what's the python之基本运算符及字符串列表元祖集合字典的内置方法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了what's the python之基本运算符及字符串列表元祖集合字典的内置方法相关的知识,希望对你有一定的参考价值。
计算机可以进行的运算有很多种,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算。字符串和列表的算数运算只能用+和*,字典没有顺序,所以不能进行算数运算和比较运算。比较运算中==比较的是值,is比较的是id。比较运算只能在同种类型下进行比较。字符串的比较是按照顺序依次进行比较。逻辑运算的顺序先后为要用括号来表示。
基本运算符如下:
算术运算
以下假设a=10,b=20
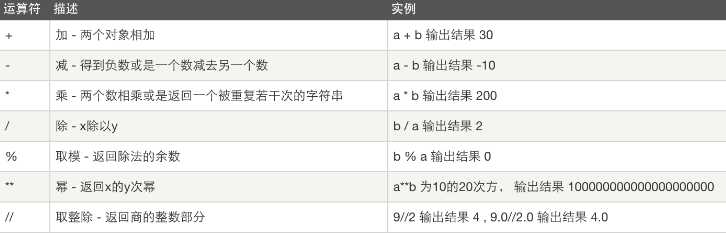
比较运算
以下假设a=10,b=20
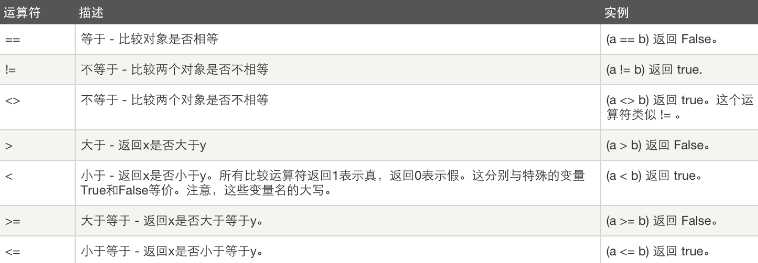
赋值运算
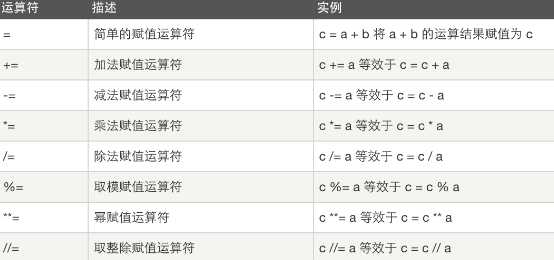
逻辑运算

成员运算

身份运算

what‘s the 内置方法
内置方法就是python中已经写好的方法,我们不用管原理直接拿来用就行。所以内置方法是规定好的,我们想要学会就必须是全部记住。
字符串的内置方法
字符串的内置方法包括:移除空白strip、切分split、长度len、切片(切出子字符串)、startswith和endswith、替代replace、查找find(顾头不顾尾,找不到则返回-1不报错)、index(顾头不顾尾,但找不到会报错)、count(顾头不顾尾,若不指定范围则查找所有)、格式化输出%或.format()、插入join、插入空格expandtabs、全大写upper和全小写lower、首字母大写capitlize、大小写翻转swapcase、每个单词的首字母大写title、插入符号
移除空白strip:
msg=‘ hello ‘ print(msg) print(msg.strip())#hello msg=‘***hello*********‘ msg=msg.strip(‘*‘) print(msg)#hello print(msg.lstrip(‘*‘))#hello********* print(msg.rstrip(‘*‘))#***hello
举个栗子(程序交互,如果用户在输入的用户名或者密码时不小心多按了空格,也不会造成错误,可以正常登陆)
while True: name=input(‘user: ‘).strip() password=input(‘password: ‘).strip() if name == ‘egon‘ and password == ‘123‘: print(‘login successfull‘)
切分split:
info=‘root:x:0:0::/root:/bin/bash‘ print(info[0]+info[1]+info[2]+info[3])#root user_l=info.split(‘:‘) print(user_l[1])#x msg=‘hello world egon say hahah‘ print(msg.split()) #[‘hello‘, ‘world‘, ‘egon‘, ‘say‘, ‘hahah‘] #默认以空格作为分隔符 cmd=‘download|xhp.mov|3000‘ cmd_l=cmd.split(‘|‘) print(cmd_l[1])#xhp.mov print(cmd_l[0])#downland print(cmd.split(‘|‘,1))#[‘download‘, ‘xhp.mov|3000‘]
长度len:
print(len(‘hell 123‘))
切片(切出子字符串):
msg=‘hello world‘ print(msg[1:3]) #el print(msg[1:4]) #ell
startswith和endswith:
name=‘you_suck‘ print(name.endswith(‘uk‘))#True print(name.startswith(‘y‘)#True print(name.startswith(‘w‘)#False
替代replace:
name=‘jack say :i have a iphone,my name is jack‘ print(name.replace(‘jack‘,‘john‘,1)) #john say :i have a iphone,my name is jack
查找find(顾头不顾尾,找不到则返回-1不报错)
index(顾头不顾尾,但找不到会报错)
count(顾头不顾尾,若不指定范围则查找所有):
name=‘jack say hello‘ print(name.find(‘S‘,1,3)) #顾头不顾尾,找不到则返回-1不会报错,找到了则显示索引 print(name.index(‘S‘)) #同上,但是找不到会报错 print(name.count(‘S‘,1,5)) #顾头不顾尾,如果不指定范围则查找所有
