[python 学习] 使用 xml.etree.ElementTree 模块处理 XML
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[python 学习] 使用 xml.etree.ElementTree 模块处理 XML相关的知识,希望对你有一定的参考价值。
---恢复内容开始---
导入数据(读文件和读字符串)
本地文件 country_data.xml
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank>1</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank>4</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank>68</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
从文件中读取 xml
import xml.etree.ElementTree as ET tree = ET.parse(‘country_data.xml‘) root = tree.getroot()
从字符串中读取 xml
root = ET.fromstring(country_data_as_string)
Element.tag 、Element.text 和 Element.attributes
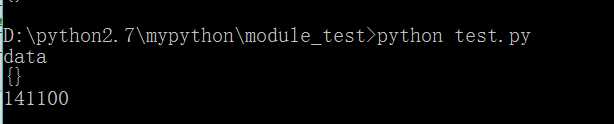
# root.tag 读取 tag 名 # root.attrib 读取 attributes # root[0][1].rank 读取文本值 print root.tag #输出根节点元素<data>的tag名:data print root.attrib #输出根节点元素<data>的attributes(空值):{} print root[0][2].text #输出第一个<country>的子元素<gdppc>的文本值:141100
Element.iter()
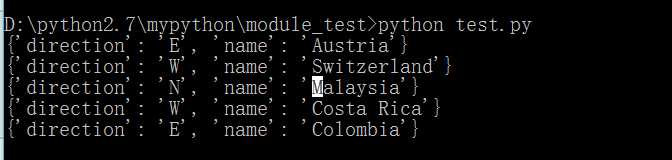
# root.iter(‘neighbor‘)查找所有子孙元素 for neighbor in root.iter(‘neighbor‘): print neighbor.attrib
find() 和 findall()
# find()返回第一个子元素 print root.find(‘country‘) # fund() 返回所有子元素 print root.findall(‘country‘)

照搬手册:
https://docs.python.org/2/library/xml.etree.elementtree.html
以上是关于[python 学习] 使用 xml.etree.ElementTree 模块处理 XML的主要内容,如果未能解决你的问题,请参考以下文章