20170820_python实时获取某网站留言信息
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了20170820_python实时获取某网站留言信息相关的知识,希望对你有一定的参考价值。
主要用的是request和bs4,遇到最大的问题是目标站是gb2312编码,python3的编码虽然比2的处理要好得多但还是好麻烦,
最开始写的是用cookie模拟登陆,但是这个在实际使用中很麻烦,需要先登陆目标网站,然后把cookie复制下来拷贝到代码中...懒惰是
第一动力!
准备用火狐的httpfox获取下目标站post的数据和地址,发现火狐浏览器自动升级到了55.x,插件只能用在35.x版本,然后用chrome发现这
个网站提交post请求是打开了一个新的页面,然后新页面再点F12就晚了,看不到post了,然后百度一番发现可以设置新标签页开启F12!如图:
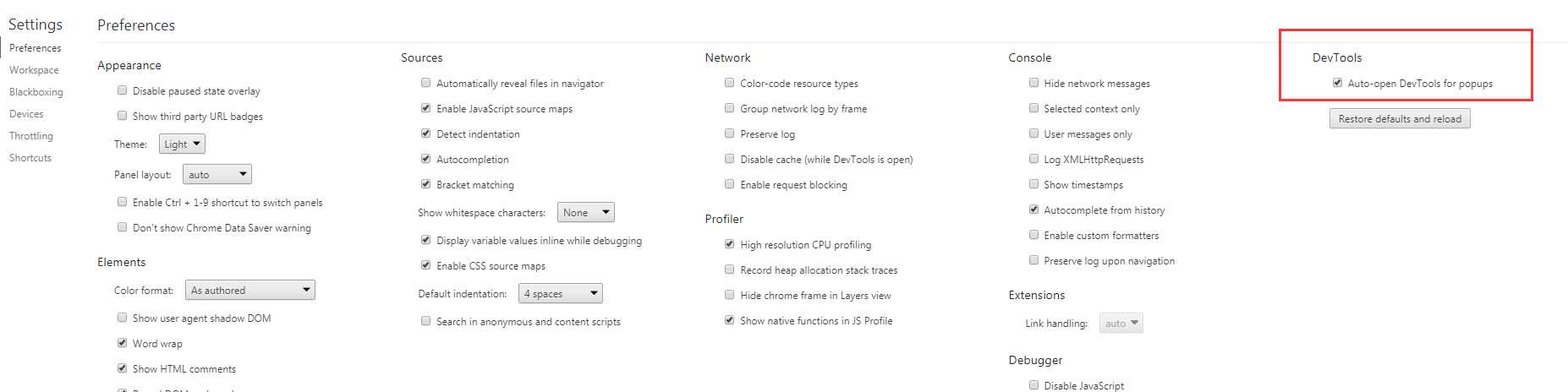
然后就知道了这个网站都post了什么数据,开始用requests模拟post,但是发现每次都登录失败,而且抓取的网页内容都是乱码,用了str(‘info‘, encoding=‘utf-8‘)才有所好转
发现根本就没有登录成功,然后提示输入账号密码登录。
 灵光一闪!!!
灵光一闪!!!
