Python下的正则表达式原理和优化笔记
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python下的正则表达式原理和优化笔记相关的知识,希望对你有一定的参考价值。
由于我都是在python上联系和使用的,所以后面的问题基本都是在python上提出来的,所以这本书中的其它正则流派我均不涉及。依书中,python和perl风格差不多,属于传统NFA引擎,也就是以“表达式主导“,采用回溯机制,匹配到即停止( 顺序敏感,不同于POSIX NFA等采用匹配最左最长的结果)。
对于回溯部分,以及谈及匹配的时候,将引擎的位置总是放在字符和字符之间,而不是字符本身。比如^对应的是第一个字符之前的那个”空白“位置。
基础规则的介绍
python中的转义符号干扰
python中,命令行和脚本等,里面都会对转义符号做处理,此时的字符串会和正则表达式的引擎产生冲突。即在python中字符串‘\\n‘会被认为是换行符号,这样的话传入到re模块中时便不再是‘\\n’这字面上的两个符号,而是一个换行符。所以,我们在传入到正则引擎时,必须让引擎单纯的认为是一个‘\\‘和一个‘n‘,所以需要加上转义符成为‘\\\\n‘,针对这个情况,python中使用raw_input方式,在字符串前加上r,使字符串中的转义符不再特殊处理(即python中不处理,统统丢给正则引擎来处理),那么换行符就是r‘\\n‘
基本字符
. #普通模式下,匹配除换行符外的任意字符。(指定DOTALL标记以匹配所有字符)
量词限定符
* #匹配前面的对象0个或多个。千万不要忽略这里的0的情况。 + #匹配前面的对象1个或多个。这里面的重点是至少有一个。 ? #匹配前面的对象0个或1个。 {m} #匹配前面的对象m次 {m,n} #匹配前面的对象最少m次,最多n次。
锚点符
^ #匹配字符串开头位置,MULTILINE标记下,可以匹配任何\\n之后的位置 $ #匹配字符串结束位置,MULTILINE标记下,可以匹配任何\\n之前的位置
正则引擎内部的转义符号
\\m m是数字,所谓的反向引用,即引用前面捕获型括号内的匹配的对象。数字是对应的括号顺序。 \\A 只匹配字符串开头 \\b 可以理解一个锚点的符号,此符号匹配的是单词的边界。这其中的word定义为连续的字母,数字和下划线。 准确的来说,\\b的位置是在\\w和\\W的交界处,当然还有字符串开始结束和\\w之间。 \\B 和\\b对应,本身匹配空字符,但是其位置是在非"边界"情况下. 比如r‘py\\B‘可以匹配‘python‘,但不能匹配‘py,‘,‘py.‘ 等等 \\d 匹配数字 \\D 匹配非数字 \\s 未指定UNICODE和LOCALE标记时,等同于[ \\t\\n\\r\\f\\v](注意\\t之前是一个空格,表示也匹配空格) \\S 与\\s相反 \\w 未指定UNICODE和LOCALE标记时,等同于[a-zA-Z0-9_] \\W 和\\w相反 \\Z 只匹配字符串结尾 其他的一些python支持的转移符号也都有支持,如前面的‘\\t‘
字符集
[]
尤其注意,这个字符集最终 只匹配一个字符(既不是空,也不是一个以上!),所以前面的一些量词限定符,在这里失去了原有的意义。
另外,‘-‘符号放在两个字符之间的时候,表示ASCII字符之间的所有字符,如[0-9],表示0到9.
而放在字符集开头或者结尾,或者被‘\\‘转义时候,则只是表示特指‘-‘这个符号
最后,当在开头的地方使用‘^‘,表示排除型字符组.
