Python学习之旅—Day07(生成器与迭代器)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python学习之旅—Day07(生成器与迭代器)相关的知识,希望对你有一定的参考价值。
前言
本篇博客主要专注于解决函数中的一个重要知识点——生成器与迭代器。不管是面试还是工作,生成器与迭代器在实际工作中的运用可以说是非常多,从我们第一天开始学习for循环来遍历字典,列表等数据类型时,我们就已经和生成器,迭代器打交道了!本篇博客从最基础的基本概念,例如容器,可迭代对象,生成器,迭代器的概念,到for循环是怎么工作的娓娓道来。希望本篇博客能够帮助大家切实掌握生成器与迭代器的使用与底层原理。
一.容器
容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个地迭代获取,可以用in, not in关键字判断元素是否包含在容器中。那到底什么是迭代呢?迭代就是从某个容器对象中逐个地读取元素,直到容器中没有更多元素为止。我们在前面所学习过的列表,字典和集合等数据结构都是容器,它们将所有的元素都存储在内存中;但是有一些特例,例如生成器和迭代器对象,它们并非将元素直接放在内存中。在Python中,一些常见的容器对象如下所示:
list, deque, ....
set, frozensets, ....
dict, defaultdict, OrderedDict, Counter, ....
tuple, namedtuple, …
str
为了方便各位同学理解各种数据结构中的概念,这里我借用网络上的一张图来表示他们的关系,如下所示:
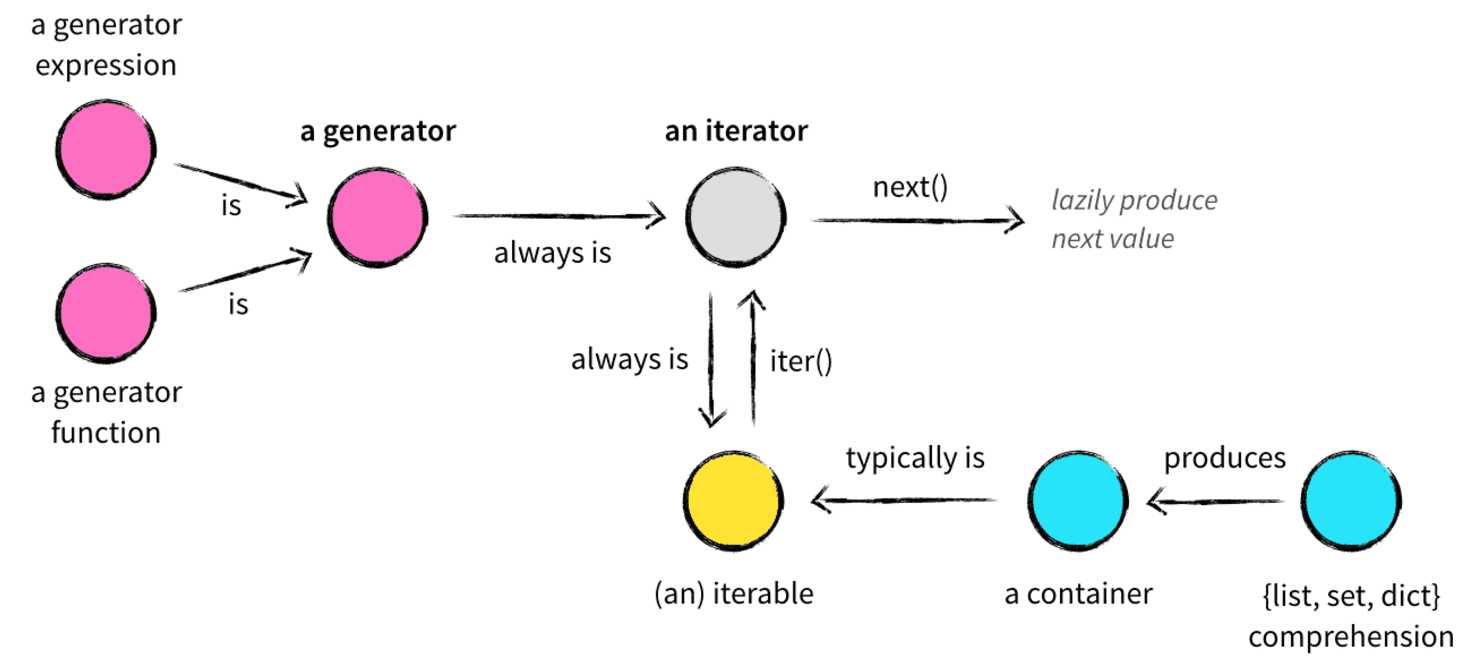 容器比较好理解,我们可以将它看作是一个箱子,可以往里面塞任何东西。从技术上而言,当我们需要查询某个元素是否在某个对象中时,此时这个对象就是一个容器,例如我们前面学过的字符串,字典,列表,元组等都可以看作是一个容器,我们都可以使用in 或者not in来判断某个元素在或者不在其中,一起来看看下面的代码:
容器比较好理解,我们可以将它看作是一个箱子,可以往里面塞任何东西。从技术上而言,当我们需要查询某个元素是否在某个对象中时,此时这个对象就是一个容器,例如我们前面学过的字符串,字典,列表,元组等都可以看作是一个容器,我们都可以使用in 或者not in来判断某个元素在或者不在其中,一起来看看下面的代码:
s = "spark is very important"
if ‘spark‘ in s:
print("spark is in s!!")