格式化输出%或.format():格式化输出宏需要用到占位符,一般统一使用%s
print(‘my name is %s my age is %s my sex is %s‘ %(‘jack‘,18,‘male‘)) #my name is jack my age is 18 my sex is male print(‘my name is {} my age is {} my sex is {}‘.format(‘jack‘,18,‘male‘)) #my name is jack my age is 18 my sex is male print(‘my name is {0} my age is {1} my sex is {0}:{2}‘.format(‘jack‘,18,‘male‘)) #my name is jack my age is 18 my sex is egon:male print(‘my name is {name} my age is {age} my sex is {sex}‘.format( sex=‘male‘, age=18, name=‘jack‘)) #my name is jack my age is 18 my sex is male
插入join(切片split的反方向):
info=‘root:x:0:0::/root:/bin/bash‘ print(info.split(‘:‘))#[‘root‘, ‘x‘, ‘0‘, ‘0‘, ‘‘, ‘/root‘, ‘/bin/bash‘] l=[‘root‘, ‘x‘, ‘0‘, ‘0‘, ‘‘, ‘/root‘, ‘/bin/bash‘] print(‘:‘.join(l))#root:x:0:0::/root:/bin/bash
插入空格expandtabs:
name=‘jack\\thello‘ print(name))#jack hello#即俩单词中间插入了一个缩进的长度的空格 print(name.expandtabs(1)#jack hello#即俩单词中间插入了一个长度的空格
全大写upper和全小写lower:
name=‘jAck‘ print(name.lower()) print(name.upper())
首字母大写capitlize、大小写翻转swapcase、每个单词的首字母大写title:
name=‘jAck‘ print(name.capitalize()) #首字母大写,其余部分小写 print(name.swapcase()) #大小写翻转 msg=‘jack say good morning‘ print(msg.title()) #每个单词的首字母大写
插入符号:
name=‘jack‘ print(name.center(30,‘-‘))#-------------jack------------- print(name.ljust(30,‘*‘))#jack************************** print(name.rjust(30,‘*‘))#**************************jack print(name.zfill(50)) #用0填充 #0000000000000000000000000000000000000000000000jack
在python3中
num0=‘4‘
num1=b‘4‘ bytes类型
num2=u‘4‘ unicode,python3中无需加u就是unicode
num3=‘四‘ 中文数字
num4=‘Ⅳ‘ 罗马数字
isdigt:str,bytes,unicode print(num0.isdigit()) print(num1.isdigit()) print(num2.isdigit()) print(num3.isdigit()) print(num4.isdigit()) isdecimal:str,unicode num0=‘4‘ num1=b‘4‘ #bytes num2=u‘4‘ #unicode,python3中无需加u就是unicode num3=‘四‘ #中文数字 num4=‘Ⅳ‘ #罗马数字 print(num0.isdecimal()) # print(num1.) print(num2.isdecimal()) print(num3.isdecimal()) print(num4.isdecimal()) isnumeric:str,unicode,中文,罗马 num0=‘4‘ num1=b‘4‘ #bytes num2=u‘4‘ #unicode,python3中无需加u就是unicode num3=‘四‘ #中文数字 num4=‘Ⅳ‘ #罗马数字 print(num0.isnumeric()) # print(num1) print(num2.isnumeric()) print(num3.isnumeric()) print(num4.isnumeric())