括号的相关内容
普通型括号
(...) 普通捕获型括号,可以被\\number引用。
扩展型括号
(?aiLmsx) a re.A i re.I #忽略大小写 L re.L m re.M s re.S #点号匹配包括换行符 x re.X #可以多行写表达式 如: re_lx = re.compile(r‘(?iS)\\d+$‘) re_lx = re.compile(r‘\\d+‘,re.I|re.S) #这两个编译表达式等价 (?:......) #非捕获型括号,此括号不记录捕获内容,可节省空间 (?P<name>...) #此捕获型括号可以使用name来调用,而不必依赖数字。使用(?P=name)调用。 (?#...) #注释型括号,此括号完全被忽略 (?=...) #positive lookahead assertion 如果后面是括号中的,则匹配成功 (?!...) #negative lookahead assertion 如果后面不是括号中的,则匹配成功 (?<=...) #positive lookbehind assertion 如果前面是括号中的,则匹配成功 (?<!...) #negative lookbehind assertion 如果前面不是括号中的,则匹配成功 #以上四种类型的断言,本身均不匹配内容,只是告知正则引擎是否开始匹配或者停止。 #另外在后两种后项断言中,必须为定长断言。 (?(id/name)yes-pattern|no-pattern) #如有由id或者name指定的组存在的话,将会匹配yes-pattern,否则将会匹配no-pattern,通常情况下no-pattern可以省略。
匹配优先/忽略优先符号
如‘??‘会先匹配没有的情况,然后才是1个对象的情况。而{m,n}?则是优先匹配m个对象,而不是占多的n个对象。
相关进阶知识
python属于perl风格,属于传统型NFA引擎,与此相对的是POSIX NFA和DFA等引擎。所以大部分讨论都针对传统型NFA
传统型NFA中的顺序问题
NFA是基于表达式主导的引擎,同时,传统型NFA引擎会在找到第一个符合匹配的情况下立即停止:即得到匹配之后就停止引擎。
而POSIX NFA 中不会立刻停止,会在所有可能匹配的结果中寻求最长结果。这也是有些bug在传统型NFA中不会出现,但是放到后者中,会暴露出来。
引申一点,NFA学名为”非确定型有穷自动机“,DFA学名为”确定型有穷自动机“
这里的非确定和确定均是对被匹配的目标文本中的字符来说的,在NFA中,每个字符在一次匹配中即使被检测通过,也不能确定他是否真正通过,因为NFA中会出现回溯!甚至不止一两次。图例见后面例子。而在DFA中,由于是目标文本主导,所有对象字符只检测一遍,到文本结束后,过就是过,不过就不过。这也就是”确定“这个说法的原因。
回溯/备用状态
备用状态
回溯机制两个要点
- 在正则引擎选择进行尝试还是跳过尝试时,匹配优先量词和忽略优先量词会控制其行为。
- 匹配失败时,回溯需要返回到上一个备用状态,原则是后进先出(后生成的状态首先被回溯到)
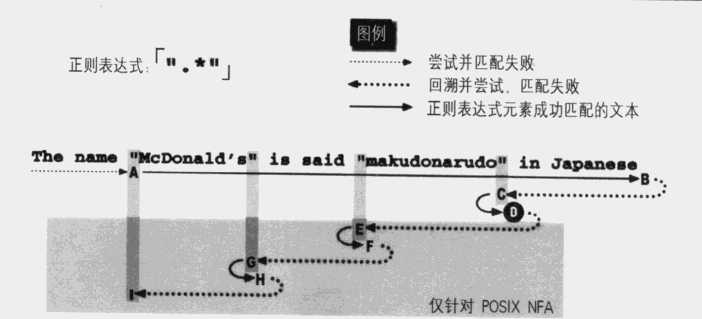
作为对比说明,下面是目标文本不能匹配时,引擎走过的路径:
如下图,我们看到此时POSIX NFA和传统型NFA的匹配路径是一致的。
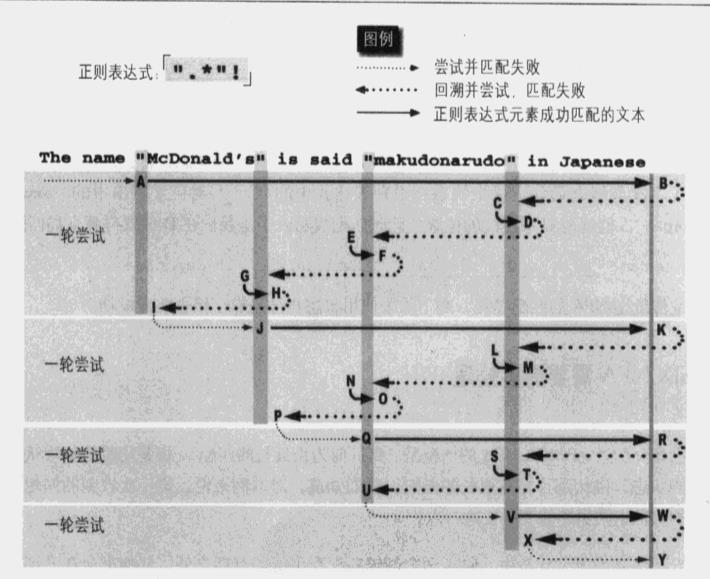