else:
print("spark is not in s")
item_list = [1, 2, 3, "spark", "python"]
if "hadoop" not in item_list:
print("hadoop is not in item_list")
else:
print("hadoop is in item_list")
item_tuple = (1, "spark", "hadoop")
if "python" not in item_list:
print("python is not in item_tuple")
else:
print("python is in item_tuple")
column_dic = {‘id‘: 0, ‘name‘: 1, ‘age‘: 2, ‘phone‘: 3, ‘job‘: 4}
if ‘gender‘ in column_dic.keys():
print("gender is in column_dic‘keys")
else:
print("gender is not in column_dic‘keys")
打印结果如下:
spark is in s!!
hadoop is not in item_list
python is in item_tuple
gender is not in column_dic‘keys
尽管绝大多数容器都提供了某种方式来获取其中的每一个元素,但这并不是容器本身提供的能力,而是可迭代对象赋予了容器这种能力。这里要特别说明的是并不是所有的容器都是可迭代的,例如:Bloom filter,虽然Bloom filter可以用来检测某个元素是否包含在容器中,但是并不能从容器中获取其中的每一个值,因为Bloom filter压根就没把元素存储在容器中,而是通过一个散列函数映射成一个值保存在数组中。下面我们就来一起探讨什么事可迭代对象。
二.可迭代对象
刚才我们说过,很多的数据类型都是可迭代对象,例如字符串,列表,字典等。另外也包含一些其他的对象,例如文件句柄,socket对象。通俗一点讲,凡是实现了__iter__方法的对象就是可迭代对象,我们可以从中按一定次序提取出其中的元素。下面通过实际的代码来讲解:
from collections import Iterable # 导入该模块,用于检测一个对象是否可迭代
print(isinstance(‘python‘, Iterable)) # 返回True
print(isinstance((123, 456), Iterable)) # 返回True
print(isinstance([1, 2, 3, "spark", "python"], Iterable)) # 返回True
通过上面程序运行结果分析可知,字符串,元组,列表等数据类型都是可迭代的,我们使用英文单词Iterable来描述一个对象是否可迭代
刚才我们说过可迭代对象都实现了__iter__方法,那我们现在就来看看,如果一个可迭代对象调用__iter__方法会返回什么?如下:
item_list = [1, 2, 3, "spark", "python"]
print(item_list.__iter__(), type(item_list.__iter__()))
# 打印 <list_iterator object at 0x000002C39C3B9780> <class ‘list_iterator‘>
从上面程序运行的结果可知,可迭代对象item_list调用__iter__方法返回的是一个list_iterator,从字面意思上我们可以翻译为列表迭代器,那如果是元组和字典呢?我们继续来看下面的代码:
item_tuple = (1, "spark", "hadoop")
print(item_tuple.__iter__(), type(item_tuple.__iter__()))
# 打印 <tuple_iterator object at 0x000001E48E4E9470> <class ‘tuple_iterator‘>
column_dic = {‘id‘: 0, ‘name‘: 1, ‘age‘: 2, ‘phone‘: 3, ‘job‘: 4}
print(column_dic.__iter__(), type(column_dic.__iter__()))
# 打印 <dict_keyiterator object at 0x000001E48E380C78> <class ‘dict_keyiterator‘>
从运行结果可知,当我们分别使用元组和字典调用__iter__方法时,返回的分别是元组迭代器和字典迭代器,而且前面打印出元组迭代器和字典迭代器在内存中的地址值。因此我们可以得出结论:可迭代对象实现了__iter__方法,在可迭代对象上调用__iter__方法会返回一个迭代器对象(刚才我们打印出来迭代器对象在内存中的地址值),而且迭代器是一种统称,具体而言,根据不同的可迭代对象,可以有列表迭代器,元组迭代器,字典迭代器等。下面我们就来具体探讨下迭代器的概念与底层原理。
三.迭代器
刚才我们讲过,可迭代对象调用__iter__方法会返回一个迭代器对象。那到底什么是迭代器呢?