列表的内置方法
列表的内置方法主要有索引、切片、追加appand、删除pop、长度len、包含in、插入insert、count、清除clear、复制copy、翻转reverse、排序sort。
切片:
l=[‘a‘,‘b‘,‘c‘,‘d‘,‘e‘,‘f‘] print(l[1:5])#[‘b‘, ‘c‘, ‘d‘, ‘e‘] print(l[1:5:2])#[‘b‘, ‘d‘]#其中的2表示步距 print(l[2:5])#[‘c‘, ‘d‘, ‘e‘] print(l[-1])#f
追加append:
hobbies=[‘play‘,‘eat‘,‘sleep‘,‘study‘] hobbies.append(‘girls‘) print(hobbies)#[‘play‘, ‘eat‘, ‘sleep‘, ‘study‘, ‘girls‘]
删除pop:
hobbies=[‘play‘,‘eat‘,‘sleep‘,‘study‘] x=hobbies.pop(1) #不是单纯的删除,是删除并且把删除的元素返回,我们可以用一个变量名去接收该返回值 print(x)#eat print(hobbies)#[‘play‘, ‘sleep‘, ‘study‘] del hobbies[1] #单纯的删除 hobbies.remove(‘eat‘) #单纯的删除,并且是指定元素去删除
就append和pop补充一个队列和堆栈的小题目


#队列:先进先出 queue_l=[] #入队 queue_l.append(‘first‘) queue_l.append(‘second‘) queue_l.append(‘third‘) print(queue_l)#[‘first‘, ‘second‘, ‘third‘] # 出队 print(queue_l.pop(0))#first print(queue_l.pop(0))#second print(queue_l.pop(0))#third #堆栈:先进后出,后进先出 l=[] #入栈 l.append(‘first‘) l.append(‘second‘) l.append(‘third‘) print(l)#[‘first‘, ‘second‘, ‘third‘] #出栈 print(l.pop())#third print(l.pop())#second print(l.pop())#first
长度len:
hobbies=[‘play‘,‘eat‘,‘sleep‘,‘study‘] print(len(hobbies))#4
包含in:
hobbies=[‘play‘,‘eat‘,‘sleep‘,‘study‘] print(‘sleep‘ in hobbies)#True msg=‘hello world jack‘ print(‘jack‘ in msg)#True
插入insert:
hobbies=[‘play‘,‘eat‘,‘sleep‘,‘study‘,‘eat‘,‘eat‘] hobbies.insert(1,‘walk‘) hobbies.insert(1,[‘walk1‘,‘walk2‘,‘walk3‘]) print(hobbies) #[‘play‘, [‘walk1‘, ‘walk2‘, ‘walk3‘], ‘walk‘, ‘eat‘, ‘sleep‘, ‘study‘, ‘eat‘, ‘eat‘]
另一种插入extend:
hobbies=[‘play‘,‘eat‘,‘sleep‘,‘study‘,‘eat‘,‘eat‘] hobbies.extend([‘walk1‘,‘walk2‘,‘walk3‘]) print(hobbies)#[‘play‘, ‘eat‘, ‘sleep‘, ‘study‘, ‘eat‘, ‘eat‘, ‘walk1‘, ‘walk2‘, ‘walk3‘] #注意extend与insert的区别
索引count、index:
hobbies=[‘play‘,‘eat‘,‘sleep‘,‘study‘,‘eat‘,‘eat‘] print(hobbies.count(‘eat‘))#3,个数 print(hobbies.index(‘sleep‘))#2,下标位置
清除clear和复制copy简单,不做详述。
字典的内置方法
