python文本处理之可视化wordcloud
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python文本处理之可视化wordcloud相关的知识,希望对你有一定的参考价值。
- 什么是词云
词云又叫文字云,是对文本数据中出现频率较高的“关键词”在视觉上的突出呈现,形成关键词的渲染形成类似云一样的彩色图片,从而一眼就可以领略文本数据的主要表达意思。- 准备工作:
python开发环境、wordcloud、jieba、matplotlib、numpy 、PIL 等库文件安装好。
-
pip 安装方法:
- pip install xxx
- 使用idea 直接安装
wordcloud生成词云的原理简介
wordcloud生成词云的原理其实并不复杂,大体分成5步(具体可自行查看源码):1.wordcloud制作词云时,首先要对对文本数据进行分词,使用process_text()方法,这一步的主要任务是去除停用词
2.第二步是计算每个词在文本中出现的频率,生成一个哈希表。词频用于确定一个词的重要性
3.根据词频的数值按比例生成一个图片的布局,类IntegralOccupancyMap 是该词云的算法所在,是词云的数据可视化方式的核心。生成词的颜色、位置、方向等
4.最后将词按对应的词频在词云布局图上生成图片,核心方法是generate_from_frequencies,不论是generate()还是generate_from_text()都最终用到generate_from_frequencies
完成词云上各词的着色,默认是随机着色
5.词语的各种增强功能大都可以通过wordcloud的构造函数实现,里面提供了22个参数,还可以自行扩展。
- demo:
# coding:utf-8
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator, STOPWORDS
import jieba
import numpy as np
from PIL import Image
# 读入背景图片
abel_mask = np.array(Image.open("/home/djh/PycharmProjects/source/test.jpg"))
# 读取要生成词云的文件
text_from_file_with_apath = open(‘/home/djh/PycharmProjects/source/a.txt‘).read()
# 通过jieba分词进行分词并通过空格分隔
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all=True)
wl_space_split = " ".join(wordlist_after_jieba)
# my_wordcloud = WordCloud().generate(wl_space_split) 默认构造函数
my_wordcloud = WordCloud(
background_color=‘white‘, # 设置背景颜色
mask=abel_mask, # 设置背景图片
max_words=200, # 设置最大现实的字数
stopwords=STOPWORDS, # 设置停用词
font_path=‘/home/djh/win_font/simkai.ttf‘, # 设置字体格式,如不设置显示不了中文
max_font_size=50, # 设置字体最大值
random_state=30, # 设置有多少种随机生成状态,即有多少种配色方案
scale=.5
).generate(wl_space_split)
# 根据图片生成词云颜色
image_colors = ImageColorGenerator(abel_mask)
# my_wordcloud.recolor(color_func=image_colors)
# 以下代码显示图片
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
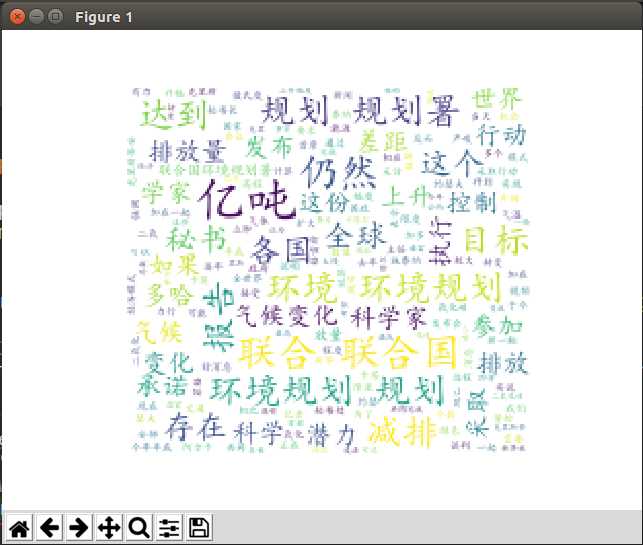
以上是关于python文本处理之可视化wordcloud的主要内容,如果未能解决你的问题,请参考以下文章