[python] 常用正则表达式爬取网页信息及分析HTML标签总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[python] 常用正则表达式爬取网页信息及分析HTML标签总结相关的知识,希望对你有一定的参考价值。
版权声明:本文为博主原创文章,转载请注明CSDN博客源地址!共同学习,一起进步~
当然如果会Selenium基于自动化测试爬虫、BeautifulSoup分析网页DOM节点,这就更方便了,但本文更多的是介绍基于正则的底层爬取分析。
涉及内容如下:
- 常用正则表达式爬取网页信息及HTML分析总结
- 1.获取<tr></tr>标签之间内容
- 2.获取<a href..></a>超链接之间内容
- 3.获取URL最后一个参数命名图片或传递参数
- 4.爬取网页中所有URL链接
- 5.爬取网页标题title两种方法
- 6.定位table位置并爬取属性-属性值
- 7.过滤<span></span>等标签
- 8.获取<script></script>等标签内容
- 9.通过replace函数过滤<br />标签
- 10.获取<img ../>中超链接及过滤<img>标签
------------------------------------------------------------------------------------------------------------------------------
1.获取<tr></tr>标签之间内容
该部分主要是通过正则表达式获取两个标签之间的内容,通常这种标签都是成对出现的。开始标签如:<tr>、<th>、<td>、<a>、<table>、<div>...
后缀标签如:</tr>、</th>、</td>、</a>、</table>、</div>...
核心代码:
res_tr = r‘<tr>(.*?)</tr>‘
m_tr = re.findall(res_tr,language,re.S|re.M)
例子:
- # coding=utf-8
- import re
- language = ‘‘‘‘‘<tr><th>性別:</th><td>男</td></tr><tr>‘‘‘
- #正则表达式获取<tr></tr>之间内容
- res_tr = r‘<tr>(.*?)</tr>‘
- m_tr = re.findall(res_tr,language,re.S|re.M)
- for line in m_tr:
- print line
- #获取表格第一列th 属性
- res_th = r‘<th>(.*?)</th>‘
- m_th = re.findall(res_th,line,re.S|re.M)
- for mm in m_th:
- print unicode(mm,‘utf-8‘), #unicode防止乱
- #获取表格第二列td 属性值
- res_td = r‘<td>(.*?)</td>‘
- m_td = re.findall(res_td,line,re.S|re.M)
- for nn in m_td:
- print unicode(nn,‘utf-8‘)
- >>>
- <th>性別:</th><td>男</td>
- 性別: 男
- >>>
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]): 搜索string,以列表形式返回全部能匹配的子串。其中RE的常见参数包括:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法)
re.M(re.MULTILINE): 多行模式,改变‘^‘和‘$‘的行为
re.S(re.DOTALL): 点任意匹配模式,改变‘.‘的行为
------------------------------------------------------------------------------------------------------------------------------
2.获取超链接<a href=..></a>之间内容
通常在使用正则表达式时,需要分析网页链接,获取URL或网页内容。核心代码如下:
res = r‘<a .*?>(.*?)</a>‘
mm = re.findall(res, content, re.S|re.M)
urls=re.findall(r"<a.*?href=.*?<\\/a>", content, re.I|re.S|re.M)
例子:
- # coding=utf-8
- import re
- content = ‘‘‘‘‘
- <td>
- <a href="https://www.baidu.com/articles/zj.html" title="浙江省">浙江省主题介绍</a>
- <a href="https://www.baidu.com//articles/gz.html" title="贵州省">贵州省主题介绍</a>
- </td>
- ‘‘‘
- #获取<a href></a>之间的内容
- print u‘获取链接文本内容:‘
- res = r‘<a .*?>(.*?)</a>‘
- mm = re.findall(
- res, content, re.S|re.M)
- for value in mm:
- print value
- #获取所有<a href></a>链接所有内容
- print u‘\\n获取完整链接内容:‘
- urls=re.findall(r"<a.*?href=.*?<\\/a>", content, re.I|re.S|re.M)
- for i in urls:
- print i
- #获取<a href></a>中的URL
- print u‘\\n获取链接中URL:‘
- res_url = r"(?<=href=\\").+?(?=\\")|(?<=href=\\‘).+?(?=\\‘)"
- link = re.findall(res_url , content, re.I|re.S|re.M)
- for url in link:
- print url
- >>>
