自学python之爬虫2
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自学python之爬虫2相关的知识,希望对你有一定的参考价值。
这次爬取的是淘宝网,通过关键词搜索后,获取结果中商品的名称和价格
1 import requests 2 import re 3 4 #获取页面 5 def getHTMLText(url): 6 try: 7 r = requests.get(url, timeout=30) 8 r.raise_for_status() 9 r.encoding = r.apparent_encoding 10 return r.text 11 except: 12 return "get fail" 13 14 #解析页面 15 def parsePage(ilt, html): 16 try: 17 plt = re.findall(r‘\\"view_price\\"\\:\\"[\\d\\.]*\\"‘,html) #商品价格 18 tlt = re.findall(r‘\\"raw_title\\"\\:\\".*?\\"‘,html) #商品名称 19 for i in range(len(plt)): 20 price = eval(plt[i].split(‘:‘)[1]) 21 title = eval(tlt[i].split(‘:‘)[1]) 22 ilt.append([price , title]) 23 except: 24 print(‘parse fail‘) 25 26 #输出商品信息 27 def printGoodsList(ilt): 28 tplt = "{:4}\\t{:8}\\t{:16}" 29 print(tplt.format("序号", "价格", "商品名称")) 30 count = 0 31 for g in ilt: 32 count = count + 1 33 print(tplt.format(count, g[0], g[1])) 34 35 #主函数 36 def main(): 37 goods = ‘书包‘ #搜索关键词 38 depth = 2 #搜索深度,即页数 39 start_url = ‘https://s.taobao.com/search?q=‘ + goods 40 infoList = [] 41 for i in range(depth): 42 try: 43 url = start_url + ‘&s=‘ + str(44*i) 44 html = getHTMLText(url) 45 parsePage(infoList, html) 46 except: 47 continue 48 printGoodsList(infoList) 49 50 main()
结果:
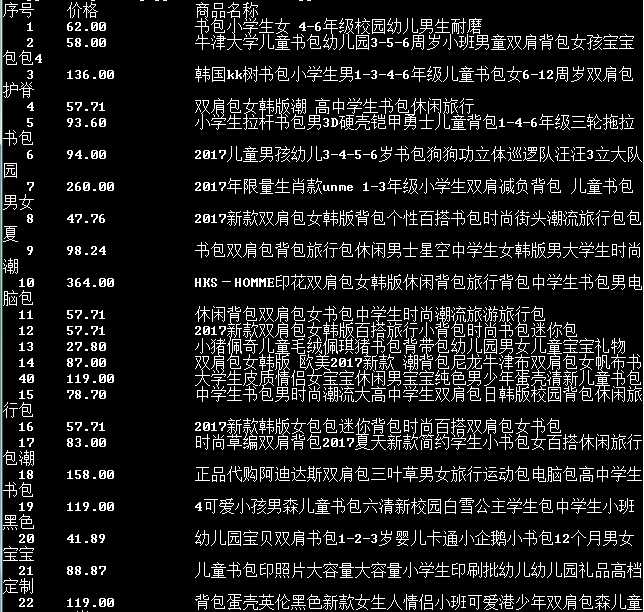
以上是关于自学python之爬虫2的主要内容,如果未能解决你的问题,请参考以下文章