JS 做一个简单的 Parser
Posted 1bite
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JS 做一个简单的 Parser相关的知识,希望对你有一定的参考价值。
 本文使用简单易懂的代码,实现了一组可以构造解析器的函数。相信通过本文的演示,你应该对解析器的基本工作原理有了一个浅浅的了解。
本文使用简单易懂的代码,实现了一组可以构造解析器的函数。相信通过本文的演示,你应该对解析器的基本工作原理有了一个浅浅的了解。
前言
前些天偶然看到以前写的一份代码,注意有一段尘封的代码,被我遗忘了。这段代码是一个简单的解析器,当时是为了解析日志而做的。最初解析日志时,我只是简单的正则加上分割,写着写着,我想,能不能用一个简单的方案做个解析器,这样可以解析多种日志。于是就有了这段代码,后来日志解析完了,没有解析其它日志就给忘了。再次看到这段代码,用非常简单易读的代码就实现了一个解析器,觉得非常值得分享。
思路
言归正传,这个简单的解析器是怎么构思的呢?那要先从模式匹配开始。解析与模式匹配有很多相似之处,比如解析一个整数,跟匹配一个整数就是相似的。都需要根据整数的文法 0|[1-9]\\d* 把文本中满足文法的部分找出来,不同的是,当说到解析整数的时候,我们希望得到的结果是一个整数,而不是一段文本。更进一步,如果我们已经知道如何解析整数,那么解析加减表达式又可以看到一些相似性。加减表达式的文法可以表示为 num (\'+\'|\'-\' num)*,就像文本模式匹配一样,需要对一些“东西”的到达顺序、重复次数、分支进行匹配。
从上面的描述可以看出,我们要做的是某种模式匹配。模式匹配的明星非正则表达式莫数。观察正则表达式,我们基本的需求都有啥?比如有,匹配一个字符或者按顺序出现的字符。好了,就从这两点出发。我们可以设计两个函数,一个 match 函数用来匹配单个字符,一个 seq 函数表示按顺序匹配。显然,多个 match 就可以形成 seq,seq 是一个高阶函数。但是,seq 是直接组合 match 吗?当然不是,因为 match 需要一个参数,表示需要匹配的字符是哪个,所以 match 也是一个高阶函数,而 seq 需要 match 产生的函数组合成新函数,即 seq([match(\'a\'), match(\'b\'), match(\'c\')])。那 match 和 seq 生成的函数是什么?答案是匹配器。允许我们直接对文本进行匹配:
const match_a = match(\'a\');
match_a(\'abc\');
const match_abc = seq([match(\'a\'), match(\'b\'), match(\'c\')]);
match_abc(\'abc\');
由于我们要组合函数,所以匹配器不是只简单返回 bool 值,这样组合过程中,状态会丢失。我们让匹配器返回两个值:一个是匹配后剩余的字符串;一个是匹配是否成功。于是我们就有了:
declare type Matcher = (src: string) => [string, bool];
function match(ch): Matcher
return src =>
if (src.startsWith(ch)) return [src.substring(1), true];
return [src, false];
;
// 顺序匹配,其中一个失败则整体失败
function seq(steps: Matcher[]): Matcher
return src =>
for (const step of steps)
const [rest, ok] = step(src);
if (!ok) return [src, false];
src = rest;
return [src, true];
;
试试看。
const match_a = match(\'a\');
console.log(...match_a(\'abc\')); // "bc" true
console.log(...match_a(\'def\')); // "def" false
const match_abc = seq([match(\'a\'), match(\'b\'), match(\'c\')]);
match_abc(\'abc\');
console.log(...match_abc(\'abc\')); // "" true
console.log(...match_abc(\'abd\')); // "abd" false
妙极了!

拥抱正则表达式
接下来,我们可以在这个基础上实现正则表达式的其它模式,比如:
alt。候选列表,列表中有一个匹配成功则成功,一个失败则整体失败。是正则表达式中是|和[]。opt。可选,正则表达的?模式。many。多次重复,正则表达式中的*模式。
其它不一一列举,如果继续下去,应该能实现一个自己的正则表达式,但不是我们的目标,我想先回到“解析”上。
观察 match 函数,它只能匹配一个字符,如果要匹配多个则要使用 seq 进行组合,不是很方便。既然正则表达式可以进行文本匹配,我们没有必要重复正则表达式的工作,直接利用它就好。所以,我们可以把正则表达式作为 match 的参数:
function match(pattern: RegExp): Matcher
// ...