- 获取链接文本内容:
- 浙江省主题介绍
- 贵州省主题介绍
- 获取完整链接内容:
- <a href="https://www.baidu.com/articles/zj.html" title="浙江省">浙江省主题介绍</a>
- <a href="https://www.baidu.com//articles/gz.html" title="贵州省">贵州省主题介绍</a>
- 获取链接中URL:
- https://www.baidu.com/articles/zj.html
- https://www.baidu.com//articles/gz.html
- >>>
driver.get(link)
elem = driver.find_elements_by_xpath("//div[@class=‘piclist‘]/tr/dd[1]")
for url in elem:
pic_url = url.get_attribute("href")
print pic_url
参考文章:[python爬虫] Selenium定向爬取虎扑篮球海量精美图片
------------------------------------------------------------------------------------------------------------------------------
3.获取URL最后一个参数命名图片或传递参数
此时需要通过该URL的"/"后面的参数命名图片,则方法如下:
- urls = "http://i1.hoopchina.com.cn/blogfile/201411/11/BbsImg141568417848931_640*640.jpg"
- values = urls.split(‘/‘)[-1]
- print values
- >>>
- BbsImg141568417848931_640*640.jpg
- >>>
此时获取参数方法如下:
- url = ‘http://localhost/test.py?a=hello&b=world‘
- values = url.split(‘?‘)[-1]
- print values
- for key_value in values.split(‘&‘):
- print key_value.split(‘=‘)
- >>>
- a=hello&b=world
- [‘a‘, ‘hello‘]
- [‘b‘, ‘world‘]
- >>>
------------------------------------------------------------------------------------------------------------------------------
4.爬取网页中所有URL链接
在学习爬虫过程中,你肯定需要从固有网页中爬取URL链接,再进行下一步的循环爬取或URL抓取。如下,爬取CSDN首页的所有URL链接。
- # coding=utf-8
- import re
- import urllib
- url = "http://www.csdn.net/"
- content = urllib.urlopen(url).read()
- urls = re.findall(r"<a.*?href=.*?<\\/a>", content, re.I)
- for url in urls:
- print unicode(url,‘utf-8‘)
- link_list = re.findall(r"(?<=href=\\").+?(?=\\")|(?<=href=\\‘).+?(?=\\‘)", content)
- for url in link_list:
- print url
- >>>
- <a href="https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn">登录</a>
- <a href="http://passport.csdn.net/account/mobileregister?action=mobileRegister">注册</a>
- <a href="https://passport.csdn.net/help/faq">帮助</a>
- ...
- https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn
- http://passport.csdn.net/account/mobileregister?action=mobileRegister
- https://passport.csdn.net/help/faq
- ...
- >>>
------------------------------------------------------------------------------------------------------------------------------
5.爬取网页标题title两种方法
获取网页标题也是一种常见的爬虫,如我在爬取维基百科国家信息时,就需要爬取网页title。通常位于<html><head><title>标题</title></head></html>中。
下面是爬取CSDN标题的两种方法介绍:
- # coding=utf-8
- import re
- import urllib
- url = "http://www.csdn.net/"
- content = urllib.urlopen(url).read()
- print u‘方法一:‘
- title_pat = r‘(?<=<title>).*?(?=</title>)‘
- title_ex = re.compile(title_pat,re.M|re.S)
- title_obj = re.search(title_ex, content)
- title = title_obj.group()
- print title
- print u‘方法二:‘
- title = re.findall(r‘<title>(.*?)</title>‘, content)
