2
[1,] 2 0
[2,] 1 0
[3,] 0 0
[4,] 0 1
[5,] 0 2
结果是具有附加类别“ thr”的基础矩阵。参数thr.value定义一个带有一个或两个阈值的向量,而side用于指定高(“ h”,默认值),低(“ l”)或双精度(“ d”)阈值参数化。
点击标题查阅往期内容

【视频】R语言中的分布滞后非线性模型(DLNM)与发病率,死亡率和空气污染示例

左右滑动查看更多

01
02
03
04
基本转换
此函数代表以dlnm为单位进行基本转换的主要函数,适用于指定暴露-反应和滞后-反应关系。它的作用是应用选定的转换并以适用于其他函数(例如crossbasis()和crosspred())的格式生成基本矩阵。以下示例复制了该部分中显示的多项式变换:
onebasis(1:5,fun="poly",degree=3)
b1 b2 b3
[1,] 0.2 0.04 0.008
[2,] 0.4 0.16 0.064
[3,] 0.6 0.36 0.216
[4,] 0.8 0.64 0.512
[5,] 1.0 1.00 1.000
attr(,"fun")
[1] "poly"
attr(,"degree")
[1] 3
attr(,"scale")
[1] 5
attr(,"intercept")
[1] FALSE
attr(,"class")
[1] "onebasis" "matrix"
attr(,"range")
[1] 1 5
结果是带有附加类“ onebasis”的基础矩阵。同样,第一个未命名参数x指定要转换的向量,而第二个参数fun将字符转换定义为应用转换而调用的函数的名称。具体来说,基本矩阵包括fun和range属性,以及定义转换的被调用函数的参数。如前所述,onebasis()还可以根据特定要求调用用户定义的函数。一个简单的例子:
> mylog <- function(x) log(x)
> onebasis(1:5,"mylog")
b1
[1,] 0.0000000
[2,] 0.6931472
[3,] 1.0986123
[4,] 1.3862944
[5,] 1.6094379
attr(,"fun")
[1] "mylog"
attr(,"range")
[1] 1 5
attr(,"class")
[1] "onebasis" "matrix"
交叉基
这是dlnm软件包中的主要函数。它在内部调用onebasis()来生成暴露-反应和滞后-反应关系的基矩阵,并通过特殊的张量积将它们组合起来,以创建交叉基,该交叉基在模型中同时指定了暴露-滞后-反应关联性。它的第一个参数x的类定义如何解释数据。可以使用第二个变量lag修改滞后期。
作为一个简单的示例,我模拟了2-5个滞后期内3个对象的暴露历史矩阵:它们中的每一个都将传递给onebasis()来分别构建暴露-反应和滞后-反应关系的矩阵。仅用于时间序列数据的附加参数组定义了被视为单独无关序列的观察组,例如在季节性分析中可能有用。作为一个简单的示例,我模拟了2-5个滞后期内3个对象的暴露历史矩阵:它们中的每一个都将传递给onebasis()来分别构建暴露-反应和滞后-反应关系的矩阵。作为一个简单的示例,我模拟了2-5个滞后期内3个对象的暴露历史矩阵:
> hist
lag2 lag3 lag4 lag5
sub1 1 3 5 6
sub2 7 8 9 4
sub3 10 2 11 12
然后,我应用交叉基参数化,将二次多项式作为暴露反应函数,并将分层函数2-3和4-5定义为滞后反应函数的分层函数:
lag=c(2,5),argvar=list(fun="poly",degree=2),
arglag=list(fun="strata",breaks=4))[,]
v1.l1 v1.l2 v2.l1 v2.l2
sub1 1.250000 0.9166667 0.4930556 0.4236111
sub2 2.333333 1.0833333 1.4583333 0.6736111
sub3 2.916667 1.9166667 2.5625000 1.8402778
该函数返回“ crossbasis”类的矩阵对象。它首先使用argvar和arglag列表中的参数调用onebasis(),以建立暴露反应空间和滞后反应空间的矩阵基础。在另一个示例中,我将crossbasis()应用于数据集中的变量temp,该数据集表示1987-2000年期间日平均温度序列:
> summary(cb)
CROSSBASIS FUNCTIONS
observations: 5114
range: -26.66667 to 33.33333
lag period: 0 30
total df: 10
BASIS FOR VAR:
fun: thr
thr.value: 10 20
side: d
intercept: FALSE
BASIS FOR LAG:
fun: ns
knots: 1 4 12
intercept: TRUE
Boundary.knots: 0 30
此处,将暴露反应建模为阈值为10和20的双阈值函数。滞后时间设置为0到30。滞后反应函数留给默认的自然三次样条(fun =“ ns”),其滞后值为1、4和12。
预测
crossbasis()生成的交叉基矩阵需要包含在回归模型公式中才能拟合模型。关联通过函数crosspred()进行汇总,该函数针对默认值或用户直接选择的预测值和滞后值的组合的网格进行预测。例如,我使用创建的交叉基矩阵cb,使用数据集时间序列数据来研究温度与心血管疾病死亡率之间的关联。首先,我将一个简单的线性模型与模型公式中包含的交叉基矩阵拟合。然后,我通过使用cross-basis和回归模型对象作为前两个参数调用crosspred()来获得预测:
crosspred(cb,model,at=-20:30)
结果是“ crosspred”类的列表对象,其中的存储预测和有关模型的其他信息,例如系数和与交叉基参数有关的关联(协)方差矩阵的一部分。可以为特定的预测器-滞后组合选择预测的网格。例如,我提取温度为-10°C且滞后5的预测和置信区间,然后提取25°C的整体累积预测:
> pred$allfit["25"]
25
1.108262