解析
前面说过,解析整数的结果是整数而不是长得像整数的字符串,因此,Matcher 不能返回 bool,而应该是某个“结果”。所以 Matcher 的签名应该是 (src: string) => [string, any]。怎么把文本变成那个“结果”呢,可以在 match 后面加一个回调,表示匹配到了文本后,应该如何处理这个文本。显然,这个回调的输入参数是匹配到的文本,输出是“结果”,即 (token: string) => any。我们把这个回调函数取名为 Action。
如果现在尝试去改 match 函数,就会发现一个问题,seq 函数也返回 Matcher,但这个匹配器执行后应该返回什么“结果”呢?为解决这个问题,我们也需要给 seq 函数添加 Action,只不过 seq 函数的 Action 的输入参数是一个列表。还有,匹配成功后,我也可以不做任何动作,此时把匹配的文本继续往下传即可。现在我们再修改代码:
declare type Matcher = (src: string) => [string, any];
declare type Action = (val: any) => any;
function noop(tok: any) return tok;
// 用 `pattern` 匹配文本的开头
function match(pattern: RegExp, action: Action = noop): Matcher
return src =>
const m = pattern.exec(src);
if (!m || m.index !== 0) throw new Error(`unexpected token \'$src[0]\'`);
const rest = src.substring(m[0].length);
return [rest, action(m[0])];
;
// 顺序匹配,其中一个失败则整体失败
function seq(steps: Matcher[], action: Action = noop): Matcher
return src =>
const list: any[] = [];
for (const step of steps)
const [rest, val] = step(src); // `step` 函数会 `throw`,因此一个失败整体就会失败
src = rest;
list.push(val);
return [src, action(list)];
;
玩玩看:
const match_helloworld = seq([match(/hello/), match(/ /), match(/world/)]);
console.log(...match_helloworld(\'hello world\')); // "" ["hello", " ", "world"]
console.log(...match_helloworld(\'helloworld\')); // Error: unexpected token \'w\'
还是妙,但目前为止还算常规,跟正则表达式差不多。那么,接下来看下面这个例子:
const int = match(/0|[1-9]\\d*/, Number); // 用整数的文法匹配文本,并把匹配到的文本直接转成 js 的 `number`
// 根据文法 `int(\'+\'|\'-\')int` 进行匹配,并根据中间 token 进行计算
const Exp = seq([int, match(/\\+|\\-/), int], toks =>
if (toks[1] === \'+\') return toks[0] + toks[2]; // 因为 `int` 函数返回的是 `number`,所以这里可以直接进行计算!
if (toks[1] === \'-\') return toks[0] - toks[2];
return toks;
);
console.log(...Exp(\'1+2\')); // "" 3
console.log(...Exp(\'5-3\')); // "" 2
现在是不是更妙了。

完全体
光有 seq 可不能满足解析的全部需求,还得要把其它模式加进来,我就不一一说明其它模式的实现方法了,直接给出全部代码,相信看代码也很好理解:
declare type Matcher = (src: string) => [string, any];
declare type Action = (val: any) => any;
function noop(tok: any) return tok;
// 原来的 `match` 函数,改了个名字
function token(pattern: string|RegExp, action: Action = noop): Matcher
if (pattern instanceof RegExp)
return (src) =>
if (src.length === 0) throw new SyntaxError("Unexpected EOS");
const regex = new RegExp(pattern.source[0] === \'^\' ? pattern.source : \'^\' + pattern.source);
const m = regex.exec(src);
if (!m || m.index !== 0)
throw new SyntaxError(`Unexpected token \'$src[0]\', expected: $pattern`);
const rest = src.substring(m[0].length);
return [rest, action(m[0])];
;
else if (typeof pattern === "string")
return (src) =>
if (src.length === 0) throw new SyntaxError("Unexpected EOS");
if (!src.startsWith(pattern))
throw new SyntaxError(`Unexpected token \'$src[0]\', expected: $pattern`);
const rest = src.substring(pattern.length);
if (action) return [rest, action(pattern)];
return [rest, pattern];
;
throw Error("pattern must to be instance of string or RegExp");
// 顺序匹配,其中一个失败则整体失败
function seq(steps: Matcher[], action: Action = noop): Matcher
return src =>
const list: any[] = [];
for (const step of steps)
const [rest, val] = step(src); // `step` 函数会 `throw`,因此一个失败整体就会失败
src = rest;
list.push(val);
return [src, action(list)];
;
// 可选匹配
function opt(step: Matcher, action: Action = noop): Matcher
return (src) =>
try
const [rest, v] = step(src);
return [rest, action(v)];
catch (err)
return [src, undefined]; // 也许这里可以改成 `return [src, action("")]`;
;
// 候选列表匹配,列表中其中一个匹配即可