迭代器是一个带状态的对象,它能在你调用next()方法的时候返回容器中的下一个值,任何实现了__iter__和__next__()(python2中实现next())方法的对象都是迭代器,__iter__返回迭代器自身,__next__返回容器中的下一个值,如果容器中没有更多元素了,则抛出StopIteration异常。
为了方便大家更好地理解迭代器概念,我们首先来看看列表迭代器(list_iterator)比列表多了哪些方法。实现思路很简单,使用dir命令求出列表迭代器和列表的内置方法,然后再变为集合,最后取差集,一起来看下面的代码:
dir(lst_iterator)是列表迭代器lst_iterator实现的所有方法,dir(item_list)是列表中实现的所有方法,都是以列表的形式返回给我们的,为了更清楚地观察它们,
我们分别把他们转换成集合,然后取差集。
item_list = [1, 2, 3, "spark", "python"] lst_iterator = item_list.__iter__() print(set(dir(lst_iterator)) - set(dir(item_list))) # 打印 {‘__setstate__‘, ‘__length_hint__‘, ‘__next__‘}
从运行结果可知,列表迭代器比列表多了3个方法,那这3个方法究竟有什么用呢?来看看下面的代码:
item_list = [1, 2, 3, "spark", "python"] lst_iterator = item_list.__iter__() # __length_hint__()方法返回迭代器中元素个数 print(lst_iterator.__length_hint__()) # 返回 5 # __setstate__(2)方法表示根据索引值指定从哪里开始迭代,例如下面指定从索引为2的位置开始迭代 print(‘****‘, lst_iterator.__setstate__(2)) # 返回 **** None # __next__()方法,一个一个去列表中取元素 print("[001]", lst_iterator.__next__()) # 打印 [001] 3 print("[002]", lst_iterator.__next__()) # 打印 [002] spark print("[003]", lst_iterator.__next__()) # 打印 [003] python print("[004]", lst_iterator.__next__()) # 会报异常:StopIteration
# 在上面执行第4个打印语句时候,会报异常StopIteration,因为在这里我们通过__setstate__(2)指定了从索引为2的位置开始迭代获取元素,所以
# 元素3开始打印
通过刚才的实验,我们是通过__next__()方法不断从迭代器中获取元素。因此结合前面的知识,我们可以得出结论:任何实现了__iter__方法的对象都是可迭代的,可迭代对象调用__iter__()方法会返回一个迭代器对象,而迭代器对象通过__next__()方法不断从迭代获取迭代器对象里面的元素。所以我们说只要实现了__iter__和__next__()(python2中实现next())方法的对象都是迭代器,__iter__返回迭代器自身,__next__返回容器中的下一个值。
既然我们知道了迭代器的本质,下面我们尝试通过迭代器的__iter__和__next__方法来写一个不依赖于for循环的遍历,如下所示:
item_list = [1, 2, 3, "spark", "python"]
lst_iterator = item_list.__iter__() # 调用__iter__()方法将可迭代对象变为迭代器对象
item = lst_iterator.__next__() # 调用迭代器的__next__()方法来获取列表中的元素
print(item) #打印 1
item = lst_iterator.__next__()
print(item) #打印2
item = lst_iterator.__next__()
print(item) #打印3
item = lst_iterator.__next__()
print(item) #打印spark
item = lst_iterator.__next__()
print(item) #打印python
item = lst_iterator.__next__() # 会报异常
print(item)
通过程序的运行结果可知,最后一行会报异常,因为列表所有的元素已经被迭代访问完毕,此时没有可迭代的元素了,为了处理该异常,我们使用后面的异常处理机制,代码如下:
item_list = [1, 2, 3, "spark", "python"]
lst_iterator = item_list.__iter__() # 调用__iter__()方法将可迭代对象变为迭代器对象
while True:
try:
"""
通过while循环不断调用__next__()方法来获取列表中的元素,直到列表中的元素都被迭代访问完毕。
"""
item = lst_iterator.__next__()
print(item)
# 当继续迭代访问列表中的元素时,此时会抛出异常StopIteration,然后使用break关键字结束循环。
except StopIteration:
break
通过上面的代码,可知:一旦迭代器建立起来,提取元素的过程就不再依赖于原始的可迭代对象,而是仅仅依赖于迭代器本身。我们通过调用迭代器对象的___next__()方法,会执行三个操作:
【001】返回当前『位置』的元素,第一次调用___next__()方法,当前位置是可迭代对象的起始位置
【002】将『位置』向后递增
【003】如果到达可迭代对象的末尾,即没有元素可以提取,则抛出StopIteration异常
在实际工作中,我们并不需要这么麻烦来使用迭代器遍历可迭代对象中的元素,Python中的循环语句会自动进行迭代器的建立、next的调用和StopIteration的处理。换句话说,遍历一个可迭代对象的元素,我们这样写就行了:
item_list = [1, 2, 3, "spark", "python"]
for item in item_list:
print(item)
我们之所以可以如此方便快捷地使用for......in语句遍历可迭代对象,是因为该语句隐藏和实现了上面的细节。是不是感觉豁然开朗?