以上的例子引发了一个匹配时的思考,很多时候我们应该尽量避免使用‘.*‘ ,因为其总是可以匹配到最末或者行尾,浪费资源。
既然我们只寻求引号之间的数据,往往可以借助排除型数组来完成工作。
此例中,使用‘[^‘‘]*‘这个来代替‘.*‘的作用显而易见,我们只匹配非引号的内容,那么遇到第一个引号即可退出*号控制权。
固化分组思想
‘\\w+:‘
这个表达式在进行匹配时的流程是这样的,会优先去匹配所有的符合\\w的字符,假如字符串的末尾没有‘:‘,即匹配没有找到冒号,此时触发回溯机制,他会迫使前面的\\w+释放字符,并且在交还的字符中重新尝试与‘:‘作比对。
但是问题出现在这里: \\w是不包含冒号的,显然无论如何都不会匹配成功,可是依照回溯机制,引擎还是得硬着头皮往前找,这就是对资源的浪费。
所以我们就需要避免这种回溯,对此的方法就是将前面匹配到的内容固化,不令其存储备用状态!,那么引擎就会因为没有备用状态可用而只得结束匹配过程。大大减少回溯的次数!
Python模拟固化过程
虽然python中不支持,但书中提供了利用前向断言来模拟固化过程。
(?=(...))\\1
本身, 断言表达式中的结果是不会保存备用状态的,而且他也不匹配具体字符,但是通过巧妙的 添加一个捕获型括号来反向引用这个结果,就达到了固化分组的效果!对应上面的例子则是:
‘(?=(\\w+))\\1:‘
多选结构
多选结构在传统型NFA中, 既不是匹配优先也不是忽略优先。而是按照顺序进行的。所以有如下的利用方式
- 在结果保证正确的情况下,应该优先的去匹配更可能出现的结果。将可能性大的分支尽可能放在靠前。
- 不能滥用多选结构,因为当匹配到多选结构时,缓存会记录下相应数目的备用状态。举例子:[abcdef]和‘a|b|c|d|e|f’这两个表达式,虽然都能完成你的某个目的,但是尽量选择字符型数组,因为后者会在每次比较时建立6个备用状态,浪费资源。
一些优化的理念和技巧
平衡法则
- 只匹配期望的文本,排除不期望的文本。(善于使用非捕获型括号,节省资源)
- 必须易于控制和理解。避免写成天书。。
- 使用NFA引擎,必须要保证效率(如果能够匹配,必须很快地返回匹配结果,如果不能匹配,应该在尽可能短的时间内报告匹配失败。)
处理不期望的匹配
在处理过程中,我们总是习惯于使用星号等非硬性规定的量词(其实是个不好的习惯),
这样的结果可能导致我们使用的匹配表达式中没有必须匹配的字符,例子如下:
‘[0-9]?[^*]*\\d*‘ #只是举个例子,没有实际意义。
上面的式子就是这种情况,在目标文本是“理想”时,可能出现不了什么问题,但是如果本身数据有问题。那么这个式子的匹配结果就完全不可预知。
原因就在于他没有一部分是必须的!它匹配任何内容都是成功的。。。
对数据的了解和假设
引擎中一般存在的优化项
编译缓存
其他技巧和补充内容
过度回溯问题
消除指数级匹配
(\\w+)*
这种情况的表达式,在匹配长文本的时候会遇到什么问题呢,如果在文本匹配失败时(别忘了,如果失败,则说明已经回溯了 所有的可能),想象一下,*号退一个状态,里面的+号就包括其余的 所有状态,验证都失败后,回到外面,*号 退到倒数第二个备用状态,再进到括号内,+号又要回溯一边比上一轮差1的 备用状态数,当字符串很长时, 就会出现指数级的回溯总数。系统就会‘卡死‘。甚至当有匹配时,这个匹配藏在回溯总数的中间时,也是会造成卡死的情况。所以,使用NFA的引擎时,必须要注意这个问题!
