Python机器学习--聚类
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python机器学习--聚类相关的知识,希望对你有一定的参考价值。
-
K-means聚类算法



-
测试:
# -*- coding: utf-8 -*- """ Created on Thu Aug 31 10:59:20 2017 @author: Administrator """ ‘‘‘ 现有1999年全国31个省份城镇居民家庭平均每人全年消费性支出的八个主 要变量数据,这八个变量分别是:食品、 衣着、 家庭设备用品及服务、 医疗 保健、 交通和通讯、 娱乐教育文化服务、 居住以及杂项商品和服务。 利用已 有数据,对31个省份进行聚类。 ‘‘‘ import numpy as np from sklearn.cluster import KMeans def loadData(filePath): fr = open(filePath,‘r+‘) lines = fr.readlines() retData = [] retCityName = [] for line in lines: items = line.strip().split(",") retCityName.append(items[0]) retData.append([float(items[i]) for i in range(1,len(items))]) return retData,retCityName if __name__ == ‘__main__‘: fpath=‘F:\\RANJIEWEN\\MachineLearning\\Python机器学习实战_mooc\\data\\聚类\\\\‘ data,cityName = loadData(fpath+‘city.txt‘) km = KMeans(n_clusters=4) label = km.fit_predict(data) expenses = np.sum(km.cluster_centers_,axis=1) #print(expenses) CityCluster = [[],[],[],[]] for i in range(len(cityName)): CityCluster[label[i]].append(cityName[i]) for i in range(len(CityCluster)): print("Expenses:%.2f" % expenses[i]) print(CityCluster[i])
-
DBSCAN密度聚类




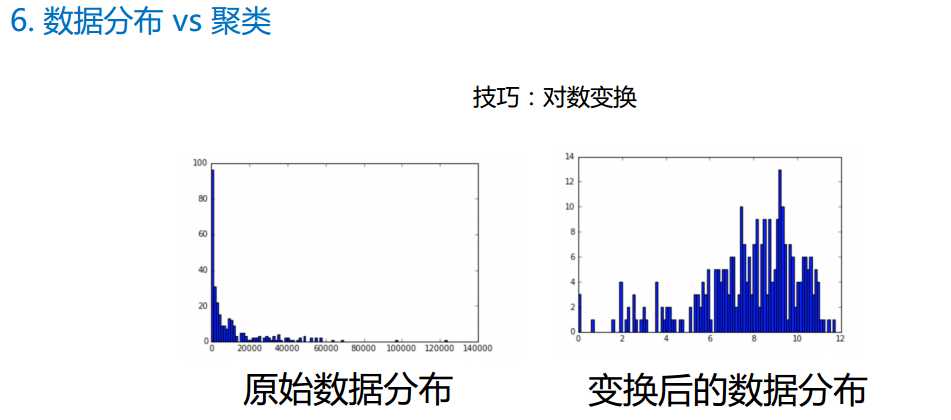
-
测试
# -*- coding: utf-8 -*- """ Created on Thu Aug 31 11:14:37 2017 @author: Administrator """ ‘‘‘ 现有大学校园网的日志数据,290条大学生的校园网使用情况数据,数据包 括用户ID,设备的MAC地址,IP地址,开始上网时间,停止上网时间,上 网时长,校园网套餐等。 利用已有数据,分析学生上网的模式。 实验目的: 通过DBSCAN聚类,分析学生上网时间和上网时长的模式。 ‘‘‘ import numpy as np import sklearn.cluster as skc from sklearn import metrics import matplotlib.pyplot as plt mac2id=dict() onlinetimes=[] fpath=‘F:\\RANJIEWEN\\MachineLearning\\Python机器学习实战_mooc\\data\\聚类\\\\‘ f=open(fpath+‘TestData.txt‘,encoding=‘utf-8‘) for line in f: mac=line.split(‘,‘)[2] onlinetime=int(line.split(‘,‘)[6]) starttime=int(line.split(‘,‘)[4].split(‘ ‘)[1].split(‘:‘)[0]) if mac not in mac2id: mac2id[mac]=len(onlinetimes) onlinetimes.append((starttime,onlinetime)) else: onlinetimes[mac2id[mac]]=[(starttime,onlinetime)] real_X=np.array(onlinetimes).reshape((-1,2)) X=real_X[:,0:1] ## 聚类数据变换技巧 # X=np.log(1+real_X[:,1:]) db=skc.DBSCAN(eps=0.01,min_samples=20).fit(X) labels = db.labels_ print(‘Labels:‘) print(labels) raito=len(labels[labels[:] == -1]) / len(labels) print(‘Noise raito:‘,format(raito, ‘.2%‘)) n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) print(‘Estimated number of clusters: %d‘ % n_clusters_) print("Silhouette Coefficient: %0.3f"% metrics.silhouette_score(X, labels)) for i in range(n_clusters_): print(‘Cluster ‘,i,‘:‘) print(list(X[labels == i].flatten())) plt.hist(X,24)
-
基于聚类的图像分割



-
测试
# -*- coding: utf-8 -*- """ Created on Thu Aug 31 15:03:11 2017 @author: Administrator """ ‘‘‘ 目标:利用K-means聚类算法对图像像素点颜色进行聚类实现简单的图像分割 输出:同一聚类中的点使用相同颜色标记,不同聚类颜色不同 ‘‘‘ import numpy as np import PIL.Image as image from sklearn.cluster import KMeans def loadData(filePath): f = open(filePath,‘rb‘) data = [] img = image.open(f) m,n = img.size for i in range(m): for j in range(n): x,y,z = img.getpixel((i,j)) data.append([x/256.0,y/256.0,z/256.0]) f.close() return np.mat(data),m,n imPath=‘F:\\RANJIEWEN\\MachineLearning\\Python机器学习实战_mooc\\data\\基于聚类的整图分割\\\\‘ imgData,row,col = loadData(imPath+‘bull.jpg‘) label = KMeans(n_clusters=4).fit_predict(imgData) label = label.reshape([row,col]) pic_new = image.new("L", (row, col)) for i in range(row): for j in range(col): pic_new.putpixel((i,j), int(256/(label[i][j]+1))) pic_new.save("result-bull-4.jpg", "JPEG")
以上是关于Python机器学习--聚类的主要内容,如果未能解决你的问题,请参考以下文章