再回到我们之前的问题,Python 2.X 的 range和xrange有何区别?答案是,range的返回值就是一个list,在我们调用range的时候,Python会产生所有的元素。而xrange是一个特别设计的可迭代对象,它在建立的时候仅仅保存终止值,需要使用的时候再一个个地返回,它不会像range一样,一下子将所有的元素都放入内存,这样就很好地节省了内存,避免了内存溢出等错误。在Python 3.X 中,不再有内建的xrange,其range等效于Python 2.X 的xrange。
四.自定义迭代器
前面我们探讨了可迭代对象和迭代器的本质,即凡是实现了__iter__()方法的对象都是可迭代对象,凡是实现了__iter__()方法和__next__()方法的对象都是迭代器。那我们可以自定义迭代器吗?带着这个问题,我们从0开始来设计一个迭代器,再次从本质上理解迭代器的概念。
class MyIterator:
def __init__(self, num):
self.num = num
for i in MyIterator(20):
print(i)
# 报错:TypeError: ‘MyIterator‘ object is not iterable
从报错信息可知:由于MyIterator(10)对象不是一个可迭代的对象,因此它不能使用for循环进行迭代和遍历。既然搞清楚了错误,我们可以在MyIterator类中实现__iter__和__next__()两个方法,从而自定义一个迭代器,代码如下:
class MyIterator:
def __init__(self, num):
self.i = 0
self.num = num
def __iter__(self):
return self
def __next__(self):
if self.i < self.num:
i = self.i
self.i += 1
return i
else:
# 达到某个条件时必须抛出此异常,否则会无止境地迭代下去
raise StopIteration()
for i in MyIterator(10):
print(i)
从代码中可知,我们实现了__iter__和__next__()两个方法,因此使用for循环进行迭代时,可以成功遍历元素。通过这个示例可知,如果想要使用for......in成功遍历我们自定义的迭代器,只需要实现相应的迭代器接口即可,即刚才提到的两个方法。
五.生成器
通过前面的知识我们了解了可迭代对象和迭代器的本质,本小节我们专注于讨论生成器的底层原理和使用。我们知道的迭代器有两种:一种是调用方法直接返回的,一种是可迭代对象通过执行iter方法得到的,迭代器的好处是可以节省内存。在某些情况下,我们也需要节省内存,就只能自己写。我们自己写的这个能实现迭代器功能的东西就叫生成器。
在Python中,生成器分为两种:1.生成器函数,2.生成器表达式。下面我们来重点讨论生成器函数。
我们知道普通函数通常使用 return 返回一个值,这和 Java 等其他语言是一样的。然而在 Python 中还有一种函数,用关键字 yield 来返回值,这种函数叫生成器函数,函数被调用时会返回一个生成器对象,生成器本质上还是一个迭代器,也是用在迭代操作中,因此它有和迭代器一样的特性,唯一的区别在于实现方式上不一样,后者更加简洁。
因此,我们可以概括生成器函数的定义:凡是包含了yield关键字的函数就是一个生成器函数。yield可以为我们从函数中返回值,但是yield又不同于return,return的执行意味着程序的结束,调用生成器函数不会得到返回的具体的值,而是得到一个生成器对象,它也不会执行生成器函数中的具体内容。每次调用生成器对象的__next__()方法才会获取到生成器函数具体的返回值。我们首先通过一段简短的代码来说明生成器函数:
def generator_func(): # 带yield关键字的函数就是生成器函数 print(123) yield ‘aaa‘ # 这里的yield相当于return关键词,只有执行__next__()方法时,才执行生成器函数里面的函数体 sum_count = 1 + 2 yield sum_count a = 666 yield a g = generator_func()
print(g) #打印<generator object generator_func at 0x000001D49362BE08>
从上面的运行结果可知:直接调用生成器函数,它返回的是一个生成器对象,我们直接打印该对象,可以获取该对象在内存中的地址值:0x000001D49362BE08。此时调用生成器函数,压根就没有执行生成器函数里面的内容,那如果我们想要获取生成器函数中的返回值该怎么办?直接调用
__next__()方法即可。来看下面的代码:
def generator_func(): # 带yield关键字的函数就是生成器函数
print(123)
yield ‘aaa‘ # 这里的yield相当于return关键词,只有执行__next__()方法时,才执行生成器函数里面的函数体
sum_count = 1 + 2
yield sum_count