我们采用如下思路去避免这个问题:
占有优先量词(python中使用前向断言加反向引用模拟)
道理很简单,既然庞大的回溯数量都是被储存的备用状态导致的,那么我们直接使引擎放弃这些状态。说到底是摆脱(regex*)* 这种形式。
import re re_lx = re.compile(r‘(?=(\\w+))\\1*\\d‘)
效率测试代码
在测试表达式的效率时,可借助以下代码比较所需时间。在两个可能的结果中择期优者。
import re import time re_lx1 = re.compile(r‘your_re_1‘) re_lx2 = re.compile(r‘your_re_2‘) starttime = time.time() repeat_time = 100 for i in range(repeat_time): s=‘test text‘*10000 result = re_lx1.search(s) time1 = time.time()-starttime print(time1) starttime = time.time() for i in range(repeat_time): s=‘test text‘*10000 result = re_lx2.search(s) time2 = time.time()-starttime print(time2)
量词等价转换
综上,python中总体上使用量词不如简单的列出来!(与书中不同!)
锚点优化的利用
下面这个例子假设出现匹配的内容在字符串对象的结尾,那么下面的第一个表达式是快于第二个表达式的,原因在于前者有锚点的优势。
re_lx1 = re.compile(r‘\\d{5}$‘) re_lx2 = re.compile(r‘\\d{5}‘) #前者快,有锚点优化
排除型数组的利用
继续,假设我们要匹配一段字符串中的5位数字,会有如下两个表达式供选择:
经过分析,我们发现\\w是包含\\d的,当使用匹配优先时,前面的\\w会包含数字,之所以能匹配成功,或者确定失败,是后面的\\d迫使前面的量词交还一些字符。
知道这一点,我们应该尽量避免回溯,一个顺其自然的想法就是不让前面的匹配优先量词涉及到\\d
re_lx1 = re.compile(r‘^\\w+(\\d{5})‘) re_lx2 = re.compile(r‘^[^\\d]+\\d{5}‘) #优于上面的表达式
总体来说,在我们没有时间去深入研究模块代码的时候,只能通过尝试和反复修改来得到最终的复合预期的表达式。
常识优化措施
“取巧”的修改又可能会关闭或者避开了这些优化,所以结果也许会令我们很失望。
避免重新编译(循环外创建对象)
使用非捕获型括号(节省捕获时间和回溯时状态的数量)
善用锚点符号
不滥用字符组
提取文本和锚点。将他们从可能的多选分支结构中提取出来,会提取速度。
最可能的匹配表达式放在多选分支前面
一个很好用的核心公式
- special部分和normal部分匹配的开头不能重合。一定保证这两部分在任何情况下不能匹配相同的内容,不然在无法出现匹配时遍历所有情况,此时引擎的路径就不能确定。
- normal部分必须匹配至少一个字符
- special部分必须是固定长度的
举个例子:
[^\\\\"]+(\\\\.[^\\\\"]+)* #匹配两个引号内的文本,但是不包括被转义的引号
以上是关于Python下的正则表达式原理和优化笔记的主要内容,如果未能解决你的问题,请参考以下文章