#存/取: info_dic={‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘} print(info_dic[‘name11111111‘]) print(info_dic.get(‘name‘,None)) #删除: info_dic={‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘} info_dic.pop() info_dic.popitem() del info_dic[‘name‘] #pop:key存在则弹出值,不存在则返回默认值,如果没有默认值则报错 print(info_dic.pop(‘nam123123123123123123e‘,None)) print(info_dic) print(info_dic.popitem()) print(info_dic) #键s,值s,键值对: info_dic={‘name‘:‘egon‘,‘age‘:18,‘sex‘:‘male‘} print(info_dic.keys())#键 print(info_dic.values())#值 print(info_dic.items())#键值对 for k in info_dic:#循环输出键值对 print(k,info_dic[k]) #长度len,比较简单不做说明 #包含in,也较简单不做说明 #升级:若原字典有则替换,若没有则添加 info_dic={‘name‘:‘jack‘,‘age‘:18,‘sex‘:‘male‘} info_dic.update({‘a‘:1,‘name‘:‘jAck‘}) print(info_dic) #增加: info_dic={‘name‘:‘jack‘,‘age‘:18,‘sex‘:‘male‘} # info_dic[‘hobbies‘]=[] # info_dic[‘hobbies‘].append(‘study‘) # info_dic[‘hobbies‘].append(‘read‘) # print(info_dic) #copy和clear较简单不做说明 #fromkeys:作用只是新建了一个字典,与原字典无关 d=info_dic.fromkeys((‘name‘,‘age‘,‘sex‘),None) print(d) d1=dict.fromkeys((‘name‘,‘age‘,‘sex‘),None) d2=dict.fromkeys((‘name‘,‘age‘,‘sex‘),(‘jack‘,18,‘male‘)) print(d1) print(d2)
元祖的内置方法
元祖的内置方法较少,主要为切片、in、长度len、索引index、count。
切片:
goods=(‘iphone‘,‘lenovo‘,‘sanxing‘,‘suoyi‘) print(goods[1:3])#(‘lenovo‘, ‘sanxing‘)
包含in:
goods=(‘iphone‘,‘lenovo‘,‘mi‘,‘zuk‘) print(‘iphone‘ in goods)#True d={‘a‘:1,‘b‘:2,‘c‘:3} print(‘b‘ in d)#True
长度len:
hobbies=(‘play‘,‘eat‘,‘sleep‘,‘study‘) print(len(hobbies))#4
索引index、count:
goods=(‘iphone‘,‘lenovo‘,‘mi‘,‘zuk‘) print(goods.index(‘iphone‘))#0,下标位置 print(goods.count(‘iphone‘))#1,个数
集合的内置方法
in和not in
s={‘a‘,‘b‘,‘c‘,‘d‘}
print(‘a‘in s)#True
并集|
s_1={‘a‘,‘b‘,‘c‘}
s_2={‘a‘,‘b‘,‘d‘}
print(s_1|s_2)#{‘a‘,‘b‘,‘c‘,‘d‘}
#也可以用union
print(s_1.union(s_2))
交集&
s_1={‘a‘,‘b‘,‘c‘}
s_2={‘a‘,‘b‘,‘d‘}
print(s_1&s_2)#{‘a‘,‘b‘}
#也可以用intersection
print(s_1.intersection(s_2))
差集-
s_1={‘a‘,‘b‘,‘c‘}
s_2={‘a‘,‘b‘,‘d‘}
print(s_1-s_2)#{‘c‘}
#也可以用difference
print(s_1.difference(s_2)) #{‘c‘}
print(s_2.difference(s_1)) #{‘d‘}
对称差集^:即两者的并集去掉两者的交集
s_1={‘a‘,‘b‘,‘c‘}
s_2={‘a‘,‘b‘,‘d‘}
print(s_1^s_2) #{‘c‘,‘d‘}
#也可以用symmetric_difference
print(s_1.symmetric_difference(s_2))
父集、子集
set1={1,2,3,4,5}
set2={1,2,3,4}
print(set1 >= set2)
#也可以用issuperset
print(set1.issupissubseterset(set2))
print(set2 <= set1)
#也可以用issubset
print(set2.issubset(set1))
简单要点,不做详述:添加add、删除pop(随机删除,因为集合是无序的)、remove(指定删除,找不到则报错)、discards(指定删除,找不到不报错)、升级update、清除clear、复制copy、解压a*_。
以上是关于what's the python之基本运算符及字符串列表元祖集合字典的内置方法的主要内容,如果未能解决你的问题,请参考以下文章