- print title[0]
- >>>
- 方法一:
- CSDN.NET - 全球最大中文IT社区,为IT专业技术人员提供最全面的信息传播和服务平台
- 方法二:
- CSDN.NET - 全球最大中文IT社区,为IT专业技术人员提供最全面的信息传播和服务平台
- >>>
------------------------------------------------------------------------------------------------------------------------------
6.定位table位置并爬取属性-属性值
如果使用Python库的一些爬取,通常可以通过DOM树结构进行定位,如代码:
login = driver.find_element_by_xpath("//form[@id=‘loginForm‘]")
参考文章:[Python爬虫] Selenium实现自动登录163邮箱和Locating Elements介绍
但如果是正则表达式这种相对传统傻瓜式的方法,通过通过find函数寻找指定table方法进行定位。如:获取Infobox的table信息。
通过分析源代码发现“程序设计语言列表”的消息盒如下:
<table class="infobox vevent" ..><tr><th></th><td></td></tr></table>
- start = content.find(r‘<table class="infobox vevent"‘) #起点记录查询位置
- end = content.find(r‘</table>‘)
- infobox = language[start:end]
- print infobox
- <table class="infobox vevent" cellspacing="3" style="border-spacing:3px;width:22em;text-align:left;font-size:small;line-height:1.5em;">
- <caption class="summary"><b>ActionScript</b></caption>
- <tr>
- <th scope="row" style="text-align:left;white-space:nowrap;;;">发行时间</th>
- <td style=";;">1998年</td>
- </tr>
- <tr>
- <th scope="row" style="text-align:left;white-space:nowrap;;;">实现者</th>
- <td class="organiser" style=";;"><a href="/wiki/Adobe_Systems" title="Adobe Systems">Adobe Systems</a></td>
- </tr>
- <tr>
- <tr>
- <th scope="row" style="text-align:left;white-space:nowrap;;;">启发语言</th>
- <td style=";;"><a href="/wiki/JavaScript" title="JavaScript">JavaScript</a>、<a href="/wiki/Java" title="Java">Java</a></td>
- </tr>
- </table>
然后再在这个infobox内容中通过正则表达式进行分析爬取。下面讲述爬取属性-属性值:
爬取格式如下:
<table>
<tr>
<th>属性</th>
<td>属性值</td>
</tr>
</table>
其中th表示加粗处理,td和th中可能存在属性如title、id、type等值;同时<td></td>之间的内容可能存在<a href=..></a>或<span></span>或<br />等值,都需要处理。下面先讲解正则表达式获取td值的例子:
参考:http://bbs.csdn.net/topics/390353859?page=1
- <table>
- <tr>
- <td>序列号</td><td>DEIN3-39CD3-2093J3</td>
- <td>日期</td><td>2013年1月22日</td>
- <td>售价</td><td>392.70 元</td>
- <td>说明</td><td>仅限5用户使用</td>
- </tr>
- </table>
- # coding=utf-8
- import re
- s = ‘‘‘‘‘<table>
- <tr>
- <td>序列号</td><td>DEIN3-39CD3-2093J3</td>
- <td>日期</td><td>2013年1月22日</td>
- <td>售价</td><td>392.70 元</td>
- <td>说明</td><td>仅限5用户使用</td>
- </tr>
- </table>
- ‘‘‘
- res = r‘<td>(.*?)</td><td>(.*?)</td>‘
- m = re.findall(res,s,re.S|re.M)
- for line in m:
- print unicode(line[0],‘utf-8‘),unicode(line[1],‘utf-8‘) #unicode防止乱码
- #输出结果如下:
- #序列号 DEIN3-39CD3-2093J3
- #日期 2013年1月22日
- #售价 392.70 元
- #说明 仅限5用户使用
------------------------------------------------------------------------------------------------------------------------------
7.过滤<span></span>等标签
在获取值过程中,通常会存在<span>、<br>、<a href>等标签,下面举个例子过滤。
<td><span class="nickname">(字) 翔宇</span></td>过滤标签<span>核心代码:
elif "span" in nn: #处理标签<span>
