第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—倒排索引
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—倒排索引相关的知识,希望对你有一定的参考价值。
第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—倒排索引
倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
倒排索引原理
就是将一句话进行分词并记录分词所存在的文章,当用户搜索词时可以直接查找到当前词所存在的文章
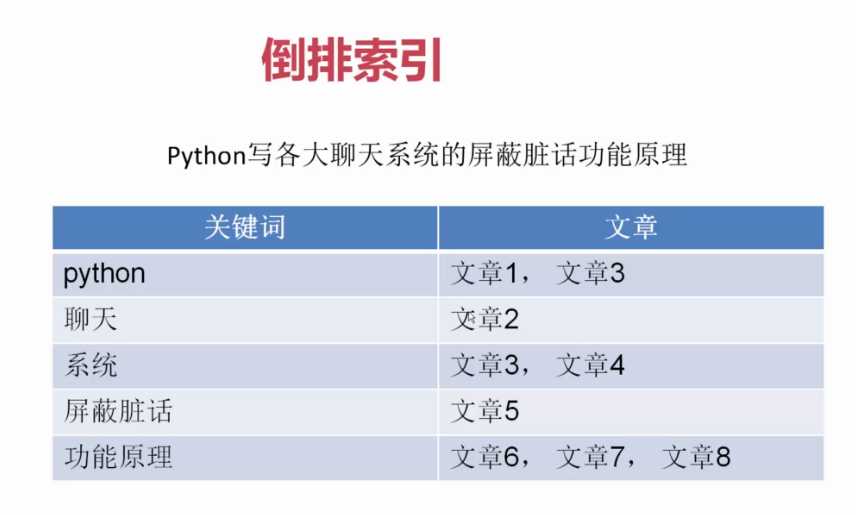
倒排索引分词权重记录(词瓶)
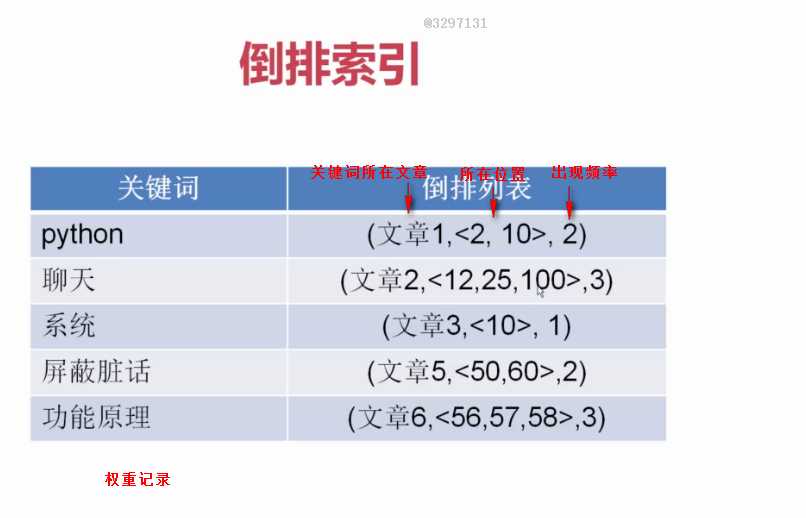
分词权重记录,是通过(TF-IDF)来实现的,详情https://baike.so.com/doc/433640-459181.html
以上是关于第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—倒排索引的主要内容,如果未能解决你的问题,请参考以下文章
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的查询
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能