a = 666
yield a
g = generator_func() # 生成器函数在执行的时候返回的是一个生成器对象
result = g.__next__() # __next__()启动生成器函数
print(result) # 打印出123 和aaa
可以看到当我们开始调用__next__()方法,才返回生成器函数的返回值,而且此时生成器函数中的函数体内容执行到yield ‘aaa‘就暂时终止了,打印结果说明了这点。
由此可知当我们调用生成器对象的__next__()方法时,生成器函数的函数体执行到第一个yield关键字暂时停止,如果我们想继续获取生成器函数中使用yield关键字返回的值,该怎么办?到这里我想大家应该明白了,我们只需要继续调用__next__()方法即可,如下:
def generator_func(): # 带yield关键字的函数就是生成器函数
print(123)
yield ‘aaa‘ # 这里的yield相当于return关键词,只有执行__next__()方法时,才执行生成器函数里面的函数体
sum_count = 1 + 2
yield sum_count
a = 666
yield a
g = generator_func() # 生成器函数在执行的时候返回的是一个生成器对象
result = g.__next__() # __next__()启动生成器函数
print(result) # 打印出123 和aaa
result = g.__next__() # __next__()启动生成器函数
print(result) # 打印出3
sum_count = g.__next__()
print(sum_count) #打印出666
sum_count = g.__next__()
print(sum_count) # 报异常:StopIteration
根据上面的运行结果可知,最后一个打印结果报异常,我想大家应该能够猜出具体原因了,因为生成器函数中使用三个yield关键字来返回值,而我们在外部却使用四个g.__next__()来迭代获取元素,当前面三个返回值被迭代获取完毕后,已经没有元素了,因此当使用第四个g.__next__()获取返回值时,肯定会报异常。
既然我们生成器的本质是迭代器,因此我们也可以直接for循环来遍历生成器对象,从而获取生成器函数中的返回值。代码如下:
def generator_func(): print(123) yield‘aaa‘print(456) yield‘bbb‘ g = generator_func() for i in g: print(‘i : ‘,i)
#打印值如下:
123 i : aaa 456 i : bbb
在上面的程序中,我们通过循环遍历生成器对象g,然后不断获取生成器函数中由yield返回的值。这里就相当于执行了g.__next__()方法,只是这次不会出现异常:
StopIteration。我们再来看下面这段代码,看它会打印什么结果:
def generator_func():
count = 1
while True:
yield count
count += 1
g = generator_func()
for i in g:
print(‘i : ‘, i)
# 不断地进行死循环,永远跳不出,因为for i in g是不断的遍历生成器对象,并调用__iter__()方法不断获取由yield关键字返回的函数的值。
# 由于生成器函数中是一个死循环,yield不断地返回值,因此外层不断调用__iter__()方法来获取返回值,这样就陷入了一个恶性死循环。
我们再来观察下面的代码,各位可以尝试观察下面代码与上面代码的区别:
def generator_func():
count = 1
while True:
yield count
count += 1
g = generator_func()
for i in range(50):
print(‘i : ‘, g.__next__())
# 打印值从i:1 到i:50
我们一起来分析下上面两段程序的区别:for i in range(50)来控制下面g.__next__()的执行次数,表明从生成器中返回50个值;而for i in g表示不断迭代遍历生成器对象g,如果生成器函数的函数体是死循环,那么这段程序将永无止境的运行下去。
我们继续来观察下面这段代码,进一步来分析下结果:
def get_clothing(): for cloth in range(1, 2000000): yield‘第%s件衣服‘ % cloth generate = get_clothing() print(generate.__next__()) print(generate.__next__()) print(generate.__next__())
# 打印结果如下:
第1件衣服 第2件衣服 第3件衣服
如果我想打印50件衣服,那岂不是要写50个print语句,这肯定不行,为此,我们使用range来控制次数,接着上面的代码:
def get_clothing(): for cloth in range(1, 2000000): yield‘第%s件衣服‘ % cloth generate = get_clothing() print(generate.__next__()) print(generate.__next__()) print(generate.__next__()) for i in range(50): print(generate.__next__())
# 打印结果如下:
第1件衣服 ....... 第51件衣服 第52件衣服 第53件衣服
有小伙伴肯定会很纳闷,明明我控制的是打印50件衣服,但是怎么打印出53件衣服?理由很简单:因为它们使用的是同一个生成器对象,在前面我们已经调用了三次generate.__next__(),此时指针指到了第三个位置末尾,那么在下面我们直接调用generate.__next__(),相当于从第四个位置的元素开始打印,所以会出现53件衣服。
针对上面的问题,我们继续来看下面几个生成器中比较容易出错的点,希望能够帮助大家进一步理解生成器的概念和原理。继续看代码:
def generator_func():
print(123)
yield ‘aaa‘
print(456)
yield ‘bbb‘
result1 = generator_func().__next__()
print(result1) # 打印 123 aaa
result2 = generator_func().__next__()
print(result2) # 打印 123 aaa
小伙伴们又要纳闷了,为什么没有打印456和bbb呢?这是因为每当我们调用一次生成器函数就会生成一个生成器对象,在上面的代码中,我们调用了2次生成器函数generator_func(),所以会生成两个生成器函数对象,当我们第一次调用generator_func().__next__()时,会执行生成器函数中的内容,直到执行到第一个yield为止,然后打印print(result1),因此会打印出123和aaa;当我们第二次调用generator_func().__next__()时,又会重新产生一个新的生成器对象,并且会重新从头开始执行生成器函数中的内容,此时开始执行后,又会执行到第一个yield为止,然后将值返回给result2,所以此时会打印出123和aaa。
关于生成器的最后一个问题,这里也要做一个简短的说明。既然普通函数的return关键字可以返回None,那么yield后面可以不跟任何返回值吗?带着这个问题,我们一起来看看如下的代码测试:
def generator():
yield
yield 2
g = generator()
for i in g:
print(i)
# 打印结果如下:None和2
由结果我们分析可知,yield后面可以不跟任何值,但是这样做毫无意义!我们一般结合yield和while循环使用。
关于生成器中相关重点内容就总结到这里,最后再来梳理下关于生成器取值要注意的几个点:
【001】通过__next__方法来获取yield返回值,此时有几个yield就可以取几次值,如果超过了yield的个数,那么会报异常,因为值都被取完了。
【002】由于生成器的本质还是迭代器,所以我们可以通过for循环来遍历生成器,类似这种:for i in g
【003】我们也可以通过其他数据类型来取值,例如将生成器对象通过列表list强制转换list(g),这样返回的就是一个列表,我们直接遍历列表中的元素即可。因为列表中此时装载着生成器中的所有内容。
结语:
关于函数生成器与迭代器的讨论就到此为止,欢迎各位感兴趣的朋友们与我交流!本博客在写的过程中参考了网络上几篇非常优秀的文章,现在分享出来,希望能够对各位有所帮助!
【001】看完这篇,你就知道Python生成器是什么:https://foofish.net/what-is-python-generator.html
【002】for循环在Python中是怎么工作的:https://foofish.net/how-for-works-in-python.html
【003】完全理解Python迭代对象、迭代器、生成器:https://foofish.net/iterators-vs-generators.html
【004】Iterables vs. Iterators vs. Generators:http://nvie.com/posts/iterators-vs-generators/
【005】python之路——迭代器和生成器:http://www.cnblogs.com/Eva-J/articles/7213953.html#_label3
【006】Python 的迭代器和生成器:https://zhuanlan.zhihu.com/p/24499698
【007】黄哥漫谈Python 生成器:https://zhuanlan.zhihu.com/p/21659182?refer=pythonpx

以上是关于Python学习之旅—Day07(生成器与迭代器)的主要内容,如果未能解决你的问题,请参考以下文章
Python100天学习笔记Day20 迭代器与生成器及 并发编程
Python100天学习笔记Day20 迭代器与生成器及 并发编程