res_value = r‘<span .*?>(.*?)</span>‘
m_value = re.findall(res_value,nn,re.S|re.M)
for value in m_value:
print unicode(value,‘utf-8‘),
代码如下,注意print中逗号连接字符串:
- # coding=utf-8
- import re
- language = ‘‘‘‘‘
- <table class="infobox bordered vcard" style="width: 21em; font-size: 89%; text-align: left;" cellpadding="3">
- <caption style="text-align: center; font-size: larger;" class="fn"><b>周恩来</b></caption>
- <tr>
- <th>性別:</th>
- <td>男</td>d
- </tr>
- <tr>
- <th>異名:</th>
- <td><span class="nickname">(字) 翔宇</span></td>
- </tr>
- <tr>
- <th>政黨:</th>
- <td><span class="org"><a href="../articles/%E4%B8%AD9A.html" title="中国">中国</a></span></td>
- </tr>
- <tr>
- <th>籍貫:</th>
- <td><a href="../articles/%E6%B5%9981.html" title="浙江省">浙江省</a><a href="../articles/%E7%BB%8D82.html" title="绍兴市">绍兴市</a></td>
- </tr>
- </table>
- ‘‘‘
- #获取table中tr值
- res_tr = r‘<tr>(.*?)</tr>‘
- m_tr = re.findall(res_tr,language,re.S|re.M)
- for line in m_tr:
- #获取表格第一列th 属性
- res_th = r‘<th>(.*?)</th>‘
- m_th = re.findall(res_th,line,re.S|re.M)
- for mm in m_th:
- if "href" in mm: #如果获取加粗的th中含超链接则处理
- restr = r‘<a href=.*?>(.*?)</a>‘
- h = re.findall(restr,mm,re.S|re.M)
- print unicode(h[0],‘utf-8‘), #逗号连接属性值 防止换行
- else:
- print unicode(mm,‘utf-8‘), #unicode防止乱
- #获取表格第二列td 属性值
- res_td = r‘<td>(.*?)</td>‘ #r‘<td .*?>(.*?)</td>‘
- m_td = re.findall(res_td,line,re.S|re.M)
- for nn in m_td:
- if "href" in nn: #处理超链接<a href=../rel=..></a>
- res_value = r‘<a .*?>(.*?)</a>‘
- m_value = re.findall(res_value,nn,re.S|re.M)
- for value in m_value:
- print unicode(value,‘utf-8‘),
- elif "span" in nn: #处理标签<span>
- res_value = r‘<span .*?>(.*?)</span>‘
- m_value = re.findall(res_value,nn,re.S|re.M) #<td><span class="nickname">(字) 翔宇</span></td>
- for value in m_value:
- print unicode(value,‘utf-8‘),
- else:
- print unicode(nn,‘utf-8‘),
- print ‘ ‘ #换行
- >>>
- 性別: 男
- 異名: (字) 翔宇
- 政黨: 中国测试
- 籍貫: 浙江省 绍兴市
- >>>
------------------------------------------------------------------------------------------------------------------------------
8.获取<script></script>等标签内容
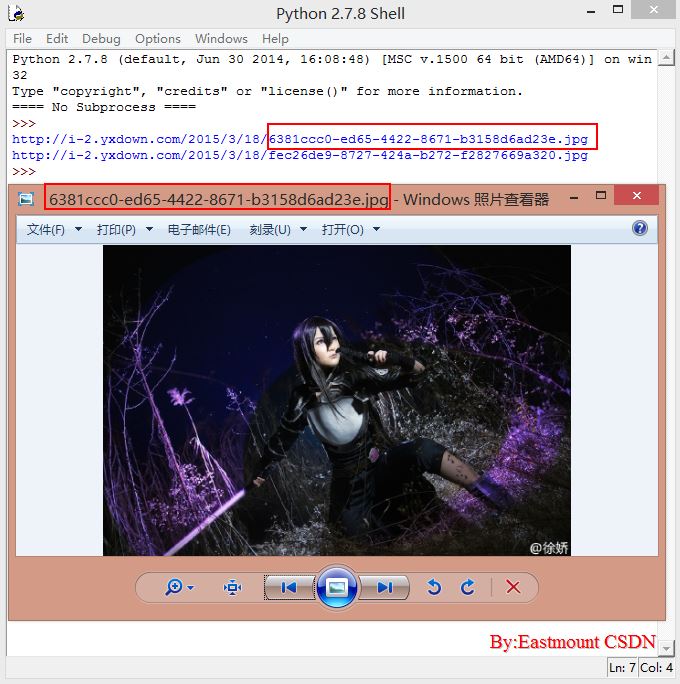
比如在获取游讯网图库中,图集对应的原图它是存储在script中,其中获取原图-original即可,缩略图-thumb,大图-big,通过正则表达式下载URL:
res_original = r‘"original":"(.*?)"‘ #原图
m_original = re.findall(res_original,script)
代码如下:
- # coding=utf-8
- import re
- import os
- content = ‘‘‘‘‘
- <script>var images = [
- { "big":"http://i-2.yxdown.com/2015/3/18/KDkwMHgp/6381ccc0-ed65-4422-8671-b3158d6ad23e.jpg",
- "thumb":"http://i-2.yxdown.com/2015/3/18/KHgxMjAp/6381ccc0-ed65-4422-8671-b3158d6ad23e.jpg",
- "original":"http://i-2.yxdown.com/2015/3/18/6381ccc0-ed65-4422-8671-b3158d6ad23e.jpg",
- "title":"","descript":"","id":75109},