估计是我post的数据是utf8而目标站接收post时是gb2312,根本看不懂啊!果断把用户名(用户名是中文!!!) username.encode("gb2312")之后顺利登录成功!然后又
开启了session保持cookie,持久化登录。然后每分钟判断下最后一个id是否等于保存的id,判断是否进行抓取。
#-*-coding:utf-8-*- #编码声明
import requests,re,time,json,os
from bs4 import BeautifulSoup
from time import strftime,gmtime
LOGIN_URL = ‘http://www.3456.tv/Default.aspx‘ #请求的URL地址
username = ‘用户名‘
password = ‘password‘
DATA = {"web_top_two2$txtName":username.encode("gb2312"), "web_top_two2$txtPass":password, ‘__VIEWSTATE‘:‘/wEPDwULLTEyNzc4MjM2OTBkGAEFHl9fQ29udHJvbHNSZXF1aXJlUG9zdEJhY2tLZXlfXxYBBRh3ZWJfdG9wX3R3bzIkaW1nQnRuTG9naW6/pqbjQqV358GfYjdoiOK+Ek4VWA==‘,‘__EVENTVALIDATION‘:‘/wEWBAL3y5PLCgLHgt+5BgL3r9v/CgLX77PND5R1XxTeGn4lXvBDrb6OdRyc4Xlk‘,‘web_top_two2$imgBtnLogin.x‘:‘22‘,‘web_top_two2$imgBtnLogin.y‘:‘8‘} #登录系统的账号密码,也是我们请求数据
HEADERS = {‘User-Agent‘ : ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36‘} #模拟登陆的浏览器
S = requests.Session()
login = S.post(LOGIN_URL,data=DATA,headers=HEADERS) #模拟登陆操作
def getData(num):
url = ‘http://www.3456.tv/user/list_proxyall.html‘
res = S.get(url)
content = res.content
return content
def getLast():
url = ‘http://www.3456.tv/user/list_proxyall.html‘
res = S.get(url)
content = res.content
soup = BeautifulSoup(content,‘html.parser‘)
tb = soup.find_all(‘tr‘,style=‘text-align:center;‘)
for tag in tb:
see = tag.find(‘a‘, attrs={‘class‘:‘see‘})
seestr = see[‘onclick‘]
seenum = re.sub("\\D", "", seestr)
break
return seenum
def isNew():
newlastid = getLast()
with open(‘lastid.txt‘) as txt:
last = txt.read()
if int(newlastid) != int(last):
print(‘当前时间:‘ + strftime("%H-%M") + ‘,发现新留言,获取中!‘)
getNewuser()
else:
print(‘当前时间:‘ + strftime("%H-%M") + ‘,暂时没有新留言‘)
def getNewuser():
url = ‘http://www.3456.tv/user/list_proxyall.html‘
res = S.get(url)
content = res.content
soup = BeautifulSoup(content,‘html.parser‘)
tb = soup.find_all(‘tr‘,style=‘text-align:center;‘)
with open(‘lastid.txt‘) as txt:
last = txt.read()
userinfo = ‘‘
for tag in tb:
see = tag.find(‘a‘, attrs={‘class‘:‘see‘})
seestr = see[‘onclick‘]
seenum = re.sub("\\D", "", seestr)
if int(seenum) == int(last):
break
userinfo += (str(seeInfo(int(seenum)), encoding = "utf-8") + ‘\\n‘)
userfilename = strftime("%H-%M") + ‘.txt‘
with open( userfilename, ‘w‘) as f:
f.write(str(userinfo))
os.system(userfilename)
with open(‘lastid.txt‘, ‘w‘) as f2:
f2.write(str(getLast()))
print(‘本次抓取完成,当前时间:‘ + strftime("%H-%M") + ‘,60秒后继续执行‘)
def seeInfo(id):
url = ‘http://www.3456.tv/user/protel.html‘
info = {‘id‘:id}
res = S.get(url,data=info)
content = res.content
return content
setsleep = 60 #修改这个设置每次抓取间隔,60为60秒
print(‘this time is today first time start?‘)
firststr = input(‘input yes or no and press enter: ‘)
if firststr == ‘yes‘:
print(‘正在抓取中...‘)
lastid = getLast()
with open(‘lastid.txt‘, ‘w‘) as f:
f.write(str(lastid))
print(‘当前时间:‘ + strftime("%H:%M") + ‘,当前第一条数据id为‘ + lastid)
print(str(setsleep) + ‘秒后继续执行‘)
else:
print(str(setsleep) + ‘秒后继续执行‘)
while 1:
isNew()
time.sleep(int(setsleep))
以上是关于20170820_python实时获取某网站留言信息的主要内容,如果未能解决你的问题,请参考以下文章