第一个结果表明,在给定的一天中,-20°C的温度会在五天后导致0.95例心血管死亡的增加,或者在给定的一天中,温度为-6摄氏度时,心血管死亡的数目增加0.95。其他类型的预测可以通过crosspred()获得。特别是,如果模型链接等于log或logit,则将自动返回取幂的预测。如果参数cum设置为TRUE,则是累积预测的矩阵cum。
crosspred()的另一种用法是预测特定的暴露历史记录集的影响。这可以通过输入暴露历史矩阵作为参数来实现。例如,我们可以从拟合模型中预测出,在过去10天暴露于30°C和在滞后期的其余时间暴露于22°C之后,心血管死亡的总体累积增加:如果参数cum设置为TRUE,则包括增量累积预测的矩阵cum,并将其存储在组件cum中。crosspred()的另一种用法是预测特定的暴露历史记录集的影响。这可以通过输入暴露历史矩阵作为参数来实现。例如,我们可以从拟合模型中预测出,在过去10天暴露于30°C和在滞后期的其余时间暴露于22°C之后,心血管死亡的总体累积增加:
> crosspred(cb,model,at=histpred)$allfit
1
5.934992
dlnm软件包的主要优点之一是,用户可以使用标准回归函数执行DLNM,只需在模型公式中包括交叉基矩阵即可。函数crosspred()自动处理来自回归函数lm()和glm(),gam()(软件包mgcv),coxph()的模型。
降维
DLNM的拟合度可以降低到预测变量或滞后的一个维度,仅以诸如总累积暴露反应表达。该计算通过函数crossreduce()进行,该函数的工作原理与crosspred()非常相似。前两个自变量base和model指定交叉基矩阵和需要对其执行计算的模型对象。减少的类型由类型定义,带有选项“ overall”-“ lag”-“ var”,用于汇总总体累积暴露反应,滞后特异性暴露反应或预测变量特异性滞后反应。
绘图
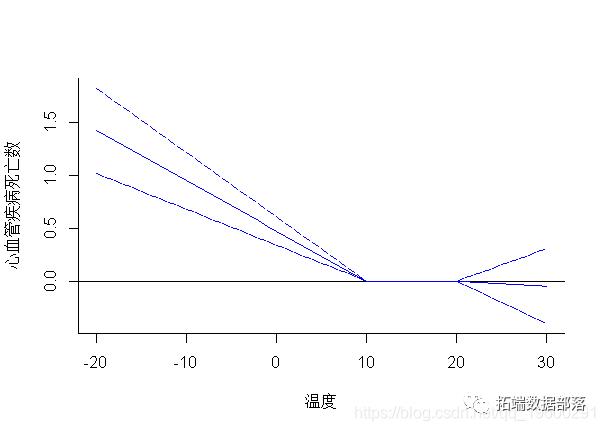
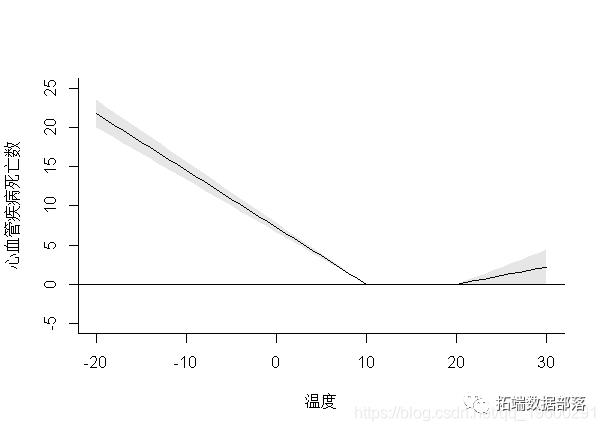
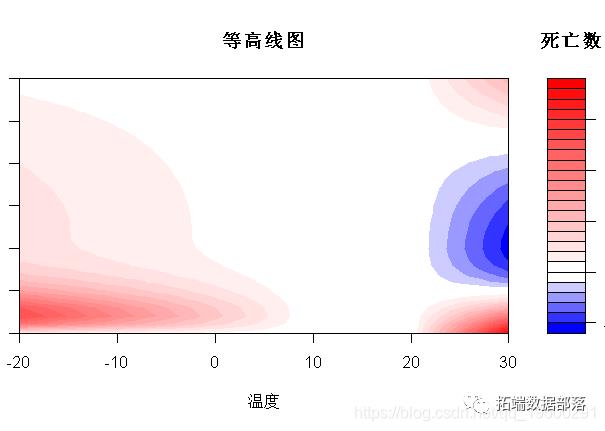
一维或二维关联的解释通过图形表示来辅助。通过方法函数plot(),lines()和points()为类“ crosspred”和“ crossreduce”提供高级和低级绘图功能。例如,我使用对象pred中的预测。plot()方法可以通过参数ptype为“ crosspred”对象生成不同类型的图。具体来说,它会生成整个二维暴露-滞后-反应关联的图形。二维关联可以绘制为3-D或等高线图,例如:
> plot(pred,ptype="3d",main="3D plot"

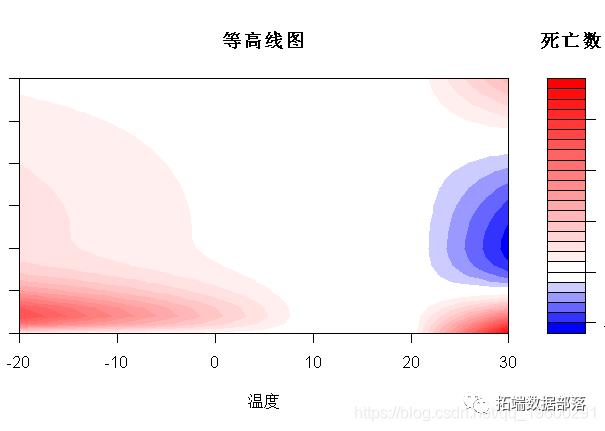
可以通过选择不同的ptype获得定义的关联的摘要。
> plot(pred,"overall"
在这种情况下,方法函数plot()在内部调用函数plot.default(),如上面的示例所示,可以将其他特定参数添加到函数调用中。通过设置ptype =“ slices”,可以将滞后特异性和预测因子特异性关联分别绘制为暴露-反应和滞后-反应关系,因为它们是在3-D曲面中沿特定维度切割的切片。例如:
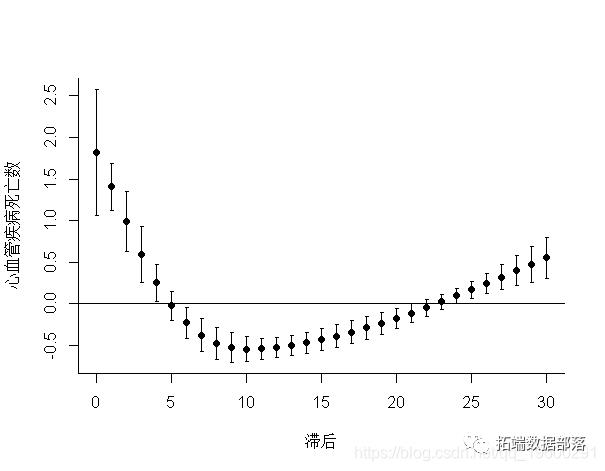
> plot(pred,"slices",lag=5
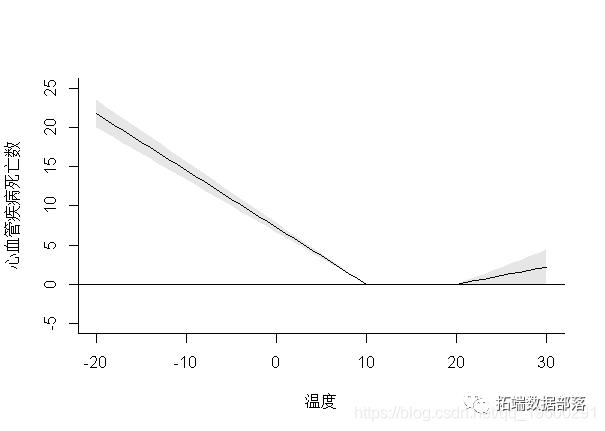
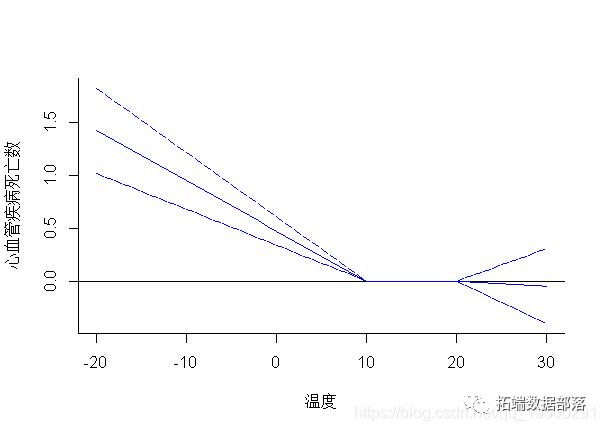
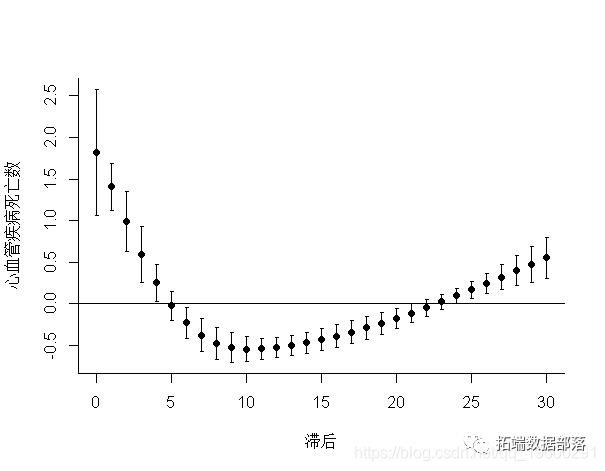
这两个图分别代表了滞后5的暴露反应和特定于25°C温度的滞后反应。参数lag和var指定必须分别绘制lag和特定于预测变量的关联的值。

点击文末 “阅读原文”
获取全文完整代码数据资料。
本文选自《R语言分布滞后非线性模型(DLNM)研究发病率,死亡率和空气污染示例》。
点击标题查阅往期内容
R语言分布滞后线性和非线性模型(DLM和DLNM)建模
分布滞后线性和非线性模型(DLNM)分析空气污染(臭氧)、温度对死亡率时间序列数据的影响
R语言中的分布滞后非线性模型DLNM与发病率和空气污染示例
【视频】R语言中的分布滞后非线性模型(DLNM)与发病率,死亡率和空气污染示例
R语言分布滞后线性和非线性模型(DLNM)分析空气污染(臭氧)、温度对死亡率时间序列数据的影响
R语言分布滞后线性和非线性模型(DLMs和DLNMs)分析时间序列数据
R语言分布滞后非线性模型(DLNM)空气污染研究温度对死亡率影响建模应用R语言分布滞后非线性模型(DLNM)研究发病率,死亡率和空气污染示例
R语言分布滞后线性和非线性模型(DLM和DLNM)建模
R语言广义相加模型 (GAMs)分析预测CO2时间序列数据
Python | ARIMA时间序列模型预测航空公司的乘客数量
R语言中生存分析模型的时间依赖性ROC曲线可视化
R语言ARIMA,SARIMA预测道路交通流量时间序列分析:季节性、周期性
ARIMA模型预测CO2浓度时间序列-python实现
R语言基于递归神经网络RNN的温度时间序列预测
R语言用多元ARMA,GARCH ,EWMA, ETS,随机波动率SV模型对金融时间序列数据建模
R语言神经网络模型预测车辆数量时间序列
卡尔曼滤波器:用R语言中的KFAS建模时间序列
在Python中使用LSTM和PyTorch进行时间序列预测
R语言从经济时间序列中用HP滤波器,小波滤波和经验模态分解等提取周期性成分分析
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
Python中的ARIMA模型、SARIMA模型和SARIMAX模型对时间序列预测
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
R语言多元Copula GARCH 模型时间序列预测
以上是关于R语言分布滞后非线性模型(DLNM)研究发病率,死亡率和空气污染示例|附代码数据的主要内容,如果未能解决你的问题,请参考以下文章
R语言时间序列平稳性几种单位根检验(ADF,KPSS,PP)及比较分析