- { "big":"http://i-2.yxdown.com/2015/3/18/KDkwMHgp/fec26de9-8727-424a-b272-f2827669a320.jpg",
- "thumb":"http://i-2.yxdown.com/2015/3/18/KHgxMjAp/fec26de9-8727-424a-b272-f2827669a320.jpg",
- "original":"http://i-2.yxdown.com/2015/3/18/fec26de9-8727-424a-b272-f2827669a320.jpg",
- "title":"","descript":"","id":75110},
- </script>
- ‘‘‘
- html_script = r‘<script>(.*?)</script>‘
- m_script = re.findall(html_script,content,re.S|re.M)
- for script in m_script:
- res_original = r‘"original":"(.*?)"‘ #原图
- m_original = re.findall(res_original,script)
- for pic_url in m_original:
- print pic_url
- filename = os.path.basename(pic_url) #去掉目录路径,返回文件名
- urllib.urlretrieve(pic_url, ‘E:\\\\‘+filename) #下载图片
参考文章: [python学习] 简单爬取图片网站图库中图片
------------------------------------------------------------------------------------------------------------------------------
9.通过replace过滤<br />标签
在获取值过程中,通常会存<br />标签,它表示HTML换行的意思。常用的方法可以通过标签‘<‘和‘>‘进行过滤,但是这里我想讲述的是一种Python常用的过滤方法,在处理中文乱码或一些特殊字符时,可以使用函数replace过滤掉这些字符。核心代码如下:
if ‘<br />‘ in value:
value = value.replace(‘<br />‘,‘‘) #过滤该标签
value = value.replace(‘\\n‘,‘ ‘) #换行空格替代 否则总换行
例如过滤前后的例子:
達洪阿 異名: (字) 厚菴<br /> (諡) 武壯<br /> (勇號) 阿克達春巴圖魯
達洪阿 異名: (字) 厚菴 (諡) 武壯 (勇號) 阿克達春巴圖魯
------------------------------------------------------------------------------------------------------------------------------
10.获取<img ../>中超链接及过滤<img>标签
在获取值属性值过程中,可能在分析table/tr/th/td标签后,仍然存在<img />图片链接,此时在获取文字内容时,你可能需要过滤掉这些<img>标签。这里采用的方法如下:
value = re.sub(‘<[^>]+>‘,‘‘, value)
例如:
- #encoding:utf-8
- import os
- import re
- value = ‘‘‘‘‘
- <table class="infobox" style="width: 21em; text-align: left;" cellpadding="3">
- <tr bgcolor="#CDDBE8">
- <th colspan="2">
- <center class="role"><b>中華民國政治人士</b><br /></center>
- </th>
- </tr>
- <tr>
- <th>性別:</th>
- <td>男</td>
- </tr>
- <tr>
- <th>政黨:</th>
- <td><span class="org">
- <img alt="中國國民黨" src="../../../../images/Kuomintang.svg.png" width="19" height="19" border="0" />
- <a href="../../../../articles/%8B%E6%B0%91%E9%BB%A8.html" title="中國國民黨">中國國民黨</a></span></td>
- </tr>
- </table>
- ‘‘‘
- value = re.sub(‘<[^>]+>‘,‘‘, value) #过滤HTML标签
- print value
- >>>
- 中華民國政治人士
- 性別:
- 男
- 政黨:
- 中國國民黨
- >>>
- if ‘<br />‘ in value:
- value = value.replace(‘<br />‘,‘‘)
- value = value.replace(‘\\n‘,‘ ‘)
- value = re.sub(‘<[^>]+>‘,‘‘, value) #过滤HTML标签
- print value
- #输出仅仅一行如下:
- #中華民國政治人士 性別: 男 政黨: 中國國民黨
- test = ‘‘‘‘‘<img alt="中國國民黨" src="../images/Kuomintang.png" width="19" height="19" border="0" />‘‘‘
- print re.findall(‘src="(.*?)"‘,test)
- >>>
- [‘../images/Kuomintang.png‘]
- >>>
最后希望文章对你有所帮助,后面如果遇到新的相关知识,我也会即使的更新添加的。
(By:Eastmount 2016-04-07 清晨6点 http://blog.csdn.net/eastmount/)
以上是关于[python] 常用正则表达式爬取网页信息及分析HTML标签总结的主要内容,如果未能解决你的问题,请参考以下文章
常用正则表达式最强汇总(含Python代码举例讲解+爬虫实战)