python的 随手记----字符编码与转码
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python的 随手记----字符编码与转码相关的知识,希望对你有一定的参考价值。
一.前提
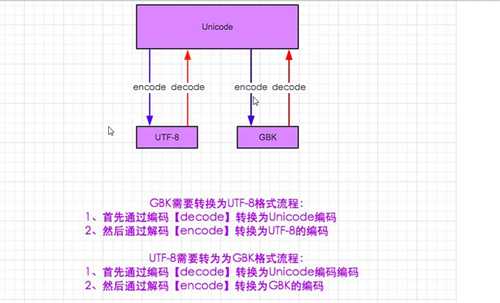
那么到底什么是编码呢? //ASCII 记住一句话:计算机中的所有数据,不论是文字、图片、视频、还是音频文件,本质上最终都是按照类似 01010101 的二进制存储的。 再说简单点,计算机只懂二进制数字! 所以,目的明确了:如何将我们能识别的符号唯一的与一组二进制数字对应上?于是美利坚的同志想到通过一个电平的高低状态来代指0或1, 八个电平做为一组就可以表示出 256种不同状态,每种状态就唯一对应一个字符,比如A--->00010001,而英文只有26个字符,算上一些特殊字符和数字,128个状态也够 用了;每个电平称为一个比特为,约定8个比特位构成一个字节,这样计算机就可以用127个不同字节来存储英语的文字了。这就是ASCII编码。 扩展ANSI编码 刚才说了,最开始,一个字节有八位,但是最高位没用上,默认为0;后来为了计算机也可以表示拉丁文,就将最后一位也用上了, 从128到255的字符集对应拉丁文啦。至此,一个字节就用满了! //GB2312 计算机漂洋过海来到中国后,问题来了,计算机不认识中文,当然也没法显示中文;而且一个字节所有状态都被占满了,万恶的帝国主义亡 我之心不死啊!我党也是棒,自力更生,自己重写一张表,直接生猛地将扩展的第八位对应拉丁文全部删掉,规定一个小于127的字符的意 义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节 (低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了;这种汉字方案叫做 “GB2312”。GB2312 是对 ASCII 的中文扩展。 //GBK 和 GB18030编码 但是汉字太多了,GB2312也不够用,于是规定:只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的 内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。 //UNICODE编码: 很多其它国家都搞出自己的编码标准,彼此间却相互不支持。这就带来了很多问题。于是,国际标谁化组织为了统一编码:提出了标准编码准 则:UNICODE 。 UNICODE是用两个字节来表示为一个字符,它总共可以组合出65535不同的字符,这足以覆盖世界上所有符号(包括甲骨文) //utf8: unicode都一统天下了,为什么还要有一个utf8的编码呢? 大家想,对于英文世界的人们来讲,一个字节完全够了,比如要存储A,本来00010001就可以了,现在吃上了unicode的大锅饭, 得用两个字节:00000000 00010001才行,浪费太严重! 基于此,美利坚的科学家们提出了天才的想法:utf8. UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,它可以使用1~4个字节表示一个符号,根据 不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,所以是兼容ASCII编码的。 这样显著的好处是,虽然在我们内存中的数据都是unicode,但当数据要保存到磁盘或者用于网络传输时,直接使用unicode就远不如utf8省空间啦! 这也是为什么utf8是我们的推荐编码方式。 Unicode与utf8的关系: 一言以蔽之:Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)这也是UTF与Unicode的区别。
我们只需要知道unicode是万国码,而utf-8还有gbk都是由unicode中拓展出来的,于是我们utf-8转为gbk是形式是:先转成unicode再转成gbk;同理其他编码转化成utf-8,也先向unicode转化,再转成utf-8
python3字符串是以Unicode编码的,文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示
其中的容易误解的地方:
(1)py3里默认文件编码就是utf-8,所以可以直接写中文,也不需要文件头声明编码了
(2)你声明的变量默认是unicode编码,即使你文件头声明编码是utf-8,也不是utf-8, 因为默认即是unicode了
import sys
print(sys.getdefaultencoding())#打印系统的默认编码
#s=u"你好"#加一个u表示这个你好是upython默认是unicodenicode的编码格式,输出结果发现和不加u是一样的,表示python默认是unicode
s="你好"#,即这个s是unicode的编码格式
print(s.encode("utf-8"))#encode解码,即告诉系统s向utf-8转换,输出一个byte类型的对象
print(s.encode("utf-8").decode("gbk"))#表示再向gbk格式转码
print(s.encode("gbk"))
print(s.encode("utf-8").decode("utf-8").encode("gbk"))
print(s.encode())#默认不写表示utf-8
print(s.encode("utf-8").decode())
输出结果:
>>>utf-8
>>>b‘\\xe4\\xbd\\xa0\\xe5\\xa5\\xbd‘#b‘表示byte类型
>>>浣犲ソ >>>b‘\\xc4\\xe3\\xba\\xc3‘
>>>b‘\\xc4\\xe3\\xba\\xc3‘
>>>b‘\\xe4\\xbd\\xa0\\xe5\\xa5\\xbd‘
>>>你好
以上是关于python的 随手记----字符编码与转码的主要内容,如果未能解决你的问题,请参考以下文章