function alt(steps: Matcher[], action: Action = noop): Matcher
return (src) =>
for (const step of steps)
try
const [rest, v] = step(src);
return [rest, action(v)];
catch (_)
// mute
throw new Error(`unknown token $src[0]`);
;
// 重复任意次数
function many(item: Matcher, action: (vals: any[]) => any = noop): Matcher
return src =>
let list: any[] = [];
let val = undefined;
while (true)
try
[src, val] = item(src);
list.push(val);
catch (_)
break;
return [src, action(list)];
;
// 带分隔符的重复,即满足 `item (sep item)*` 这种文法的
function many_sep(sep: Matcher, item: Matcher, action: (vals: any[]) => any = noop): Matcher
const etc = seq([sep, item], vs => vs[1]);
return (src) =>
let list: any[] = [];
let val = undefined;
try
[src, val] = item(src);
list.push(val);
catch (_)
return [src, action(list)];
// 以下逻辑也可通过调用 `many` 实现
while (true)
try
[src, val] = etc(src);
list.push(val);
catch (_)
break;
return [src, action(list)];
;
好了,直接攒个大活儿,咱们用这些东西解析 JSON 看看:
const ws = token(/\\s*/);
const Sep = seq([token(\',\'), opt(ws)], v => v[0]); // 也可以简写为 `token(/,\\s*/)`
const Str = token(/"([^\\\\"]|\\\\[\\\\\\/bfrtn]|\\\\u[0-9a-fA-F]0)*"/, JSON.parse); // 这里使用 `JSON.parse` 算是作弊,不过用它让演示代码缩短了不少
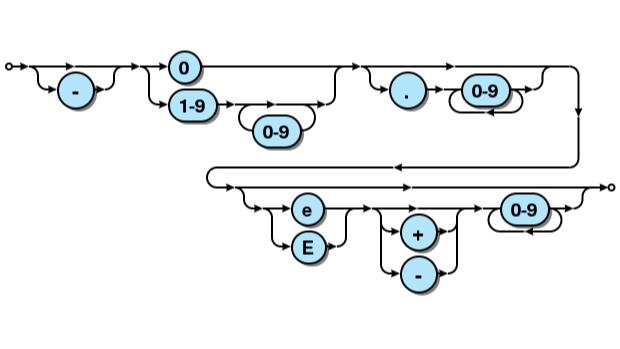
const Num = token(/-?(0|[1-9]\\d*)(\\.\\d+)?([eE][\\+\\-]?\\d+)?/, Number);
// Elems = Val (\',\' Val)*
const Elems = many_sep(Sep, src => Val(src));
// KVs = KV (\',\' KV)*
const KVs = many_sep(Sep, src => KV(src));
// js 中可以直接使用 `Object.fromEntries`
function objFromKVs(kvs: [string, any][])
return kvs.reduce((obj, [k, v]) => obj[k] = v; return obj; , as any);
// Val = Str | Num | \'true\' | \'false\' | \'null\' | \'[\' ws Elems ws \']\' | \'\' ws KVs ws \'\'
const Val = alt([
Str,
Num,
token(/true|false/, token => token === \'true\'),
token(/null/, _ => null),
seq([token(\'[\'), ws, Elems, ws, token(\']\')], v => v[2]), // \'[\' ws Elems ws \']\'
seq([token(\'\'), ws, KVs, ws, token(\'\')], v => objFromKVs(v[2] as any[])) // \'\' ws KVs ws \'\'
]);
// KV = Str ws \':\' ws Val
const KV = seq([
Str,
ws,
token(\':\'),
ws,
Val,
], kv => [kv[0], kv[4]]); // 匹配 KV 列表,并转换成 `[[key, val]...]` 的形式
// 演示
console.log(...Val(\'[1, 2.3e4, true, null, "\\\\t"]\')); // "" [1, 23000, true, null, " "]
console.log(...Val(\' "k1": 123, "k2": true \')); // "" k1: 123, k2: true
怎么样,相当不错吧!!!

接下来再演示下进阶版本的表达式解析与求值,支持加、减、乘、除和括号:
// Factor = \'(\' ws Exp ws \')\' | Num
const Factor = alt([
seq([token(\'(\'), ws, src => Exp(src), ws, token(\')\')], vals => vals[2]),
Num,
]);
// Term = Factor (ws \'*|/\' ws Factor)*
const Term = seq([Factor, many(seq([ws, token(/\\*|\\//), ws, Factor]))], ([head, tail]) =>
return (tail as any[]).reduce((acc, x) =>
if (x[1] === \'*\') return acc * x[3];
if (x[1] === \'/\') return acc / x[3];
return acc;
, head);
);
// Exp = Term (ws \'+|-\' ws Term)*
const Exp = seq([Term, many(seq([ws, token(/\\+|-/), ws, Term]))], ([head, tail]) =>
return (tail as any[]).reduce((acc, x) =>
if (x[1] === \'+\') return acc + x[3];
if (x[1] === \'-\') return acc - x[3];
return acc;
, head);
);
console.log(...Exp(\'( 1 + 2 * 5 ) * 3\')); // "" 33
总结
本文使用简单易懂的代码,实现了一组可以构造解析器的函数。相信通过本文的演示,你应该对解析器的基本工作原理有了一个浅浅的了解。实际上,我们实现的这一组函数是一种领域特定语言,即 DSL。虽然实现方式简单,但不妨碍这种 DSL 的实用性,在日常的小脚本中,更加体现它的小巧、易懂、功能强大。不过也要注意的是,我是以小巧、简易为目标实现的,所以性能不是首要目标,将本文的实现用于性能挑剔的场合肯定是不合适的。
以上是关于JS 做一个简单的 Parser的主要内容,如果未能解决你的问题,请参考以下文章
仍然需要使用带有 passport.js 的 cookie-parser 吗?
java,typescript基础角度项目parser.js错误
使用 node.js 和 node-csv-parser(节点模块)提示 csv 文件下载为弹出窗口